







Self-Guided Image Dehazing Using Progressive Feature Fusion
摘要:
提出一个有效的算法,这个算法有三个部分,pre-dehazer, progressive feature fusion module, image restoration,
这三个部分,依次发挥作用。
架构图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Cm4MUFxs-1689085852494)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230711200147442.png)]](https://img-blog.csdnimg.cn/9671051c2a9549a68876949bba3c5ddb.png)
1、Pre-dehazer:由大气散射模型变形得到如下公式:
J
(
x
)
=
I
(
x
)
1
t
(
x
)
+
A
−
A
t
(
x
)
J(x) = I(x)\frac{1}{t(x)}+A-\frac{A}{t(x)}
J(x)=I(x)t(x)1+A−t(x)A
作者认为:理想状态下,A应该是一个常数,而在理想状态下,A只会影响颜色,而不会影响结构。所以用A=1就可以得到一个具有结构信息的图像,而为了更加精确地估计
t
(
x
)
t(x)
t(x),本文预测
W
(
x
)
W(x)
W(x),来代替
t
(
x
)
t(x)
t(x),所以得到如下公式:
J
(
x
)
=
I
(
x
)
1
W
(
x
)
+
1
−
1
W
(
x
)
J(x) = I(x)\frac{1}{W(x)}+1-\frac{1}{W(x)}
J(x)=I(x)W(x)1+1−W(x)1
两式结合得到
W
W
W的表达式:
W
(
x
)
=
t
(
x
)
(
I
(
x
)
−
1
)
t
(
x
)
(
A
−
1
)
+
I
(
x
)
−
A
W(x) = \frac{t(x)(I(x)-1)}{t(x)(A-1)+I(x)-A}
W(x)=t(x)(A−1)+I(x)−At(x)(I(x)−1)
然后利用一个神经网络来预测
W
(
x
)
W(x)
W(x),这里就和2017年ICCV的AODNet一样,结合大气散射模型和神经网络,就已经可以得到一个相对比较不错的结果。
下面就是Pre-dehazer的架构图,同时也是Image Resrtoration的架构图,区别就是第一个卷积核不一样
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Nyyxerst-1689085852495)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230711214709445.png)]](https://img-blog.csdnimg.cn/4732afcc19224032b8839b3b8b5d7ffe.png)
2、progressive feature fusion module
首先是PFF之前有一个特征提取的操作,在代码中是
F
e
a
t
u
r
e
=
s
e
l
f
.
R
e
s
b
l
o
c
k
(
s
e
l
f
.
r
e
l
u
(
s
e
l
f
.
c
o
n
v
(
x
)
)
)
Feature = self.Resblock(self.relu(self.conv(x)))
Feature=self.Resblock(self.relu(self.conv(x)))
在代码中,一个PFF模块包括两个UAF模块,下图是UAF的架构图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oIaFSDWA-1689085852496)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230711221155042.png)]](https://img-blog.csdnimg.cn/27c2c9293fc54d7087331deb1be98231.png)
损失函数
损失函数有三个:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jVaYrw5T-1689085852497)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230711221453490.png)]](https://img-blog.csdnimg.cn/6cb5d17ac40549d2922e625316032395.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U4VyjeNT-1689085852498)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230711221459937.png)]](https://img-blog.csdnimg.cn/d828ad36abe940cea1afaf62ae60ef06.png)
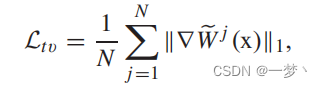
分别是L1损失,L1损失包括恢复图的损失,和参考图的损失, L g r a d L_{grad} Lgrad为边缘损失, L t v L_{tv} Ltv是对 W W W的梯度损失
最终损失;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lPvYnhVb-1689085852499)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230711221717826.png)]](https://img-blog.csdnimg.cn/8c688c4a3024494fae3ab99815ac23d3.png)
超参数分别是1,0.1,0.05.
训练方法
网络首先训练 N r N_r Nr,其初始学习率为1e-5,然后再联合训练整个网络。batchsize为8,epoch为200,训练集图像大小为256,测试集为512。
总结
剩下的一些表格和摘要可以直接看原文,总的来看这篇文章的思路很明确,但是其对比实验似乎并不多,当时的CVPR2020,2021的论文已经有了,那FFANet这个SOTS上有效的网络并没有放上去。总之文章很容易看懂,思想也非常简单,等将代码训练好将继续更新下这篇博客,看是否可复现。















 925
925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









