







复现代码:https://gitee.com/chengze1998/STDN
0 概述
STDN是CVPR 2018的一篇目标检测论文,提出STDN网络用于提升多尺度目标的检测效果。要点包括:(1)使用DenseNet-169作为基础网络提取特征特征提取网络(自带高低层特征融合),基于多层特征做预测(类似SSD),并对预测结果做融合得到最终结果;(2)提出Scale-transfer Layer,在几乎不增加参数量和计算量的情况下生成大尺度的feature map。
1 网络模型
1.1 Densenet
1.2 STDN
在Densenet基础上,STDN在第四个Denseblock嵌入了一个STM模块用于提取特征图和进行目标检测任务。
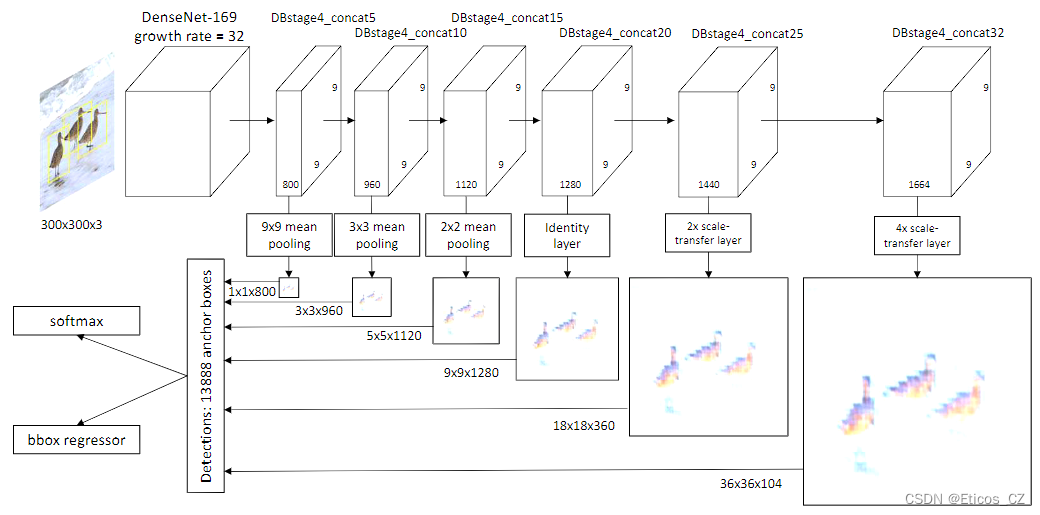
为了获得高层次的语义多尺度特征图,同时不影响检测器的速度,我们开发了一个尺度转移模块(STM),并将该模块直接嵌入到DenseNet中[14]。DenseNet的作用是在CNN中整合低级和高级特征,以获得更强大的特征。由于网络结构的密集连接,DenseNet的特征自然比普通卷积特征更强大。STM由池化层和标度转移层组成。池化层用于获得小尺度的特征图,标度转移层用于获得大尺度的特征图。尺度转移层最早被提出来做图像超分辨率[28],因为它的简单性和效率,有些人也用它来做语义分割[30]。我们利用这一层来有效地扩大用于物体检测的特征图的分辨率。(翻译自原文)
STM自然适合基础网络,并能实现端到端的训练。我们认为,STM有两个明显的优势。首先,结合DenseNet[14],特征图自然拥有低层次的物体细节特征和高层次的语义特征。我们将证明,这将提高物体检测的准确性。第二,STM是由池化层和超分辨率层组成的,没有额外的参数和计算。实验结果表明,本文提出的框架能够准确地检测物体并满足实时性要求。(翻译自原文)
2 代码复现
复现部分是笔者参照了大量的资料和自行摸索的结果,很多地方使用的方法可能会很笨拙,甚至出现纰漏,也期待各位提出意见或建议,谢谢!
本文代码:https://gitee.com/chengze1998/STDN
代码框架以及检测部分参考代码:http://t.csdn.cn/ZoR0B
本文代码部分特别感谢本站@Bubbliiiing的文章,通过
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 917
917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









