









简介:PyCaret 是 Python 中的一个开源、低代码的机器学习库,能够自动化机器学习的工作流程。它是一个端到端的机器学习和模型管理工具,可以加快机器学习实验的周期,让我们的工作效率更高。
安装pycaret 2.0
一条命令解决:
pip install pycaret==2.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
2020年11月14号,更新
安装pycaret 2.2
最好有梯子,一条命令解决:
pip install pycaret==2.2
现在pycaret更新为2.2版本了,还支持GPU加速,不过要安装cupy,cuml等包,这些包现在只支持Linux系统,没有windows的版本,看后期rapids相应的包支持windows。这样利用GPU加速,效率会更高些。
pycaret官网地址https://pycaret.org/guide/
官网英文手册
pycaret官网地址https://pycaret.org/setup/
加载数据
我是在jupyter notebook运行的代码
官方加载数据为:
# Loading data from pycaret
from pycaret.datasets import get_data
data = get_data('juice')
但我报错了,查明原因是网络问题,这需要科学上网才能访问,所以我只能把数据集下载好然后用pandas加载,如下:
'''
如果直接使用
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
会报错,网络地址不对,这是因为国内的网无法访问国外的网的问题,此时打开科学上网器,再运行这2行代码,问题就没有了。
所以使用pandas读取数据
'''
import pandas as pd
diabetes = pd.read_csv('F:/代码01Data/pycaret练习代码/datasets/diabetes.csv')
diabetes
Number of times pregnant Plasma glucose concentration a 2 hours in an oral glucose tolerance test Diastolic blood pressure (mm Hg) Triceps skin fold thickness (mm) 2-Hour serum insulin (mu U/ml) Body mass index (weight in kg/(height in m)^2) Diabetes pedigree function Age (years) Class variable
0 6 148 72 35 0 33.6 0.627 50 1
1 1 85 66 29 0 26.6 0.351 31 0
2 8 183 64 0 0 23.3 0.672 32 1
3 1 89 66 23 94 28.1 0.167 21 0
4 0 137 40 35 168 43.1 2.288 33 1
... ... ... ... ... ... ... ... ... ...
763 10 101 76 48 180 32.9 0.171 63 0
764 2 122 70 27 0 36.8 0.340 27 0
765 5 121 72 23 112 26.2 0.245 30 0
766 1 126 60 0 0 30.1 0.349 47 1
767 1 93 70 31 0 30.4 0.315 23 0
768 rows × 9 columns
分类例子
'''
Classification
ID Name
‘lr’ Logistic Regression
‘knn’ K Nearest Neighbour
‘nb’ Naives Bayes
‘dt’ Decision Tree Classifier
‘svm’ SVM – Linear Kernel
‘rbfsvm’ SVM – Radial Kernel
‘gpc’ Gaussian Process Classifier
‘mlp’ Multi Level Perceptron
‘ridge’ Ridge Classifier
‘rf’ Random Forest Classifier
‘qda’ Quadratic Discriminant Analysis
‘ada’ Ada Boost Classifier
‘gbc’ Gradient Boosting Classifier
‘lda’ Linear Discriminant Analysis
‘et’ Extra Trees Classifier
‘xgboost’ Extreme Gradient Boosting
‘lightgbm’ Light Gradient Boosting
‘catboost’ CatBoost Classifier
'''
'''
只用分类例子,其他例子可以去官网看
导入模块并初始化安装程序
'''
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# 返回最好的模型
best = compare_models()
# 根据“Accuracy”返回前3个模型
# top3 = compare_models(n_select = 3)
# 返回最好模型基于"AUC",默认是Accuracy
# best = compare_models(sort = 'AUC')
# 比较特殊的模型
# best_specific = compare_models(whitelist = ['dt','rf','xgboost'])
# 黑名单特定的模型
# best_specific = compare_models(blacklist = ['catboost', 'svm'])
Model Accuracy AUC Recall Prec. F1 Kappa MCC TT (Sec)
0 Ridge Classifier 0.7505 0.0000 0.5292 0.7043 0.5934 0.4198 0.4357 0.0042
1 Logistic Regression 0.7449 0.7849 0.5187 0.7014 0.5875 0.4086 0.4248 0.0269
2 Linear Discriminant Analysis 0.7449 0.7898 0.5345 0.6857 0.5896 0.4104 0.4242 0.0045
3 Gradient Boosting Classifier 0.7411 0.7948 0.5670 0.6484 0.5994 0.4109 0.4169 0.0969
4 Random Forest Classifier 0.7263 0.7750 0.4708 0.6640 0.5381 0.3547 0.3722 0.1143
5 Ada Boost Classifier 0.7188 0.7623 0.5190 0.6234 0.5606 0.3576 0.3646 0.0699
6 Extreme Gradient Boosting 0.7132 0.7594 0.5357 0.6018 0.5618 0.3515 0.3559 0.0549
7 Extra Trees Classifier 0.7077 0.7579 0.4333 0.6180 0.5083 0.3092 0.3199 0.1457
8 Light Gradient Boosting Machine 0.7039 0.7674 0.4985 0.5888 0.5353 0.3226 0.3272 0.0631
9 Decision Tree Classifier 0.6946 0.6676 0.5781 0.5664 0.5671 0.3331 0.3364 0.0037
10 K Neighbors Classifier 0.6926 0.7088 0.4807 0.5779 0.5202 0.2979 0.3034 0.0043
11 Naive Bayes 0.6668 0.7141 0.2839 0.5556 0.3711 0.1757 0.1966 0.0029
12 Quadratic Discriminant Analysis 0.5941 0.5963 0.4611 0.4561 0.4038 0.1253 0.1447 0.0033
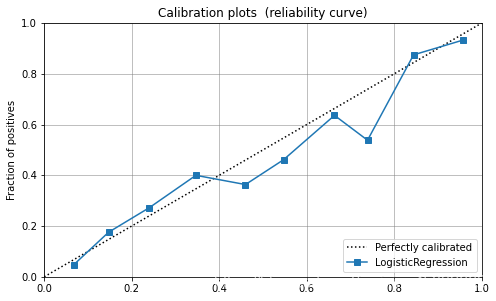
画图模型
'''
Plot Model
'''
# Importing module and initializing setup
from pycaret.classification import *
clf1 = setup(data=diabetes, target='Class variable')
# creating a model
lr = create_model('lr')
# plotting a model
plot_model(lr, plot='calibration', save=True, verbose=True, system=True)
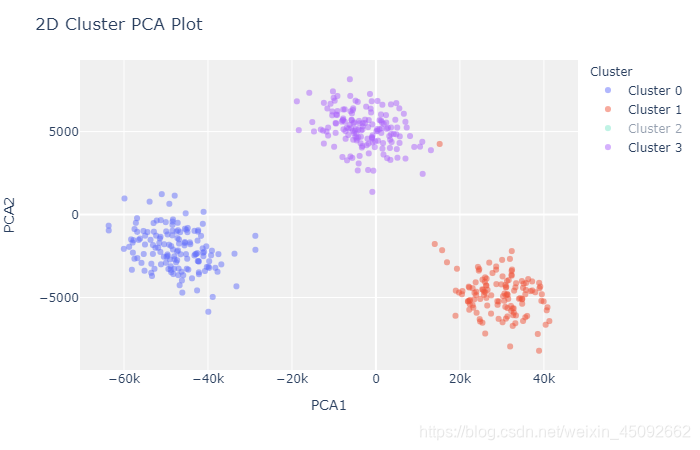
聚类模型
'''
Clustering
'''
# Importing dataset
from pycaret.datasets import get_data
jewellery = get_data('jewellery')
# Importing module and initializing setup
from pycaret.clustering import *
clu1 = setup(data = jewellery)
# creating a model
kmeans = create_model('kmeans')
# plotting a model
plot_model(kmeans)
Metric
Silhouette 0.7207
Calinski-Harabasz 5011.8115
Davies-Bouldin 0.4114
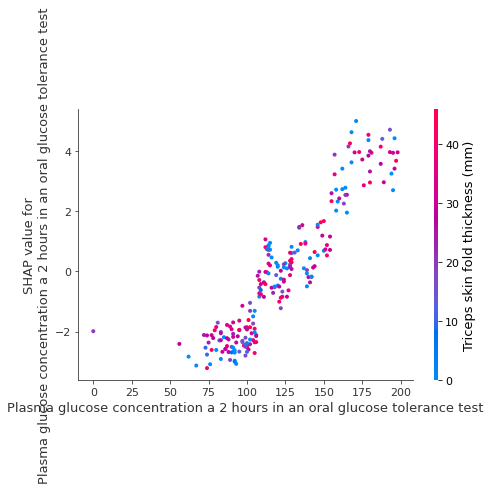
xgboost模型
官方代码有错误,所以自己查资料修改了下,运行成功了。
# Importing module and initializing setup
from pycaret.classification import *
clf1 = setup(data=diabetes, target='Class variable')
# creating a model
xgboost = create_model('xgboost')
#Temprary fix fo an error for xgboost
mybooster = xgboost.get_booster()
model_bytearray = mybooster.save_raw()[4:]
def myfun(self=None):
return model_bytearray
mybooster.save_raw = myfun
interpret_model(xgboost, plot='correlation')
总之就是pycaret可以用很少的代码替换原来的数百行代码,简化工作量。对数据挖掘与分析很有帮助。
可以看看我运行的一些例子,我的码云网址为:https://gitee.com/rengarwang/pycaret-coding
本站所有文章均为原创,欢迎转载,请注明文章出处:https://blog.csdn.net/weixin_45092662。百度和各类采集站皆不可信,搜索请谨慎鉴别。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。


















 450
450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









