






摘要
我们提出了一个分析人类情感状态的多模态数据集。记录32名参与者的脑电图(EEG)和周围生理信号,每个人观看40段一分钟长的音乐视频片段。参与者根据唤醒,效价,喜欢/不喜欢,主导和熟悉程度对每个视频进行评分。在32位参与者中,有22位还录制了正面面部视频。提出了一种新颖的刺激选择方法,该方法通过使用来自last.fm网站的情感标签进行检索,视频高亮检测和在线评估工具来进行。提供了对实验过程中参与者评分的广泛分析。脑电信号频率和参与者的评分之间的相关性进行了调查。提出了使用脑电图,周围生理信号和多媒体内容分析方法对唤醒,效价和喜欢/不喜欢的等级进行单次试验的方法和结果。最后,对来自不同模态的分类结果进行决策融合。该数据集已公开提供,我们鼓励其他研究人员将其用于测试他们自己的情感状态估计方法。
关键词——情感分类,脑电图,生理信号,信号处理,模式分类,情感计算。
1 引言
情绪是一种有意识和/或无意识的物体或情况感知触发的心理生理过程,通常与情绪,气质,性格和性格以及动机有关。情绪在人类交流中起着重要的作用,可以通过情绪词汇进行口头表达,也可以通过表达非语言提示(例如语音语调,面部表情和手势)来表达。大多数当代人机交互(HCI)系统都无法解释此信息,并且缺乏情感智能。换句话说,他们无法识别人类的情绪状态,无法使用这些信息来决定要执行的适当动作。情感计算的目的是通过检测人机交互过程中出现的情感提示并合成情感反应来填补这一空白。
在多媒体信息检索中,用相关的、可靠的、有鉴别能力的标签来描述多媒体内容是非常重要的。多媒体的情感特征是描述多媒体内容的重要特征,可以通过情感标签来表现。内隐情感标记是指不费力地产生主观和/或情感标记。利用情感信息对视频进行隐式标注,可以帮助推荐和检索系统提高其性能[1]-[3]。记录当前数据集的目的是创建一个自适应的音乐视频推荐系统。在我们提出的音乐视频推荐系统中,用户的身体反应将被转化为情绪。用户观看音乐视频片段时的情绪会帮助推荐系统首先了解用户的喜好,然后推荐符合用户当前情绪的音乐片段。
该数据库探索了通过向不同用户播放音乐视频来对情感维度进行分类的可能性。据我们所知,对这种刺激的反应(音乐视频剪辑)之前从未被探索过,这一领域的研究主要集中在图像、音乐或非音乐视频片段[4]、[5]。在自适应音乐视频推荐系统中,通过对类似性质的音乐视频的生理反应训练的情感识别器能够更好地实现其目标。
各种离散的情绪分类已经被提出,例如Ekman和Friesen[6]提出的六种基本情绪,Parrot[7]提出的情绪树形结构。情绪的维度尺度也被提出,如Plutchik的情绪轮[8]和Russell的效价唤醒度[9]。在这项工作中,我们使用罗素的效价唤醒度[表,广泛用于研究影响,定量描述情绪。在这个尺度中,每一种情绪状态都可以被放置在一个二维平面上,唤醒度和效价是水平和垂直轴。虽然唤醒度和效价解释了大多数情绪状态的变化,但第三维度的支配性也可以包括在[9]模型中。唤醒度的范围从不活跃的(如不感兴趣的,无聊的)到活跃的(如警惕的,兴奋的),而效价的范围从不愉快的(如悲伤的,紧张的)到愉快的(如高兴的,高兴的)。支配度的范围从一种无助和软弱的感觉(没有控制)到一种强大的感觉(控制一切)。对于这些尺度的自我评估,我们使用著名的自我评估人体模型(SAM)[10]。
情感评估通常是通过分析用户的情感表达和/或生理信号。情感表达是指任何可观察到的语言和非语言行为,沟通情感。情感评估迄今为止,大部分的研究都集中在面部表情和演讲的分析来确定一个人的情绪状态。生理信号也被认为是包括情感信息可用于情感评估但是他们得到了更少的关注。他们组成的信号来自中枢神经系统(CNS)和周围神经系统(PNS)。
最近在情绪识别方面的进展推动了包含不同方式的情绪表达的新数据库的创建。这些数据库主要包括语音、可视或视听数据(如[11]-[15])。视觉形态包括面部表情和/或身体姿势。音频情态包括不同语言中拟态的或真实的情感话语。许多现有的可视化数据库只包含摆拍或有意表达的情感。
Healey[16],[17]记录了最早的情感性生理数据集之一。她记录了24名在波士顿地区开车的参与者,并根据司机的压力水平对数据集进行了注解。24位参与者的回答中有17位是公开的。她的记录包括心电图(ECG)、手和脚的皮肤电反应(GSR)、右侧斜方肌的肌电图(EMG)和呼吸模式。
据我们所知,唯一公开的包括生理反应和面部表情的多式情感数据库是enterface 2005情感数据库和MAHNOB HCI[4]、[5]。第一次是由Savran等人记录的[5]。这个数据库包括两个集。第一组包括脑电图(EEG)、周边生理信号、功能性近红外光谱(fNIRS)和来自5名男性参与者的面部视频。第二个数据集只有16名男女参与者的面部视频和fNIRS。这两个数据库都记录了人们对来自国际情感图像系统(IAPS)[18]的情感图像的自发反应。在[13],[19]中可以找到对情感性视听数据库的广泛回顾。MAHNOB HCI数据库[4]由两个实验组成。记录了30人的脑电图、生理信号、眼神、声音和面部表情等反应。第一个实验是观看从电影和在线资料库中提取的20个情感视频。第二个实验是标签一致性实验,在这个实验中,先给参与者看有人类动作的图片和短视频,没有标签,然后再给参与者看一个显示的标签。标签是正确的还是错误的,参与者对显示的标签的一致性进行了评估。
在生理信号[16]、[20]-[24]的情绪识别领域已经发表了大量的研究成果。在这些研究中,只有少数使用视频刺激取得了显著的结果。Lisetti和Nasoz使用生理反应来识别电影场景[23]的情绪。电影场景被选择来引出六种情绪,即悲伤、娱乐、恐惧、愤怒、沮丧和惊讶。对于这六种情绪的识别,他们获得了84%的高识别率。然而,这种分类是基于对视频中预先选择的与高度情绪化事件相关的片段的信号分析。
在多媒体内容的隐性情感标注方面已经做了一些努力。Kierkels等人提出了一种利用周围生理信号进行多媒体个性化情感标注的方法。参与者观看视频时的情感效价和唤醒水平是通过使用线性回归[26]从生理反应中计算出来的。一个片段的量化唤醒和效价随后被映射到情感标签上。该映射允许基于关键字查询检索视频剪辑。到目前为止,这种新方法的精度较低。
Yazdani等人[27]提出使用基于P300诱发电位的脑机接口(BCI),用Ekman六种基本情绪之一[28]对视频进行情感标记。他们的系统接受了8名参与者的培训,然后在另外4人身上进行了测试。他们在选择标签方面达到了很高的准确性。然而,在他们提出的系统中,BCI只是代替了显式表达情感标签的接口,也就是说,该方法并不使用参与者的行为和心理生理反应来隐式地标记多媒体项目。
除了使用行为线索的内隐标记外,多项研究还使用多媒体内容分析(MCA)来自动对视频进行情感标记。Hanjalic等人在[29]中介绍了“个性化内容交付”,这是情感索引和检索系统中一个很有价值的工具。为了在视频中表现情感,他们首先根据视频和音频内容与价值激发空间的关系来选择特征。然后,结合这些特征来估计在这个空间中产生的情绪。虽然效价-唤醒度可以单独用于索引,但他们通过遵循时间模式将这些值结合起来。这可以用来确定影响曲线,这对于提取电影或体育视频中的视频亮点非常有用。
Wang和Cheong[30]使用音频和视频特征对电影场景引发的基本情绪进行分类。将音频信号分为音乐信号、语音信号和环境信号,分别进行处理,形成听觉情感特征向量。将每个场景的听觉情感向量与关键灯光、视觉刺激等基于视频的特征融合,形成场景特征向量。最后,利用场景特征向量对电影场景进行分类和情感标记。
Soleymani等人提出了一个场景情感表征使用贝叶斯框架[31]。首先用线性回归法确定每个镜头的唤醒和效价。然后,除了每个场景的内容特征外,使用唤醒值和效价值将每个场景分为三类,即平静、兴奋、积极和兴奋、消极。贝叶斯框架能够结合电影类型和最后场景或时间信息的预测情绪来提高分类精度。
从声学特征[32]-[34]对音乐情感表征的研究也有很多。节奏、速度、梅尔频率倒谱系数(MFCC)、音高、过零率是用来描述音乐影响的常见特征。
在[35]中对当前工作进行了初步研究。在这项研究中,6名参与者观看了20个音乐视频,记录了他们的脑电图和生理信号。参与者对唤醒和效价水平进行评级,每个视频的脑电图和生理信号被分为低唤醒/高唤醒/效价水平。
在当前的工作中,音乐视频剪辑被用作视觉刺激来激发不同的情感。 为此,使用新颖的刺激选择方法收集了相对较大的一组音乐视频剪辑。 然后进行主观测试以选择最合适的测试材料。 对于每个视频,都会自动选择一分钟的亮点。 32名参与者参加了该实验,并观看了40个精选的音乐视频,并记录了他们的脑电图和周围生理信号。 参与者根据唤醒度,效价,喜欢/不喜欢,支配和熟悉程度对每个视频进行评分。 对于22位参与者,还录制了正面面部视频。
本文旨在介绍这一公共数据库。该数据库包含所有记录的信号数据、一部分参与者的正面视频和参与者的主观评分。还包括最初的在线主观注释的主观评分和使用的120个视频列表。由于许可证问题,我们不能包括实际的视频,但YouTube链接包括在内。表1给出了数据库内容的概述。

据我们所知,这个数据库拥有最多的参与者,在公共数据库中,从生理信号分析自发的情绪。此外,它是唯一一个使用音乐视频作为情感刺激的数据库。
我们对参与者的评分和脑电图信号与评分之间的相关性进行了广泛的统计分析。对脑电图、周围生理信号和MCA的初步单次试验分类结果进行了介绍和比较。最后,利用融合算法将各模态的结果进行融合,得到更稳健的决策。
这篇论文的布局如下。第二部分详细描述了刺激源的选择过程。实验设置将在第3节中介绍。第4节提供了一个统计分析的评级,由参与者在实验和验证我们的刺激选择方法。在第5部分,脑电图频率和参与者评分之间的相关性被展示出来。第6节给出了单次试验分类的方法和结果。这项工作的结论见第7节。
2 刺激的选择
实验中使用的刺激物是分几个步骤选择的。首先,我们选择了120个初始刺激,其中一半是半自动选择的,另一半是手动选择的。然后,为每个刺激点设置一分钟的亮点部分。最后,通过一个基于网络的主观评价实验,选择40个最终刺激。下面将解释这些步骤。
2.1初始刺激选择
激发测试参与者的情绪反应是一项艰巨的任务,而选择最有效的刺激材料至关重要。我们在此提出一种半自动化的刺激选择方法,其目标是最小化由手动刺激选择引起的偏差。
使用Last.fm音乐发烧友网站从120个最初选择的刺激中选择了60个。Last.fm允许用户跟踪他们的音乐收听习惯并接收有关新音乐和新事件的建议。 另外,它允许用户将标签分配给单独的歌曲,从而创建标签的民俗学。 许多标签带有情感含义,例如“压抑”或“激进”。Last.fm提供了一种API,允许人们检索标签和加标签的歌曲。
从[7]中选取了情感关键词列表,并将其扩展为包括词尾变化和同义词,产生了304个关键词。 接下来,对于每个关键字,在Last.fm数据库中找到相应的标签。 对于每个发现的情感标签,选择了最经常用该标签标记的十首歌曲。 共产生1084首歌曲。
效价-唤醒度空间可细分为四个象限,即低唤醒/低效价(LA/LV),低唤醒/高效价(LA/HV),高唤醒/低效价(HA/LV)和高唤醒/高效价(HA/HV)。为了确保诱发情绪的多样性,根据以下标准从1084首歌曲中为每个象限手动选择了15首歌曲:
标签是否准确地反映了情感内容?
根据这一标准被主观拒绝的歌曲包括仅仅因为歌曲标题或歌手名字与标签相对应而被标记的歌曲。此外,在某些情况下,歌词可能与标签相对应,但歌曲的实际情感内容是完全不同的(例如,关于悲伤主题的快乐歌曲)。
这首歌有音乐录影带吗?
歌曲的音乐视频会自动从YouTube上检索,必要时还会手动更正。然而,许多歌曲没有音乐视频。
这首歌适合在实验中使用吗?
由于我们的测试参与者大多是欧洲学生,因此我们为目标人群选择了最有可能引起情感的歌曲。 因此,主要选择了欧洲或北美艺术家。
除了使用上述方法选择的歌曲外,我们还手动选择了60个刺激视频,并为唤醒/价空间的每个象限选择了15个视频。这里的目标是选择那些有望对每个象限产生最清晰情感反应的视频。人工选择和使用情感标签的选择相结合,产生了一个包含120个候选刺激视频的列表。
2.2一分钟亮点检测
对于120个最初选择的音乐视频中的每一个,提取一个用于实验的1分钟片段。为了提取具有最大情感内容的片段,提出了一种情感突出显示算法。
Soleymani等人[31]使用线性回归方法计算电影中每一个镜头的唤醒。在他们的方法中,使用基于内容特征的线性回归来计算镜头的唤醒和效价。用于唤醒估计的信息特征包括声音信号的响度和能量、运动成分、视觉刺激和拍摄持续时间。用同样的方法计算效价。还有一些其他的内容特性,如颜色变化和关键光照,已经被证明与效价相关[30],本工作中使用的内容特性的详细描述见第6.2节。
为了用回归法找到最佳的唤醒和效价估计权重,回归者在[31]中给出的数据集中对21部带注释电影的所有镜头进行训练。线性权重通过Tipping[36]提供的RVM工具箱中的相关向量机(RVM)计算。RVM在训练过程中能够拒绝非信息性特征,因此没有进一步的特征选择用于唤醒和效价的确定。
然后将音乐视频分割成一分钟的片段,片段之间重叠55秒。提取内容特征,为回归分析提供输入。第i节ei的情绪突出评分采用以下公式计算:
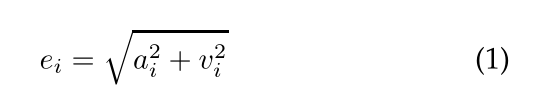
唤醒(ai)和效价(vi)被放在中心位置。因此,情绪亮点得分(ei)越小,越接近中性状态。在每个视频中,选取情绪高潮得分最高的一分钟长片段进行实验。对于一些片段,自动情感高亮检测被手动覆盖。这只针对那些特别具有歌曲特色、为公众所熟知、最有可能引发情感反应的歌曲。在这些情况下,选择一分钟的突出部分,以便包括这些片段。
根据120个1分钟的音乐视频片段,实验中使用的40个视频的最终选择是根据志愿者的主观评分做出的,如下一节所述。
2.3在线主观标注
从最初收集的120个刺激视频中,使用基于web的主观情绪评估界面选择最后40个测试视频片段。参与者观看了音乐视频,并在一个离散的9点量表上对其进行了价格、唤醒和支配的评分。界面截图如图1所示。每个参与者观看了他/她想要的视频,并且可以随时结束评分。剪辑的顺序是随机的,但优先选择被最少参与者评分的剪辑。这确保了每个视频的收视率相同(每个视频收集14-16个评估)。确保参与者从未看过同一段视频两次。
在120个视频被至少14名志愿者分别打分后,最后选出40个供实验使用的视频。为了最大限度地激发情绪,我们选择了那些志愿者评分最高,同时变化较小的视频。为此,对于每个视频x,我们通过平均评分除以标准差(μx/σx)来计算标准化唤醒和价格得分。
然后,对于规范化的价格唤醒空间中的每个象限,我们选择了最接近该象限的极端角落的10个视频。图2示出了以绿色突出显示的每个视频和所选视频的分级的得分。该视频的评分是最接近每个象限的极端角落明确提到。在40个选定的视频中,有17个是通过Last.fm情感标签选择的,这表明可以通过这种方法选择有用的刺激。
 图1.主观情绪评估Web界面的屏幕截图
图1.主观情绪评估Web界面的屏幕截图
3实验设置
3.1材料与设置
实验是在两个受控照明的实验室环境中进行的。 使用Biosemi ActiveTwo系统4在专用的记录PC(奔腾4,3.2 GHz)上记录脑电图和周围生理信号。 使用专用的刺激PC(奔腾4,3.2 GHz)显示刺激,该PC直接将同步标记发送到记录PC。 为了演示刺激并记录用户的评分,使用了Neurobehavioral系统5的“演示”软件。 音乐视频显示在17英寸的屏幕上(1280×1024,60 Hz),并且为了最大程度地减少眼球运动,所有视频刺激均以800×600的分辨率显示,约占屏幕的2/3。 受试者坐在离屏幕约1米的地方。 使用立体声飞利浦扬声器,并且将音乐音量设置为相对较大的音量,但是在实验之前,每个参与者都被询问音量是否舒适,并在必要时进行调整。
使用32个有源AgCl电极(根据国际10-20系统放置)以512 Hz的采样率记录EEG。 还记录了13个外围生理信号(将在6.1节中进一步讨论)。 此外,对于32位参与者中的前22位,使用Sony DCR-HC27E消费级便携式摄像机以DV质量录制了正面面部视频。 面部视频未在本文的实验中使用,但已与其余数据一起公开提供。 图3示出了用于采集周围生理信号的电极放置。

图2.在线评估中每个视频的分级的μx/σx值。选择用于实验的视频以绿色突出显示。对于每个象限,最极端的视频都有详细的歌曲标题和视频截图。
3.2实验协议
32名健康参与者(50%女性),年龄在19岁到37岁之间(平均年龄26.9岁),参加了实验。在实验之前,每个参与者都要签署一份同意书并填写一份问卷。接下来,给他们一组阅读说明,告诉他们实验方案和用于自我评估的不同量表的含义。一名实验者也在场回答任何问题。当指示清楚后,被试被领进实验房间。在放置传感器并检查其信号之后,参与者进行了一次模拟试验,以熟悉系统。在这个没有记录的试验中,播放了一个简短的视频,然后参与者进行了自我评估。接下来,实验者开始记录生理信号并离开房间,然后按下键盘上的一个键开始实验。
实验以2分钟的基线记录开始,在此期间向参与者展示一个固定十字架(在此期间要求参与者放松)。然后,40个视频在40个试验中呈现,每个试验包括以下步骤:
1)显示当前试验编号的2秒屏幕,告知受试者试验进展情况。
2) 5秒基线记录(注视交叉)。
3)音乐视频1分钟显示。
4)对唤起、情感、喜好和支配能力的自我评估。
20次试验后,参与者休息了一小会儿。在休息期间,他们会得到一些饼干和不含咖啡因、不含酒精的饮料。然后实验者检查了信号的质量和电极的位置,参与者被要求继续第二部分的测试。图4显示了实验开始前不久的参与者。

图3.周边生理传感器的放置。电极用于记录EOG和4的肌电图(大颧肌和斜方肌)。此外,测量GSR、血容量压(BVP)、体温和呼吸。
3.3参与者自我评估
在每个试验的最后,参与者对他们的兴奋程度、情感、喜好和支配能力进行了自我评估。使用自评人体模型(SAM)[37]对量表进行可视化处理(见图5)。人体模型显示在屏幕的中间,数字1-9打印在下面。参与者将鼠标严格水平移动到数字下方,然后点击以显示他们的自我评估水平。参与者被告知,他们可以点击数字下面或数字之间的任何地方,从而使自我评估成为一个连续的量表。
 图4.实验前不久的一名参与者。
图4.实验前不久的一名参与者。

图5.用于自我评估的图像。 从顶部开始:Valence SAM,Arousal SAM,Dominance SAM,喜欢。
效价范围从不快乐或悲伤到快乐或快乐。唤醒量表的范围从平静或无聊到刺激或兴奋。支配性量表的范围从顺从(或“无控制”)到支配(或“有控制,有权力”)。第四个量表要求参与者对视频的个人喜好。最后一个量表不应该与效价量表相混淆。这项测试询问的是参与者的品味,而不是他们的感受。例如,喜欢让人感到悲伤或愤怒的视频是可能的。最后,在实验结束后,参与者被要求对每首歌的熟悉程度打分,从1分(“实验前从未听过”)到5分(“非常熟悉这首歌”)。
4主观评分分析
在这一节中,我们描述了情感刺激对参与者的主观评分的影响。首先,我们将提供描述性统计的记录评分喜欢,效价,唤醒,支配和熟悉。其次,我们将讨论不同评级之间的协变。
选择刺激以在效价-唤醒度空间的四个象限(LALV,HALV,LAHV,HAHV)中诱发情绪。 来自这四个影响的诱发条件的刺激通常会导致选择目标时的目标情绪的激发,从而确保掩盖了效价-唤醒度平面(AV平面)的大部分(见图6)。Wilcoxon符号秩检验表明,低和高唤醒度刺激引起不同的效价等级(p <.0001和p <.00001)。同样,低效价和高效价刺激会引起不同的唤醒度等级(p <.001和p <.0001)。

图6.所示四种情况(LALV、HALV、LAHV、HAHV)刺激在唤醒–效价平面上的平均位置。喜欢是由颜色编码的:暗红色代表低喜欢,明黄色代表高喜欢。显性由符号大小编码:小符号代表低显性,大符号代表高显性。
情绪激发在高刺激条件下效果特别好,对各个刺激产生相对的最高效价评级。低激发条件下的刺激在激发强烈的效价反应方面不太成功。此外,根据在线研究,LAHV病情的某些刺激引起的觉醒高于预期。有趣的是,这导致效价-唤醒度平面上的刺激呈C形,这在国际情感图片系统(IAPS)[18]和国际情感数字声音系统(IADS)[38]的有效评级中也观察到,表示通常很难以高效价但低唤醒度的方式来诱导情绪。每个条件下各个评分的分布(见图7)显示,条件之间的差异很大,这是由刺激之间和参与者之间的变化引起的,可能与刺激特征或音乐品味,总体情绪或音阶的个体差异有关解释。但是,条件之间在效价和唤醒度方面的显着差异反映了目标情感状态的成功诱导(参见表2)。
表2
不同情感激发条件下的喜好度(1-9分)、效价(1-9分)、唤起度(1-9分)、支配度(1-9分)、熟悉度(1-5分)的平均值(和标准差)。

不同规模和条件下的评级分布表明评级之间存在复杂的关系。我们探讨了参与者不同量表的平均相互关系(参见表3),因为它们可能表明习惯或疲劳的可能混杂或有害影响。我们观察到喜好与效价之间以及优势与效价之间存在高度正相关。貌似,在不暗示任何因果关系的情况下,人们喜欢音乐,这种音乐给了他们积极的感觉和/或授权的感觉。唤醒度与主导之间,唤醒度与喜好之间存在中等正相关。熟悉程度与喜好和效价呈正相关。正如上面已经观察到的那样,效价和唤醒度的量表不是独立的,但是它们的正相关性很低,这表明参与者能够区分这两个重要的概念。刺激顺序对喜好和支配等级的影响很小,与其他等级没有显着关系,这表明习惯和疲劳的影响保持在可接受的最低水平。
综上所述,情感诱导在总体上是成功的,尽管低效价条件在一定程度上受到中等效价反应和较高唤醒的影响。观察到的高尺度的相互关联仅限于配价与喜好和支配的关系,这可能在音乐情感的语境中被期待。其余量表之间的相互关系强度较小或中等,表明量表概念被参与者很好地区分。
5脑电图与评分的相关性
为了研究主观评分与脑电图信号的相关性,将脑电图数据进行共同平均引用,降采样至256 Hz,利用EEGlab 6工具箱用2 Hz的切换频率进行高通滤波。我们用盲源分离技术去除了人工制品。然后,提取每个试验(视频)最后30秒的信号进行进一步分析。为了校正与刺激无关的功率随时间的变化,将每个视频前5秒的脑电图信号提取为基线。

图7.四种情感诱发条件(LALV、HALV、LAHV、HAHV)的主观评分(L-综合评分、V-效价、A-唤起、D -优势度、F-熟悉度)的分布。
表4
与量表相关性显著的电极(*=p < .01, **=p < .001)。还显示了主相关系数(¯R)、最负相关系数(R−)和最正相关系数(R +)的平均值。

表3
所有40个刺激的效价、唤醒度、喜好、支配、熟悉程度和呈现顺序(即时间)之间的主观相关。根据Fisher方法,显著相关(p<.05)由星星表示。

采用Welch方法提取试验频率和3 ~ 47Hz之间的基线,窗口为256个样本。然后从试验功率中减去基线功率,得到相对于刺激前时期的功率变化。这些功率的变化在(3 - 7赫兹)、(8 - 13赫兹)、(14 - 29赫兹)和(30 - 47赫兹)的频带上取平均值。对于相关统计,我们计算了权力变化和主观评分之间的Spearman相关系数,并计算了左尾(正)和右尾(负)相关检验的p值。我们分别对每个参与者进行了这项工作,假设[39]是独立的,那么每个相关方向(正/负)、频带和电极的32个p值将通过Fisher’s方法[40]合并为一个p值。
图8显示了显著(p < .05)相关电极的(平均)相关性。下面我们将只报告和讨论p < .01时显著的影响。表4列出了各种影响。
对于唤醒度,我们发现theta,alpha和gamma波段呈负相关。 较高唤醒度的中央α功率降低与我们较早的先导研究[35]的发现相符,并且在[41],[42]之前已经报道了α功率与一般唤醒水平之间存在反比关系。

图8:效价,唤醒度和总体评分与theta(4-7 Hz),alpha(8-13 Hz),beta(14- 29 Hz)和gamma(30-47 Hz)。突出显示的传感器与额定值显着相关(p <.05)。
效价显示出与脑电信号的最强相关性,并且在所有分析的频带中都发现了相关性。在低频theta和alpha中,效价的增加导致功率的增加。这与试点研究的结果一致。这些影响在枕骨区域,因此在视觉皮层上的位置,可能表明这些影响是相对的失活或自上而下的抑制,这是由于参与者专注于愉悦的声音所致[43]。对于β频段,我们发现在飞行员中也观察到了中央下降,并且枕骨和右颞骨的功率增加。 [44],对右侧颞部部位的增强的β能力与积极的情绪自我诱导和外部刺激有关。类似地,[45]报道了价态和高频功率的正相关,包括前颞脑来源的β和γ带。相应地,我们观察到左,尤其是右颞伽马力的显着增加。但是,应该提到的是,EMG(肌肉)活性在高频中也很突出,尤其是在前电极和颞电极上[46]。
在所有分析的频带中都发现了相似的相关性。对于θ和α屈光力,我们观察到左额中央皮层的增大。喜欢可能与进场动机有关。然而,观察到较高的喜好导致左α力量增加与左额叶激活的发现相冲突,导致该区域的α降低,这通常被报道为与进场动机有关的情绪[47]。当考虑到一些不喜欢的片段很可能引起愤怒的感觉(由于不得不听它们,或者仅仅是由于歌词的内容)而引起的矛盾时,这种矛盾可能会得到解决,这也与进场动机有关,因此可能导致alpha向左减少。在β和γ谱带中发现的正确的颞部增大与所观察到的效价相似,应谨慎行事。通常,图8中所示的效价和喜好相关性的分布看起来非常相似,这可能是上述量表之间高度相关的结果。
综上所述,我们可以指出,观察到的相关性部分符合试点研究和其他研究中探索情感状态的神经生理学相关性的观察结果。因此,在多模态音乐刺激的背景下,它们可能被视为情感状态的有效指标。然而,平均相关性很少大于±0.1,这可能是由于参与者之间在脑激活方面的高变异性造成的,因为在相同的电极/频率组合下,在给定的尺度相关性下观察到±0.5之间的个体相关性。这种高的参与者间变异性的存在证明了参与者特有的分类方法是正确的,正如我们所使用的,而不是针对所有参与者的单一分类器。
6单项试验分类
在本节中,我们将介绍视频单次分类的方法和结果。采用脑电图信号、周围生理信号和MCA三种不同的模式进行分类。所有模式的条件保持不变,只是特征提取步骤不同。
提出了三种不同的二元分类问题:低/高唤醒的分类,低/高效价和低/高喜好分类。 为此,将实验期间参与者的评分作为基本事实。 这些量表中的每个量表的等级都分为两类(低和高)。在9点评分量表上,阈值仅位于中间。 请注意,对于某些主题和规模,这会导致班级不平衡。 为了说明类别的不平衡程度,每个等级量表中属于高等级的视频所占百分比的平均值和标准差(超出参与者)为引起59%(15%),价57%(9%) 喜欢67%(12%)。
鉴于此问题,为了可靠地报告结果,我们报告了F1分数,该分数通常用于信息检索中,并且考虑了类平衡,这与单纯的分类率相反。 此外,我们使用朴素贝叶斯分类器,这是一种简单且可概括的分类器,能够处理小型训练集中的不平衡类。
首先,为每个试验(视频)提取给定模态的特征。 然后,对于每个参与者,F1量度用于评估“留一法”交叉验证方案中的情感分类表现。 在交叉验证的每个步骤中,一个视频用作测试集,其余视频用作训练集。 我们使用Fisher线性判别式J进行特征选择:

µ和σ的平均值和标准偏差特性f。我们计算每个特性这一标准,然后应用一个阈值选择最大限度地区别对待的。这个阈值是根据经验确定的0.3。
使用高斯朴素贝叶斯分类器将测试集分类为低/高唤醒,效价或喜好。 朴素贝叶斯分类器G假定特征的独立性,并由下式给出:

其中F是要素集,C是类。 通过假设特征的高斯分布并从训练集中对其建模来估计p(Fi=fi|C=c)。
接下来的部分解释了EEG和周围生理信号的特征提取步骤。第6.2节介绍了MCA分类中使用的特性。在第6.3节中,我们解释了用于结果决策融合的方法。最后,第6.4节给出了分类结果。
6.1脑电图及周边生理特征
目前大多数关于情绪[48]、[49]的理论都认为,生理活动是情绪的重要组成部分。例如,一些研究已经证明了与基本情绪[6]相关的特定生理模式的存在。
围神经系统信号记录如下:GSR,呼吸幅度,皮肤温度,心电图,血容量体积描记器、颧肌和斜方肌的肌肉的肌电图,眼电图(小城镇)。GSR提供皮肤的电阻的测量定位两个电极的远端趾骨和食指中间。这种阻力减少由于增加的汗水,这通常发生在一个正在经历的情绪,如压力或惊喜。此外,朗等人发现GSR的平均值与唤醒的程度[20]。
容积描记器测量参与者拇指的血容量。这种测量也可以用来计算心率(HR),通过识别局部最大心率(即心跳)、搏动间期和心率变异性(HRV)。血压和HRV与情绪相关,因为压力会增加血压。刺激的愉快程度可增加峰值心率反应[20]。除了HR和HRV特征外,HRV衍生的光谱特征在情绪评估[50]中被证明是一个有用的特征。
记录皮肤温度和呼吸,因为它们随着不同的情绪状态而变化。缓慢的呼吸与放松有关,而不规则的节奏、快速的变化和呼吸的停止则与愤怒或恐惧等更强烈的情绪有关。
关于肌电图信号,我们记录了斜方肌(颈部)的活动,以研究听音乐时可能的头部运动。大颧肌的活动也被监测,因为当参与者大笑或微笑时,这块肌肉会被激活。肌肉收缩时肌电信号频谱中的大部分功率都在4到40赫兹之间。因此,从不同肌肉的肌电信号在这个频率范围内的能量可以得到肌肉的活动特征。眨眼频率是另一个与焦虑相关的特征。眨眼会影响EOG信号,并导致该信号中容易检测到的峰值。要进一步了解情绪的心理生理学,我们建议读者参考[51]。
表5
从脑电图和生理信号中提取特征。

所有的生理反应都以512Hz的采样率记录下来,然后向下采样至256Hz以减少处理时间。通过减去时间低频漂移,去除心电图和GSR信号的变化趋势。通过平滑每个ECG和GSR通道上的信号,以256点移动平均值计算低频漂移。
根据文献[22]、[26]、[52]-[54]提出的特征,从周围生理反应中共提取106个特征(见表5)。
从EEG信号中,提取出功率谱特征。 来自theta(4-8 Hz),慢速alpha(8-10 Hz),alpha(8-12 Hz),beta的频谱功率的对数
从所有32个电极提取(12-30Hz)和gamma(30+ Hz)波段作为特征。 除了功率谱特征外,还提取了左右半球上所有对称电极对的谱功率之间的差异,以测量由于情感刺激而导致的大脑活动中可能存在的不对称性。 一项针对32个电极的试验的EEG特征总数为216。表5总结了从生理信号中提取的特征列表。
6.2 MCA特性
音乐视频被编码为MPEG-1格式,以提取运动矢量和I帧以进行进一步的特征提取。 使用[55]中提出的方法已经将视频流在镜头级别进行了分割。
从电影导演的角度来看,照明键[30],[56]和颜色变化[30]是唤起情感的重要工具。 因此,我们通过将平均值V(在HSV中)乘以值V(在HSV中)的标准偏差,从HSV空间中的帧中提取照明关键点。 通过计算L,U和V的协方差矩阵的行列式,在CIE LUV颜色空间中获得颜色方差。
Hanjalic和Xu[29]展示了视频节奏和情感之间的关系。提取平均镜头变化率和镜头长度方差来表征视频节奏。在连续的画面中快速移动的场景或物体的移动也是引起兴奋的一个有效因素。为了测量这一因素,运动分量被定义为连续帧中的运动量,它是通过对所有B帧和p帧的运动矢量大小的累加计算得到的。
颜色及其比例是引起情绪的重要参数[57]。 针对每个I帧计算HSV空间中的色调和亮度值的20 bin颜色直方图,然后在所有帧上取平均值。 所得的bin平均值用作基于视频内容的功能。 计算HSL空间中L值的中值以获得帧的中值亮度。
最后,根据[30]给出的定义,确定代表阴影比例、视觉刺激、灰度和细节的视觉线索。
声音对情感也有重要的影响。例如,语音的响度(能量)与唤起有关,而语音信号的节奏和平均音高与价态[58]有关。视频的音频通道被提取并编码成mono MPEG-3格式,采样率为44.1 kHz。所有的音频信号在进一步处理之前都被归一化到相同的振幅范围。每个音频信号共确定53个低电平音频特征。表6中列出的这些特性通常用于音频和语音处理以及音频分类[59]、[60]。利用PRAAT软件包提取MFCC、共振峰和音频信号的音高[61]。
6.3单模态结果融合
上述多种模式的融合旨在通过利用不同模式的互补性来改进分类结果。通常,模态融合的方法可以分为两大类,即特征融合(或早期融合)和决策融合(或后期融合)[63]。在特征融合中,将从不同模式的信号中提取的特征串联起来形成一个复合的特征向量,然后将其输入到识别器中。另一方面,在决策融合中,每个模态都由相应的分类器独立处理,并将分类器的输出组合起来得到最终的结果。每种方法都有自己的优点。例如,实现一个基于特征融合的系统是很简单的,而一个基于决策融合的系统可以通过使用现有的单模分类系统来构建。此外,特征融合可以考虑所涉及模式的同步特性,而决策融合可以灵活地对模式的异步特性进行建模。
决策融合相对于特征融合的重要优势在于,由于决策融合中的每个信号都是独立处理和分类的,因此采用最佳加权方案来调整每种模态对最终信号的贡献的相对量相对容易。 根据模态的可靠性做出决定。 我们工作中使用的加权方案可以形式化如下:对于给定的测试基准X,融合系统的分类结果为

其中M模式的数量被认为是融合,λM是第M形态的分类器,和π(X |λm)为第i类是它的输出。αm的加权因子,满足0≤αm≤1 M和 ,确定每个模式会导致最后的决定和表示方式的可靠性。
,确定每个模式会导致最后的决定和表示方式的可靠性。
我们采用了一种简单的方法,即一旦从训练数据确定其最优值,就确定权重因子。通过穷举搜索规则网格空间来估计最优权值,其中每个权值从0到1增加0.01,并为训练数据选择产生最佳分类结果的权值。
6.4结果与讨论
表7列出了每种方式和每个评分量表的参与者的平均准确率和F1得分(两个班级的平均F1得分)。 我们将结果与随机投票的期望值(解析确定)进行比较,根据训练数据中的多数类别投票,并针对每个类别的投票及其在训练数据中出现的可能性进行比较。 为了确定多数投票和班级比例投票的期望值,我们在实验中使用了每个参与者反馈的班级比例。 这些结果有些过高,因为实际上必须从留一法交叉验证的每一折中的训练集中估计班级比率。
根据班别比例投票,每个参与者的预期f1分为0.5分。为了检验显著性,我们进行了独立的单样本t检验,将受试者的f1分布与0.5基线进行比较。从表中可以看出,在获得的9个f1分数中,有8个明显好于class ratio baseline。唯一的例外是使用脑电图信号进行喜好分类(p = 0.068)。当根据多数阶级投票时,由于阶级的不平衡,获得了相对较高的准确性。然而,这个投票方案的f1分数也是最低的。
总的来说,使用MCA特征进行分类的结果明显优于脑电图和外周血管(p均< 0.0001),而脑电图和外周血管的得分没有显著差异(p = 0.41)(对每个等级量表和参与者的连接结果进行双侧重复样本t检验)。
可以看出这些模式表现出适度的互补性,其中脑电图在唤醒方面得分最高,外在效价在价位方面得分最高,在喜好方面则在MCA得分最高。 在不同的等级量表中,效价分类表现最佳,其次是喜好,最后是唤醒度。
总体而言,使用MCA进行分类的效明显优于脑电图和外围评分(两者p均<0.0001),而脑电图和外围评分均无显着差异(p = 0.41)(使用双向重复样本t检验进行了 每个评分量表和参与者的合并结果)。 仅考虑了两种表现最佳的方式。 尽管融合通常胜过单一模式,但仅对价比例均等权重的MCA,PER有意义(p = 0.025)。
虽然给出的结果明显高于随机分类,但仍有很大的改进空间。 信号噪声,个体生理差异和有限的自我评估质量使单次试验分类具有挑战性。
表6
从音频信号中提取低级特征。

表7
平均准确率(ACC)和F1分(F1,每个班的平均分数)。根据一个独立的单样本t测试,星形显示受试者的f1分数分布是否显著高于0.5(∗∗= p < .01,∗= p < .05)。为了比较,我们给出了基于随机投票的分类、基于多数类别的投票和基于类的比例投票的预期结果。

表8
使用相等权重和最优权重方案的最佳两种模式和所有三种模式的融合的F1分数。 为了进行比较,还给出了最佳单模态的F1得分。

7结论
在这项工作中,我们提出了一个数据库的分析自发的情绪。该数据库包含32名参与者的生理信号(和22名参与者的正面视频),每个参与者观看并评价他们对40个音乐视频的情绪反应,这些情绪反应包括唤醒度、效价和支配度,以及他们对这些视频的喜爱程度和熟悉程度。摘要提出了一种基于情感标签的半自动刺激选择方法。参与者评分与脑电图频率之间存在显著相关。使用从脑电图、周围神经和MCA模式中提取的特征,对唤起、效价和喜欢度进行单次试验分类。结果表明,该方法明显优于随机分类。最后,这些结果的决策融合产生了性能的适度提高,表明至少与模式有一定的互补性。
该数据库是公开的,我们希望其他研究人员将尝试他们的方法和算法在这个高度具有挑战性的数据库。
R EFERENCES
[1] M. K. Shan, F. F. Kuo, M. F. Chiang, and S. Y. Lee, “Emotion-based
music recommendation by affinity discovery from film music,”
Expert Syst. Appl., vol. 36, no. 4, pp. 7666–7674, September 2009.
[2] M. Tkalˇ ciˇ c, U. Burnik, and A. Koˇ sir, “Using affective parameters in
a content-based recommender system for images,” User Modeling
and User-Adapted Interaction, pp. 1–33–33, September 2010.
[3] J. J. M. Kierkels, M. Soleymani, and T. Pun, “Queries and tags in
affect-based multimedia retrieval,” in Proc. Int. Conf. Multimedia
and Expo. New York, NY, USA: IEEE Press, 2009, pp. 1436–1439.
[4] M. Soleymani, J. Lichtenauer, T. Pun, and M. Pantic, “A multi-
modal Affective Database for Affect Recognition and Implicit Tag-
ging,” IEEE Trans. Affective Computing, Special Issue on Naturalistic
Affect Resources for System Building and Evaluation, under review.
[5] A. Savran, K. Ciftci, G. Chanel, J. C. Mota, L. H. Viet, B. Sankur,
L. Akarun, A. Caplier, and M. Rombaut, “Emotion detection in the
loop from brain signals and facial images,” in Proc. eNTERFACE
2006 Workshop, Dubrovnik, Croatia, Jul. 2006.
[6] P. Ekman, W. V. Friesen, M. O’Sullivan, A. Chan, I. Diacoyanni-
Tarlatzis, K. Heider, R. Krause, W. A. LeCompte, T. Pitcairn,
and P. E. Ricci-Bitti, “Universals and cultural differences in the
judgments of facial expressions of emotion.” Journal of Personality
and Social Psychology, vol. 53, no. 4, pp. 712–717, Oct. 1987.
[7] W. G. Parrott, Emotions in Social Psychology: Essential Readings.
Philadelphia: Psychology Press, 2001.
[8] R. Plutchik, “The nature of emotions,” American Scientist, vol. 89,
p. 344, 2001.
[9] J. A. Russell, “A circumplex model of affect,” Journal of Personality
and Social Psychology, vol. 39, no. 6, pp. 1161–1178, 1980.
[10] M. M. Bradley and P. J. Lang, “Measuring emotion: the self-
assessment manikin and the semantic differential.” J. Behav. Ther.
Exp. Psychiatry, vol. 25, no. 1, pp. 49–59, Mar. 1994.
[11] M. Pantic, M. Valstar, R. Rademaker, and L. Maat, “Web-based
database for facial expression analysis,” in Proc. Int. Conf. Multi-
media and Expo, Amsterdam, The Netherlands, 2005, pp. 317–321.
[12] E. Douglas-Cowie, R. Cowie, and M. Schröder, “A new emotion
database: Considerations, sources and scope,” in Proc. ISCA Work-
shop on Speech and Emotion, 2000, pp. 39–44.
[13] H. Gunes and M. Piccardi, “A bimodal face and body gesture
database for automatic analysis of human nonverbal affective
behavior,” in Proc. Int. Conf. Pattern Recognition, vol. 1, 2006, pp.
1148–1153.
[14] G. Fanelli, J. Gall, H. Romsdorfer, T. Weise, and L. Van Gool, “A
3-D audio-visual corpus of affective communication,” IEEE Trans.
Multimedia, vol. 12, no. 6, pp. 591–598, Oct. 2010.
[15] M. Grimm, K. Kroschel, and S. Narayanan, “The vera am mittag
german audio-visual emotional speech database,” in Proc. Int.
Conf. Multimedia and Expo, 2008, pp. 865 –868.
[16] J. A. Healey, “Wearable and automotive systems for affect recog-
nition from physiology,” Ph.D. dissertation, MIT, 2000.
[17] J. A. Healey and R. W. Picard, “Detecting stress during real-
world driving tasks using physiological sensors,” IEEE Trans.
Intell. Transp. Syst., vol. 6, no. 2, pp. 156–166, 2005.
[18] P. Lang, M. Bradley, and B. Cuthbert, “International affective pic-
ture system (IAPS): Affective ratings of pictures and instruction
manual,” University of Florida, USA, Tech. Rep. A-8, 2008.
[19] Z. Zeng, M. Pantic, G. I. Roisman, and T. S. Huang, “A survey
of affect recognition methods: Audio, visual, and spontaneous
expressions,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 31, no. 1,
pp. 39–58, Mar. 2009.
[20] P. Lang, M. Greenwald, M. Bradely, and A. Hamm, “Looking
at pictures - affective, facial, visceral, and behavioral reactions,”
Psychophysiology, vol. 30, no. 3, pp. 261–273, May 1993.
[21] J. Kim and E. André, “Emotion recognition based on physiological
changes in music listening,” IEEE Trans. Pattern Anal. Mach. Intell.,
vol. 30, no. 12, pp. 2067–2083, 2008.
[22] J. Wang and Y. Gong, “Recognition of multiple drivers’ emotional
state,” in Proc. Int. Conf. Pattern Recognition, 2008, pp. 1 –4.
[23] C. L. Lisetti and F. Nasoz, “Using noninvasive wearable com-
puters to recognize human emotions from physiological signals,”
EURASIP J. Appl. Signal Process., vol. 2004, no. 1, pp. 1672–1687,
Jan. 2004.
[24] G. Chanel, J. Kierkels, M. Soleymani, and T. Pun, “Short-term
emotion assessment in a recall paradigm,” International Journal of
Human-Computer Studies, vol. 67, no. 8, pp. 607–627, Aug. 2009.
[25] J. Kierkels, M. Soleymani, and T. Pun, “Queries and tags in affect-
based multimedia retrieval,” in Proc. Int. Conf. Multimedia and
Expo, Special Session on Implicit Tagging, New York, USA, Jun. 2009,
pp. 1436 – 1439.
[26] M. Soleymani, G. Chanel, J. J. M. Kierkels, and T. Pun, “Affective
characterization of movie scenes based on content analysis and
physiological changes,” International Journal of Semantic Comput-
ing, vol. 3, no. 2, pp. 235–254, Jun. 2009.
[27] A. Yazdani, J.-S. Lee, and T. Ebrahimi, “Implicit emotional tagging
of multimedia using EEG signals and brain computer interface,”
in Proc. SIGMM Workshop on Social media, 2009, pp. 81–88.
[28] P. Ekman, W. Friesen, M. Osullivan, A. Chan, I. Diacoyannitar-
latzis, K. Heider, R. Krause, W. Lecompte, T. Pitcairn, P. Riccibitti,
K. Scherer, M. Tomita, and A. Tzavaras, “Universals and cultural-
differences in the judgments of facial expressions of emotion,”
Journal of Personality and Social Psychology, vol. 53, no. 4, pp. 712–
717, Oct. 1987.
[29] A. Hanjalic and L.-Q. Xu, “Affective video content representation
and modeling,” IEEE Trans. Multimedia, vol. 7, no. 1, pp. 143–154,
2005.
[30] H. L. Wang and L.-F. Cheong, “Affective understanding in film,”
IEEE Trans. Circuits Syst. Video Technol., vol. 16, no. 6, pp. 689 –
704, Jun. 2006.
[31] M. Soleymani, J. Kierkels, G. Chanel, and T. Pun, “A Bayesian
framework for video affective representation,” in Proc. Int. Conf.
Affective Computing and Intelligent interaction, Sep. 2009, pp. 1–7.
[32] D. Liu, “Automatic mood detection from acoustic music data,” in
Proc. Int. Conf. Music Information Retrieval, 2003, pp. 13–17.
[33] L. Lu, D. Liu, and H.-J. Zhang, “Automatic mood detection and
tracking of music audio signals,” IEEE Transactions on Audio,
Speech and Language Processing, vol. 14, no. 1, pp. 5–18, Jan. 2006.
[34] Y.-H. Yang and H. H. Chen, “Music emotion ranking,” in Proc.
Int. Conf. Acoustics, Speech and Signal Processing, ser. ICASSP ’09,
Washington, DC, USA, 2009, pp. 1657–1660.
[35] S. Koelstra, A. Yazdani, M. Soleymani, C. Mühl, J.-S. Lee, A. Ni-
jholt, T. Pun, T. Ebrahimi, and I. Patras, “Single trial classification
of EEG and peripheral physiological signals for recognition of
emotions induced by music videos,” in Brain Informatics, ser.
Lecture Notes in Computer Science, Y. Yao, R. Sun, T. Poggio,
J. Liu, N. Zhong, and J. Huang, Eds. Berlin, Heidelberg: Springer
Berlin / Heidelberg, 2010, vol. 6334, ch. 9, pp. 89–100.
[36] M. E. Tipping, “Sparse bayesian learning and the relevance vector
machine,” Journal of Machine Learning Research, vol. 1, pp. 211–244,
Jun. 2001.
[37] J. D. Morris, “SAM: the self-assessment manikin. An efficient
cross-cultural measurement of emotional response,” Journal of
Advertising Research, vol. 35, no. 8, pp. 63–68, 1995.
[38] M. Bradley and P. Lang, “International affective digitized sounds
(iads): Stimuli, instruction manual and affective ratings,” The
Center for Research in Psychophysiology, University of Florida,
Gainesville, Florida, US, Tech. Rep. B-2, 1999.
[39] Lazar, N., “Combining Brains: A Survey of Methods for Statistical
Pooling of Information,” NeuroImage, vol. 16, no. 2, pp. 538–550,
June 2002.
[40] T. M. Loughin, “A systematic comparison of methods for com-
bining p-values from independent tests,” Computational Statistics
& Data Analysis, vol. 47, pp. 467–485, 2004.
[41] R. J. Barry, A. R. Clarke, S. J. Johnstone, C. A. Magee, and J. A.
Rushby, “EEG differences between eyes-closed and eyes-open
resting conditions,” Clinical Neurophysiology, vol. 118, no. 12, pp.
2765–2773, Dec. 2007.
[42] R. J. Barry, A. R. Clarke, S. J. Johnstone, and C. R. Brown, “EEG
differences in children between eyes-closed and eyes-open resting
conditions,” Clinical Neurophysiology, vol. 120, no. 10, pp. 1806–
1811, Oct. 2009.
[43] W. Klimesch, P. Sauseng, and S. Hanslmayr, “EEG alpha oscil-
lations: the inhibition-timing hypothesis.” Brain Research Reviews,
vol. 53, no. 1, pp. 63–88, Jan. 2007.
[44] H. Cole and W. J. Ray, “EEG correlates of emotional tasks related
to attentional demands,” International Journal of Psychophysiology,
vol. 3, no. 1, pp. 33–41, Jul. 1985.
[45] J. Onton and S. Makeig, “High-frequency broadband modulations
of electroencephalographic spectra,” Frontiers in Human Neuro-
science, vol. 3, 2009.
[46] I. Goncharova, D. J. McFarland, J. R. Vaughan, and J. R. Wolpaw,
“EMG contamination of EEG: spectral and topographical charac-
teristics,” Clinical Neurophysiology, vol. 114, no. 9, pp. 1580–1593,
Sep. 2003.
[47] E. Harmon-Jones, “Clarifying the emotive functions of asymmet-
rical frontal cortical activity,” Psychophysiology, vol. 40, no. 6, pp.
838–848, 2003.
[48] R. R. Cornelius, The Science of Emotion. Research and Tradition in
the Psychology of Emotion. Upper Saddle River, NJ: Prentice-Hall,
1996.
[49] D. Sander, D. Grandjean, and K. R. Scherer, “A systems approach
to appraisal mechanisms in emotion,” Neural Networks, vol. 18,
no. 4, pp. 317–352, 2005.
[50] R. McCraty, M. Atkinson, W. Tiller, G. Rein, and A. Watkins, “The
effects of emotions on short-term power spectrum analysis of
heart rate variability,” The American Journal of Cardiology, vol. 76,
no. 14, pp. 1089 – 1093, 1995.
[51] S. D. Kreibig, “Autonomic nervous system activity in emotion: A
review,” Biological Psychology, vol. 84, no. 3, pp. 394–421, 2010.
[52] G. Chanel, J. J. M. Kierkels, M. Soleymani, and T. Pun, “Short-term
emotion assessment in a recall paradigm,” International Journal of
Human-Computer Studies, vol. 67, no. 8, pp. 607–627, Aug. 2009.
[53] J. Kim and E. André, “Emotion recognition based on physiological
changes in music listening,” IEEE Trans. Pattern Anal. Mach. Intell.,
vol. 30, no. 12, pp. 2067–2083, 2008.
[54] P. Rainville, A. Bechara, N. Naqvi, and A. R. Damasio, “Basic
emotions are associated with distinct patterns of cardiorespiratory
activity.” International Journal of Psychophysiology, vol. 61, no. 1, pp.
5–18, Jul. 2006.
[55] P. Kelm, S. Schmiedeke, and T. Sikora, “Feature-based video key
frame extraction for low quality video sequences,” in Proc. Int.
Workshop on Image Analysis for Multimedia Interactive Services, May
2009, pp. 25 –28.
[56] Z. Rasheed, Y. Sheikh, and M. Shah, “On the use of computable
features for film classification,” IEEE Trans. Circuits Syst. Video
Technol., vol. 15, no. 1, pp. 52–64, 2005.
[57] P. Valdez and A. Mehrabian, “Effects of color on emotions.” J.
Exp. Psychol. Gen., vol. 123, no. 4, pp. 394–409, Dec. 1994.
[58] R. W. Picard, Affective Computing. MIT Press, Sep. 1997.
[59] D. Li, I. K. Sethi, N. Dimitrova, and T. McGee, “Classification of
general audio data for content-based retrieval,” Pattern Recogn.
Lett., vol. 22, no. 5, pp. 533–544, 2001.
[60] L. Lu, H. Jiang, and H. Zhang, “A robust audio classification
and segmentation method,” in Proc. ACM Int. Conf. Multimedia,
Ottawa, Canada, 2001, pp. 203–211.
[61] P. Boersma, “Praat, a system for doing phonetics by computer,”
Glot International, vol. 5, no. 9/10, pp. 341–345, 2001.
[62] L. Chen, S. Gunduz, and M. Ozsu, “Mixed type audio classifica-
tion with support vector machine,” in Proc. Int. Conf. Multimedia
and Expo, Toronto, Canada, Jul. 2006, pp. 781 –784.
[63] J.-S. Lee and C. H. Park, “Robust audio-visual speech recognition
based on late integration,” IEEE Trans. Multimedia, vol. 10, no. 5,
pp. 767–779, 2008.















 1440
1440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









