






Python(Pycharm)集成飞桨OCR
写的比较糙,引用了很多文章,大家可以直接去引用文章看具体内容
1、更换镜像源为国内清华源,下载起来快一些
参考:
https://blog.csdn.net/weixin_55629186/article/details/132549074?spm=1001.2014.3001.5506
2、按官方文档操作:
https://github.com/PaddlePaddle/PaddleOCR/blob/main/ppstructure/docs/quickstart.md
具体操作如下
2.1 使用CPU
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
2.2 # 安装 paddleocr,推荐使用2.6版本
pip3 install “paddleocr>=2.6.0.3”
这两个安装完就可以使用测试代码了(我只用OCR识图片,多的代码没贴),
值得注意的是 我没有导入
pip3 install paddleclas>=2.4.3
不需要图像方向分类,所以在image_orientation=True这里替换为False
import os
import cv2
from paddleocr import PPStructure,draw_structure_result,save_structure_res
table_engine = PPStructure(show_log=True, image_orientation=True)
save_folder = './output'
img_path = 'ppstructure/docs/table/1.png'
img = cv2.imread(img_path)
result = table_engine(img)
save_structure_res(result, save_folder,os.path.basename(img_path).split('.')[0])
for line in result:
line.pop('img')
print(line)
运行时候报错
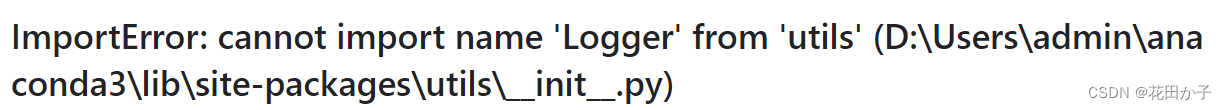
导入了这两个包
pip install utils
pip install logger
还需要再解释器中再次配置。
具体参考: https://blog.csdn.net/lk_mm_love/article/details/121412398
我在解释器中配置就可以了,不需要手动把包粘贴过去。
成功!
















 6033
6033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









