







文章目录
前言
最近一直再学习ftrace,记录学习下来的知识。
Linux下追踪技术简图:
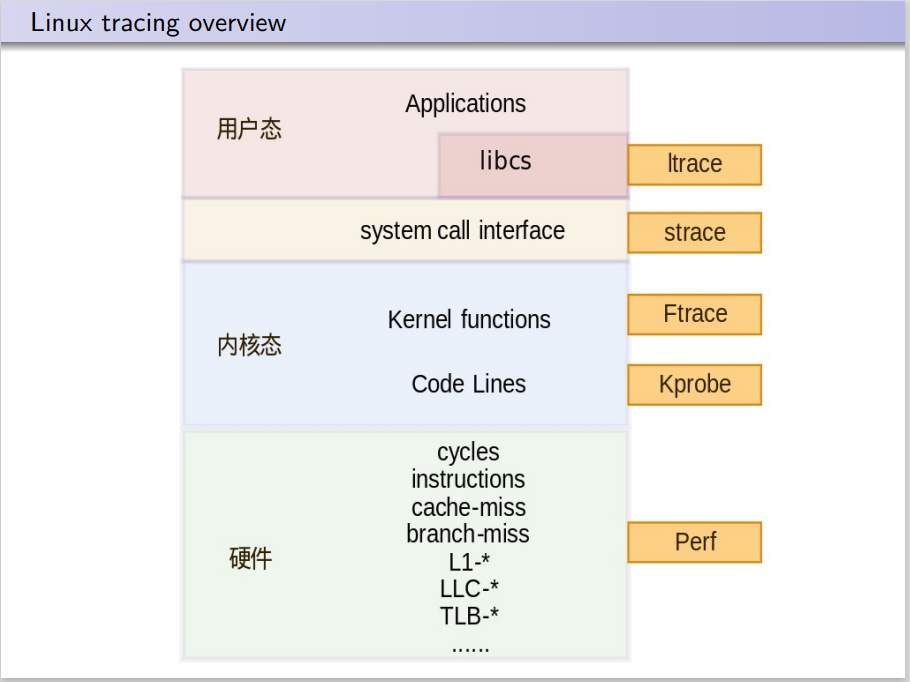
ltrace 用来跟踪进程的库函数。
ltrace - A library call tracer
比如我们常用的strace,用来跟踪进程的系统调用,以及其参数和返回代码。
strace - trace system calls and signals
一、Event Sources
根据事件类型的不同,追踪技术所使用的事件源,可以分为静态探针、动态探针以及硬件事件等三类。可以检测的不同事件源和事件如下图所示:
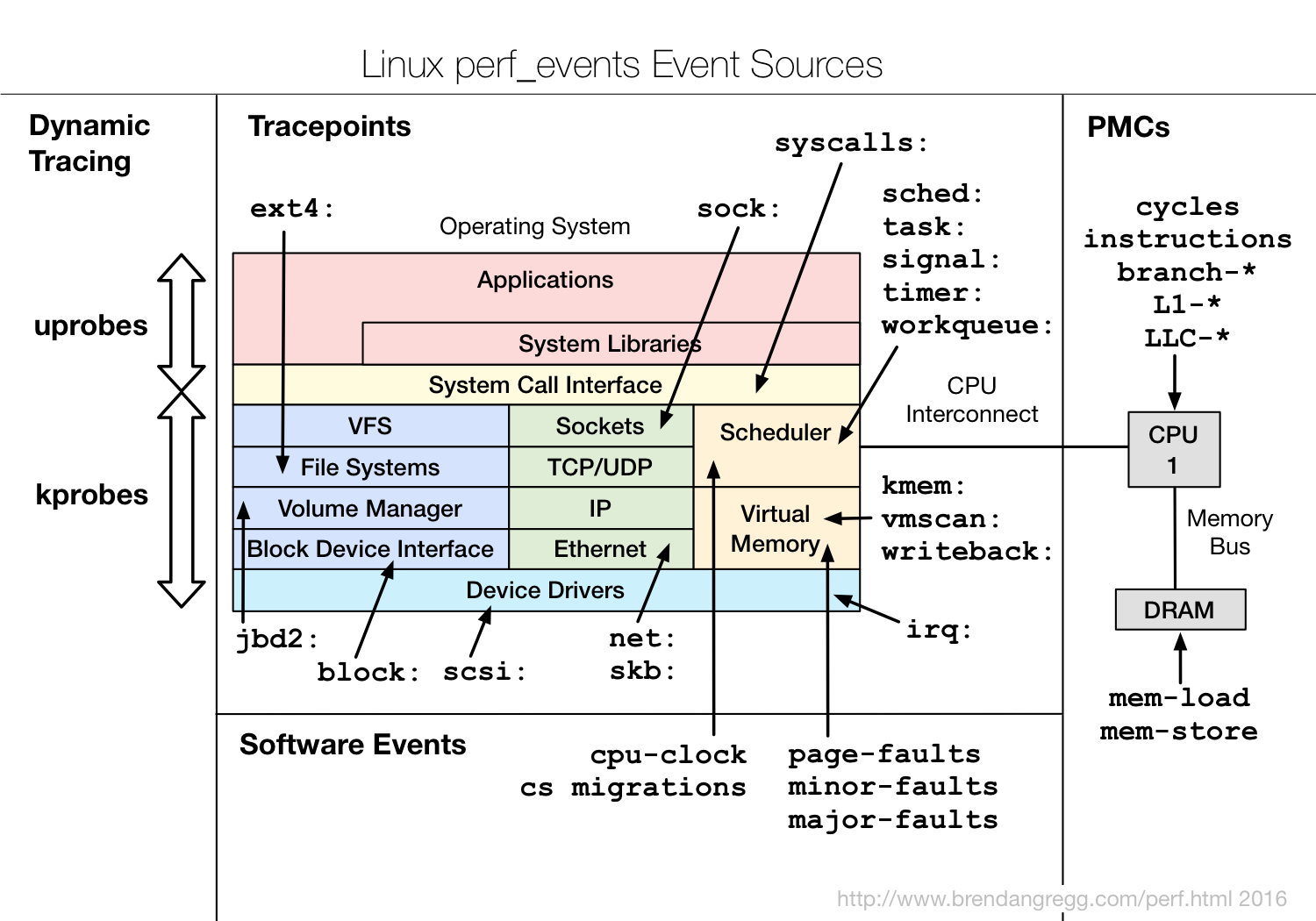
1.1 硬件事件
通常由性能监控计数器 Performance monitoring counters (PMCs)产生,指处理器上的可编程硬件计数器,包括了各种硬件的性能情况,比如 CPU 的缓存、指令周期、分支预测等等。
PMCs 是性能分析的重要资源。只用通过PMC才能测量CPU指令执行的效率,CPU缓存命中率、内存/数据互联和设备总线的利用率,以及阻塞的指令周期等。在性能分析方面使用这些方法可以进行各种性能优化。
1.2 静态探针
是指事先在代码中定义好,并编译到应用程序或者内核中的探针。这些探针只有在开启探测功能时,才会被执行到;未开启时并不会执行。常见的静态探针包括内核中的跟踪点(tracepoints)和 USDT(User-level statically defined tracing)探针。
(1)跟踪点(tracepoints)是内核静态插桩技术,跟踪点在技术上只是放置在内核源代码中的跟踪函数,实际上就是在源码中插入的一些带有控制条件的探测点,这些探测点允许事后再添加处理函数。比如在内核中,最常见的静态跟踪方法就是 printk,即输出日志。又比如:在系统调用、调度程序事件、文件系统操作和磁盘 I/O 的开始和结束时都有跟踪点。 于 2009 年在 Linux 2.6.32 版本中首次提供。跟踪点是一种稳定的 API,数量有限。
(2)USDT(User-level statically defined tracing)探针,全称是用户级静态定义跟踪, 提供了一个用户空间版的跟踪点机制,需要在源码中插入 DTRACE_PROBE() 代码,并编译到应用程序中。
1.3 动态探针
则是指没有事先在代码中定义,但却可以在运行时动态添加的探针,比如函数的调用和返回等。动态探针支持按需在内核或者应用程序中添加探测点,具有更高的灵活性。常见的动态探针有两种,即用于内核态的 kprobes 和用于用户态的 uprobes。
(1)kprobes 是内核动态插桩,用来跟踪内核态的函数,/proc/kallsym 中的函数几乎都可以用于跟踪,包括用于函数调用的 kprobe 和用于函数返回的 kretprobe。为非稳定的跟踪机制,数量比较多。
(2)uprobes Uprobes是用户级的动态插桩,用来跟踪用户态的函数,包括用于函数调用的 uprobe 和用于函数返回的 uretprobe。
动态追踪技术,通过探针机制,来采集内核或者应用程序的运行信息,从而可以不用修改内核和应用程序的代码,就获得丰富的信息,帮你分析、定位想要排查的问题。
1.4 Tracing Tools
Linux 跟踪工具使用前面描述的事件探针的基础上(tracepoints、USDT、kprobes、uprobes)进行高级性能分析。 Linux 也提供了一系列的动态追踪机制工具,比如:
(1)perf:官方的 Linux 分析器。 它非常适合 CPU 分析(堆栈跟踪采样)和 PMC 分析,并且可以检测其他事件,通常记录到输出文件以进行后处理。
(2)ftrace:官方的 Linux 追踪器,它是一个由不同的追踪工具组成的多功能工具。 它适用于内核代码路径分析和资源受限的系统,因为它可以在没有依赖关系的情况下使用。
(3)BPF(eBPF) :它支持高级跟踪工具,主要是 BCC 和 bpftrace。 BCC 提供了强大的工具,而 bpftrace 提供了用于 custom one-liners and short programs的高级语言。
(4)SystemTap:一种高级语言和跟踪器,带有许多用于跟踪不同目标的 Tapsets(库)。是一个允许我们来编写简单的脚本来检查正在运行的Linux系统活动状态的一个工具,可以快速、安全地提取、过滤和总结数据,以实现复杂性能或功能问题的诊断。
二、Ftrace
2.1 简介
Ftrace 是 Linux 官方提供的跟踪工具,用来 trace 内核中的函数的,在 Linux 2.6.27 版本中引入。在Ftrace 的基础上,还有很多第三方提供的开源工具,用于简化操作或者提供数据可视化等扩展应用。
Ftrace 是一个内部跟踪器,帮助系统的开发人员和设计人员找到内核内部发生的事情。 它可用于调试或分析发生在用户空间之外的延迟和性能问题。Ftrace最开始是一个函数跟踪器,主要用于记录内核函数运行轨迹;随着功能的逐渐增加,演变成一个跟踪框架,一个包含多种跟踪实用程序的框架(比如:有延迟跟踪来检查中断禁用和启用之间发生的情况,以及抢占以及从任务被唤醒到任务实际调度的时间。)。
框架图如下:
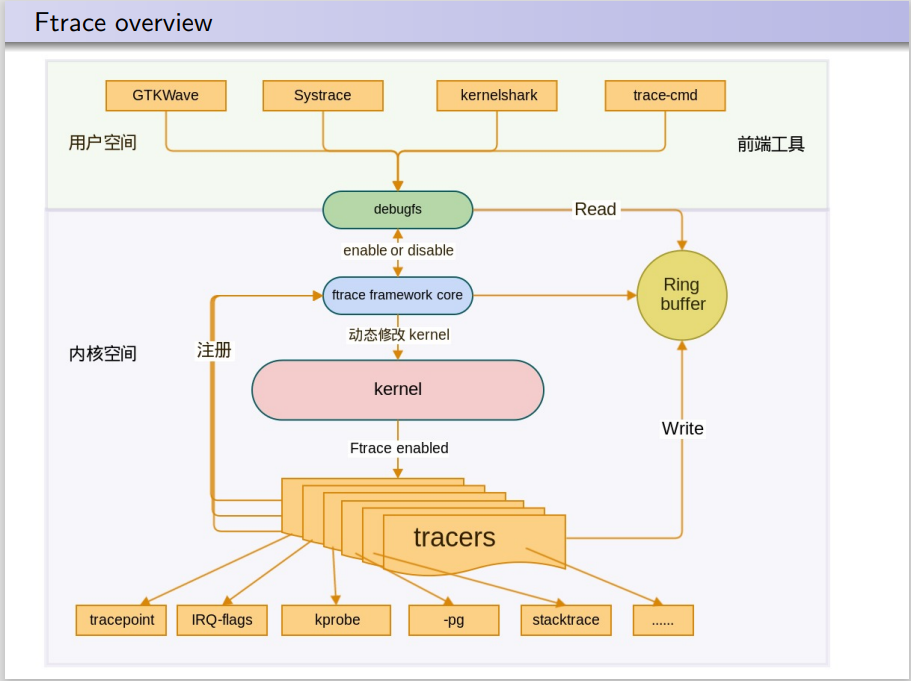
各类tracer往ftrace主框架注册,不同的trace则在不同的probe点把信息通过probe函数给送到Ring buffer中,再由暴露在用户态debufs实现相关控制。
其主要由两部分构成:
(1)ftrace Framework core: 其主要包括利用 debugfs 系统在 /debugfs 下建立 tracing 目录,对用户空间输出 trace 信息,并提供了一系列的控制文件。
(2)一系列的 tracers: 每个 tracer 完成不同的功能,ftrace 的 trace 信息保存在 Ring buffer(内存缓冲区) 中,它们统一由 framework 管理。
ftrace 最常见的用途之一是event跟踪。 在整个内核中,有数百个静态事件点(static event points)可以通过 tracefs (debugfs)文件系统启用,以查看内核某些部分发生了什么。
它可以在没有任何额外的用户级前端的情况下使用,使其特别适用于存储空间非常宝贵的嵌入式 Linux 环境。 它对于服务器环境也很有用。
2.2 funcgraph
trace 跟踪工具由性能分析器(profiler)和跟踪器(tracer)两部分组成:
(1)分析器提供统计摘要,例如计数和直方图。
(2)跟踪器提供每个事件的详细信息。
下图是Ftrace及其前端的概述,箭头显示了从事件到输出类型的路径,
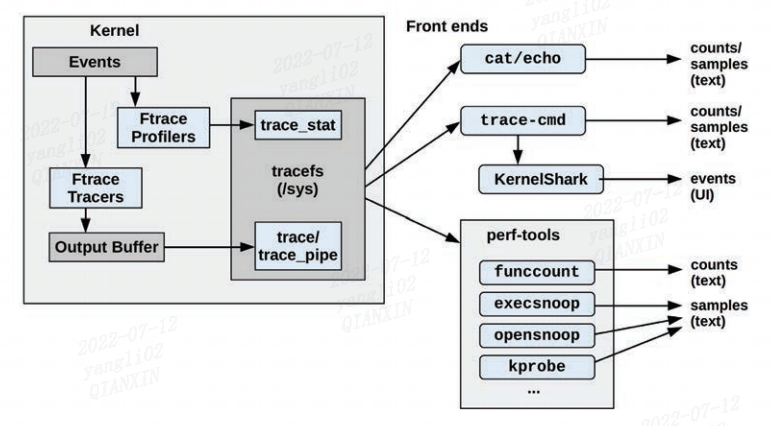
作为 Ftrace 的示例,以下 funcgraph 工具使用 Ftrace 跟踪器来显示 vfs_read() 内核函数的子调用,下载perf-tools:
git clone --depth 1 https://github.com/brendangregg/perf-tools
funcgraph - trace kernel function graph, showing child function calls.
//该工具显示给定内核函数的子函数调用图。 这可能会花费适度的执行开销,并且只应在使用其他开销较低的工具之前用于了解给定函数的内核行为。
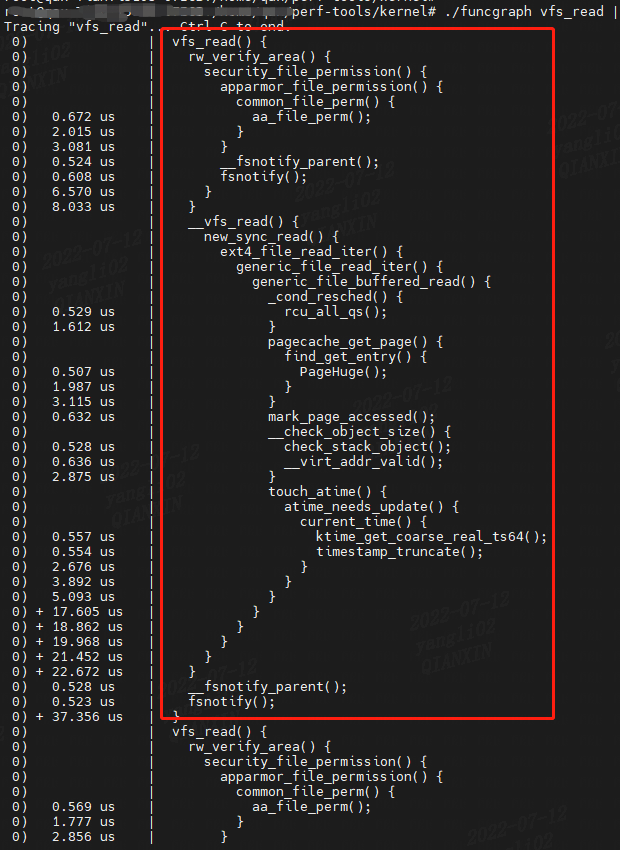
输出显示 vfs_read() 调用了 rw_verify_area(),rw_verify_area()调用了 security_file_permission() 等等。
第二列显示每个函数的持续时间(“us”是微秒),以便您可以进行性能分析,识别导致父函数变慢的子函数,这种特殊的 Ftrace 功能称为函数图跟踪。
2.3 File System
trace通过debugfs(或者tracefs)文件系统向用户空间提供访问接口,因此需要在系统启动时挂载debugfs(tracefs)。不需要额外的工具,你就可以通过挂载点( /sys/kernel/debug/tracing 目录或者/sys/kernel/tracing目录)内的文件读写,来跟 ftrace 交互,跟踪内核或者应用程序的运行事件。
debugfs是Linux内核中一种特殊的文件系统,非常易用、基于RAM,专门设计用于调试.
低版本内核使用debugfs接口,高版本内核使用tracefs接口。
(1) debugfs file system
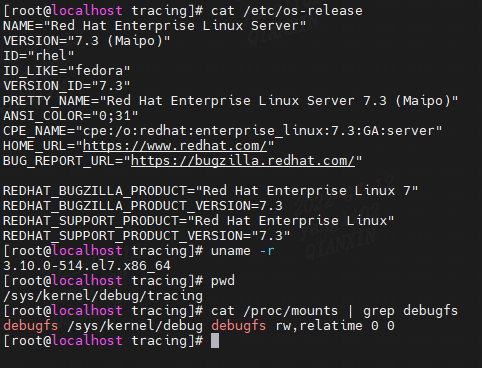
在 linux 内核版本 4.1 之前,所有 ftrace 跟踪控制文件都在 debugfs 文件系统中,该文件系统通常位于 /sys/kernel/debug/tracing。
/sys/kernel/debug/tracing
Linux版本:redhat 7.3 (3.10.0)
(2)tracefs file system
Ftrace 使用 tracefs 文件系统来保存控制文件以及显示输出的文件,当 tracefs 配置到内核中时,目录 /sys/kernel/tracing 将被创建:
/sys/kernel/tracing
Linux版本:ubuntu20.04(5.4.0)

高版本也可以使用 /sys/kernel/debug/tracing 目录,挂载debugfs文件系统时,tracefs文件系统会自动挂载到:
/sys/kernel/debug/tracing

位于 tracefs 文件系统中的所有文件也将位于该 debugfs 文件系统目录中。
备注:后面都以 /sys/kernel/debug/tracing 目录 为基础说明。
(3)
当 tracefs 配置到内核中时,目录 /sys/kernel/tracing 将被创建。 要挂载此目录,您可以添加到 /etc/fstab 文件:
tracefs /sys/kernel/tracing tracefs defaults 0 0
或者您可以在运行时挂载::
mount -t debugfs nodev /sys/kernel/debug/
或者
mount -t tracefs nodev /sys/kernel/tracing
通常tracefs在系统启动时会挂载,因此作为用户我们无需再配置。
三、 /sys/kernel/debug/tracing目录介绍
3.1 目录简介
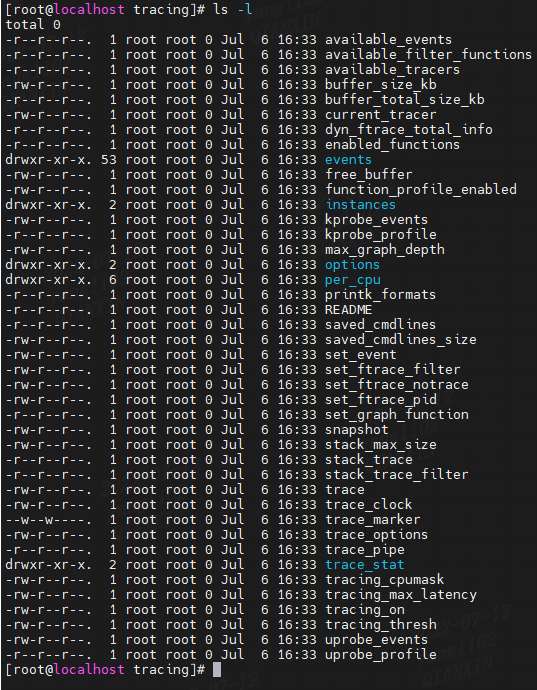
上述目录或者文件有些是各种跟踪器共享使用的,有些是特定于某个跟踪器使用的。在操作这些数据文件时,通常使用 echo 命令来修改其值,也可以在程序中通过文件读写相关的函数来操作这些文件的值。
该目录下有一个mini说明文档:
tracing mini-HOWTO:
# echo 0 > tracing_on : quick way to disable tracing
# echo 1 > tracing_on : quick way to re-enable tracing
Important files:
trace - The static contents of the buffer
To clear the buffer write into this file: echo > trace
trace_pipe - A consuming read to see the contents of the buffer
current_tracer - function and latency tracers
available_tracers - list of configured tracers for current_tracer
buffer_size_kb - view and modify size of per cpu buffer
buffer_total_size_kb - view total size of all cpu buffers
trace_clock -change the clock used to order events
local: Per cpu clock but may not be synced across CPUs
global: Synced across CPUs but slows tracing down.
counter: Not a clock, but just an increment
uptime: Jiffy counter from time of boot
perf: Same clock that perf events use
x86-tsc: TSC cycle counter
trace_marker - Writes into this file writes into the kernel buffer
tracing_cpumask - Limit which CPUs to trace
instances - Make sub-buffers with: mkdir instances/foo
Remove sub-buffer with rmdir
trace_options - Set format or modify how tracing happens
Disable an option by adding a suffix 'no' to the option name
saved_cmdlines_size - echo command number in here to store comm-pid list
available_filter_functions - list of functions that can be filtered on
set_ftrace_filter - echo function name in here to only trace these functions
accepts: func_full_name, *func_end, func_begin*, *func_middle*
modules: Can select a group via module
Format: :mod:<module-name>
example: echo :mod:ext3 > set_ftrace_filter
triggers: a command to perform when function is hit
Format: <function>:<trigger>[:count]
trigger: traceon, traceoff
enable_event:<system>:<event>
disable_event:<system>:<event>
stacktrace
snapshot
example: echo do_fault:traceoff > set_ftrace_filter
echo do_trap:traceoff:3 > set_ftrace_filter
The first one will disable tracing every time do_fault is hit
The second will disable tracing at most 3 times when do_trap is hit
The first time do trap is hit and it disables tracing, the counter
will decrement to 2. If tracing is already disabled, the counter
will not decrement. It only decrements when the trigger did work
To remove trigger without count:
echo '!<function>:<trigger> > set_ftrace_filter
To remove trigger with a count:
echo '!<function>:<trigger>:0 > set_ftrace_filter
set_ftrace_notrace - echo function name in here to never trace.
accepts: func_full_name, *func_end, func_begin*, *func_middle*
modules: Can select a group via module command :mod:
Does not accept triggers
set_ftrace_pid - Write pid(s) to only function trace those pids (function)
set_graph_function - Trace the nested calls of a function (function_graph)
max_graph_depth - Trace a limited depth of nested calls (0 is unlimited)
snapshot - Like 'trace' but shows the content of the static snapshot buffer
Read the contents for more information
stack_trace - Shows the max stack trace when active
stack_max_size - Shows current max stack size that was traced
Write into this file to reset the max size (trigger a new trace)
stack_trace_filter - Like set_ftrace_filter but limits what stack_trace traces
我简单的介绍一下:
current_tracer 用于设置或显示当前使用的跟踪器;使用 echo 将跟踪器名字写入该文件可以切换到不同的跟踪器。系统启动后,其缺省值为 nop ,即不做任何跟踪操作。在执行完一段跟踪任务后,可以通过向该文件写入 nop 来重置跟踪器。
available_tracers 记录了当前编译进内核的跟踪器的列表,可以通过 cat 查看其内容。写 current_tracer 文件时用到的跟踪器名字必须在该文件列出的跟踪器名字列表中。
trace 文件提供了查看获取到的跟踪信息的接口。可以通过 cat 等命令查看该文件以查看跟踪到的内核活动记录,也可以将其内容保存为记录文件以备后续查看。
set_graph_function 设置要清晰显示调用关系的函数,显示的信息结构类似于 C 语言代码,这样在分析内核运作流程时会更加直观一些。在使用 function_graph 跟踪器时使用;缺省为对所有函数都生成调用关系序列,可以通过写该文件来指定需要特别关注的函数。
buffer_size_kb 用于设置单个 CPU 所使用的跟踪缓存的大小。跟踪器会将跟踪到的信息写入缓存,每个 CPU 的跟踪缓存是一样大的。跟踪缓存实现为环形缓冲区的形式,如果跟踪到的信息太多,则旧的信息会被新的跟踪信息覆盖掉。注意,要更改该文件的值需要先将 current_tracer 设置为 nop 才可以。
tracing_on 用于控制跟踪的暂停。有时候在观察到某些事件时想暂时关闭跟踪,可以将 0 写入该文件以停止跟踪,这样跟踪缓冲区中比较新的部分是与所关注的事件相关的;写入 1 可以继续跟踪。
available_filter_functions 记录了当前可以跟踪的内核函数。对于不在该文件中列出的函数,无法跟踪其活动。
set_ftrace_filter和 set_ftrace_notrace 在编译内核时配置了动态 ftrace (选中 CONFIG_DYNAMIC_FTRACE 选项)后使用。前者用于显示指定要跟踪的函数,后者则作用相反,用于指定不跟踪的函数。如果一个函数名同时出现在这两个文件中,则这个函数的执行状况不会被跟踪。这些文件还支持简单形式的含有通配符的表达式,这样可以用一个表达式一次指定多个目标函数;具体使用在后续文章中会有描述。注意,要写入这两个文件的函数名必须可以在文件 available_filter_functions 中看到。缺省为可以跟踪所有内核函数,文件 set_ftrace_notrace 的值则为空。
function_profile_enabled :设置后,它将使用函数跟踪器启用所有函数,或者如果已配置,则使用函数图跟踪器。 它将保留被调用函数数量的直方图,如果配置了函数图跟踪器,它还将跟踪在这些函数中花费的时间。 直方图内容可以显示在文件中:
trace_stat/function<cpu> ( function0, function1, etc).
trace_stat:包含不同跟踪统计信息的目录。
…
3.2 available_tracers

| 名称 | 用途 |
|---|---|
| function | 函数调用追踪器(几乎可以跟踪所有内核函数),可以看出哪个函数何时调用,可以通过过滤器指定要跟踪的函数 |
| function_graph | 与函数跟踪器类似,只是函数跟踪器在函数的入口处探测函数,而函数图跟踪器在函数的入口和出口处跟踪。 然后,它提供了绘制类似于 C 代码源的函数调用图的能力。 |
| blk | 块跟踪器。 blktrace 用户应用程序使用的跟踪器。 |
| hwlat | 硬件延迟跟踪器用于检测硬件是否产生任何延迟 |
| wakeup_dl/wakeup_rt/wakeup | 跟踪进程唤醒信息,进程调度延迟追踪器 deadline/rt/普通进程 |
| nop | 不会跟踪任何内核活动,将 nop 写入 current_tracer 文件可以删除之前所使用的跟踪器,并清空之前收集到的跟踪信息,即刷新 trace 文件 |
其中最重要的两个跟踪器:
(1)function tracer:在函数的入口处探测函数,提供上下文信息和parent function,打印了内核函数调用的每个事件的详细信息。
(2)function_graph tracer:函数的入口和出口处跟踪,打印函数的调用图,揭示代码的流程,展示了内核函数在内核态中的调用流程。
3.3 Ftrace Function Profiler
函数分析器提供有关内核函数调用的统计信息,适用于探索哪些内核函数正在使用并确定哪些是最慢的,我经常使用函数分析器作为了解给定工作负载的内核代码执行的起点,特别是因为它高效且开销相对较低。
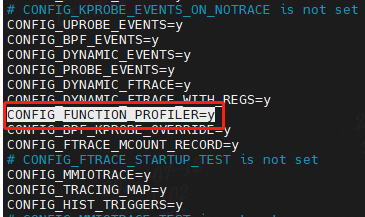
使用它,我可以使用更昂贵的每个事件跟踪来识别要分析的函数。 它需要CONFIG_FUNCTION_PROFILER=y 内核选项:
vim /boot/config-5.4.0-26-generic
函数分析器通过在每个内核函数开始时使用 compiled-in profiling calls 来工作。例如 gcc 的 -pg 选项,它插入 mcount() 调用以与 gprof 一起使用。 从 gcc 4.6 版开始,这个 mcount() 调用现在是 fentry()。 为每个内核函数添加调用看起来会花费大量开销,这对于可能很少使用的东西来说是一个问题,但开销问题已经解决:当不使用时,这些调用通常会替换为快速 nop 指令, 并且仅在需要时切换到 fentry() 调用。
比如 centos7 gcc version 4.8.5 :
vim /usr/src/kernels/3.10.0-1160.el7.x86_64/Makefile
ifdef CONFIG_FUNCTION_TRACER
ifndef CC_FLAGS_FTRACE
CC_FLAGS_FTRACE := -pg
endif
export CC_FLAGS_FTRACE
ifdef CONFIG_HAVE_FENTRY
CC_USING_FENTRY := $(call cc-option, -mfentry -DCC_USING_FENTRY)
endif
KBUILD_CFLAGS += $(CC_FLAGS_FTRACE) $(CC_USING_FENTRY)
KBUILD_AFLAGS += $(CC_USING_FENTRY)
ifdef CONFIG_DYNAMIC_FTRACE
ifdef CONFIG_HAVE_C_RECORDMCOUNT
BUILD_C_RECORDMCOUNT := y
export BUILD_C_RECORDMCOUNT
endif
endif
endif
其中gprof 是一个用于分析程序性能的工具,能够生成关于程序中函数调用和执行时间的报告,帮助开发人员找出程序中的性能瓶颈。使用 gprof 进行性能分析时,编译时要启用 -pg 选项,它会在可执行文件中插入性能分析所需的代码。同时,生成的 gmon.out 文件包含了程序运行时的性能数据,所以确保在运行程序之后再进行分析。
NAME
gprof - display call graph profile data
备注: 当开始 “ftracing” 一个内核函数的时候,该函数的代码实际上就已经发生变化了。内核将在程序集中插入一些额外的指令,使得函数调用时可以随时通知追踪程序。
下面演示了使用 /sys 中的 tracefs 接口的函数分析器。 作为参考,下面显示了函数分析器的原始未启用状态:

这些命令使用函数分析器计算所有以“tcp”开头的内核调用大约 10 秒:

sleep 命令用于设置配置文件的(粗略)持续时间。 禁用功能分析和重置过滤器之后的命令。 提示:一定要使用“0 >”而不是“0>”——它们不一样; 后者是文件描述符 0 的重定向。同样避免“1>”,因为它是文件描述符 1 的重定向。
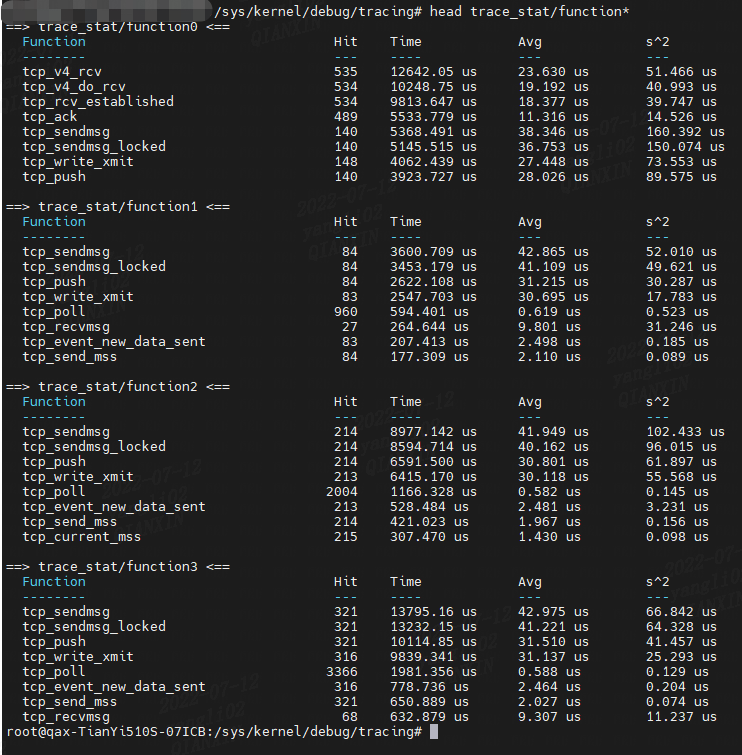
这些列显示函数名称 (Function、后面的数字代表cpu)、调用次数 (Hit)、函数中的总时间 (Time)、平均函数时间 (Avg) 和标准偏差 (s^2)。
在分析期间,向分析的函数添加了少量开销。 如果 set_ftrace_filter 留空,所有内核函数都会被分析(正如我们之前看到的初始状态警告的那样:“所有函数已启用”)。 使用分析器时请记住这一点,并尝试使用函数过滤器来限制开销。
后面会介绍的 Ftrace 前端可以自动执行这些步骤,并且可以将每个 CPU 的输出组合到系统范围的摘要中。
3.4 function trace实例
函数跟踪器打印内核函数调用的每个事件的详细信息,并使用上一节中描述的函数分析工具。 这可以显示各种函数的顺序、基于时间戳的模式以及可能负责的 CPU 进程名称和 PID。 函数跟踪的开销高于函数分析,因此跟踪最适合相对不频繁的函数(每秒调用少于 1,000 次)。 您可以使用上一节中的函数分析来找出函数的速率,然后再跟踪它们。
基于 Ftrace 的内核函数调用跟踪整体架构如下所示:
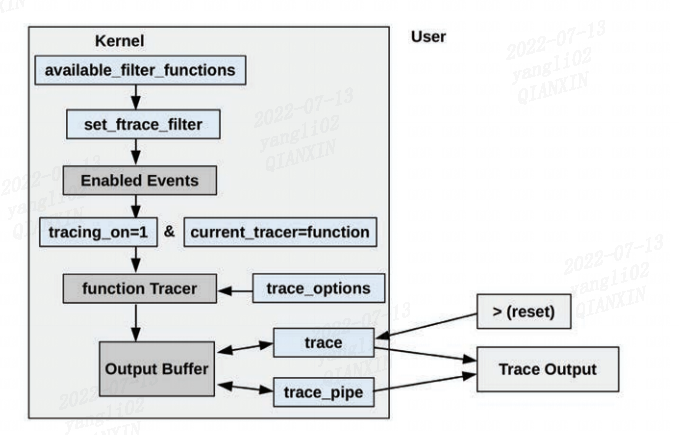
最终的跟踪输出从 trace 或 trace_pipe 文件中读取,如以下部分所述。 这两个接口也都有清除 output buffer 的方法(因此箭头返回output buffer)。
(1)Using trace
演示了使用跟踪输出文件进行的函数跟踪。 作为参考,下面显示了函数跟踪器的原始未启用状态:

对于这个例子,所有以“sleep”结尾的内核函数都被跟踪,事件最终被保存到 /tmp/out.trace01.txt 文件中。 虚拟睡眠命令用于收集至少 10 秒的跟踪。 此命令序列通过禁用函数跟踪器并使系统恢复正常来完成:
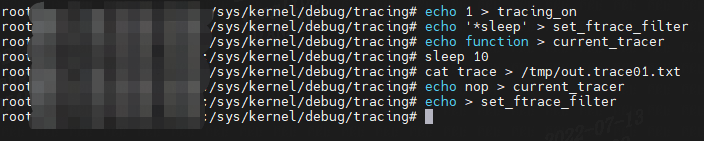
当我们跟踪“睡眠”函数调用时,在跟踪输出中捕获了虚拟睡眠命令:
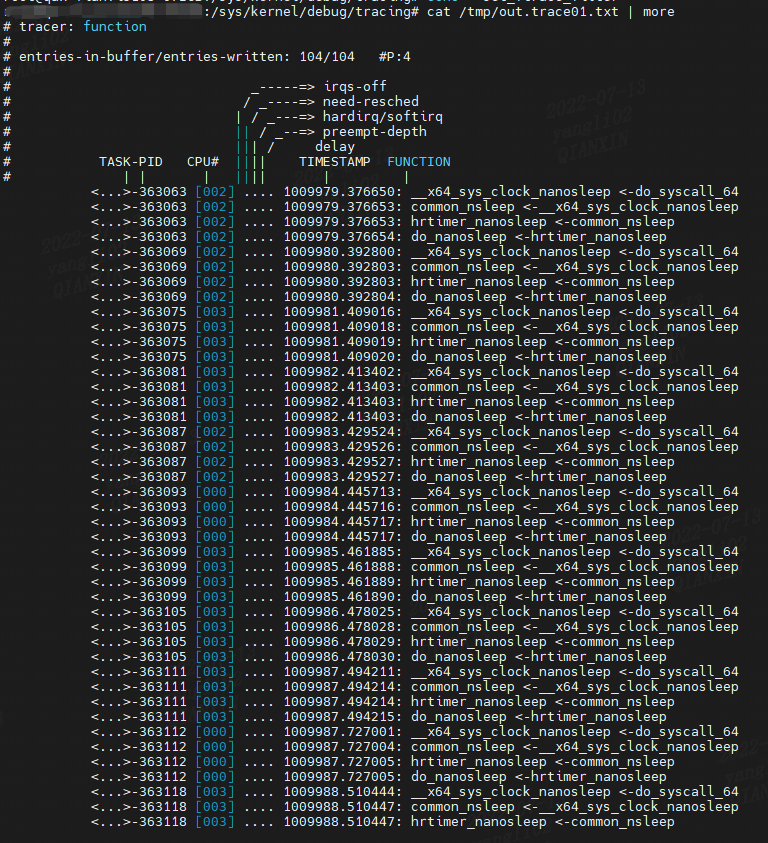
输出包括字段标题和跟踪元数据。 此示例显示一个名为 multipathd 的进程,进程 ID 为 363063,它调用 sleep 函数以及 sleep(1) 命令。final 字段显示当前函数和调用它的父函数。 例如,对于第一行,函数是__x64_sys_clock_nanosleep() 并由 do_syscall_64() 调用。
跟踪文件是跟踪事件缓冲区的接口。 读取它会显示缓冲区内容; 您可以通过向其写入换行符来清除内容:
> trace
当 current_tracer 设置回 nop 时,跟踪缓冲区也会被清除,就像我在禁用跟踪的示例步骤中所做的那样。 当使用 trace_pipe 时它也会被清除。
(2) Using trace_pipe
trace_pipe 文件是用于读取跟踪缓冲区的不同接口。 从此文件中读取会返回无穷无尽的事件流。 它还消耗事件,因此一旦它们不再在跟踪缓冲区中就读取它们。
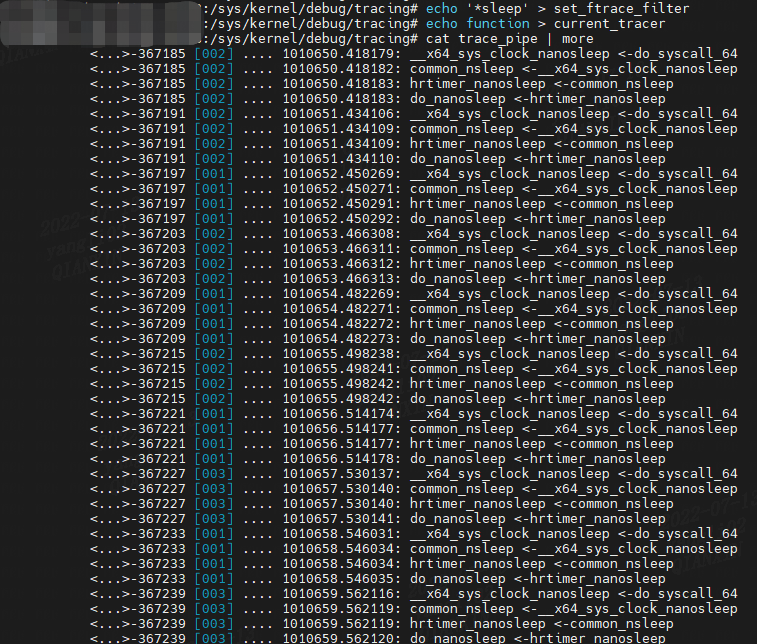
这些字段与前面显示的 trace file 输出相同,但这次没有列标题。
trace_pipe 文件对于观察低频事件很方便,但对于高频事件,您需要将它们捕获到一个文件中,以便以后使用前面显示的跟踪文件进行分析。
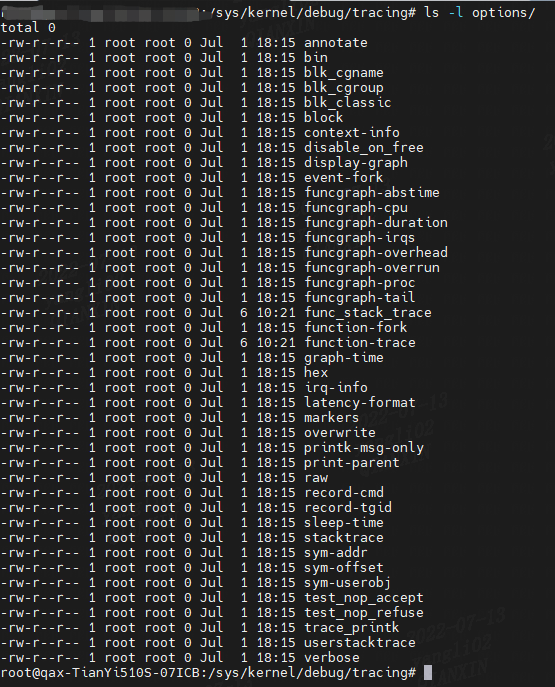
(3) Options
Ftrace 提供用于自定义跟踪输出的选项,可以从 trace_options 文件或选项目录进行控制。
这些选项包括 stacktrace 和 userstacktrace,它们会将内核和用户堆栈跟踪附加到输出:这对于理解调用函数的原因很有用。
userstacktrace
This option changes the trace. It records a stacktrace of the current user space thread after each trace event.
//此选项更改跟踪。 它在每个跟踪事件之后记录当前用户空间线程的堆栈跟踪。
stacktrace
When set, a stack trace is recorded after any trace event is recorded.
//设置后,将在记录任何跟踪事件后记录堆栈跟踪。
现在输出中不存在标志文件。 您可以使用以下方法重新设置:
echo 1 > options/irq-info
Options for function tracer:
func_stack_trace
When set, a stack trace is recorded after every function that is recorded. NOTE! Limit the functions that are recorded before enabling this, with “set_ftrace_filter” otherwise the system performance will be critically degraded. Remember to disable this option before clearing the function filter.
//设置后,在记录的每个函数之后都会记录堆栈跟踪。 注意: 使用“set_ftrace_filter”限制启用此功能之前记录的功能,否则系统性能将严重下降。 请记住在清除功能过滤器之前禁用此选项。
#stack.sh
#!/bin/sh
debugfs=/sys/kernel/debug
echo 0 > $debugfs/tracing/tracing_on
echo nop > $debugfs/tracing/current_tracer
echo function > $debugfs/tracing/current_tracer
echo $$ > $debugfs/tracing/set_ftrace_pid
echo 1 > $debugfs/tracing/options/func_stack_trace
echo do_sys_open > $debugfs/tracing/set_ftrace_filter
echo 1 > $debugfs/tracing/tracing_on
exec "$@"
./stack.sh ls
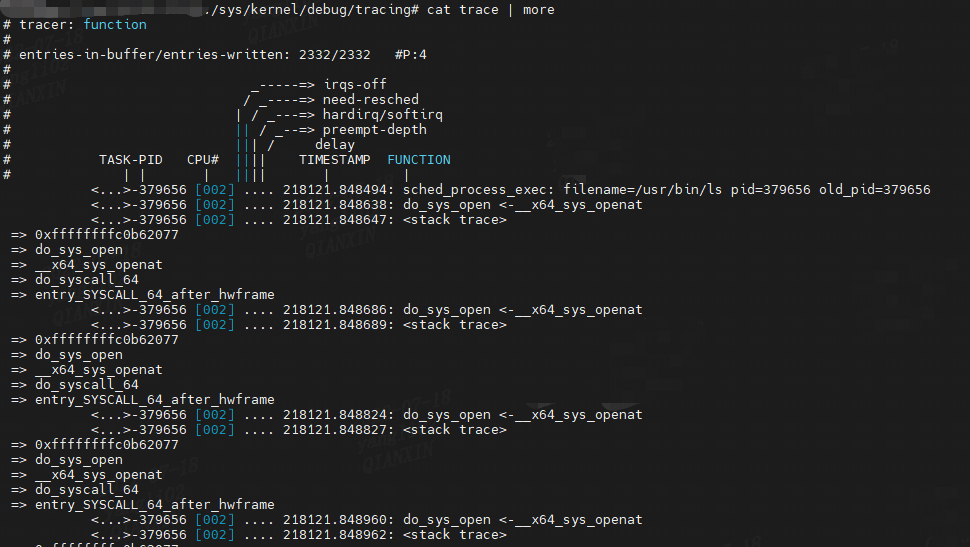
(4) do_sys_open
接下来在演示跟踪do_sys_open函数,ls 命令会通过 open 系统调用打开目录文件,而 open 在内核中对应的函数名为 do_sys_open。
echo 0 > tracing_on
echo function > current_tracer
echo do_sys_open > set_ftrace_filter
echo 1 > tracing_on
ls
cat trace | more
Linux 内核 5.4.0:
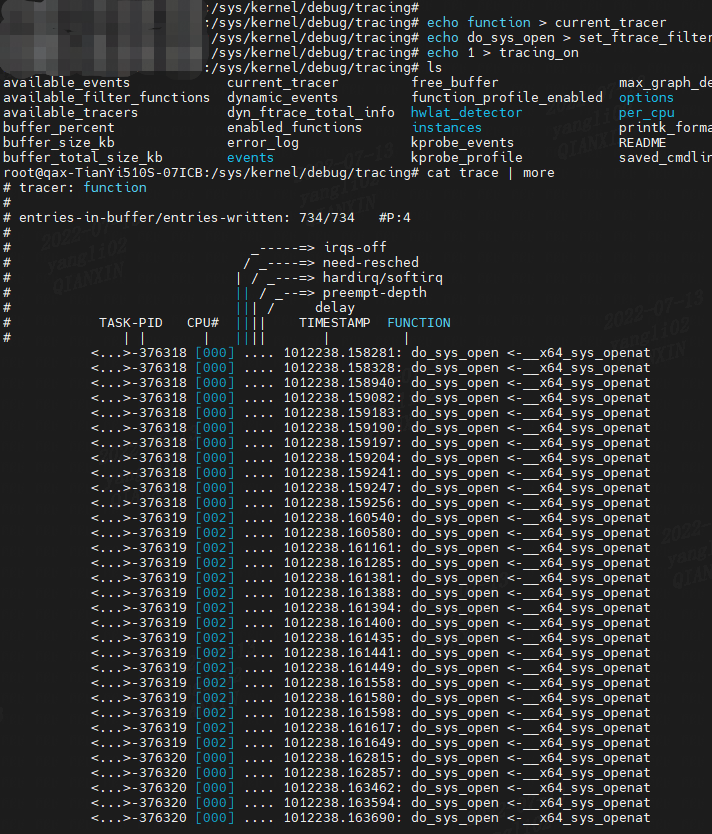
Linux 内核 3.10.0:
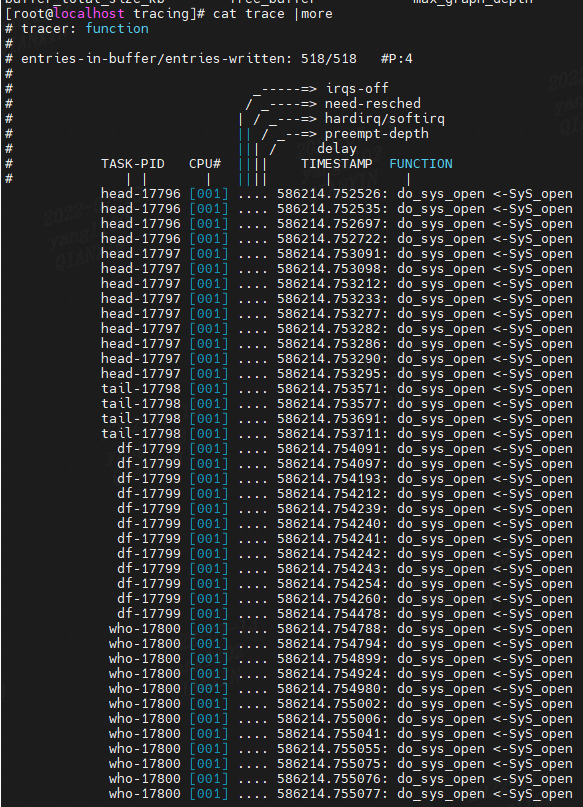
function,函数调用追踪器, 跟踪函数调用,默认跟踪所有函数。
如果设置set_ftrace_filter, 则跟踪过滤的函数,可以看出哪个函数何时调用,上述我们以do_sys_open为例子
同时ftrace允许你对一个特定的进程进行跟踪,设置set_ftrace_pid的值要更新为你想跟踪的进程的PID
总结
给大家推荐一本书籍:Systems.Performance.Enterprise.and.the.Cloud.2nd.Edition。很多都是参考这本书籍上面的例程。
参考资料
BPF.Performance.Tools
Systems.Performance.Enterprise.and.the.Cloud.2nd.Edition
https://www.kernel.org/doc/html/latest/trace/ftrace.html
https://blog.csdn.net/u012489236/category_11264548.html
https://github.com/leonsvic/CLK/tree/master/CLK2016
https://blog.csdn.net/pwl999/article/details/80702365
https://www.cnblogs.com/davad/p/16015768.html
https://www.cnblogs.com/arnoldlu/p/7211249.html#ftrace_tools
https://riboseyim.gitbook.io/perf/dtrace_ftrace#si-ti-xi-jie-gou

















 532
532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









