






TransGAN网络是将在DCGAN的基础上进行的改写,DCGAN网络中判别器和生成器的核心主干网络为卷积神经网络,TransGAN是利用transformer作为主干网络将卷积神经网络全部进行了替换,
原始代码地址:https://github.com/VITA-Group/TransGAN
原始文章地址:https://arxiv.org/abs/2102.07074
但是在实现过程中发现原始给的代码是在Linux上面跑的,在window上面无论怎么跑都没有办法跑通,因此我打算自己重新根据已经开源的代码进行编辑。
根据对文章的理解以及作者给出的结构图,如下图所示:
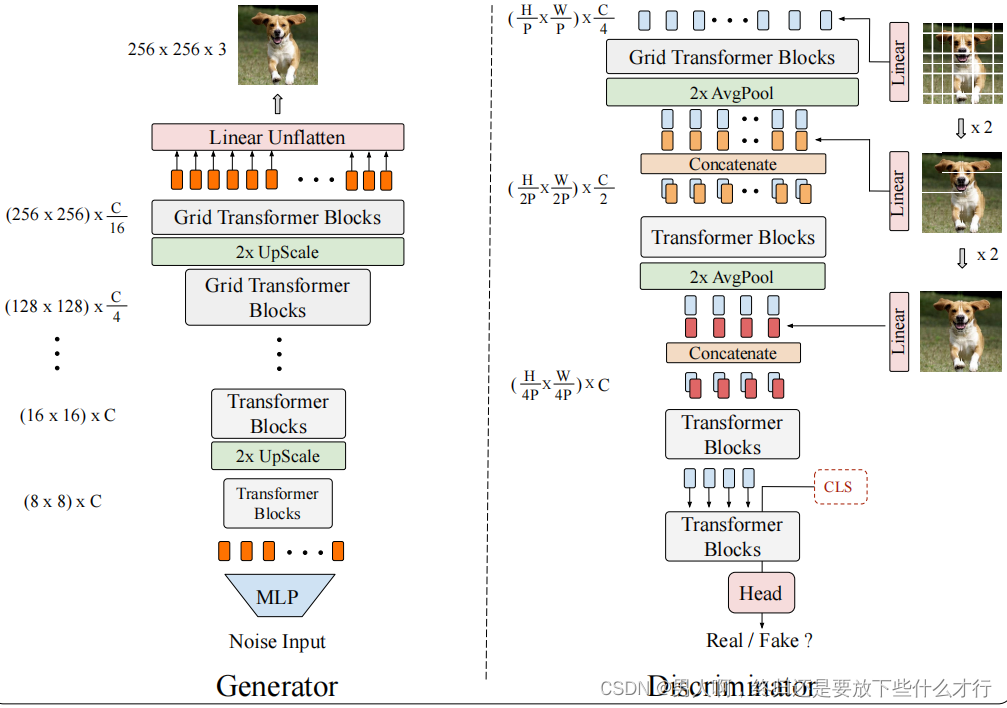
可以很明显的看出来其网络架构,那么接下来就对TransformerGAN进行网络框架的构建。
首先对多层感知机的代码进行编写:
class Mlp(nn.Module):
"""
MLP as used in Vision Transformer, MLP-Mixer and related networks 所有MLP的函数全部按照这个格式来写就行
"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)#表示为全连接层
self.act = act_layer() #激活函数
self.fc2 = nn.Linear(hidden_features, out_features)#全连接层
self.drop = nn.Dropout(drop)#我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x经过MLP之后下一步就是在transformer中进行编码,transformer分为一下几个部分,
先将数据传输到layer normal中,将其划分为qkv,将qkv传入到muti-head self-attention里。经过自注意力对各个元素进行处理之后,在进行传输,可以看到从一开始伸出来一条线直接略过了norm层和注意力机制层,这是一种残差的操作,目的为了保证每次输出的数据能是最优的数据,随后在传输到norm层-->MLP,最后传递给后面的模块中。
整体的transformer block图像如下所示:
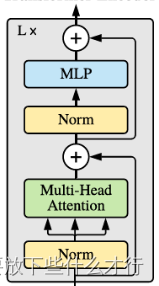
根据transformerblock对其进行代码的编写 :
class Block(nn.Module):
def __init__(self,
dim,
num_heads,
mlp_ratio=4.,
qkv_bias=False,
qk_scale=None,
drop=0.,
attn_drop=0.,
drop_path=0.,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop,
proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp1(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))#类似残差网络将最优的数据进行输出
return x可以看到block中包含有self-attemtion的操纵,可以看一下self-attention的结构图:
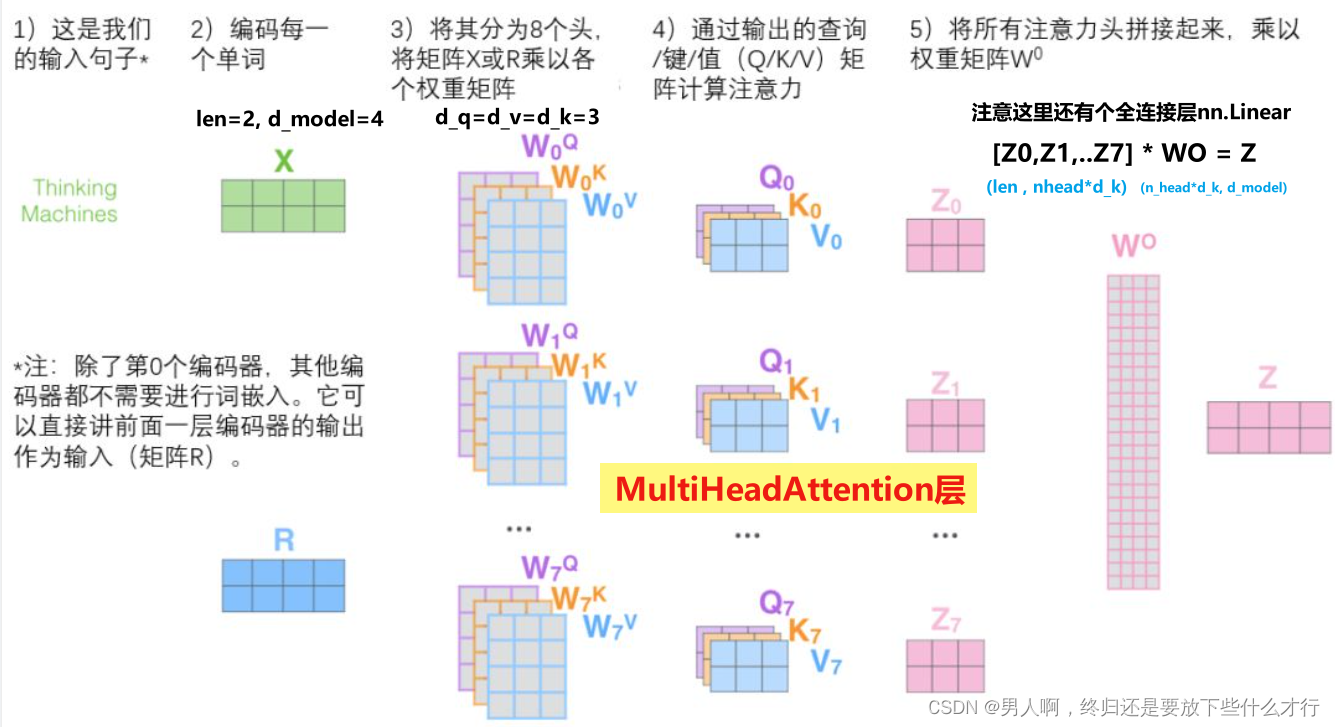
transformer原始的使用途径是在NLP上进行的,因此需要对输入的各个元素进行打标记,将每个元素都打上各自的QKV。
class Attention1(nn.Module):
def __init__(self,
dim, # 输入token的dim,表示为设定的总编码的个数,
num_heads=8,#multi-head的个数
qkv_bias=False,#是否在qkv使用偏置
qk_scale=None,
attn_drop_ratio=0.,#传入dro
proj_drop_ratio=0.):
super(Attention1, self).__init__()
self.num_heads = num_heads
head_dim = dim // num_heads #用总编码个数除以head个数,表示为用了几个attention得出的自编码来组成总编码个数
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)#有助于并行化
self.attn_drop = nn.Dropout(attn_drop_ratio)
self.proj = nn.Linear(dim, dim) #相当于W^o,用于将head进行concat
self.proj_drop = nn.Dropout(proj_drop_ratio)
def forward(self, x):
# [batch_size, num_patches + 1, total_embed_dim]
B, N, C = x.shape
# qkv(): -> [batch_size, num_patches + 1, 3 * total_]
# reshape: -> [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head]
# permute: -> [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head]
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) #(3,self.num_heads, c // self.num_heads)表示为将3 * total_embed_dim拆分成三个部分,
# 3-->表示为qkv三个参数,self.num_heads采用head的数目,c 表示为total_embed_dim除以每一个Head
# [batch_size, num_heads, num_patches + 1, embed_dim_per_head]
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
# transpose: -> [batch_size, num_heads, embed_dim_per_head, num_patches + 1]
# @: multiply -> [batch_size, num_heads, num_patches + 1, num_patches + 1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1) #dim=-1表示为得到结果每一行进行softmax处理。dim=-2表示为对每一列进行处理
attn = self.attn_drop(attn)
# @: multiply -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head]
# transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head]
# reshape: -> [batch_size, num_patches + 1, total_embed_dim]
x = (attn @ v).transpose(1, 2).reshape(B, N, C)#对每一行V进行矩阵相乘,加权求和
x = self.proj(x) #通过W^O进行映射
x = self.proj_drop(x) #proj表示为卷积层以proj的形式写的dropout层进行输出
return x一个完整的transformer块就成型了,那么接下来就是需要将这些模块放置在判别器当中,根据对文章的理解,首先先将VIT全部模型替换掉CNN,看看是否能跑通















 5890
5890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









