







 超级会员免费看
超级会员免费看
今天我们一起来读一篇来自OpenAI的CLIP工作。原文Learning Transferable Visual Models From Natural Language Supervision,简称CLIP,Contrastive Language-Image Pre-training。自从2021年2月底提出,就立马火爆全场,他的方法出奇的简单,但是效果又出奇的好,很多结果和结论都让人瞠目结舌。
比如,作者说CLIP的这个迁移学习能力是非常强的。
CLIP预训练好后,能够在任意一个视觉分类数据集上取得不错的效果,而且最重要的是zero shot,意思就是说他完全没有在这些数据集上去做训练,就能得到很高的效果。
作者做了超级多的实验,他们在超过30个数据集上做了测试,涵盖的面也非常广,包括了OCR,包括视频动作检测,还有就是坐标定位和许多细分类任务。
在所有这些结果之中,其中最炸裂的一条就是在ImageNet上的这个结果了,CLIP在不使用ImageNet训练集的情况下,也就是不使用128万张图片中任何一张训练的情况下,直接zero shot做推理就能获得和之前有监督训练好的这个ResNet-50取得同样的效果。
就在CLIP这篇工作出来之前,很多人都认为这是不可能的事情。
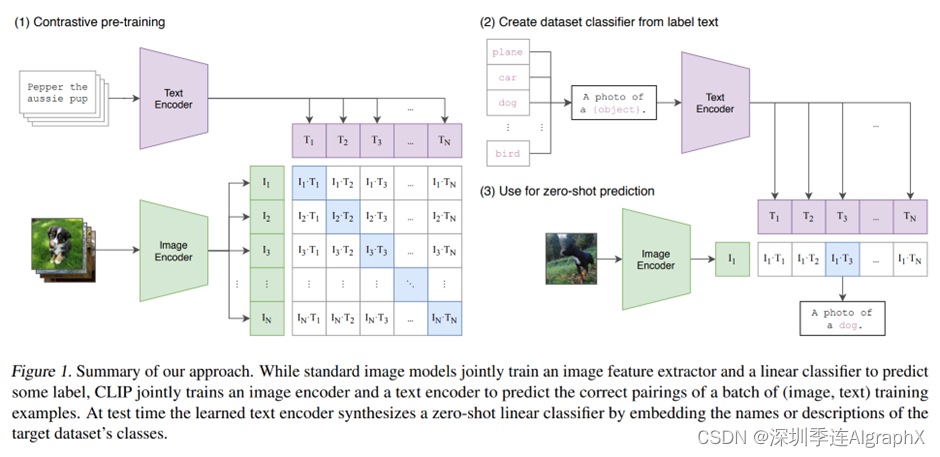
到底他是怎么去做这个zero的推理的,我们现在直接就来看文章的图一,也就是CLIP的这个模型总览图。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1880
1880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











