







- 香港理工大学&bytedance&alibaba
- https://github.com/yangxy/PASD/
- https://arxiv.org/pdf/2308.14469
- 问题引入
- 当前的基于SD的方法缺乏对图片结构的保持,所以本文提出pixel-aware cross atten来引入图片的结构信息,并且引入了degradation removal module来预处理作为生成条件的图片;
- methods

- Degradation Removal Module:提取degradation无关的low level特征作为生成条件,使用一个金字塔形的网络,最后训练通过toRGB的输出和HR做L1损失完成;
- Pixel-Aware Cross Attention (PACA):condition的feature与原始unet进行交互的方式有变化,原始的交互方式通过简单的zero-convolution然后相加实现,但是无法保证图片原有的结构,所以本文提出了另一种方法,对于原始unet和controlnet的feature x , y x,y x,y,首先将两者进行reshape x ′ ∈ R h ∗ w × c , y ′ ∈ R h ∗ w × c x'\in\mathbb{R}^{h*w\times c},y'\in\mathbb{R}^{h*w\times c} x′∈Rh∗w×c,y′∈Rh∗w×c,之后进行cross attention P A C A ( Q , K , V ) = S o f t m a x ( Q K T d ) ⋅ V PACA(Q,K,V) = Softmax(\frac{QK^T}{\sqrt{d}})\cdot V PACA(Q,K,V)=Softmax(dQKT)⋅V,其中 Q = t o Q ( x ′ ) , K = t o K ( y ′ ) , V = t o V ( y ′ ) Q = toQ(x'),K = toK(y'),V = toV(y') Q=toQ(x′),K=toK(y′),V=toV(y′),因为controlnet分支的输入没有经过encoder所以可以比较好的保持图片结构;
- Adjustable Noise Schedule (ANS):测试时候和训练时候的在T时刻z的状态不一样,在测试的时候是纯噪声,所以本文在测试的时候T时刻的z是由LR加噪声得到的;
- High-Level Information:之前的模型将text prompt用null来代替训练超分模型,本文使用resnet yolo和blip来获取信息代替;
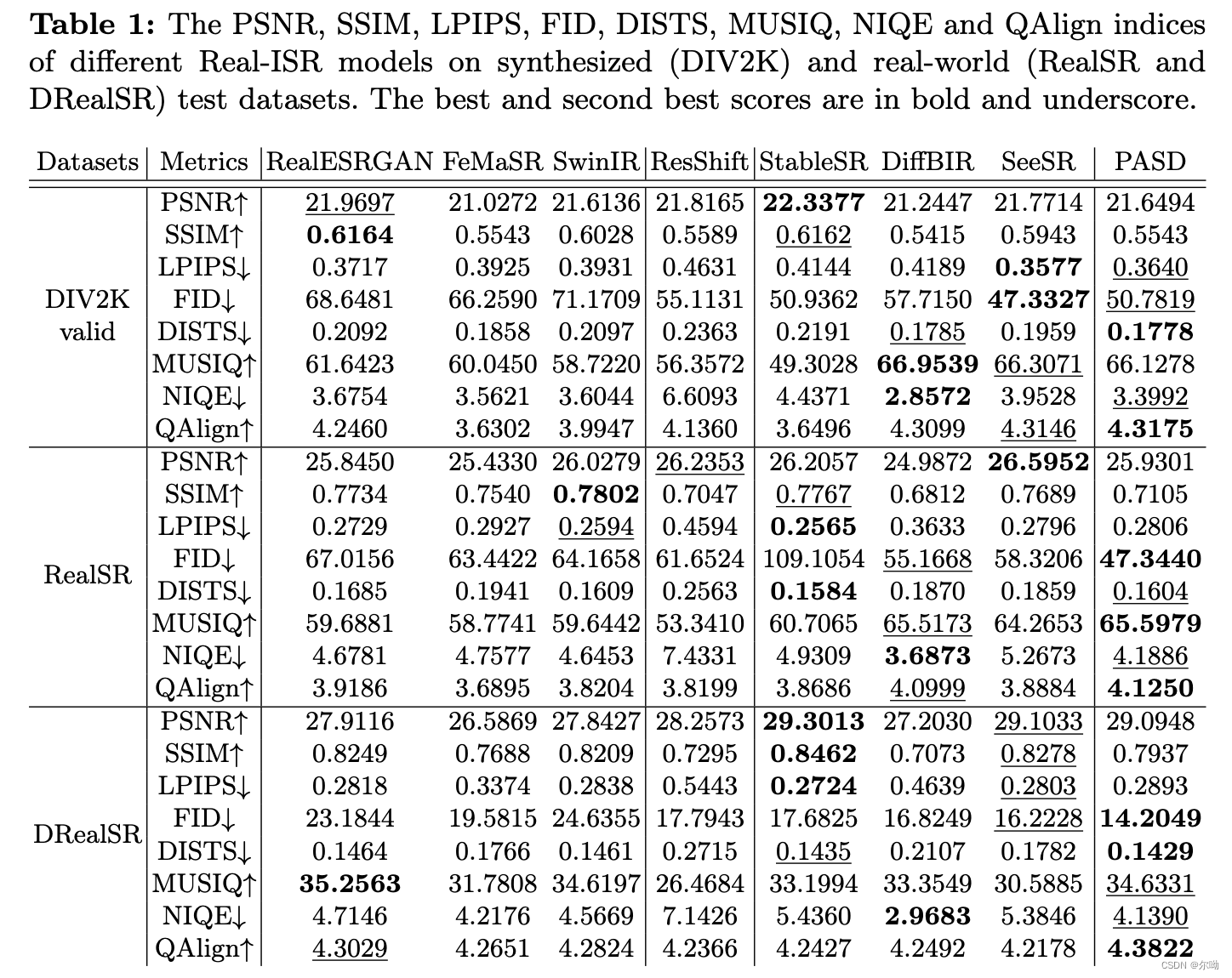
- 实验















 4557
4557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









