









由于好久没有复习过基础知识点,些许的概念有点模糊,第一节课主要做了复习
目录
知识点复习及补充
注意力机制
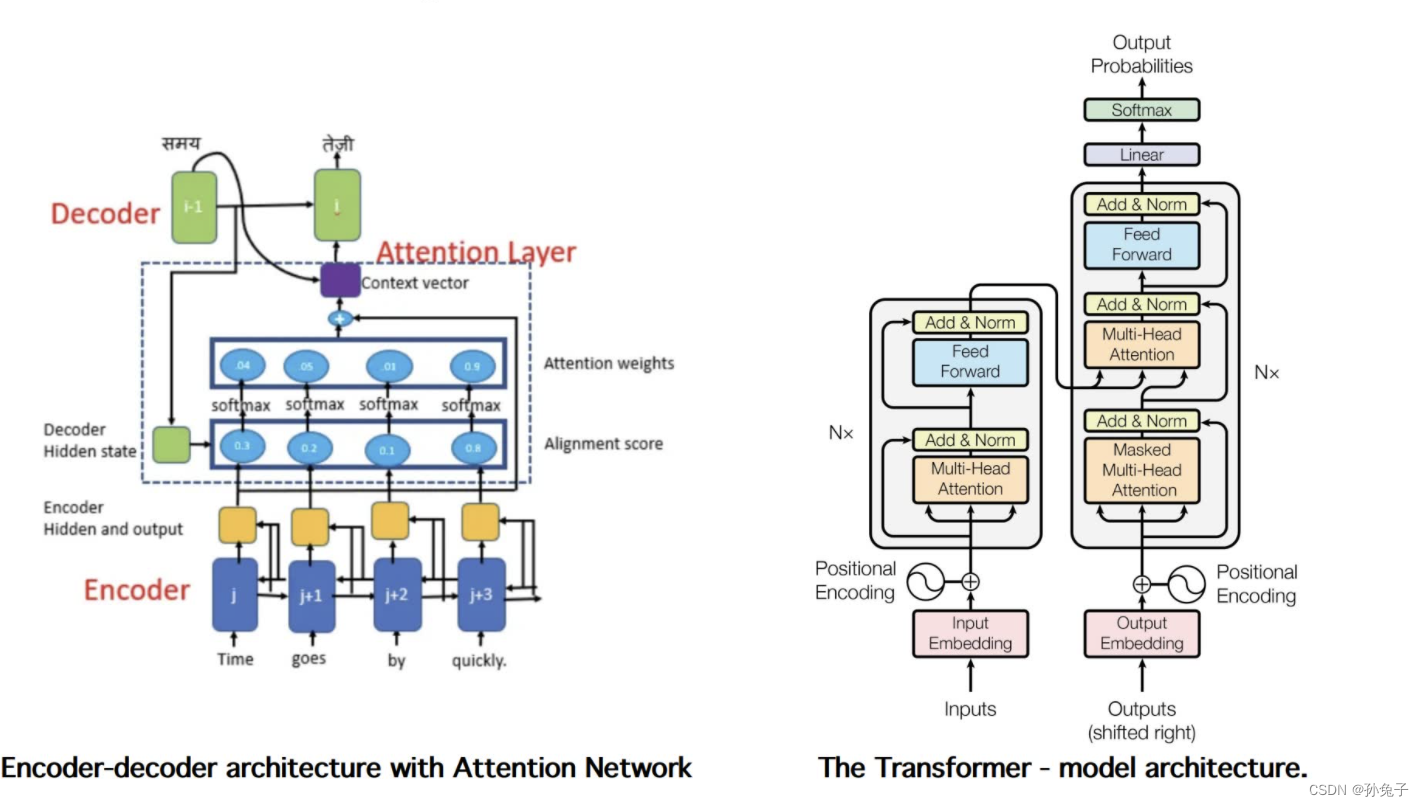
每个神经元的输出不仅仅取决于前一层的所有神经元的输出,还可以根据输入数据的不同部分进行加权,即对不同部分赋予不同的权重。这样可以使模型更加关注输入序列中的关键信息,从而提高模型的精度和效率。
通俗的说注意力机制可以理解为找重点,但是高频出现的词语并不等于重点。
打个比方,面前有两份面,一个加了卤蛋,另一个加了卤蛋和牛肉,在你特别喜欢吃牛肉的情况下,第二碗牛肉面在你心里的权重就增加了,你会更趋于选第二碗面
而且,在上述话中,牛肉出现的频率也挺高,但面是关键词。
Self-attention
自注意力机制(Self-Attention)是一种常用的注意力机制,它主要用于处理序列数据,可以在不同的时间步上计算出不同位置的注意力权重,从而将所有时间步的信息进行整合和交互。
(真正的理解语言)传话中要理解意思,不要丢词
Multi-head Attention
多头机制扩展了模型集中于不同位置的能力,赋予attention多种子表达方式。
不同方式叠加的学习重点(叠加多个对齐函数)
比如说你想跟你妈妈说中午吃面,你可以喊一句:妈!吃面。也可以选择发微信说中午吃面,还可以给你爸说,中午让我妈做面吃。不同的途径,传达了相同的意思,让你妈更明确的知道你是真的想吃面。总之,这个面,中午必须吃上。
Masked-Attention
比如说你说说十个字,后面五个看不见,给一个遮挡。
bert和chat的区别:

相同之处:

BERT的独特价值:
1.全方位上下文理解:与以前的模型(例如GPT)相比,BERT能够双向理解上下文,即同时考虑一个词的左边和右边的上下文。这种全方位的上下文理解使得BERT能够更好地理解语言,特别是在理解词义、消歧等复杂任务上有明显优势。
2.预训练+微调(Pre-training + Fine-tuning)的策略:BERT模型先在大规模无标签文本数据上进行预训练,学习语言的一般性模式,然后在具体任务的标签数据上进行微调。这种策略让BERT能够在少量标签数据上取得很好的效果,大大提高了在各种NLP任务上的表现。
3.跨任务泛化能力:BERT通过微调可以应用到多种NLP任务中,包括但不限于文本分类、命名实体识别、问答系统、情感分析等。它的出现极大地简化了复杂的NLP任务,使得只需一种模型就能处理多种任务。
4.多语言支持:BERT提供了多语言版本(MultilingualBERT),可以支持多种语言,包括但不限于英语、中文、德语、法语等,使得NLP任务能够覆盖更广的语言和区域。
5.性能优异:自BERT模型提出以来,它在多项NLP基准测试中取得了优异的成绩,甚至超过了人类的表现。它的出现标志着NLP领域进入了预训练模型的新时代。
6.开源和可接入性:BERT模型和预训练权重由Google公开发布,让更多的研究者和开发者可以利用BERT模型进行相关研究和应用开发,推动了整个NLP领域的发展。















 547
547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









