







针对的问题
以前的大多数作品都是通过将给定子集的风格转移到未见子集的内容来解决这个问题的。然而,他们只关注同一语言中的字体样式转换。在许多任务中,我们需要学习一种语言的字体信息,然后将其应用到其他语言。现有的方法很难完成这样的任务。
解决方法
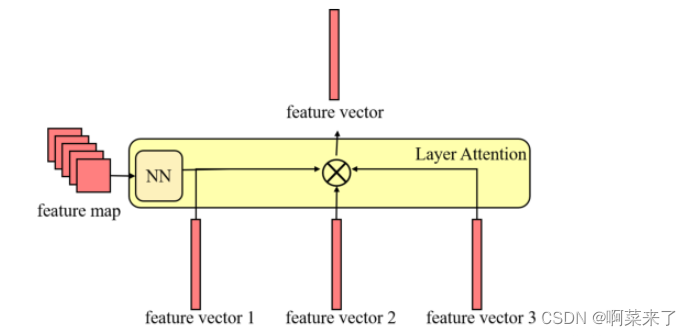
我们专门将我们的网络设计成一个多层次的注意力形式,以捕捉风格图像的局部和全局特征。
构建了一个包含847个字体的实验字体数据集,每个字体都包含相同风格的英文和中文字符。
所提出的层注意力网络的体系结构
创新点
1、引入了两个新颖的模块,上下文感知注意力网络和层注意力网络,以同时捕获局部和全局风格特征。
2、该模型的架构允许任意数量的输入样式图像,因此它可以在任何语言之间传输样式,而不受字符数量的限制。
3、构建了一个新的多语言字形图像数据集,该数据集由847个字体组成,每个字体包含52个英文字母和1000多个中文字符。
tips:数据集可以找我拿一下,有空就给你发。没空就不给你找了。
论文里面的Experiments
构建了一个数据集,包括847个灰度字体(风格输入),每个字体都有大约1000个常用汉字和52个相同风格的拉丁字母。
使用普通字体(例如,Microsoft YaHei)作为内容输入,它仅用于索引我们想要合成的字符的类别。我们通过在每个字形周围找到一个包围框来处理数据集,并调整它的大小,使较大的维度达到64像素,然后填充以创建64×64字形图像。
随机选择29个字体和字符作为未知的样式和内容,其余部分作为训练数据。因此,将整个数据集分为三部分分别为:S1用于训练的图像;S2用于测试的图像,在训练过程中见过样式但内容未知;S3用于测试的图像,内容已知但样式未知。
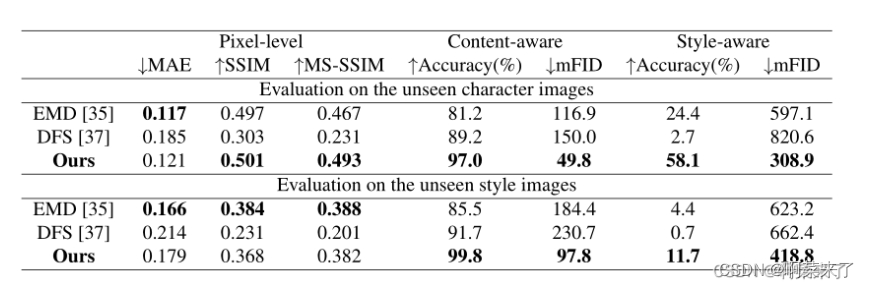
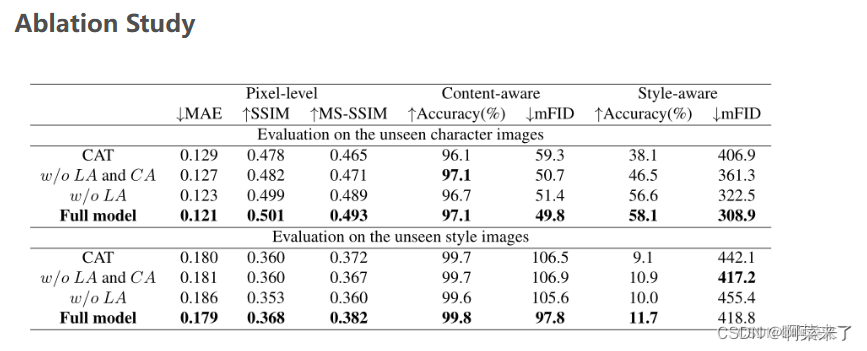
(这里没太看明白他的消融实验怎么弄的,晚点再继续琢磨。前面那个对比实验基本弄完了,数据还是可信的。跟别人的一些项目比起来,这篇论文的数据复现出来的结果相差不大。)
论文地址&code
论文:https://openaccess.thecvf.com/content/WACV2021/papers/Li_Few-Shot_Font_Style_Transfer_Between_Different_Languages_WACV_2021_paper.pdf
code:https://github.com/ligoudaner377/font_translator_gan
论文讲解及其翻译:https://blog.csdn.net/m0_61985580/article/details/128327905?spm=1001.2014.3001.5502
复现细节
tips:这里只进行了FTransGAN的复现,dfs还在跑。
环境
- Linux
- CPU or NVIDIA GPU + CUDA CuDNN
- Python 3 (我装的是3.8)
- torch>=0.4.1
- torchvision>=0.2.1
- dominate>=2.3.1
- visdom>=0.1.8.3
然后pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
指令
bash ./train.sh

训练完后的权重

训练过程中得到的图像

test_unknow_content_latest


images 部分展示

metrics部分展示
测试内容的指标。里面有20个左右字体的指标,以及最终的指标。


测试风格的所得指标数据
每种风格的指标数据
风格的最终指标

test_unknow_style
跟test_unknow_content_latest类似,这里只展示最终的指标
content

style
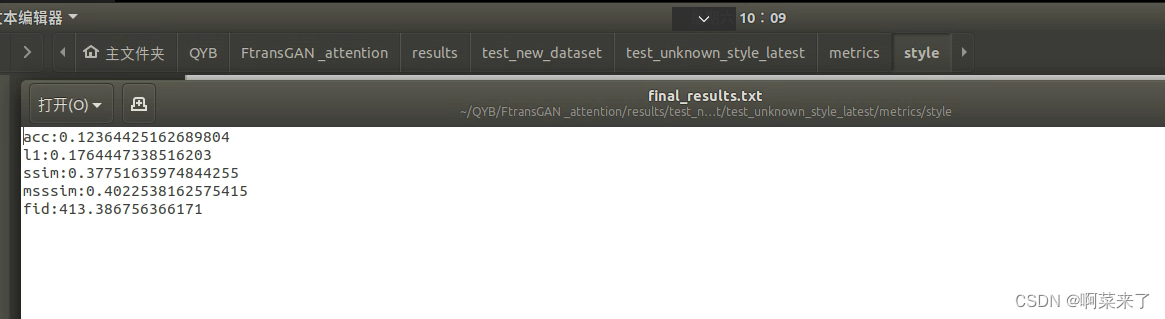
和论文里面的数据相比相差不多。基本能复现出来。
















 1613
1613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











