







🤵 Author :Horizon John
✨ 编程技巧篇:各种操作小结
🏆 神经网络篇:经典网络模型
💻 算法篇:再忙也别忘了 LeetCode
[ Transformer篇 ] 经典网络模型 —— Vision Transformer + Transformer in Transformer + Swin Transformer

🚀 01. Vision Transformer

📜 Paper: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale [ICLR 2021]
🖥️ GitHub: vision_transformer
🎨 结构框图

🚩 详解
Transformer 结构在 NLP 领域已逐渐成为标准,但在 CV 领域的应用仍有限;
在此之前 注意力(attention) 在 CV 领域的应用要么 与卷积网络结合 或者 替换掉卷积网络的某些组件,同时保留其主要结构,但卷积结构仍旧占有主导地位;
作者证明了即使不使用卷积网络结构,也能得到较好的效果,尤其是利用大规模数据集进行预训练再迁移至中小型数据集上(参考 NLP 领域中的 BERT),可以得到非常好的效果(与 ResNet 进行了比较),并且需要的训练资源也较少;
BERT:完形填空式训练(denoising self-supervised),挖掉完整句子中的某个词,利用模型进行预测;GPT:预测型训练(language modeling),根据给定的句子预测下一个词是什么;
作者提到随着模型和数据集的增长,仍然没有 性能饱和 的迹象;
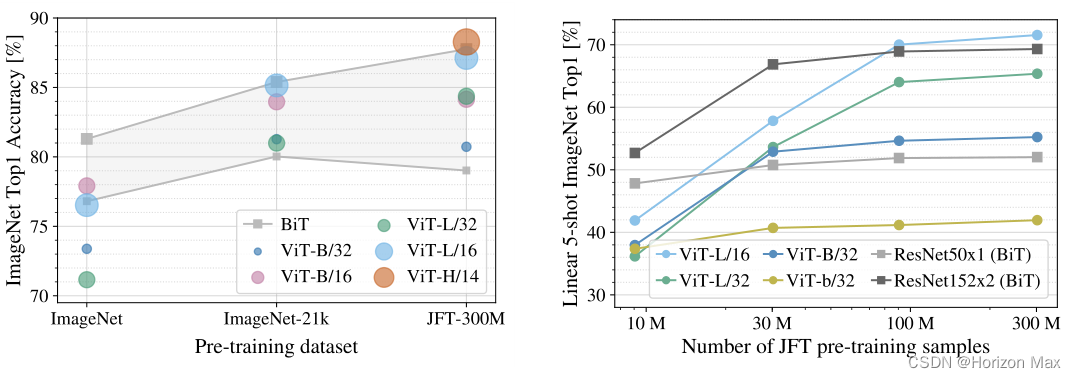
在 ImageNet, CIFAR-100, VTAB 等数据集上做了相关的对比实验;
难点:
Transformer 在 NLP 中的应用,输入是一个一维的序列,核心点是 自注意力操作,即输入的每一个元素都会两两之间进行互动得到一个Attention值,最后将得到的Attention值与输入序列进行加权平均,最后输出;
若将图片输入则需要将图片拉成一个一维的序列,拉成一维序列的方法可能是将图片的每一个 像素展开,这会得到一个非常大的一维序列,从而导致自注意力操作的计算量巨大,硬件上难以实现(BERT里序列长度为512),以图像分类任务中的 224×224 为例,转成一维序列后的长度为 1×50176,而在目标检测和图像分割任务当中图像大小更大,最后的序列更长 ;
- 合理地将
二维图片转成一维序列; - 不对标准的 Transformer 进行任何的改动,以提高模型的
可拓展性;
主要方法:
如 Figure 1. 左侧所示为 Vison Transformer 的主要结构;
核心思想:
在图像分类任务中,主流的图片数据输入大小为 224×224 ;
- 将输入图像分割为
固定尺寸(16×16)的补丁(fixed-size patches),得到14×14=196个 patch; - 将分割后的每个 patch 通过一个线性投射层得到输入的
一维序列,并添加位置编码,以保留他们之间的位置信息; - 输入到标准的
Transformer Encoder模块当中 ; - 借鉴 BERT 模型,添加了一个
* Extra learnable [class] embedding并将该位置的输出当成最后的输出;

注:
Extra learnable [class] embedding 利用自注意力操作特点,其会与输入序列的每一个元素进行交互,从而能够学习到输入序列的全局特征 ;
一维序列维度为 196×768(14×14=196;16×16×3=768);
图中的 Linear 层为一个全连接层,维度为 768×768;
加上额外的 class embedding 后,维度为197×768;
位置信息编码维度为1×768,与图片信息相加,维度仍为197×768;
最后输入 Transformer 的序列维度为 197×768;
未来展望:
拓展到视觉领域中的 检测和分割(detection and segmentation) 任务;
🚩 效果




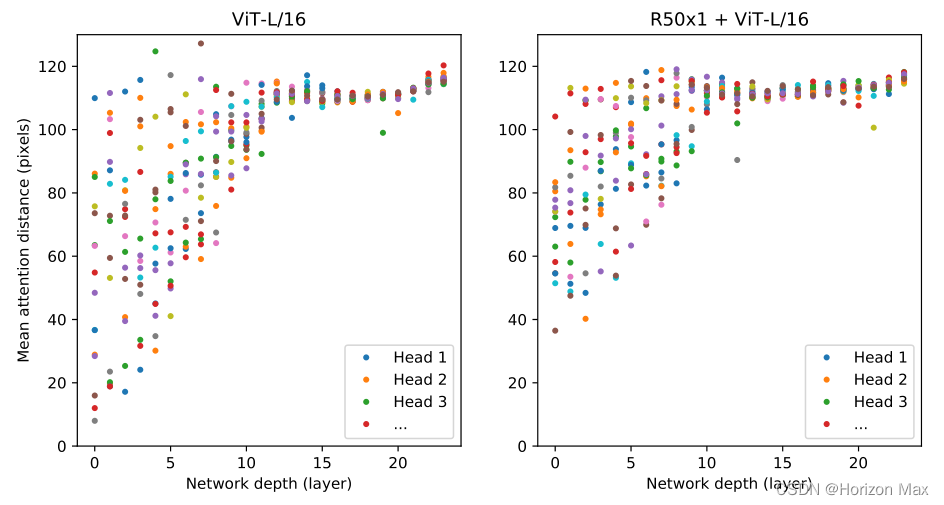
Head 之间的距离越大反应学习到的全局特征越好,类似于感受野,可以看到在刚开始的几层也能学到全局特征;

🚀 02. Transformer in Transformer

📜 Paper: Transformer in Transformer [NeurIPS 2021]
🖥️ GitHub: Efficient-AI-Backbones
🎨 结构框图

🚩 详解
ViT 模型的注意力只关注了 patch之间的信息 而忽略了 patch内部的信息 ;
基于此,作者将每一个 局部的 patch(16×16) 进一步划分为 更小的patch(4×4) ,一起计算以实现 特征聚合,增强模型的 表征能力 ;
在 ImageNet 上实现了81.5%的 top-1 精度,而计算成本高出约1.7% ;
🚩 效果


🚀 03. Swin Transformer

📜 Paper: Swin Transformer: Hierarchical Vision Transformer using Shifted Windows [ICCV 2021 best paper]
🖥️ GitHub: Swin-Transformer
🎨 结构框图



🚩 详解
提出了 移动窗口(shifted windows) 的概念,移动窗口可以 提高计算效率(自注意力在移动窗口内计算,计算复杂的与图像大小为 线性增长 的关系,而ViT为平方增长),通过移动的操作可以使相邻的窗口进行交互,从而实现 全局建模 的效果(Figure 2.);并利用 层级结构 可以实现多尺度特征的提取(Figure 1.)(Figure 3.(a));
在 目标检测和语义分割(object detection and semantic segmentation) 等任务上取得了很好的效果;
移动窗口为 7×7 大小,每一个移动窗口包含 7×7=49 patches ;
Swin Transformer 没有像 ViT 一样使用 class embedding ,而是对输出进行 平均池化;
🚩 效果

如Figure 2. 所示,如果按照那种方式进行移动窗口会使移动窗口的数量增加,无形之中增加了计算量,所以进行了改进,将A、B、C部分分别移动到右下角、右侧、下侧,并对得到的新特征图进行掩码操作,保证其位置信息不变,最后得到的移动窗口数量仍然不变;



















 521
521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











