







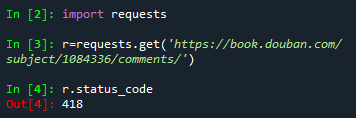
场景:爬取豆瓣评论,状态码为418(正确的状态码应为200)
Part 1 状态码418的解决方法
一、常见的HTTP状态码
HTTP状态码的英文为HTTP Status Code。
HTTP状态码共分为5种类型:

常见的HTTP状态码:
200 - 请求成功
301 - 资源(网页等)被永久转移到其它URL
404 - 请求的资源(网页等)不存在
500 - 内部服务器错误
(来源:https://www.runoob.com/http/http-status-codes.html)
二、状态码418
418的意思是:你爬取的网站有反爬虫机制,需要通过反爬机制去解决这个问题。 headers是解决requests请求反爬的方法之一,相当于我们进去这个网页的服务器本身,假装自己本身在爬取数据。
对反爬虫网页,可以设置一些headers信息,模拟成浏览器取访问网站 。
在谷歌浏览器中的需要爬取的网页页面上,右键——检查:
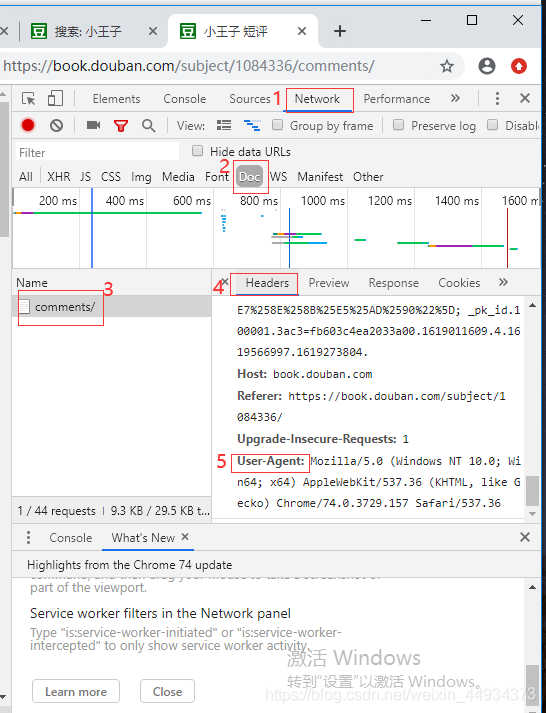
三、解决办法:在爬取代码中添加headers
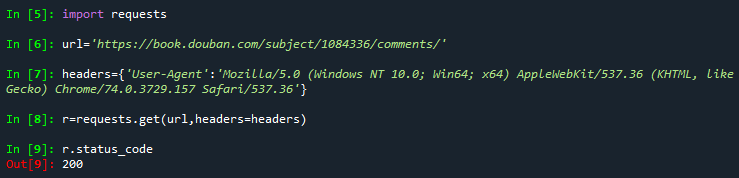
成功!
Part 2:在网站设置有反爬机制的情况下如何抓取内容:
场景仍然是豆瓣小王子的评论,代码如下:
import requests
url='https://book.douban.com/subject/1084336/comments/'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'}
r=requests.get(url,headers=headers) ##通过get()方法,加上要抓取的网页地址,就可以获得一个response对象,为了解决反爬机制,我们加上了header
#r=requests.get('https://book.douban.com/subject/1084336/comments/') 这行代码是没有反爬机制的写法
from bs4 import BeautifulSoup #导入BeautifulSoup库
soup=BeautifulSoup(r.text,'lxml') # 把之前get到的对象作为一个参数传入BeautifulSoup()函数,结果是生成了一个BeautifulSoup对象soup
pattern=soup.find_all('span','short') #然后通过find_all()方法寻找评论所在行,我们在源码中看到评论行的特征是标签span,属性内容是short。 find_all()方法返回的是一个列表。
for item in pattern: #需要对列表进行遍历,输出每一个对象的string属性
print(item.string)
运行结果:

一些其他的说明:
1、Requests库是Python的第三方库,是目前公认的爬取网页最好的库。
BeautifulSoup库:可以从HTML或XML文件中提取数据的Python库。
2、r的类型是response
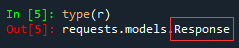
3、r.text的类型是字符串。
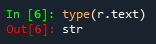
text属性可以自动推测文本编码并进行解码。
4、如果不使用find_all()函数,而是使用find(),则只会找到第一个标签的内容。
输出结果如下:

爬取短评成功!
Part 3 :如何获取豆瓣评分总和
代码如下:
import requests
import re #导入re库
url='https://book.douban.com/subject/1084336/comments/'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'}
r=requests.get(url,headers=headers)
#r=requests.get('https://book.douban.com/subject/1084336/comments/') 这行代码是没有反爬机制的写法
#上面的代码是为了解决反爬机制。
'''这段是输出评论的代码
from bs4 import BeautifulSoup
soup=BeautifulSoup(r.text,'lxml')
pattern=soup.find_all('span','short')
for item in pattern:
print(item.string)
'''
s=0
pattern_s=re.compile('<span class="user-stars allstar(.*)rating"')
#通过compile()方法把字符串编译成一个pattern实例
p=re.findall(pattern_s,r.text)
#再利用正则表达式模块中的findall()函数匹配源代码中的r.text模式,结果返回一个列表p
for star in p:
s+=int(star) #然后计算评分总和,这里还要注意把字符串类型转换为int类型
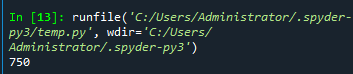
print(s) #输出总和
输出结果:
一些其他的说明:
1、re库:是python中处理正则表达式的标准库,主要用于字符串匹配。
2、源码中评分的标签形式为:
<span class="user-stars allstar50 rating" title="力荐"></span>
而我们使用compile方法时要写为这样:’<span class="user-stars allstar(.)rating"’
(.):代表的是评分
3、BeautifulSoup中find_all()有下划线;
re库中的findall()没有下划线。
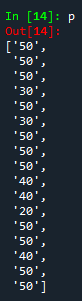
4、p是一个列表。
查看p的所有值输出如下:

















 7078
7078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









