






介绍(Introduction)
Reinforcement learning is really cool. For instance, its used to train the Robot Dogs to walk. Let me give you an quick example, once you have created a Robot Dog, we can implement an algorithm inside a Robot Dog which will tell how to walk. We can provide sequence of actions that it needs to take to accomplish the task which is walking. Well, we are not going to delve into training the Robots since that is a topic more on the side of Artificial Intelligence.
强化学习真的很棒。 例如,它曾经训练过机器狗走路。 让我举一个简单的例子,一旦创建了机器狗,我们就可以在机器狗内部实现一个算法,该算法将告诉您如何走路。 我们可以提供完成行走任务所需采取的一系列动作。 好吧,我们不会深入研究机器人,因为这更多地是人工智能方面的话题。
In this section let’s learn more about The Multi-Armed Bandit Problem which is a bit of a different application in Reinforcement Learning.
在本节中,我们将学习有关“多臂强盗问题”的更多信息,该问题在“强化学习”中的应用有所不同。
First of all what on earth is this, ‘The Multi-Armed Bandit Problem’?
首先,“多武装强盗问题”到底是什么?
In simple words, ‘one armed bandit’ refers to a slot machine — pull the ‘arm’ and the ‘bandit’ will take your money. ‘Multi armed Bandit’, refers multiple slot machines — like 5 or 10.
简单来说,“一个武装匪徒”指的是一台老虎机-拉动“胳膊”,“匪徒”会拿走你的钱。 “多武装强盗”是指多台老虎机-例如5或10。
多武装强盗问题陈述 (The Multi-Armed Bandit Problem Statement)
To describe the problem in more detail we got to mention that the assumption here is — each one of the slot machines has a distribution of numbers/outcomes behind it, out of which the machine picks results randomly(whether you win or whether you loose). The distributions are assumed to be different for these machines, sometimes it might be same but by default they are different.The goal is to figure out — which of these distributions is the best one.
为了更详细地描述问题,我们不得不提到这里的假设是-每台老虎机背后都有一个数字/结果分布,机器从中随机挑选结果(无论您赢还是输) 。 假定这些机器的发行版不同,有时可能相同,但默认情况下它们是不同的。目标是弄清楚-这些发行版中哪一个是最佳发行版。
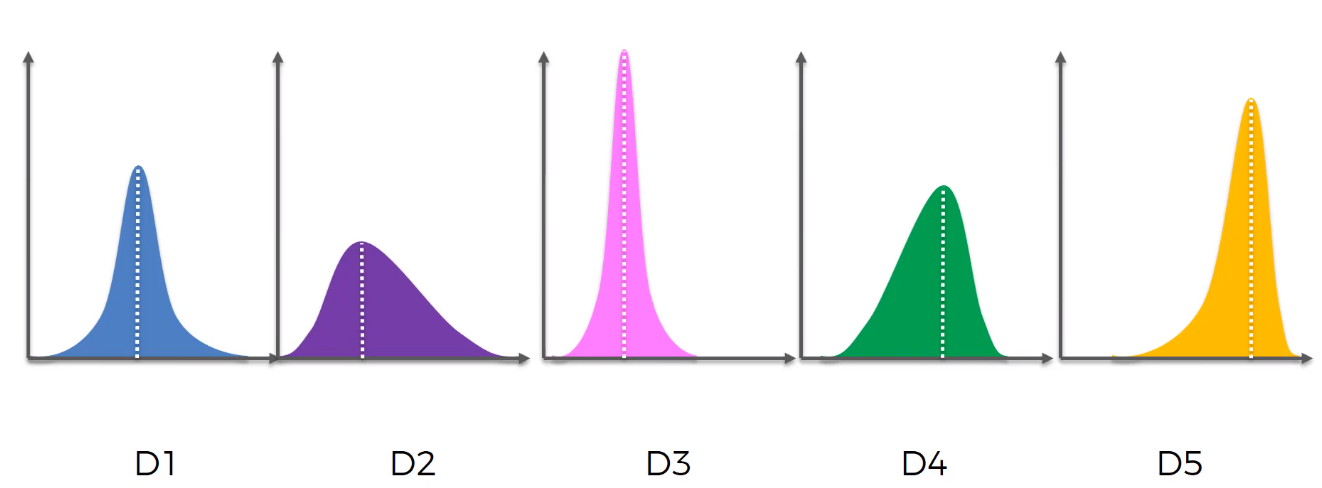
For instance, in the above graph we have got the five machines with five different distributions. By looking at this — which you think is the best machine? Its one on the right — the orange(D5). Since its left skewed and also it has got the most favorable outcomes — highest mean, median and mode. That said, we don’t know in advance that D5 has the best distribution, our goal is to figure out which is best one.
例如,在上图中,我们获得了五台具有五种不同分布的机器。 通过观察这一点-您认为哪台机器是最好的? 它在右侧-橙色(D5)。 自从其左偏斜以来,它还获得了最有利的结果-最高均值,中位数和众数。 就是说,我们不预先知道D5的分布最佳,我们的目标是找出最好的D5。
To figure out the best one we need to consider two factors — exploration — to explore the machine to find out which is best as quick as possible and exploitation — exploiting these machines/findings to make the maximum return.
为了找出最好的一个,我们需要考虑两个因素-探索-以 探索机器以找出最佳选择 尽快 和开发-利用这些机器/发现来获得最大的回报。
Well, here we are going to explore the most modern application of ‘The Multi-Armed Bandit Problem’,which is — Advertising.
好了,这里我们将探讨“多臂强盗问题”的最新应用,即广告。
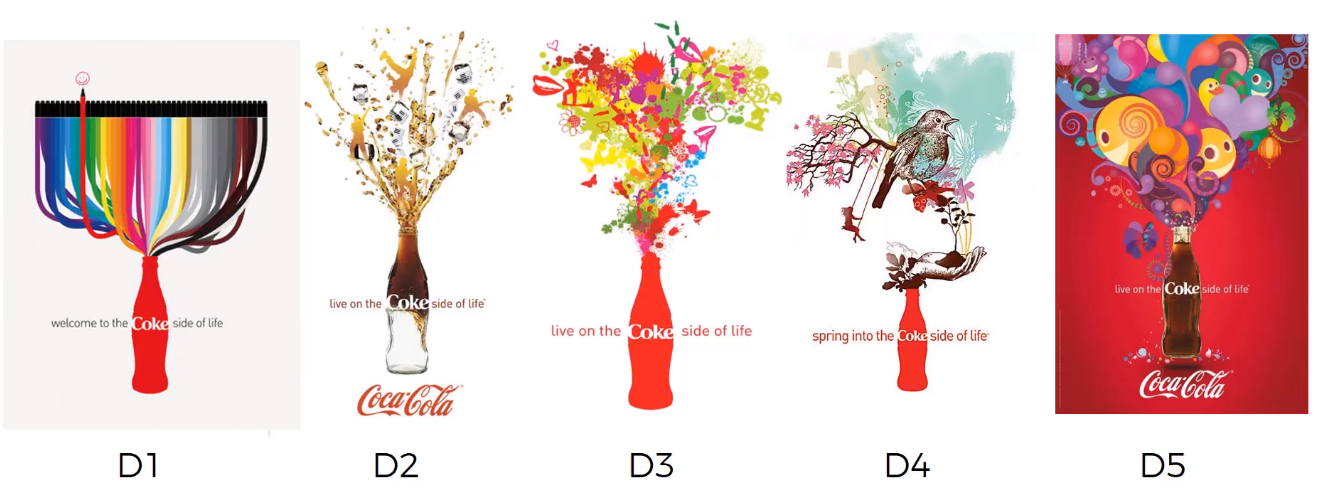
Consider the above figure which is Coco Cola Campaign, here goal is — to find out which is the best ad. This can be solved using two algorithms — UCB and Thompson Sampling.
考虑上图是可口可乐广告系列,这里的目标是-找出哪个是最好的广告。 可以使用UCB和Thompson Sampling这两种算法来解决。
使用汤普森采样解决多武装强盗问题 (Solution to The Multi-Armed Bandit Problem using Thompson Sampling)
A quick summary of “The Multi-Armed Bandit Problem”,
“多武装强盗问题”快速摘要,
We have d arms. For example, arms are ads that we display to users each time they connect to a web page.
我们有武器。 例如,武器是我们在用户每次连接到网页时向他们展示的广告。
Each time a user connects to this web page, that makes a round.
每次用户连接到此网页,都会进行一轮回合。
At each round n, we choose one ad to display to the user.
在第n轮中,我们选择一个广告展示给用户。
At each round n,ad i gives reward rᵢ(n) ε {0,1}: rᵢ(n) = 1 if the user click on the ad i, 0 if the user didn’t.
在每个第n轮,广告I给出奖励řᵢ(n)的ε{0,1},Rᵢ(N)= 1,如果在广告的用户点击I,0,如果用户没有。
Our goal is to maximize the total reward we get over many rounds.
我们的目标是使我们在多轮谈判中获得的总回报最大化。
汤普森采样算法的直觉 (Thompson Sampling Algorithm Intuition)
Now this is going to be fun and interesting. Get ready for fun ride — lets get started.
现在,这将变得有趣而有趣。 准备好玩的乐趣-让我们开始吧。
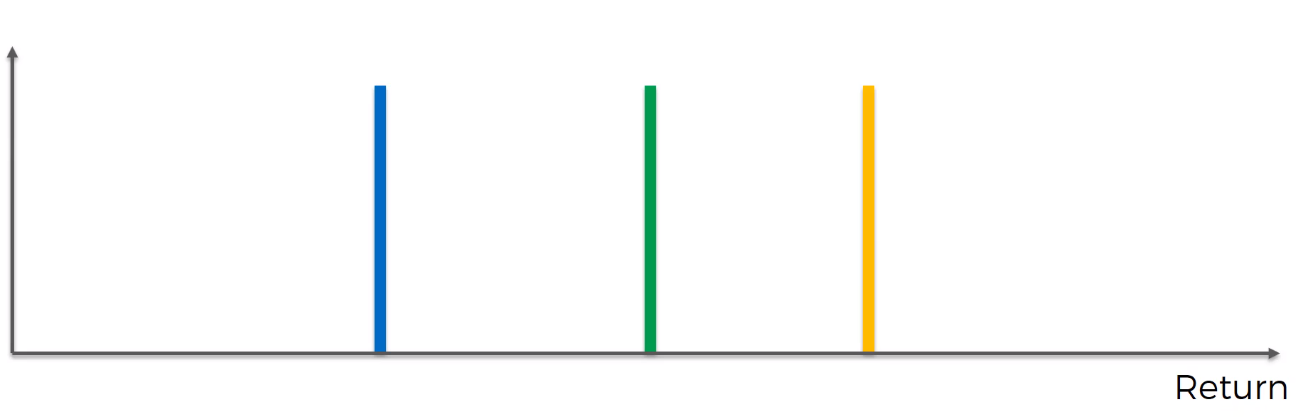
Consider the above scale, the horizontal axis is the Return that we get from the Bandit. Here we are considering three Bandits to understand the concept. Each of these machines has a distribution behind it.
考虑上面的比例,水平轴是我们从强盗那里获得的收益。 在这里,我们考虑三个土匪来理解这个概念。 这些机器中的每一个都有其背后的分布。
So what’s in this Algorithm?
那么这个算法是什么呢?
- At the start, all the machines are identical. 一开始,所有机器都是相同的。
In Graph 2, we have some trial runs. Based on the trial runs, the Algorithm will construct a distribution. For example, consider the graph 2 — for the blue machine we are pulling the values and we get some values say four as shown in the graph based on these values we are constructing a distribution.
在图2中,我们进行了一些试运行。 根据试运行,该算法将构建一个分布。 例如,考虑图2-对于蓝色机器,我们提取值,然后基于这些值得到一些值,如图4所示,我们正在构建分布。
It doesn’t represent the distributions behind the machines. We are constructing the distributions of where we think the actual expected value might lie(Indeed, we aren’t re-creating the machines instead we are re-creating the possible way these machines could have been created).
它不代表机器背后的分布。 我们正在构建我们认为实际期望值可能位于的分布(实际上,我们不是在重新创建机器,而是在重新创建可能创建这些机器的方式)。
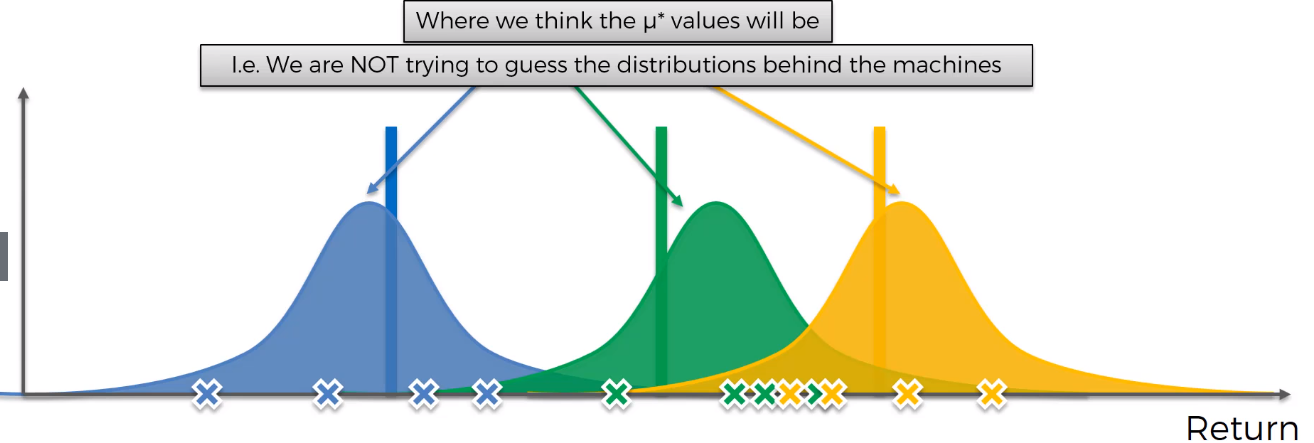
4. This demonstrates that it is a Probabilistic Algorithm(consider graph 3, the μ* can be anywhere within the distribution curve)
4.这证明它是一个概率算法(考虑图3, μ*可以在分布曲线内的任何位置)
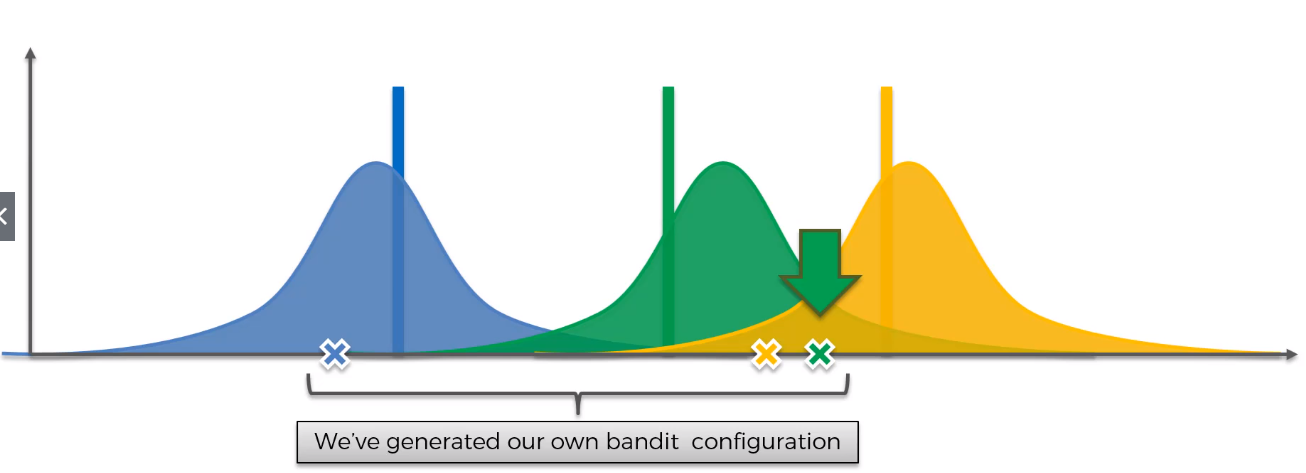
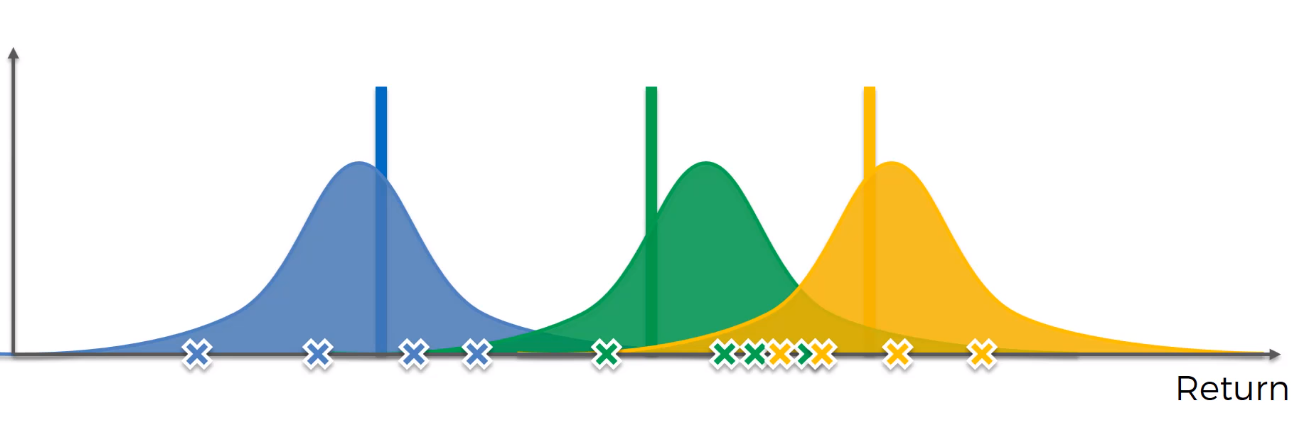
5. In Graph 4, the values are pulled from each distribution(blue,green,yellow) — which is highlighted as “X”. By doing this we have generated our own Bandit Configuration(i.e, we have created a imaginary set of machines in our own virtual world). To solve the problem, we just pick the green machine — since it has the highest expected return.
5.在图4中,从每个分布(蓝色,绿色,黄色)中拉出值-高亮显示为“ X”。 通过这样做,我们生成了自己的Bandit配置(即,我们在自己的虚拟世界中创建了一组虚拟的机器)。 为了解决这个问题,我们只选择绿色机器,因为它的预期收益最高。
6. Now we have to translate these results which we got from our imaginary set into the actual world.
6.现在,我们必须将我们从想象中获得的结果转换为现实世界。
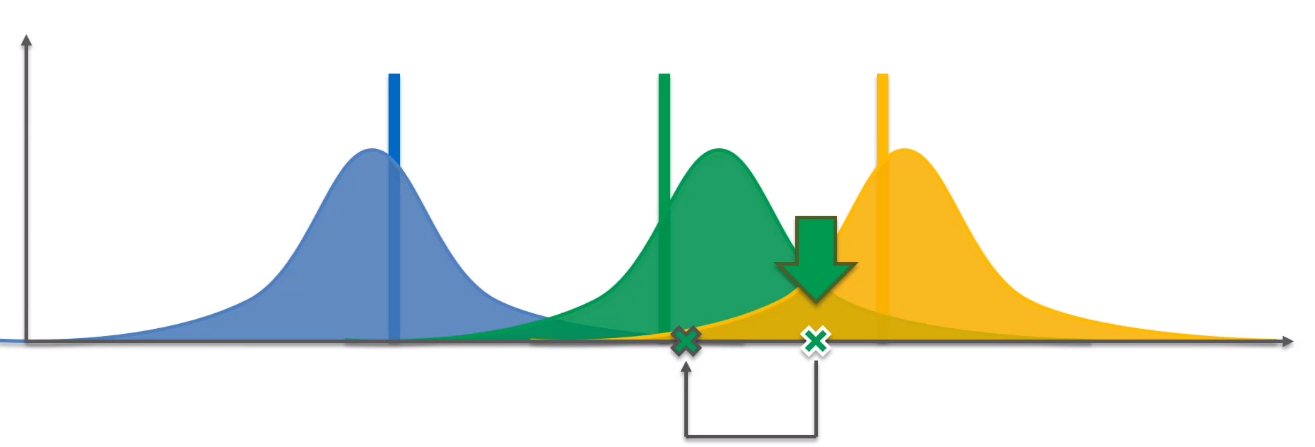
7. In the hypothetical world we have selected green machine, so in actual world the algorithm also selects the green machine and what that does is it pulls the lever for this machine — this gives the value. This value will be based on the distribution behind this green machine(this is the actual expected value of the distribution as shown in Graph 5).
7.在假设的世界中,我们选择了绿色机器,因此在实际世界中,算法也选择了绿色机器,这是它拉动该机器的杠杆的作用,这就是价值所在。 该值将基于该绿色机器背后的分布(这是该分布的实际期望值,如图5所示)。
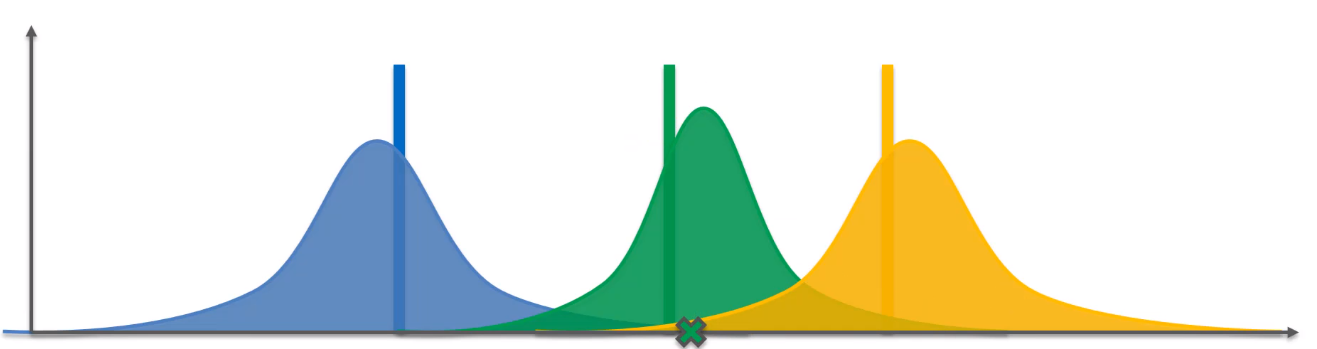
8. Now we have got the new information(i.e, the new value)which we need to add and adjust the distribution based on this new value. In Graph 6, we can see the shift in the distribution — it has also become narrower. Every time we add new information out distribution becomes more refined.
8.现在我们获得了新信息(即新值),我们需要根据该新值添加和调整分布。 在图6中,我们可以看到分布的变化-它也变得越来越窄。 每次我们添加新信息时,分发就会变得更加精细。

9. Now what happens next is, NEW ROUND. Again we pull out some new values and generate our own bandit configuration in our hypothetical/imaginary world. And pick the best bandit, pull the lever of that bandit which gives some value — this is the actual value that we received from the real world. Then we need to in-cooperate this value into our real world and make adjustments accordingly. And so on…
9.现在,接下来发生的是新回合。 同样,我们在假设的/虚构的世界中提取了一些新的值并生成了自己的强盗配置。 并选择最佳的强盗,拉动该强盗的杠杆,它会提供一定的价值-这是我们从现实世界中获得的实际价值。 然后,我们需要将此价值与现实世界进行合作,并进行相应的调整。 等等…
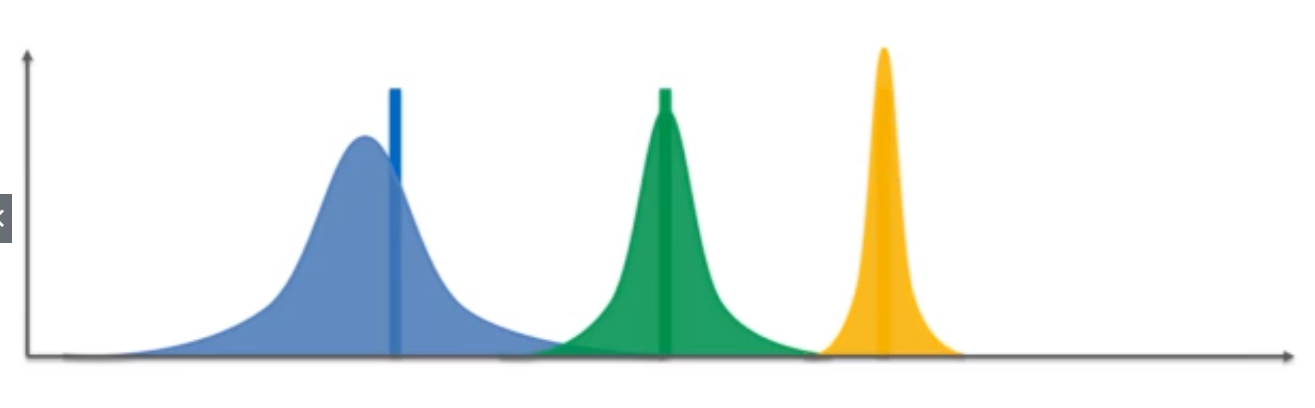
10. We need to continuing doing this until we get into the point where we have refined the distributions substantially. As you can see in Graph 8.
10.我们需要继续这样做,直到我们达到对分配进行实质性改进的程度。 如您在图8中所见。
So, there we go that’s pretty much how this Thompson Sampling Algorithm works.
因此,我们可以大致了解该汤普森采样算法的工作原理。
Hopefully this has given some idea on Thompson Sampling Algorithm and how to solve the Multi-Armed Bandit Problem. In the next part will be discussing the practical side of things.
希望这对Thompson采样算法以及如何解决多臂强盗问题提供了一些思路。 在下一部分将讨论事物的实际方面。
Happy Learning!
学习愉快!















 4092
4092











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









