






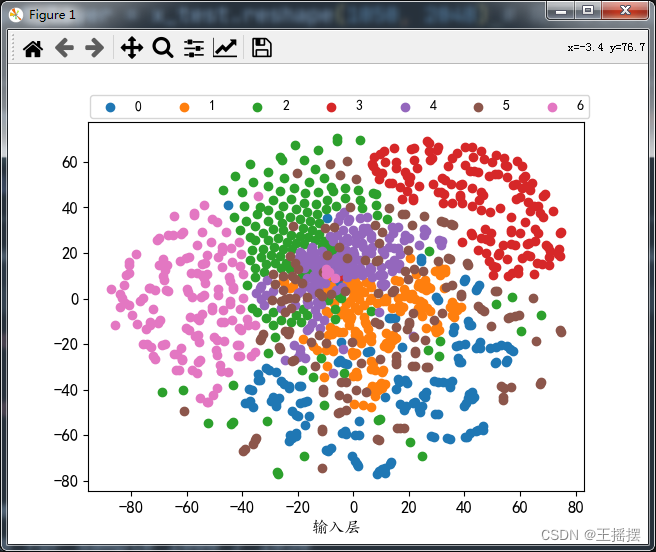
学习代码
[t-SNE] Computing 91 nearest neighbors...
[t-SNE] Indexed 1050 samples in 0.003s...
[t-SNE] Computed neighbors for 1050 samples in 0.059s...
[t-SNE] Computed conditional probabilities for sample 1000 / 1050
[t-SNE] Computed conditional probabilities for sample 1050 / 1050
[t-SNE] Mean sigma: 14.442199
[t-SNE] KL divergence after 250 iterations with early exaggeration: 121.511391
[t-SNE] KL divergence after 1000 iterations: 2.100818
(1050, 2)
这些信息来自 t-SNE 的计算过程,提供了有关 t-SNE 运行情况的详细信息。以下是每一行信息的简要解释:
-
[t-SNE] Computing 91 nearest neighbors…
- t-SNE 正在计算每个样本的最近邻。
-
[t-SNE] Indexed 1050 samples in 0.003s…
- t-SNE 已经对 1050 个样本建立了索引,并在 0.003 秒内完成。
-
[t-SNE] Computed neighbors for 1050 samples in 0.059s…
- t-SNE 已经为 1050 个样本计算了最近邻。
-
[t-SNE] Computed conditional probabilities for sample 1000 / 1050
- t-SNE 正在计算第 1000 个样本的条件概率。
-
[t-SNE] Computed conditional probabilities for sample 1050 / 1050
- t-SNE 已经计算了所有 1050 个样本的条件概率。
-
[t-SNE] Mean sigma: 14.442199
- 平均 sigma 是 t-SNE 中用于计算条件概率的参数,表示样本之间的平均距离。
-
[t-SNE] KL divergence after 250 iterations with early exaggeration: 121.511391
- 在前期夸大(early exaggeration)的 250 次迭代后,KL 散度为 121.511391。KL 散度是 t-SNE 算法中的一个目标,目的是在降维后保留样本之间的相对关系。
-
[t-SNE] KL divergence after 1000 iterations: 2.100818
- 在总共 1000 次迭代后,KL 散度降至 2.100818。KL 散度越低,表示 t-SNE 的降维效果越好。
-
(1050, 2)
- 最终的 t-SNE 降维结果是一个形状为 (1050, 2) 的数组,其中每个样本被映射到了二维空间。
这些信息提供了 t-SNE 在降维过程中的一些关键统计和参数,以及算法的收敛情况。通常,KL 散度越低,表示 t-SNE 的降维效果越好,更能够保留原始数据的结构。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











