







本内容是基于上篇博客 装饰器 的基础上写的。
上篇博客侧重于装饰器
本博客侧重于文件内容的迅速查找
- 本节内容的数据见电脑F:\python数据\Python海量数据(精缩版) 或 百度网盘“我的数据文件/Python海量数据”
七、普通查找、二分查找、拉格朗日查找
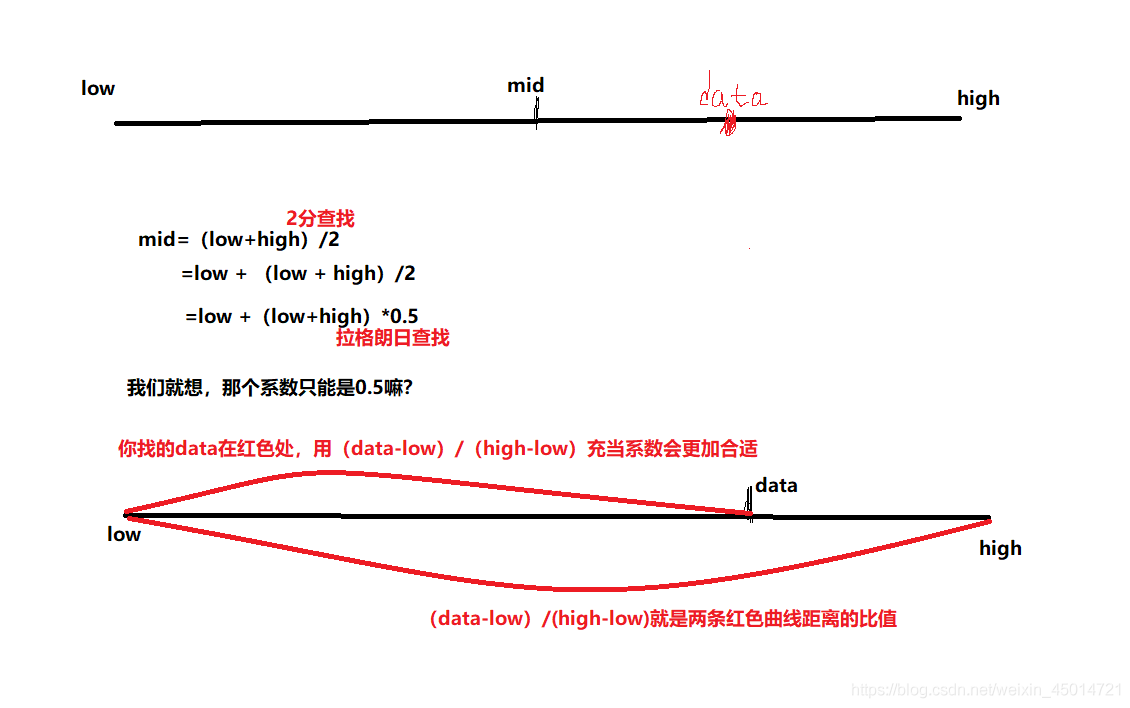
10000个人中有一个人得了新冠肺炎,你要筛选那一个人总不可能是一个一个检测吧?
将10000分成两拨,五千个一起检测,然后把有病毒的5000个样本中分成两拨,2500个的检测。。。
这就是2分查找
拉格朗日查找就是2分查找的公式改变
1.普通的方式查找一个数
import time
def costTime(func):
def _costTime(finddata,findlist):
starttime=time.time()
func(finddata,findlist)
endtime=time.time()
print(endtime-starttime)
return _costTime
@costTime
def search(finddata,findlist):
for data in findlist:
if data==finddata:
print("find",data)
return
print("not find")
findlist=[x for x in range(100000)]
while True:
finddata=eval(input("data"))
search(finddata,findlist)

2.用二分查找
import time
def costTime(func):
def _costTime(finddata,findlist):
starttime=time.time()
func(finddata,findlist)
endtime=time.time()
print(endtime-starttime)
return _costTime
@costTime #这是2分查找,2分查找就是在0-100里面找56的位置时,直接比较(0+100)/2=50和56的大小
def search2(finddata,findlist):
low=0 #第一个
high=len(findlist)-1 #代表最后一个
times=0
while low<=high: #不能重叠
times+=1
print("times",times) #记录查询的次数
mid=(low+high)//2 #取出中间索引
middata=findlist[mid] #取出中间数据
if finddata <middata: #小于 淘汰1半
high =mid-1
elif finddata >middata: #小于 淘汰1半
low =mid+1
else:
print("find",finddata,mid)
return mid
print("not find")
return -1
findlist=[x for x in range(100000)]
while True:
finddata=eval(input("data"))
search2(finddata,findlist)

import time
def costTime(func):
def _costTime(finddata,findlist):
starttime=time.time()
func(finddata,findlist)
endtime=time.time()
print(endtime-starttime)
return _costTime
@costTime #这是拉格朗日的查找方法
def search2lr(finddata,findlist):
low=0 #第一个
high=len(findlist)-1 #代表最后一个
times=0
while low<=high: #不能重叠
times+=1
print("times",times)
#mid=(low+high)//2 #取出中间索引
datamid=((finddata-low)/(high-low))
mid = int(low + (high - low) * datamid)
middata=findlist[mid] #取出中间数据
if finddata <middata: #小于 淘汰1半
high =mid-1
elif finddata >middata: #小于 淘汰1半
low =mid+1
else:
print("find",finddata,mid)
return mid
print("not find")
return -1
findlist=[x for x in range(100000)]
while True:
finddata=eval(input("data"))
search2lr(finddata,findlist)
八、例题
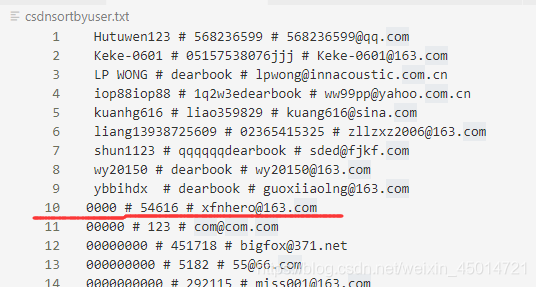
1.先对文件进行排序
//我们把csdn里面的数据按照用户的字母顺序排序
def getuser(line):
line=line.decode("gbk","ignore")
linelist=line.split(" # ")
return linelist[0]
inputfilepath="E:\python数据分析\百度网盘\Python数据分析海量数据营销day2\Python数据分析海量数据营销day2\Search\csdn.txt"
outputfilepath="E:\python数据分析\百度网盘\Python数据分析海量数据营销day2\Python数据分析海量数据营销day2\Search\csdnsortbyuser.txt"
csdninputfile=open(inputfilepath,"rb")
csdnlist=csdninputfile.readlines()
csdninputfile.close()
print("读取完成")
csdnlist.sort(key=lambda x :getuser(x))
print("排序完成")
csdnoutputfile=open(outputfilepath,"wb")
for line in csdnlist:
csdnoutputfile.write(line)
csdnoutputfile.close()
2.快速查询文件里面的某一行内容

filepath="E:\python数据分析\百度网盘\Python数据分析海量数据营销day2\Python数据分析海量数据营销day2\Search\csdnsortbyuser.txt"
csdninputfile=open(filepath,"rb")
csdnlist=csdninputfile.readlines()
lengthlist=[0] #第一行的索引为0
for line in csdnlist:
lengthlist.append(len(line)) #读取每一行的长度到数组
i=1
length=len(lengthlist)
while i <length -1: #舍弃了最后一行
lengthlist[i]=lengthlist[i-1]+lengthlist[i] #叠加,确定每一行的文件位置
i+=1
while True:
linenum=eval(input("input lines: ")) #输入你想直接跳到的行数
csdninputfile.seek(lengthlist[linenum-1],0) #seek可以直接跳到某一行的位置
line=csdninputfile.readline()#读取那一行的信息
print(line)
csdninputfile.close()

3.利用二分查找,根据文件里面的某一行内容快速定位这一行所在的位置
def search2(searchstr,lengthlist):
low = 0 # 第一个
high = len(lengthlist) - 1 # 代表最后一个
times = 0
while low <= high: # 不能重叠
times += 1
print("times", times)
mid = (low + high) // 2 # 取出中间索引
midindex=lengthlist[mid] #取出位置,
csdninputfile.seek(midindex,0) #移动到位置
line=csdninputfile.readline() #读取以行
line=line.decode("gbk","ignore") #解码
linelist=line.split(" # ")#切割
middata=linelist[0] #挖出user,按照user
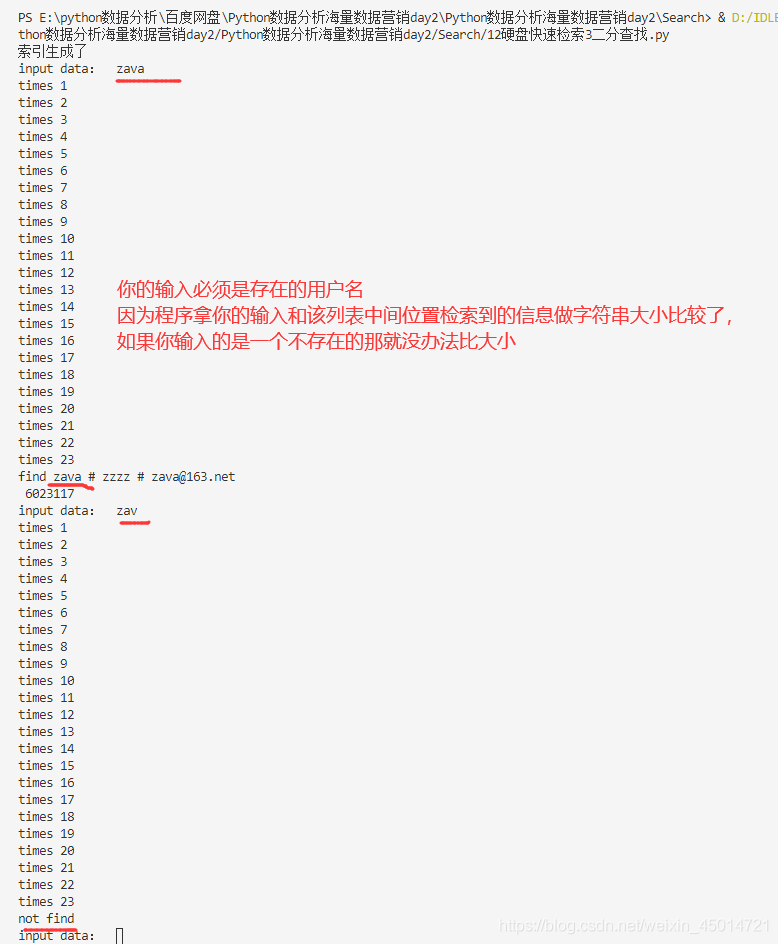
if searchstr< middata: # 小于 淘汰1半
high = mid - 1
elif searchstr > middata: # 小于 淘汰1半
low = mid + 1
else:
print("find", line, mid)
return mid
print("not find")
return -1
filepath="E:\python数据分析\百度网盘\Python数据分析海量数据营销day2\Python数据分析海量数据营销day2\Search\csdnsortbyuser.txt"
csdninputfile=open(filepath,"rb")
csdnlist=csdninputfile.readlines()
lengthlist=[0]
for line in csdnlist:
lengthlist.append(len(line)) #读取每一行的长度到数组
i=1
length=len(lengthlist)
while i <length -1:
lengthlist[i]+=lengthlist[i-1] #叠加,确定每一行的文件位置
i+=1
print("索引生成了")
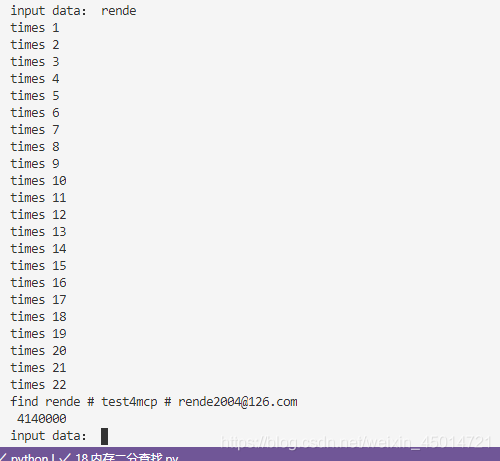
while True:
searchstr=input("input data: ") #根据用户名查找,你输入一个存在的用户名然后来查找
search2(searchstr,lengthlist)
csdninputfile.close()
上面的内容是基于几百万的数据,你可以把索引存到一个列表里,下面我们要搞17亿的数据
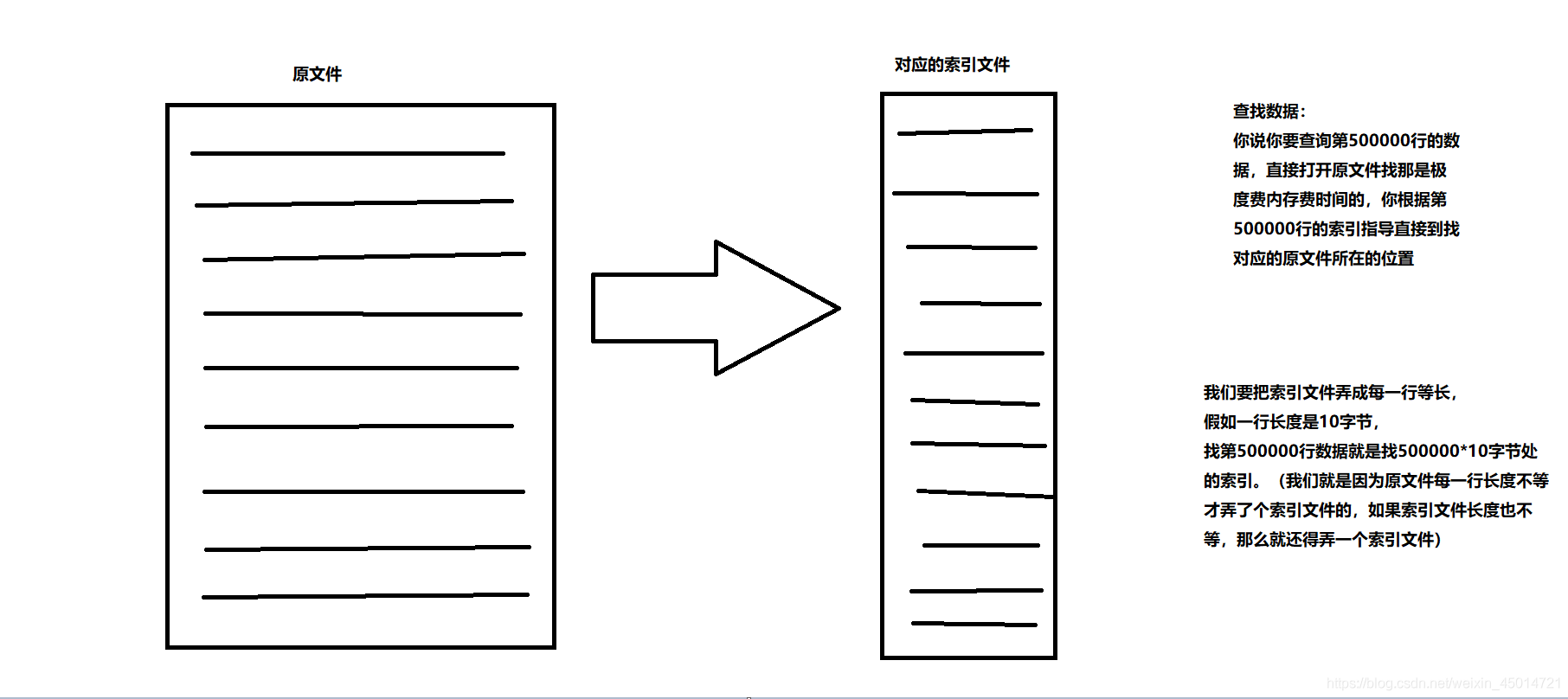
基本思想是根据文件里面的数据生成一个索引文件(把索引放到文件里),根据索引文件来查找那些特定行的数据
一、根据数据生成索引文件
filepath="E:\python数据分析\百度网盘\Python数据分析海量数据营销day3\Python数据分析海量数据营销day3\Search\csdnsortbyuser.txt"
csdninputfile=open(filepath,"rb")
csdnlist=csdninputfile.readlines()
lengthlist=[0]
for line in csdnlist:
lengthlist.append(len(line)) #读取每一行的长度到数组
i=1
length=len(lengthlist)
while i <length -1:
lengthlist[i]+=lengthlist[i-1] #叠加,确定每一行的文件位置
i+=1
indexfilepath="E:\python数据分析\百度网盘\Python数据分析海量数据营销day3\Python数据分析海量数据营销day3\Search\csdnsortbyuserindex.txt"
saveindexfile=open(indexfilepath,"wb")
for i in range(len(lengthlist)-1):
saveindexfile.write(format(lengthlist[i],"10d").encode("utf-8"))#保存为等长,为了随机访问(我们知道原文件每一行都不是等长的,我们生成的索引文件里面的每个数据就必须是等长的,方便查找)
saveindexfile.close()
csdninputfile.close()

二、根据索引文件快速访问某一行数据
csdnfilepath="E:\python数据分析\百度网盘\Python数据分析海量数据营销day3\Python数据分析海量数据营销day3\Search\csdnsortbyuser.txt"
csdnindexfilepath="E:\python数据分析\百度网盘\Python数据分析海量数据营销day3\Python数据分析海量数据营销day3\Search\csdnsortbyuserindex.txt"
csdnfile=open(csdnfilepath,"rb")
csdnindexfile=open(csdnindexfilepath,"rb")
while True:
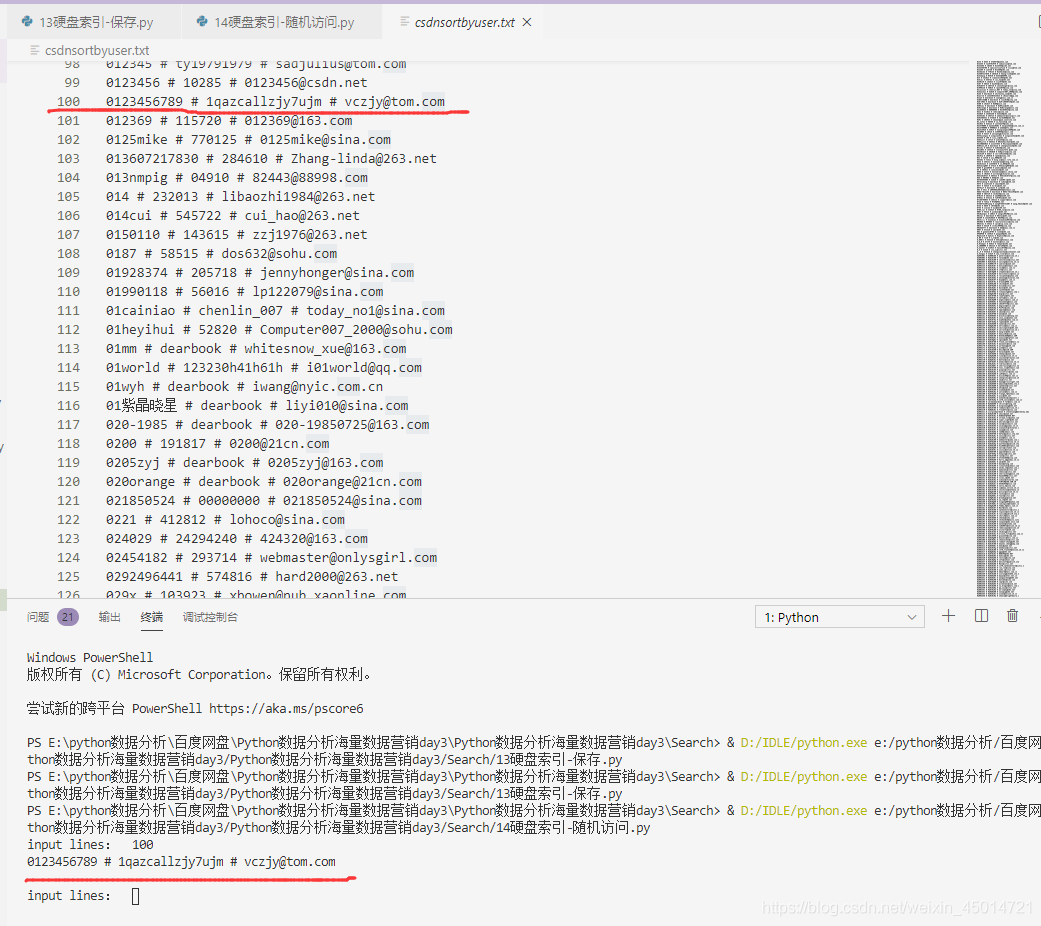
linenum=eval(input("input lines: "))
csdnindexfile.seek(10*(linenum-1),0) #跳到索引文件的中间位置(别忘了你之前保存的时候是按照"10d"的方式保存的)
lineval=csdnindexfile.read(10)#读取10个字符
lineval=eval(lineval)#转化为数字
csdnfile.seek(lineval,0) #根据索引取出位置
line=csdnfile.readline()
line=line.decode("gbk","ignore")
print(line)
csdnindexfile.close()
csdnfile.close()
三、利用二分查找,根据文件里面的某一行内容快速定位这一行所在的位置
def search2(searchstr):
low = 0 # 第一个
high = 6428632-1 # 代表最后一个
times = 0
while low <= high: # 不能重叠
times += 1
print("times", times)
mid = (low + high) // 2 # 取出中间索引
csdnindexfile.seek(10 * (mid - 1), 0) # 跳到索引文件的中间位置
lineval = csdnindexfile.read(10) # 读取10个字符
lineval = eval(lineval) # 转化为数字
csdnfile.seek(lineval, 0) # 根据索引取出位置
line = csdnfile.readline()
line = line.decode("gbk", "ignore")
linelist=line.split(" # ")
middata=linelist[0]
if searchstr< middata: # 小于 淘汰1半
high = mid - 1
elif searchstr > middata: # 小于 淘汰1半
low = mid + 1
else:
print("find", line, mid)
return mid
print("not find")
return -1
csdnfilepath="E:\python数据分析\百度网盘\Python数据分析海量数据营销day3\Python数据分析海量数据营销day3\Search\csdnsortbyuser.txt"
csdnindexfilepath="E:\python数据分析\百度网盘\Python数据分析海量数据营销day3\Python数据分析海量数据营销day3\Search\csdnsortbyuserindex.txt"
csdnfile=open(csdnfilepath,"rb")
csdnindexfile=open(csdnindexfilepath,"rb")
while True:
searchstr=input("input searchstr: ")
search2(searchstr)
csdnindexfile.close()
csdnfile.close()
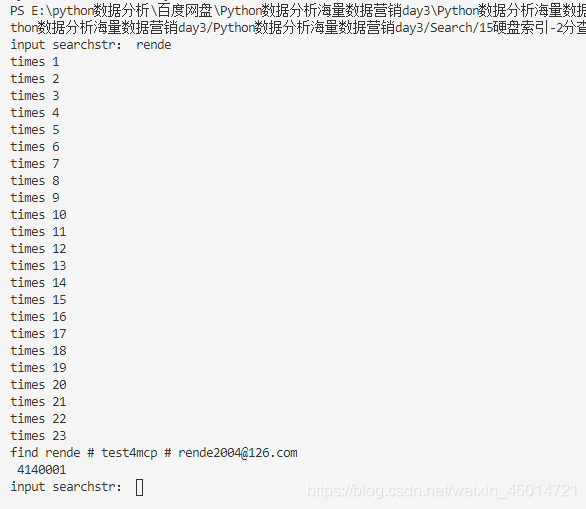
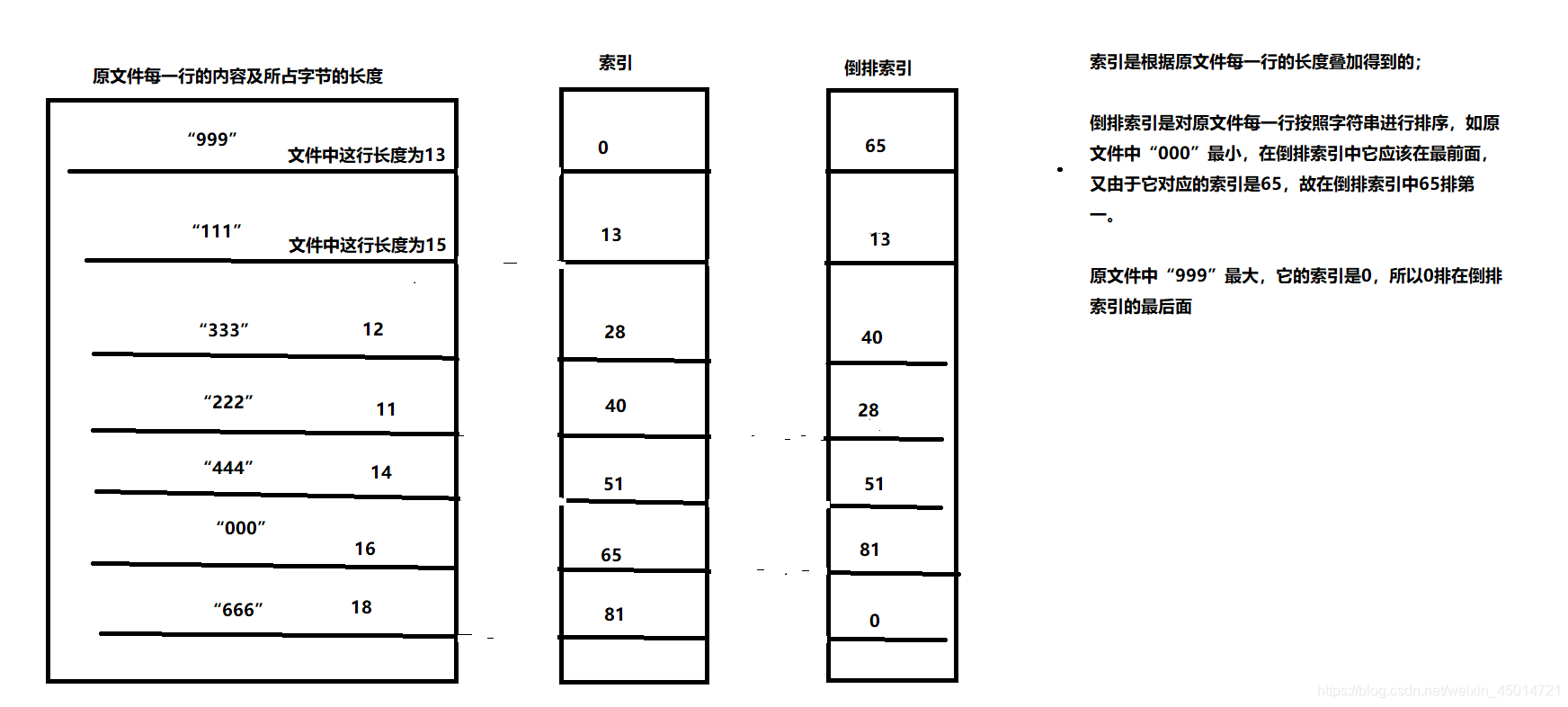
一、倒排索引
def getuser(num):
csdninputfile.seek(num,0) #跳到文件的位置。根据文件排序
line=csdninputfile.readline()
line=line.decode("gbk","ignore")
linelist=line.split(" # ")
return linelist[0]
filepath="E:\python数据分析\百度网盘\Python数据分析海量数据营销day3\Python数据分析海量数据营销day3\Search\csdn.txt"
csdninputfile=open(filepath,"rb")
csdnlist=csdninputfile.readlines()
lengthlist=[0]
for line in csdnlist:
lengthlist.append(len(line)) #读取每一行的长度到数组
i=1
length=len(lengthlist)
while i <length -1:
lengthlist[i]+=lengthlist[i-1] #叠加,确定每一行的文件位置
i+=1
lengthlist.sort(key=lambda x:getuser(x))#根据文件排序索引,
'''
csdninputfile是原文件,lengthlist是索引
注意:lengthlist.sort(key=lambda x:getuser(x))中的x是索引列表lenglist里的每一个元素,getuser(x)就是根据索引得到对应的csdninputfile里的那一行的元素,
lengthlist.sort(key=lambda x:getuser(x))的计算机理是先算key=lambda x:getuser(x)再算lengthlist.sort()
C = [('e', 4, 2), ('a', 2, 1), ('c', 5, 4), ('b', 3, 3), ('d', 1, 5)]
print(sorted(C, key=lambda x: x[2]))
[('a', 2, 1), ('e', 4, 2), ('b', 3, 3), ('c', 5, 4), ('d', 1, 5)]
'''
print("index made")
while True:
linenum=eval(input("input lines"))
csdninputfile.seek(lengthlist[linenum],0) #跳到某一行的位置
line=csdninputfile.readline()#读取1行
print(line)
csdninputfile.close()
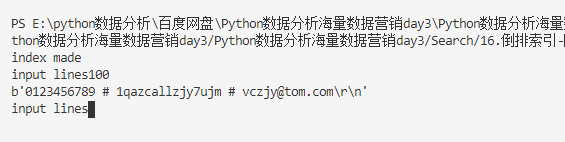
二、生成倒排索引文件
def getuser(num):
csdninputfile.seek(num,0) #跳到文件的位置。根据文件排序
line=csdninputfile.readline()
line=line.decode("gbk","ignore")
linelist=line.split(" # ")
return linelist[0]
filepath="E:\python数据分析\百度网盘\Python数据分析海量数据营销day3\Python数据分析海量数据营销day3\Search\csdn.txt"
csdninputfile=open(filepath,"rb")
csdnlist=csdninputfile.readlines()
lengthlist=[0]
for line in csdnlist:
lengthlist.append(len(line)) #读取每一行的长度到数组
del csdnlist #及时清理不用的东西,清理内存
i=0
length=len(lengthlist)
while i <length -1:
lengthlist[i+1]+=lengthlist[i] #叠加,确定每一行的文件位置
i+=1
del lengthlist[len(lengthlist)-1] #删除最后一个(你可以看看,最后一个就不是索引了)
lengthlist.sort(key=lambda x:getuser(x))#根据文件排序索引,
print("index made")
indexfilepath="E:\python数据分析\百度网盘\Python数据分析海量数据营销day3\Python数据分析海量数据营销day3\Search\csdnsortindex.txt"
saveindexfile=open(indexfilepath,"wb")
for i in range(len(lengthlist)-1):
#保存为等长,为了随机访问
saveindexfile.write(format(lengthlist[i],"10d").encode("utf-8")) #按照十个字节的长度存储进去
saveindexfile.close()

三、用二分查找
1.内存二分查找
什么叫做内存二分查找?你把索引存放到一个列表lengthlist里,这不就是存到内存里了吗?
什么叫硬盘二分查找?你把索引存放到一个文件里面,这不就是存放到硬盘里了吗?
倒排索引就相当于对原文件按照字符串大小进行排好序了,只要是按照文件内容排好序的都可以用2分查找快速定位
def search2(searchstr,lengthlist):
low = 0 # 第一个
high = len(lengthlist) - 1 # 代表最后一个
times = 0
while low <= high: # 不能重叠
times += 1
print("times", times)
mid = (low + high) // 2 # 取出中间索引
midindex=lengthlist[mid] #取出位置,
csdninputfile.seek(midindex,0) #移动到位置
line=csdninputfile.readline() #读取以行
line=line.decode("gbk","ignore") #解码
linelist=line.split(" # ")#切割
middata=linelist[0] #挖出user,按照user
if searchstr< middata: # 小于 淘汰1半
high = mid - 1
elif searchstr > middata: # 小于 淘汰1半
low = mid + 1
else:
print("find", line, mid)
return mid
print("not find")
return -1
def getuser(num):
csdninputfile.seek(num,0) #跳到文件的位置。根据文件排序
line=csdninputfile.readline()
line=line.decode("gbk","ignore")
linelist=line.split(" # ")
return linelist[0]
filepath="E:\python数据分析\百度网盘\Python数据分析海量数据营销day3\Python数据分析海量数据营销day3\Search\csdn.txt"
csdninputfile=open(filepath,"rb")
csdnlist=csdninputfile.readlines()
lengthlist=[0]
for line in csdnlist:
lengthlist.append(len(line)) #读取每一行的长度到数组
del csdnlist
i=0
length=len(lengthlist)
while i <length -1:
lengthlist[i+1]+=lengthlist[i] #叠加,确定每一行的文件位置
i+=1
del lengthlist[len(lengthlist)-1] #删除最后一个
lengthlist.sort(key=lambda x:getuser(x))#根据文件排序索引,
print("index made")
while True:
searchstr=input("input data")
search2(searchstr,lengthlist)
csdninputfile.close()
2.硬盘二分查找
什么叫做内存二分查找?你把索引存放到一个列表lengthlist里,这不就是存到内存里了吗?
什么叫硬盘二分查找?你把索引存放到一个文件里面,这不就是存放到硬盘里了吗?
def search2(searchstr):
low = 0 # 第一个
high = 6428632-1 # 代表最后一个
times = 0
while low <= high: # 不能重叠
times += 1
print("times", times)
mid = (low + high) // 2 # 取出中间索引
csdnindexfile.seek(10 * (mid - 1), 0) # 跳到索引文件的中间位置
lineval = csdnindexfile.read(10) # 读取10个字符
lineval = eval(lineval) # 转化为数字
csdnfile.seek(lineval, 0) # 根据索引取出位置
line = csdnfile.readline()
line = line.decode("gbk", "ignore")
linelist=line.split(" # ")
middata=linelist[0]
if searchstr< middata: # 小于 淘汰1半
high = mid - 1
elif searchstr > middata: # 小于 淘汰1半
low = mid + 1
else:
print("find", line, mid)
return mid
print("not find")
return -1
csdnfilepath="E:\python数据分析\百度网盘\Python数据分析海量数据营销day3\Python数据分析海量数据营销day3\Search\csdn.txt"
csdnindexfilepath="E:\python数据分析\百度网盘\Python数据分析海量数据营销day3\Python数据分析海量数据营销day3\Search\csdnsortindex.txt"
csdnfile=open(csdnfilepath,"rb")
csdnindexfile=open(csdnindexfilepath,"rb")
while True:
searchstr=input("input searchstr: ")
search2(searchstr)
csdnindexfile.close()
csdnfile.close()

















 1888
1888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











