









 SSDA-YOLO提出了一种新的半监督域自适应方法,使用YOLOv5这一一阶段检测器,结合知识蒸馏和多任务模型,处理跨域目标检测的性能下降问题。通过风格迁移生成伪图像以缓解图像级差异,并利用教师-学生框架进行模型训练。实验在PASCALVOC-Clipart1k和Cityscapes-FoggyCityscapes数据集上进行,显示了方法的有效性。
SSDA-YOLO提出了一种新的半监督域自适应方法,使用YOLOv5这一一阶段检测器,结合知识蒸馏和多任务模型,处理跨域目标检测的性能下降问题。通过风格迁移生成伪图像以缓解图像级差异,并利用教师-学生框架进行模型训练。实验在PASCALVOC-Clipart1k和Cityscapes-FoggyCityscapes数据集上进行,显示了方法的有效性。
SSDA-YOLO: SEMI-SUPERVISED DOMAIN ADAPTIVE YOLO FOR CROSS-DOMAIN OBJECT DETECTION
源码地址
https://github.com/hnuzhy/SSDA-YOLO
论文地址
arXiv:2211.02213v2 [cs.CV] 27 Nov 2022
Abstract
DAOD的目的是目的缓解跨域差异导致的传输性能下降,目前的DAOD方法大多数是过时、计算量大的两阶段检测器Faster-rcnn,本文提出了半监督的域自适应YOLO方法,使用一阶段的检测器YOLOv5。具体,将知识蒸馏框架与MT模型相结合,帮助学生模型获得未标记目标领域的实例级特征,利用风格迁移转换在不同域交叉生成伪图像,弥补图像级差异。
INTRODUCE
最先进的检测方法大规模基准测试取得非常好的良好效果,但是在非常不同的目标域场景下进行检测,导致性能下降。
由于不同的图像风格、光照条件、图像质量会导致训练数据和测试数据之间带来相当大的域偏移。
解决训练数据集和目标测试数据集之间的差距是 DAOD的重点。DAOD尝试使用源域的标记数据和来自目标域的未标记数据来学习一个鲁棒的和可推广的检测器。domain adaption Faster RCNN为了解决目标检测中域偏移问题而发展起来的一项里程碑研究。
本文提出SSDA-YOLO,通过全监督学习提取源域特征,采取知识蒸馏框架,使用MT模型引导教师网络对未标记的目标图像进行检测,对预测进行过滤,迭代生成强伪标签,实现学生网络的更新。缩小教师和学生模型在图像级的距离,使用CUT离线生成伪图像作为附加输入。
提出新的半监督自适应YOLO,yolo与知识蒸馏结构相结合
设计两个域适应惩罚函数,蒸馏损失和稠度损失。
在两个公开数据集(PascalVOC——Clipart 1k)和(Cityscapes——Fogggy Cityscapes)常用的域转移实验。
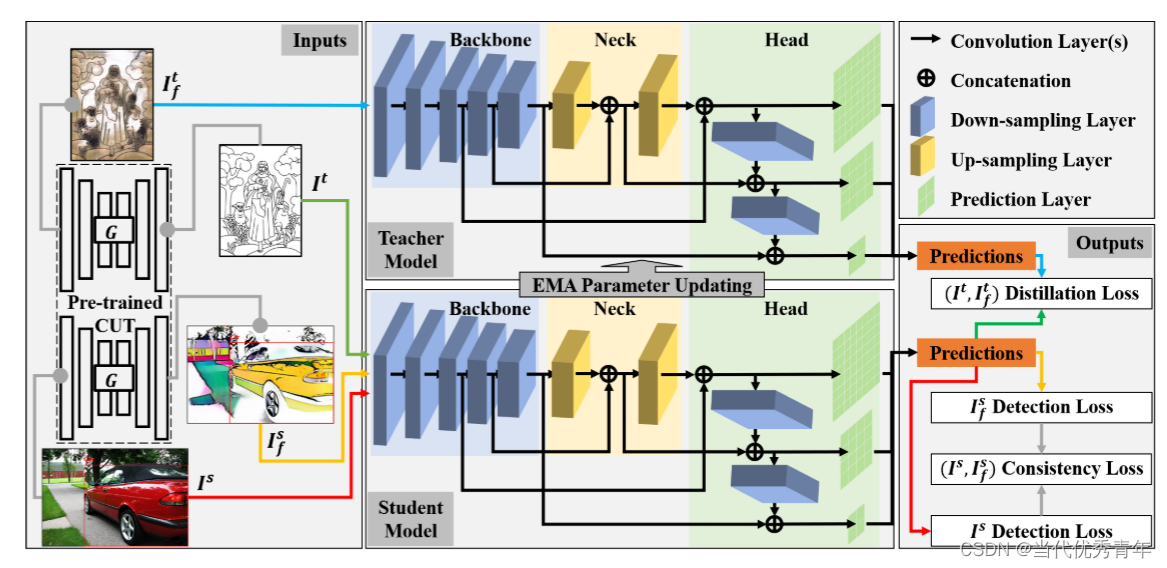
整体结构:中间:我们采用原始的Yolov5网络作为教师和学生模型的基本检测器,在一个知识提炼框架中。 左边:在训练过程中,除了将真实源图像IS和目标图像IT作为输入外,我们还利用相应的预训练CUT模型生成了类目标假源图像IS F和类源假目标图像IT F以缓解图像级域差异。 右边:基于多个输入,我们构成各种相应的损失函数来支持半监督学习。
相关工作:
2.1 Object Detection
单阶段检测:SSD、FCOS、yolo系列
双阶段检测:Faster R-CNN、Mask RCNN
Transformer应用端到端目标检测:模型结构复杂、收敛速度慢
2.2 Cross Domain Object Detection
现有的目标检测方法广泛使用双阶段Faster R-CNN,DA-Faster引入GRL梯度反向层,首次提出实例级和图像级对齐。
本论文采取单阶段检测器解决DAOD问题
2.3 半监督域适应
无监督域适应UDA是将一个模型从标记的源域自适应到未标记的目标域。广泛用于图像分类任务。对于DAOD问题,目标域的标签在训练过程是不可见的,只使用图像。
实际上,我们可以获得一小部分在目标场景中局部标记图像。因此我们可以通过半监督学习(few shot 学习)获得可靠的收益。
本论文收到启发,结合当前的MT模型,构建知识蒸馏方法,利用监督学习在源域数据集,无监督学习在目标数据集。此外,在输入到教师模型之前用类源域全局图片对无标记的目标训练图像进行风格迁移。(未标记的目标域图像,就是模型需要学习如何将源域图像转换到目标域的图像)(将未标记的目标图像输入到教师模型之前,使用源域图像的全局场景对其进行风格转换,可以帮助模型更好的学习如何将源域图像转换为目标域图像,因为全局场景可以帮助模型更好的理解两个与之间的差异)
准备和动机
大多数DAOD方法都侧重利用源域和目标域的数据训练一个共享的检测网络,这种方法很难优化和收敛,促使本论文应对两个主要挑战:
知识蒸馏结构
过去的DAOD方法使用单一的共享的网络去适应跨域数据是一个困难的过程。使用GRL实现两个相互冲突的优化目标。一方面,最小化分类误差在前向传播,另一方面,在反向传播过程中,它变成了一个负标量,以最大化二值分类误差和学习域不变特征。 最大均值差异(MMD)等距离度量通常被用于测量域移位和监督模型。
知识蒸馏结构增强源检测器对目标图像中的目标的感知能力。本论文采用teacher-student 框架,基于单阶段YOLOv5 。
Cross-domain Features Extraction
指在不同的数据集中提取特征并将其组合成一个混合特征表示的过程。这个技术通常用于跨域图像分类、物体检测等
在跨域场景中,不同域的图像有不同的视觉特征,因此需要在不同域之间学习共享特征,以便模型可以再新的域中进行泛化。一般使用VGG、resnet提取图像特征,作为跨域任务的输入,使用迁移学习的技术对其进行微调,达到适应新的域。
本论文采用,伪交叉生成图像解决图像层的对齐,采用MT模型来获取实例层的目标域特征,指导学生模型的训练。
PROPOSED METHOD
包含四个主要的结构:
基于知识蒸馏的MT模型,指导学生网络更新
消除图像级差异的伪交叉生成训练图像网络
消除跨域差异的更新的蒸馏损失
新的一致性损失,进一步纠正跨域的客观性偏差
MT model
应用于半监督的图像分类任务,典型的知识蒸馏结构和两个相同的模型体系结构(学生和教师,教师模型参数更多,可以提供更高的性能)。应用于域适应任务,使用梯度下降优化器,在源域中应用标记数据训练学生模型。根据MT模型的设置,教师模型由来自学生模型的EMA指数移动平均权重更新(EMA方法对学生模型的权重进行平滑处理并使用平滑后的权重更新教师模型参数,该过程可以使教师模型更加平滑和稳定),学生模型和教师模型的权重参数分别为Ps和Pt:
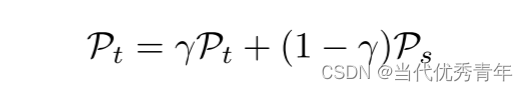
γ是指数衰减。其合理值接近1.0,通常范围:0.99、0.999等
在跨域目标检测任务重,将未标记的目标域样本DT作为教师模型的单一输入。在这些未标记的样本对学生模型进行部分训练。在蒸馏过程中,通过从教师模型预测中选择概率较高的bounding box作为伪标签,学生模型倾向于减少目标域上的方差(分布越大,数据分布越分散),增强模型的鲁棒性。
假设我们从相同的图像 It 中为教师模型输入了增强的目标信息 It-,为学生模型输入了增强的目标信息It~,可以使用如下定义的蒸馏损失来惩罚两个模型之间的预测的不一致:
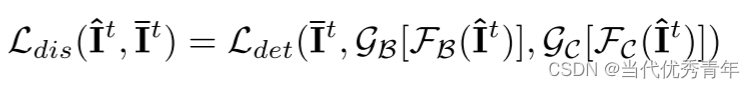
FB和FC是bounding box坐标教师模型的预测分支和最大类别得分较高的类别。GB和GC是对应的过滤器。
在训练的每一步都将MT模型设置为评估模式,并使用NMS对预测的边界框进行过滤,边界框按照置信度进行排序,设置IoU的阈值,最后选择类别得分最高的bounding box。最后的伪标签提供目标域的学生模型实例级特征。
Pseudo Training Image Generation 伪训练图像的生成
在源域中,学生模型的权重更新是由图像主导的。教师模型不会接触源图像,以目标域特征为指导。减轻图像级域差异,这种差异导致两个模型偏向于它们单调的图像输入。收到SWDA启发,利用CycleGAN在全局场景级通过弱配准学习域不变特征的启发,将源域图像转移到类目标域。TDD采用FDA在传统傅里叶变换的基础上,与其风格转换模块中生成类目标图像,作为目标域中额外的目标监督。
本文采用同时生成类目标假源图像和类源假目标图像。
采用CUT非配对的图像翻译器


Remedying Cross-Domain Discrepancy
纠正跨域差异
生成类源域假目标图像和类目标假源图像为了减少跨域差异,为了弥补存在跨域差异的学生模型,增加了一个新的监督分支,以类目标图像作为输入(框架黄色流),训练它们与源图像(框架红色流)完全相同,损失函数:
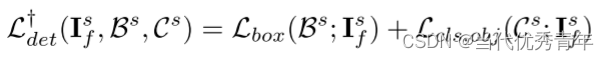
(等式4)
对于教师模型,为了让它能够学习源域的全局 image-level的特征,将原始输入目标图像替换为类源域假图像(框架蓝色流)。未标记的目标图像 It- 用于训练学生模型保持不变(框架绿色部分),更新蒸馏损失:
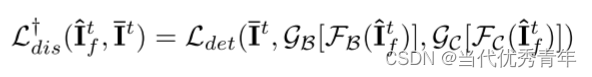
(等式5)
等式4和5的关系在MT模型中通过EMA参数更新建立。学习的教师模型不会明显的倾向于擅长预测目标域中的对象。学生模型的训练将会逐渐接近真实的目标领域,对来自过滤后的 Itf 预测的伪标签进行弱监督,这些伪标签在促进细粒度实例化级适应方面发挥作用。
一致性损失函数
输入学生网络的源图像和类目标图像(It,Itf),具有不同的场景级数据分布,但是属于同一个标签控件。理想情况,用连个域的图像训练的学生模型输出应该一致。因此为了保证输出尽可能一致,在新的分支上增加了一个新的约束。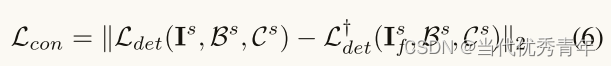
整体优化
类目标图像和类源域图像通过预训练的CUT离线生成,学生模型采用精细训练的学生模型,以目标图像为单一输入。联合优化所有相关损失进行端到端的训练。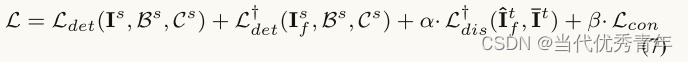
实验过程
训练和测试图片大小(960,960,3),训练过程中,每个批量由两对图像组成
(Is, Isf) with labels and (It, Itf) without labels
以下四种数据集:
1.PASCAL VOC
2.Clipart1k
3.Cityscapes
4.Foggy Cityscapes
训练Cityscapes
训练过程中采用Cityscapes作为源域,Foggy Cityscapes作为目标域,数据集在训练集和验证集中分别包含2975张和500张图像。 雾景数据集是由Cityscapes合成的雾景数据集,具有完全相同的数据分割 

















 109
109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









