







【类增量学习】ICCV 2019:Incremental Learning Using Conditional Adversarial Networks

论文地址:
https://ieeexplore.ieee.org/document/9009031
论文摘要:
使用深度神经网络的增量学习会遭受灾难性的遗忘。现有的方法通过存储旧的图像示例或只更新几个全连接层来缓解这个问题,然而,这需要很大的内存足迹,或损害了模型的可塑性。
本文提出了一种新的基于条件对抗网络的增量学习策略。我们的新策略允许我们使用内存高效的统计信息来存储旧知识,并微调卷积层和全连接层,以巩固新知识。
具体来说,我们提出了一个由三个部分组成的模型,即基子网、生成器和鉴别器:
- 基子网作为一种特征提取器,可以在大规模数据集上进行预训练,并在多个图像识别任务中共享;
- 以标记嵌入为条件的生成器旨在构造与旧数据具有相同分布的伪示例;
- 鉴别器结合了新数据的实例和旧数据分布生成的伪例来学习旧类和新旧类的表示;
通过对鉴别器和生成器的对抗训练,实现了多重连续增量学习。
与公共CIFAR-100和CUB-200数据集上的最先进技术进行比较表明,我们的方法在新旧类上都取得了最好的精度,同时需要相对较少的内存存储。
论文简介:
在许多分类任务中,我们经常会遇到在模型训练完成后出现新的类别的情况。在这些情况下,我们非常希望有一种学习方法,它可以在新类上逐步训练模型,同时仍然保持在旧类上的性能。
一种简单的方法是在对旧类进行训练后,微调新类上的模型。然而,这种方法存在一个称为灾难性遗忘的问题,即在对新类的原始模型进行微调后,对旧类的了解较少。
另一种简单的方法是在新旧数据上对模型进行重新训练。当需要快速训练或旧数据根本不再可用时,这再次变得不可行。
为了缓解灾难性遗忘问题,通常采用两种策略:
- 选择并存储旧图像数据的子集与新图像数据混合;
- 在增量学习过程中只更新完全连接的层;
对于第一种方法,通常使用到每个类的平均样本的距离来作为对样本进行排序的度量,如最近的方法 iCaRL 和 end-to-end 增量模型。不幸的是,这种操作严重削弱了训练模型在旧类上的性能,因为每个类的类内的变化都丢失了。
对于第二种方法,只更新全连接层,正如在最近的一项工作 FearNet 中所做的那样,确实可以防止在增量学习过程中DNN模型的剧烈变化,从而减少灾难性遗忘的机会。然而,它缺乏对DNN卷积层的表示学习,限制了模型的可塑性,导致新类的性能较差。
鉴于这些缺陷,我们的目标是设计一个系统,以更有效的方式存储旧数据,并允许在增量类学习中对更多的参数进行微调。具体来说,我们不存储原始图像的子集,而是存储旧类的特征嵌入的统计信息(即均值和协方差),并在增量类学习过程中对部分卷积层和全连接层进行微调。为此,我们提出了一个由基子网、生成器和鉴别器三个部分组成的条件对抗网络。
基子网将图像作为输入和输出的卷积特征图,我们称之为实例。生成器将从已保存数据统计数据的随机高斯分布中抽样的归一化嵌入作为输入,并输出卷积特征映射,我们称之为伪例。将实例和伪例混合在一起,训练了同时进行多类别分类和真假鉴别的鉴别器。鉴别器反过来可以参与基于鉴别嵌入的生成器的对抗性学习。在增量学习过程中,从基于旧类统计数据条件的生成器生成的伪示例中保留旧类信息。我们交替地训练生成器和鉴别器,以实现多个连续的增量学习。
综上所述,我们的主要贡献有三方面:
- 我们提出了一种新的利用条件生成对抗网络的增量学习策略,它可以有效地存储旧信息,同时适当地保持模型的可塑性;
- 我们构建了一个生成器,它以旧类的嵌入为条件,并产生感知卷积特征作为伪示例来重放旧类信息;
- 我们构造了一个鉴别器,它具有两个头,可以产生可区分多类别分类和真假实例识别的规范化嵌入;
相关工作:
我们求助于生成模型来实现我们的高效存储策略。其中一个密切相关的工作是生成对抗网络(GANs),其中引入了生成器和鉴别器的对抗训练。
Radford 等进一步开发了 GANs 到深度卷积GANs(DCGANs),并对卷积GANs的架构添加了一组约束,以使训练稳定。这些策略已被广泛应用于其他对抗网络,我们在训练对抗网络时也遵循类似的策略。
另一方面,Mirza 和 Osindero 将 GANs 扩展到一个条件版本,其中生成器以额外的信息为条件。额外的信息可以是任何类型的,例如类标签或来自其他模式的数据。
其中一些生成模型结合各种策略已经被探索用于增量学习。一种常见的方法是应用无条件GANs或仅基于类标签的GANs来生成图像示例,并执行伪预演以减轻灾难性遗忘。与此不同,我们的方法以标记嵌入向量为条件下的GANs作为生成器,并回放卷积特征图,更加合理、更有效。
具体实现:
基本框架:
我们提出了一种基于深度学习的增量学习策略,并将表示学习和增量分类器学习集成在一个框架中。具体来说,我们在设计新策略时遵循两个指导原则:
- 使用特征嵌入的统计数据来存储旧知识;
- 对卷积层和全连接层进行微调,以适应新知识;
与现有的方法只微调全连接层和/或存储来自旧类的原始图像相比,我们的方法有几个好处:
- 首先,与图像相比,特征嵌入具有更强的鉴别性和记忆效率;
- 其次,随着数据集规模的扩展,嵌入的统计数据进一步保持了每个类的存储消耗不变;
- 第三,当将嵌入统计数据与生成器相结合,生成可信度较高的伪例时,可以很大程度地保留旧的类信息;
- 最后,微调卷积层和全连接层增加了我们的模型在学习新类方面的灵活性;
在此基础上,我们设计了一个结合新图像数据和旧嵌入提取信息的系统来训练由卷积层和全连接层组成的鉴别器。
具体地说,我们提出了一个条件对抗网络 A = { B , G , D } A=\{B,G,D\} A={B,G,D} 来进行增量学习。
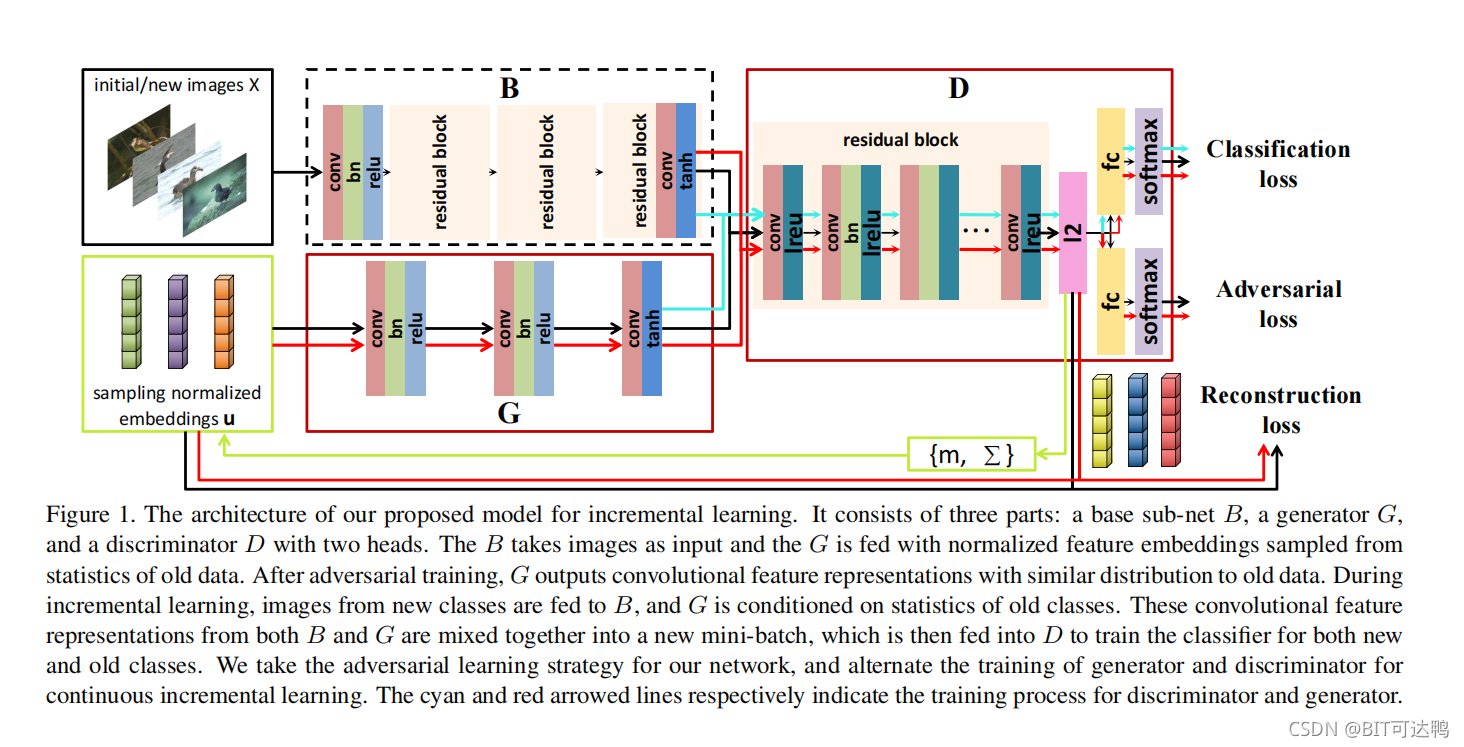
如图所示,其中有三个部分,即基子网 B B B、生成器 G G G 和鉴别器 D D D。
基子网 B B B 作为一个特征提取器,可以在大规模数据集上进行预训练。它的参数可以被大多数分类任务共享,因此在我们的增量类学习过程中是固定的。
生成器 G G G 以从旧类的统计数据中抽样的嵌入为条件,用于生成与基础网络 B B B 的输出相同的特征级的信息。
为了实现GANs中的对抗性学习,我们称 B B B 和 G G G 的输出分别为实例和伪例。
鉴别器 D D D 具有两个头:一个用于多类别分类,另一个用于真假实例识别。下面我们将详细介绍生成器 G G G、判别器 D D D 和增量学习策略。
生成器:
在本节中,我们的目标是设计一个子网络,它将旧类的嵌入作为输入,并生成与基础网络 B B B 的输出具有相同的分布和大小的特征。
一种可选的方案可以反转 D D D 的表示提取部分,并制作一个对称的解码器来重建中间的CNN特征(即 B B B 的输出)。为了训练该子网络,可以使用均方误差(MSE)重构损失,类似于FearNet中使用的自动编码器。
然而,我们想要获得的中间特征是空间特征,不能轻易地通过简单的MSE损失来重建。此外,完全反转表示提取的鉴别器架构也具有更高的计算复杂度。
相反,我们提出了生成与最大似然估计相同分布特征的问题。由于人们普遍认为GANs提供了最大似然估计的一个有吸引力的替代方案。因此,我们设计了一个类似于网络生成器的子网络,并以对抗的方式进行训练。在生成器的体系结构中,有几个分段串联的卷积层、批归一化层和非线性激活层。
虽然我们的生成器来自 GAN,但当应用于增量学习时,它就变得不同了:
- 首先,我们使用旧类的标记嵌入,而不是随机噪声作为输入,这意味着我们的生成器的条件是鉴别特征嵌入;
- 其次,我们区分了特征级的实例,而不是图像级的实例。这与图像转换任务中常用的知觉丧失具有相似的精神。
在我们的问题中,特征级的例子包含了更多关于图像的感知信息,因此为图像分类任务提供了更多的信息。
鉴别器:
在本节中,我们将描述多类别分类和对抗学习的判别器。具体来说,我们的目标是设计一个子网络,它具有两个功能,即区分多个类别的实例和辅助生成器的对抗性学习。
为了获得多类别分类的判别表示,我们从现有的公共 CNN 中继承了 D D D 的特征提取部分。也就是说,在一定的中间卷积层中,我们将一个典型的CNN进行分类,分为两部分,分别用于 B B B 和 D D D。为了实现这两个分类函数,我们在特征提取部分的顶部进一步添加了两个头。
注意,在最近关于GANs半监督学习的方法中,只添加了一个额外的类来识别伪例。这是因为他们使用的伪示例是未标注的,而我们的生成器是基于已标注的特征嵌入。
此外,当鉴别器参与生成器的对抗性学习时,我们还将 D D D 输出的特征嵌入输出约束为与 G G G 的输入向量相似。为了减少匹配误差,我们建议为嵌入添加一个 ℓ 2 \ell_{2} ℓ2 归一化层。
注意, D D D 的输出特征嵌入 v \mathbf{v} v 和 G G G 的输入向量 u \mathbf{u} u 都是归一化的单位向量。
损失函数:
我们对训练的整体损失是:
L = L a d v e r s a r y + L c l a s s i f i c a t i o n + L r e c o n s t r u c t i o n L=L_{a d v e r s a r y}+L_{c l a s s i f i c a t i o n}+L_{r e c o n s t r u c t i o n} L=Ladversary+Lclassification+Lreconstruction
对于 L a d v e r s a r y L_{a d v e r s a r y} Ladversary,我们解决了一个对抗性的最小-最大问题:
min θ G max θ D − l E [ log D θ D − l ( B θ B ( I ) ) ] + E [ log ( 1 − D θ D − l ( G θ G ( u ∣ m i , Σ i ) ) ) ] \begin{array}{rl} \min _{\theta_{G}} \max _{\theta_{D - l}} & \mathbb{E}\left[\log D_{\theta_{D-l}}\left(B_{\theta_{B}}(I)\right)\right]+ \\ & \mathbb{E}\left[\log \left(1-D_{\theta_{D-l}}\left(G_{\theta_{G}}\left(\mathbf{u} \mid m_{i}, \Sigma_{i}\right)\right)\right)\right] \end{array} minθGmaxθD−lE[logDθD−l(BθB(I))]+E[log(1−DθD−l(GθG(u∣mi,Σi)))]
其中 I I I 和 u \mathbb{u} u 分别为 B B B 的输入图像和 G G G 的输入嵌入, θ B \theta_{B} θB 和 θ G \theta_{G} θG 分别是 B B B 和 G G G 的参数, θ D − l \theta_{D - l} θD−l 表示使用二分类头(即识别真/假的实例)的 D D D 的参数, m i m_i mi 和 Σ i \Sigma_{i} Σi 是类 i i i 的均值和协方差
这是GANs的一个典型的优化目标,除了我们取 B B B 输出的卷积特征映射来替换 D D D 输入的真实图像,并对生成器 G G G 作为各类嵌入向量的统计条件。
对于 L c l a s s i f i c a t i o n L_{classification} Lclassification,我们最小化交叉熵损失:
min θ D − c − ( E [ log D θ D − c ( B θ B ( I ) ) ] + E [ log D θ D − c ( G θ G ( u ∣ m i , Σ i ) ) ] ) \begin{aligned} \min _{\theta_{D-c}}-&\left(\mathbb{E}\left[\log D_{\theta_{D-c}}\left(B_{\theta_{B}}(I)\right)\right]+\right.\\ &\left.\mathbb{E}\left[\log D_{\theta_{D-c}}\left(G_{\theta_{G}}\left(\mathbf{u} \mid m_{i}, \Sigma_{i}\right)\right)\right]\right) \end{aligned} θD−cmin−(E[logDθD−c(BθB(I))]+E[logDθD−c(GθG(u∣mi,Σi))])
θ D − c \theta_{D - c} θD−c 表示使用二分类头(即识别真/假的实例)的 D D D 的参数。
对于 L r e c o n s t r u c t i o n L_{r e c o n s t r u c t i o n} Lreconstruction,我们建议使用余弦距离来匹配卷积特征映射的嵌入,而不是直接测量卷积特征映射的重建:
L reconstruction = E [ 1 − cos ( u , D θ D ( G θ G ( u ∣ m i , Σ i ) ) ) ] L_{\text {reconstruction }}=\mathbb{E}\left[1-\cos \left(\mathbf{u}, D_{\theta_{D}}\left(G_{\theta_{G}}\left(\mathbf{u} \mid m_{i}, \Sigma_{i}\right)\right)\right)\right] Lreconstruction =E[1−cos(u,DθD(GθG(u∣mi,Σi)))]
其中 u \mathbf{u} u 是从均值 m i m_i mi 和协方差 Σ i \Sigma_{i} Σi 的高斯分布中采样的 G G G 的输入嵌入, D θ D ( G θ G ( u ) ) D_{\theta_{D}}\left(G_{\theta_{G}}(\mathbf{u})\right) DθD(GθG(u)) 是 u \mathbf{u} u 的新输出嵌入, c o s ( x , y ) cos(\mathbf{x},\mathbf{y}) cos(x,y) 计算两个向量之间的夹角的余弦。此外,由于嵌入向量是归一化的单位向量,因此在上式中的余弦距离现在可以等价地以内积的形式重写:
L reconstruction ′ = − E [ u T D θ D ( G θ G ( u ∣ m i , Σ i ) ) ] L_{\text {reconstruction }}^{\prime}=-\mathbb{E}\left[\mathbf{u}^{T} D_{\theta_{D}}\left(G_{\theta_{G}}\left(\mathbf{u} \mid m_{i}, \Sigma_{i}\right)\right)\right] Lreconstruction ′=−E[uTDθD(GθG(u∣mi,Σi))]
学习算法:

我们研究了新类样本不断出现的增量学习场景。
给定一个来自旧类的初始图像集 X 0 X_{0} X0,我们首先需要训练一个原始模型。在训练过程中,在大规模ImageNet数据集上预训练的基子网 B B B 被固定,只对鉴别器 D D D 进行微调。经过训练 D D D 后,我们从 D D D 中收集归一化的嵌入集,并计算其统计量 { m , Σ } 0 \{m,\Sigma\}_{0} {m,Σ}0,其中包含每个类的平均向量和协方差矩阵。然后结合 X 0 X_{0} X0 和从统计数据中采样的归一化嵌入 { u } 0 \{\mathbf{u}\}_{0} {u}0,我们使用之前提到的损失函数以对抗性的方式训练 G G G 和 D D D。使用新的 G G G 和 D D D,我们更新统计数据 { m , Σ } 0 \{m,\Sigma\}_{0} {m,Σ}0 和相应的采样嵌入 { u } 0 \{\mathbf{u}\}_{0} {u}0。
当新类 X 1 X_{1} X1 的图像数据到达时,我们将旧的嵌入 { u } 0 \{\mathbf{u}\}_{0} {u}0 混合,以重新训练 D D D。利用新的图像和旧的嵌入,我们可以得到新的统计数据 { m , Σ } 0 , 1 \{m,\Sigma\}_{0,1} {m,Σ}0,1 和新的采样嵌入 { u } 0 , 1 \{\mathbf{u}\}_{0,1} {u}0,1。然后将新的采样嵌入与 X 1 X_{1} X1 一起混合,然后再次交替训练 G G G 和 D D D,并进一步更新了统计数据和采样嵌入。
每次出现来自新类(例如, { X 2 , ⋯ , X t } \{X_2,\cdots,X_t\} {X2,⋯,Xt})的新图像数据时,我们都通过反复训练生成器和鉴别器来重复上述步骤,就能实现多重连续的增量学习。
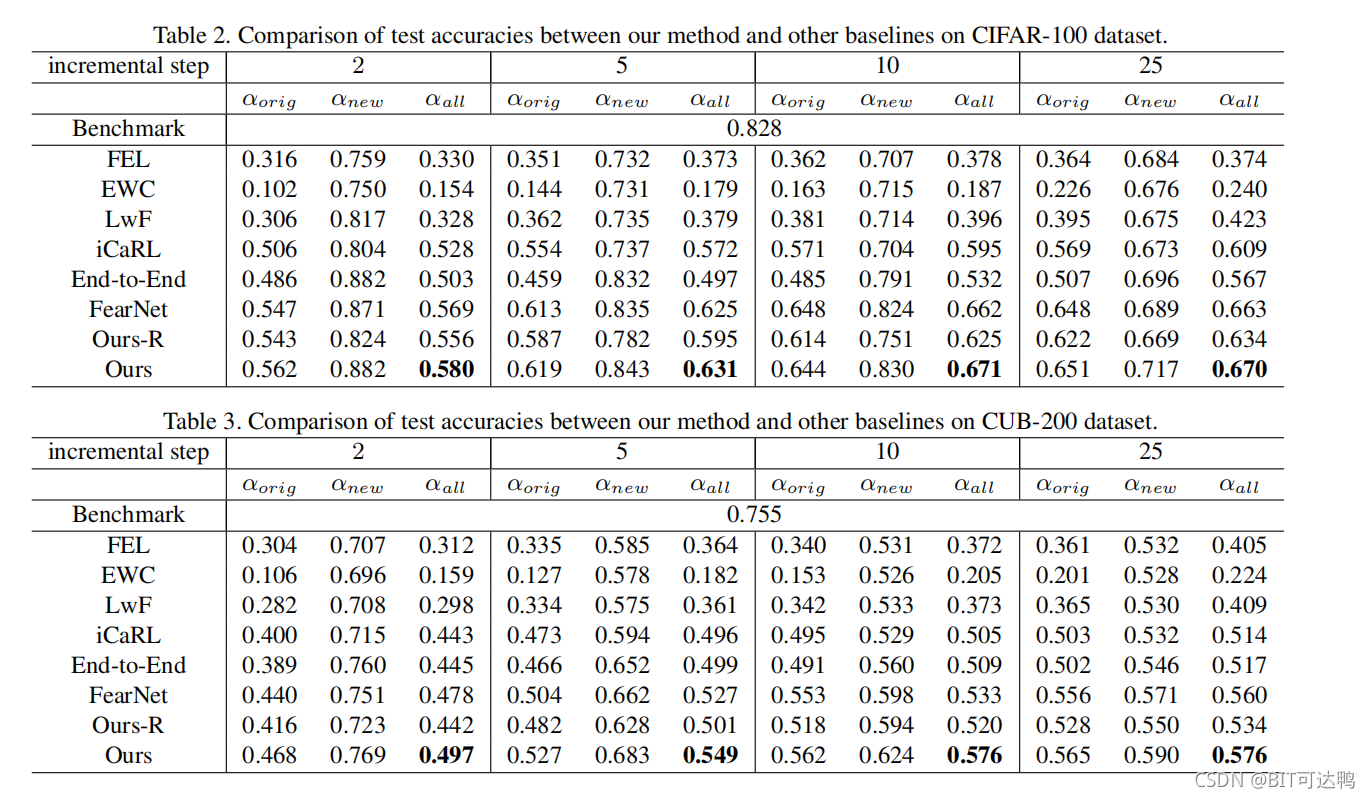
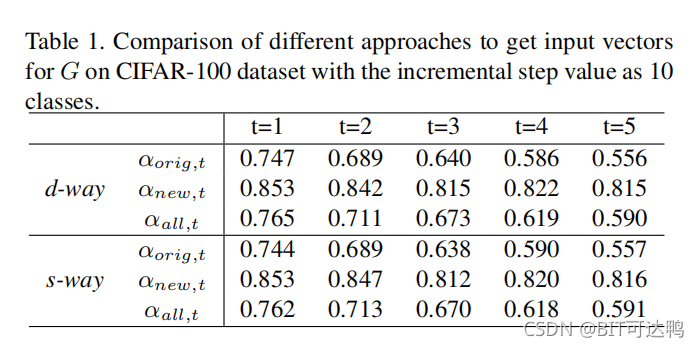
实验结果:


















 2161
2161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











