







1、简介
- 决策树算法是一种归纳分类算法,它通过对训练集的学习,挖掘出有用的规则,用于对新数据进行预测。
- 决策树算法属于监督学习方法。
- 决策树归纳的基本算法是贪心算法,自顶向下来构建决策树。
- 贪心算法:在每一步选择中都采取在当前状态下最好/优的选择。
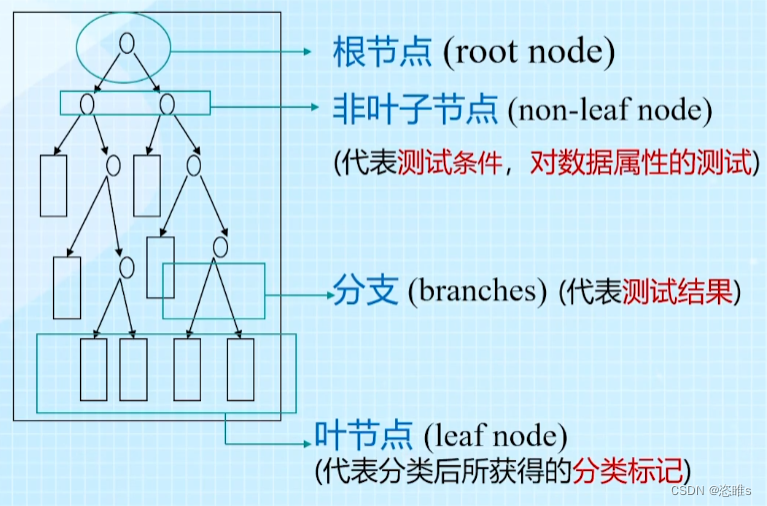
- 简单来说,决策树就是做决策的树,类似于流程图的结构,其中每个内部节点代表一个属性上的“判断”,每个分支代表测试的结果,每个叶节点代表一个测试结果,从根到叶的路径代表分类规则。
- 决策树的结构:
2、原理
- 决策树希望通过每次分支节点的“决策”使结果变得更纯粹。也就是通过层层筛选,让是否批准分成“批准”和“拒绝”的单一子集。
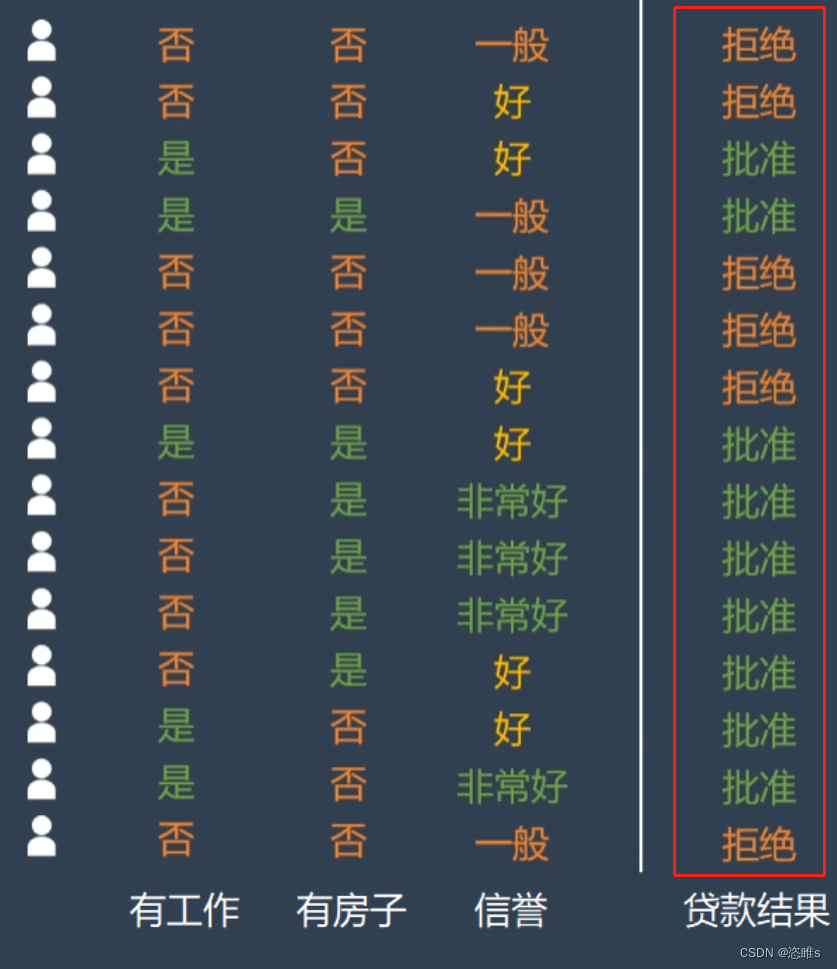
- 举个简单的例子:
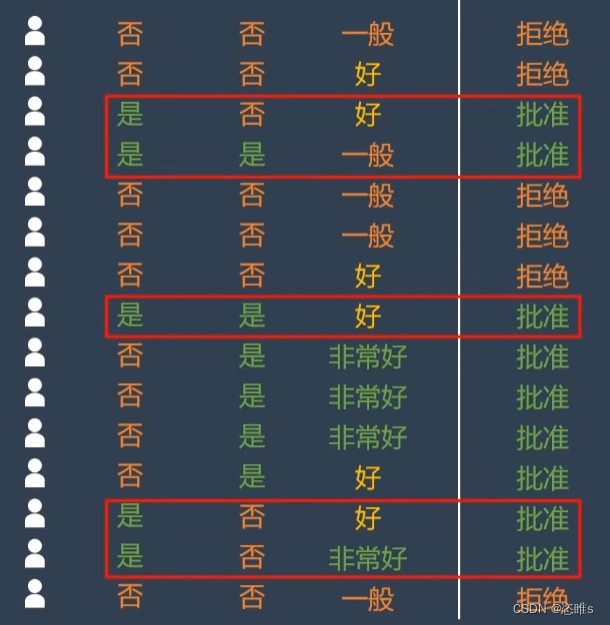
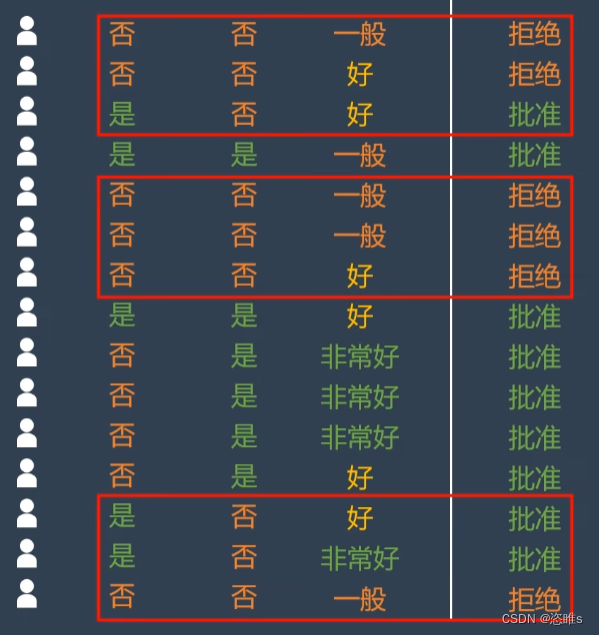
- 使用模型快速判断银行是否给客户放贷。数据经过下列分类之后,最终只剩下单一的子集。
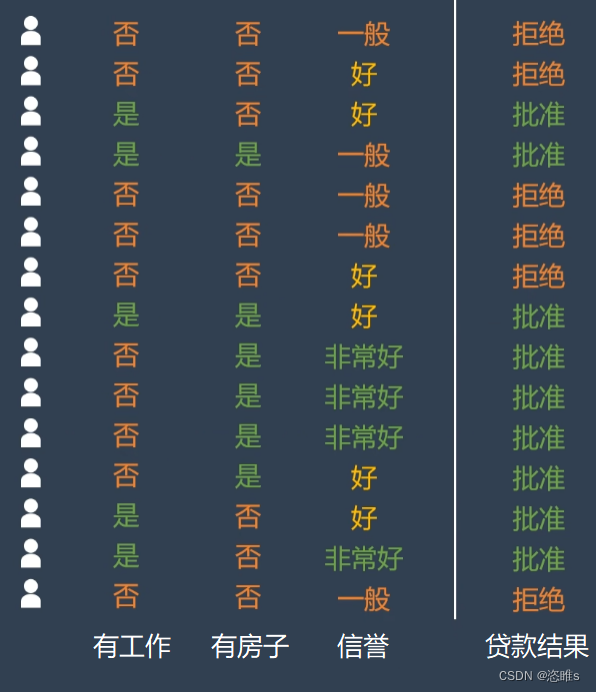
- 模型需要学习哪些特征和相应的正确阈值才能最好地分割数据,即有工作、有房子、信誉,应该选择哪些,应该选择何值。所以,在决策树的生成过程中,分割方法即属性选择的度量是关键。
2.1、基尼系数
- 基尼系数(Gini Index)是决策树学习中常用的一种划分评价指标。
- 基尼系数计算公式:
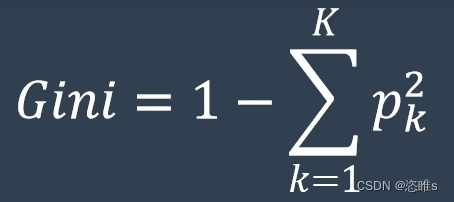 (一减去所有类别概率的平方)
(一减去所有类别概率的平方) - 上述二分分类问题中,公式为:

- 含义:基尼系数衡量了一个数据集合的不确定性。
- 例如:
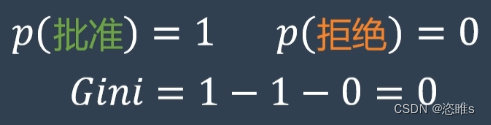


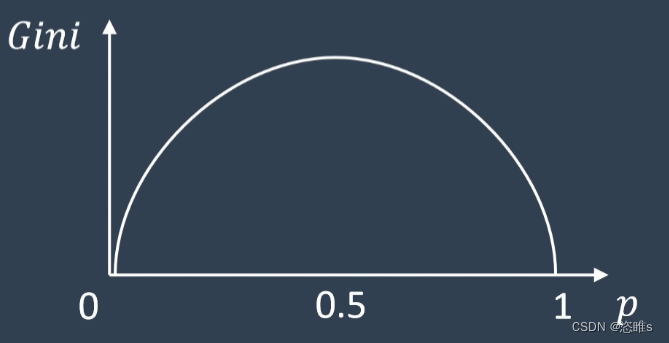 (基尼系数随概率的变化)
(基尼系数随概率的变化)
- 在决策树中,基尼系数最小意味着分割后子集合的纯度最高。所以,选择基尼系数最小的属性,来作为决策树下一级分类的标准即可。
2.2、生成过程
- 计算公式:

2.2.1、选择第一个分类标准
- 首先根据贷款结果计算基尼系数。
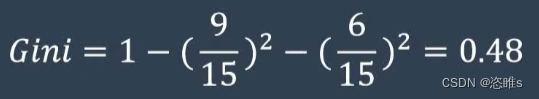
- 可以看出这个基尼系数非常大。
- 再以有无工作来计算基尼系数。
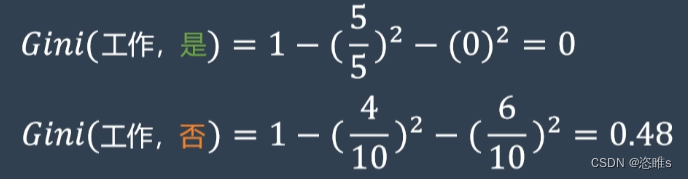
- 计算以工作为分类标准的基尼系数需要通过加权的方式求和得到该标准最终的基尼系数。

- 以此类推,可以计算出以房子和信誉为分类标准的基尼系数。
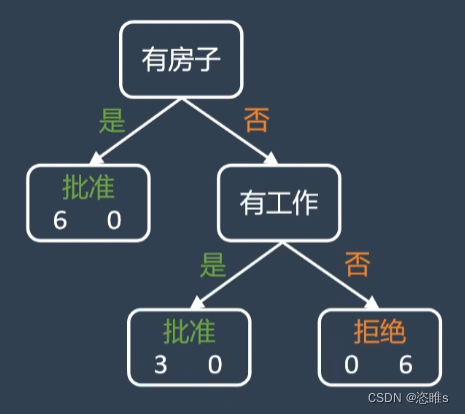
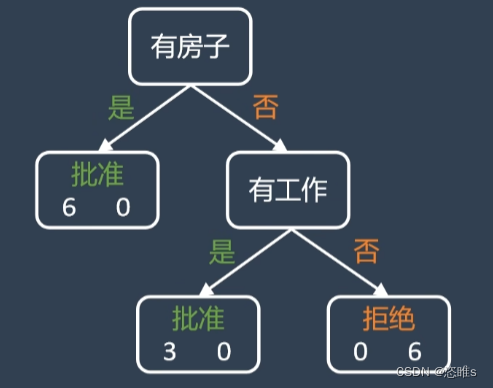
- 其中,以房子为分类标准的基尼系数最小,所以选择它为标准来构建决策树。

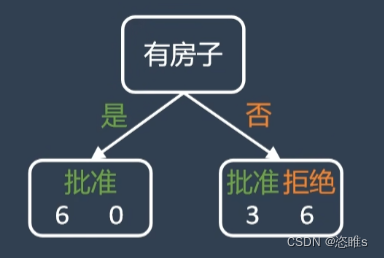
2.2.2、选择下一个分类标准
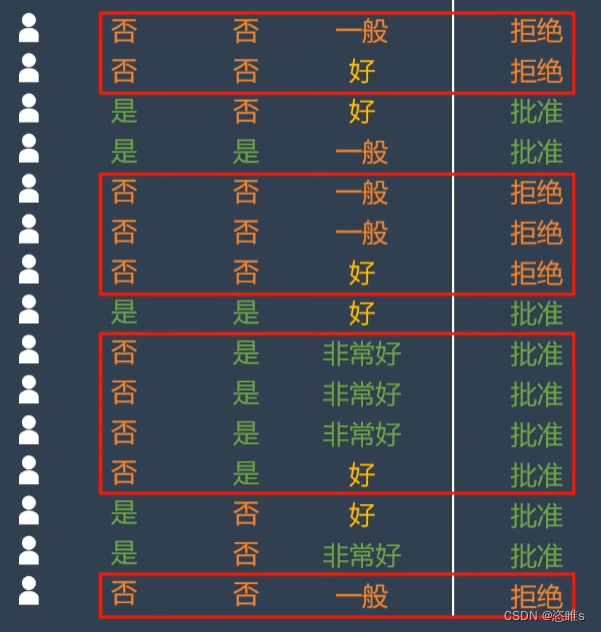
- 根据上述分类,左边已经是一个单一子集,不需要再进行分类。我们对右边的子集进行分类。
- 首先根据贷款结果计算基尼系数。
- 再计算出以工作和信誉为分类标准的基尼系数(只在没有房子的客户中)。
- 其中,以工作为分类标准的基尼系数最小,所以选择它为标准来构建决策树。
- 此时,所有的叶节点都是单一子集,分类完成。
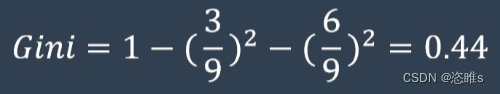

















 577
577











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











