







论文:Focal and Global Knowledge Distillation for Detectors
论文:https://arxiv.org/abs/2111.11837
代码:https://github.com/yzd-v/FGD
一,针对问题
1. 目标检测中前背景不平衡问题
知识蒸馏旨在使学生学习教师的知识,以获得相似的输出从而提升性能。为了探索学生与教师在特征层面的差异,作者首先对二者的特征图进行了可视化。可以看到在空间与通道注意力上,教师与学生均存在较大的差异。其中在空间注意力上,二者在前景中的差异较大,在背景中的差异较小,这会给蒸馏中的学生带来不同的学习难度。
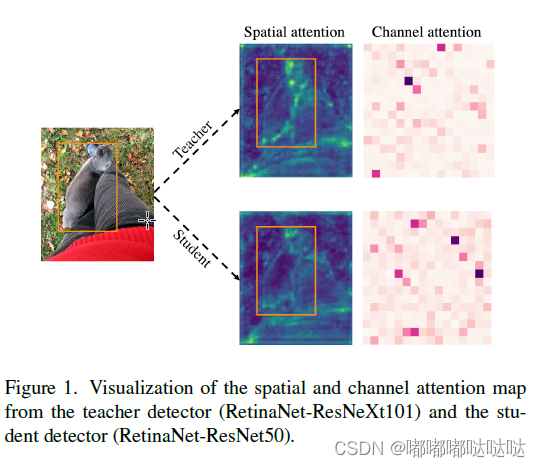
为了进一步探索前背景对于知识蒸馏的影响,作者分离出前背景进行了蒸馏实验,全图一起蒸馏会导致蒸馏性能的下降,将前景与背景分开学生能够获得更好的表现。

针对学生与教师注意力的差异,前景与背景的差异,作者提出了重点蒸馏Focal Distillation:分离前背景,并利用教师的空间与通道注意力作为权重,指导学生进行知识蒸馏,计算重点蒸馏损失。
二,方法

整体蒸馏损失计算方式:
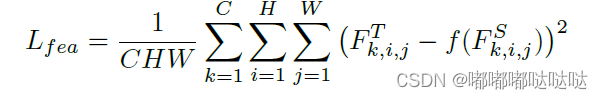
C,H,W:feature map的通道时和高宽。
和
为教师和学生模型的输出。
2.1 分离前背景
前、背景Mask
设置一个二值MASK:

r代表GT bbox,如果feature map的点落在bbox内则该点为1,否则为0.
2.2 尺度
尺度Mask
大小目标focal,前、背景

Hr和Wr为bbox的高和宽,如果一个同时属于多个目标(遮挡场景)选取bbox最小的目标去计算S
2.2 空间与通道注意力
空间与通道注意力
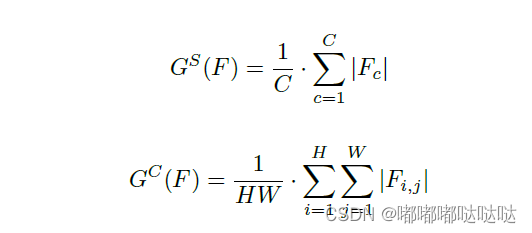
C,H,W:feature map的通道时和高宽。
G 代表空间注意立和通道注意力机制,
Attention MASK:
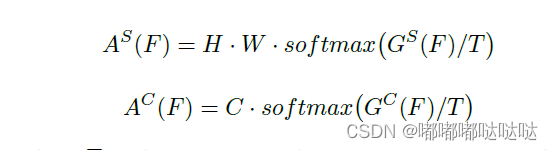
T为蒸馏温度 ,论文设置为0.5
2.3 全局蒸馏
全局信息的丢失
Focal Distillation将前景与背景分开进行蒸馏,割断了前背景的联系,缺乏了特征的全局信息的蒸馏。为此提出了全局蒸馏Global Distillation:利用GcBlock分别提取学生与教师的全局信息,并进行全局蒸馏损失的计算。

使用GCBlock去获取全局信息,使得学生模型从教室模型中学习前背景的联系。
损失计算如下:

self.conv_mask_t = nn.Conv2d(teacher_channels, 1, kernel_size=1)
self.channel_add_conv_s = nn.Sequential(
nn.Conv2d(teacher_channels, teacher_channels//2, kernel_size=1),
nn.LayerNorm([teacher_channels//2, 1, 1]),
nn.ReLU(inplace=True), # yapf: disable
nn.Conv2d(teacher_channels//2, teacher_channels, kernel_size=1))
self.channel_add_conv_t = nn.Sequential(
nn.Conv2d(teacher_channels, teacher_channels//2, kernel_size=1),
nn.LayerNorm([teacher_channels//2, 1, 1]),
nn.ReLU(inplace=True), # yapf: disable
nn.Conv2d(teacher_channels//2, teacher_channels, kernel_size=1))
def spatial_pool(self, x, in_type):
batch, channel, width, height = x.size()
input_x = x
# [N, C, H * W]
input_x = input_x.view(batch, channel, height * width)
# [N, 1, C, H * W]
input_x = input_x.unsqueeze(1)
# [N, 1, H, W]
if in_type == 0:
context_mask = self.conv_mask_s(x)
else:
context_mask = self.conv_mask_t(x)
# [N, 1, H * W]
context_mask = context_mask.view(batch, 1, height * width)
# [N, 1, H * W]
context_mask = F.softmax(context_mask, dim=2)
# [N, 1, H * W, 1]
context_mask = context_mask.unsqueeze(-1)
# [N, 1, C, 1]
context = torch.matmul(input_x, context_mask)
# [N, C, 1, 1]
context = context.view(batch, channel, 1, 1)
return context
def get_rela_loss(self, preds_S, preds_T):
loss_mse = nn.MSELoss(reduction='sum')
context_s = self.spatial_pool(preds_S, 0)
context_t = self.spatial_pool(preds_T, 1)
out_s = preds_S
out_t = preds_T
channel_add_s = self.channel_add_conv_s(context_s)
out_s = out_s + channel_add_s
channel_add_t = self.channel_add_conv_t(context_t)
out_t = out_t + channel_add_t
rela_loss = loss_mse(out_s, out_t)/len(out_s)
return rela_loss
2.4 最终Loss
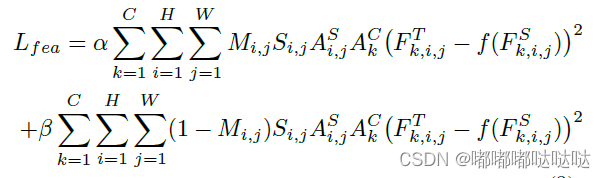
alpha=0.001,beta=0.0005
除此之外,利用注意力损失来强迫学生模型去逼近教师模型的空间和通道注意力Mask
公式如下:

gamma=0.0005.
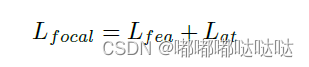
最终loss

lambda=0.000005
关于超参

最终效果:
















 1412
1412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









