







第三章. Pandas入门
3.8 索引设置
1. 索引的作用:
1).更方便的查询数据
2).使用索引可以提升查询性能
· 如果索引是唯一的,Pandas会使用哈希表优化,查找数据的时间复杂度为O(1)
· 如果索引不是唯一的,但是有序,Pandas会使用二分查找算法,查找数据的时间复杂度为O(logN)
· 如果索引是完全随机的,那么每次查找数据都需要扫描数据表,时间复杂度是O(N)
3).强大的数据结构
2. 重新设置索引:
1).函数格式:
DataFrame.reindex((labels=None, index=None, columns=None, axis=None, method=None, copy=True, level=None, fill_value=nan, limit=None, tolerance=None))
参数说明:
labels:可以是数组
index:行索引
columns:列索引
axis:0:表示行 1:表示列
method:重新设置索引时,选择的差值方式:None,bfill(向后填充),ffill(向前填充)
fill_value:缺失值填充的数据
2)对Series对象重新设置索引:
import pandas as pd
# 对Series对象重新设置索引
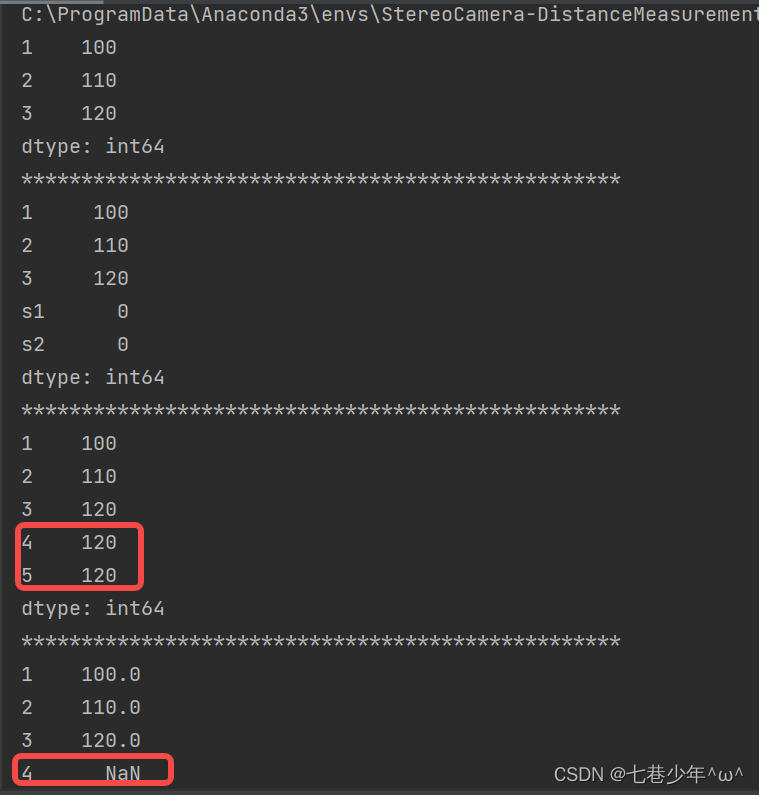
s1 = pd.Series([100, 110, 120], index=[1, 2, 3])
print(s1)
print('*' * 50)
s2 = s1.reindex(index=[1, 2, 3, 's1', 's2'], fill_value=0)
print(s2)
print('*' * 50)
s3 = s1.reindex(index=[1, 2, 3, 4, 5], method='ffill')
print(s3)
print('*' * 50)
s4 = s1.reindex(index=[1, 2, 3, 4, 5], method='bfill')
print(s4)
print('*' * 50)
结果展示:
3).对DataFrame对象重新设置索引:
import pandas as pd
# 对DataFrame对象重新设置索引
pd.set_option('display.unicode.east_asian_width', True)
data = [[60, 70, 80], [90, 100, 110], [120, 130, 140]]
index = ['xiaoming', 'xiaomei', 'xiaoqiang']
column = ['yuwen', 'shuxue', 'yingyu']
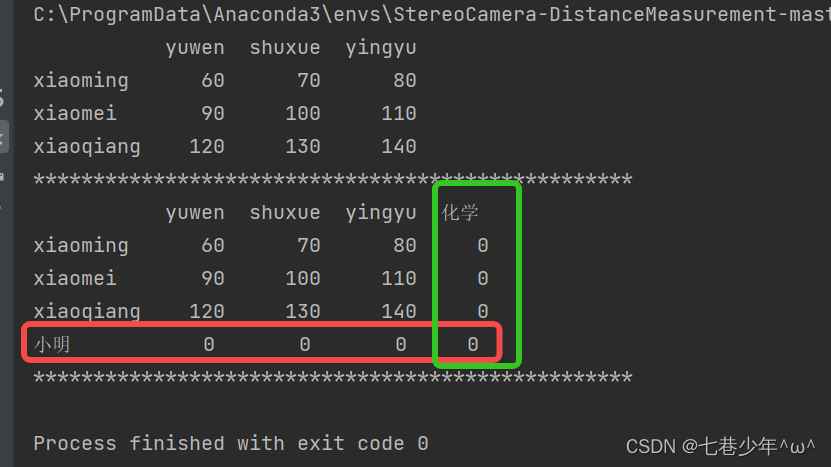
s1 = pd.DataFrame(data=data, index=index, columns=column)
print(s1)
print('*' * 50)
s2 = s1.reindex(index=['xiaoming', 'xiaomei', 'xiaoqiang','小明'], columns=['yuwen', 'shuxue', 'yingyu', '化学'], fill_value=0)
print(s2)
print('*' * 50)
结果展示:
3.设置某列为行索引:
主要使用DataFrame对象中的set_index方法,语法如下:
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
参数说明:
keys.列标签或列标签/数组列表 需要设置为索引的列
drop.默认为True 删除用作新索引的列
append.是否将列附加到现有索引 默认为False
inplace.布尔类型 表示当前操作是否对原数据生效 默认为False
verify_integrity.检查新索引的副本 将其设置为False将提高该方法的性能 默认为false
1).设某列为行索引:
import pandas as pd
pd.set_option("display.unicode.east_asian_width", True)
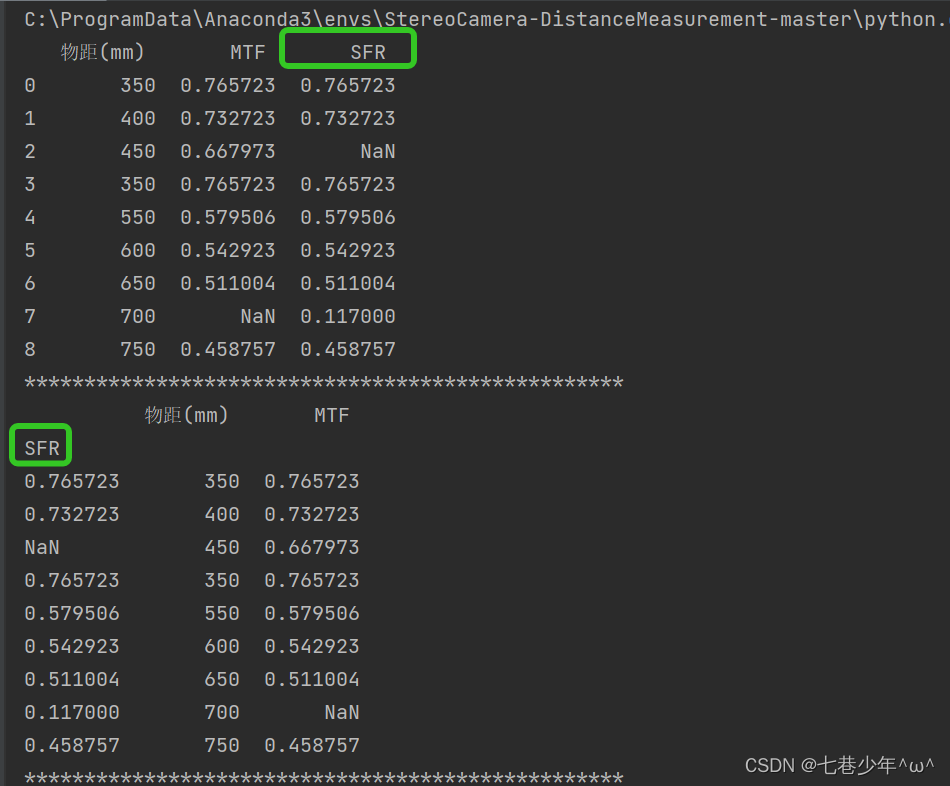
df = pd.read_excel('D:\\MTF_data.xlsx')
print(df)
print('*' * 50)
# 设某列为行索引
df1 = df.set_index(['SFR'])
print(df1)
print('*' * 50)
结果展示:
2).数据清洗或删除后重新设置连续的行索引:
DataFrame.reset_index(level=None, drop=False, inpalce=False, col_level=0, col_fill=' ')
参数说明:
level.数值类型 int、str、tuple或list 默认无 删除所有级别的索引,指定level 删除指定级别
drop.当指定 drop=False 时,则索引列会被还原为普通列;否则,经设置后的新索引值被会丢弃 默认为False
inplace.布尔类型 是否修改原始数据框 默认False
col_level.数值类型 int、str 默认值为0,如果列有多个级别,则确定将标签插入到哪个级别。默认情况下,它将插入到第一级。指定重置后的级别)
col_fill.object 默认‘’,如果列有多个级别,则确定其他级别的命名方式。如果没有,则重复索引名。
import pandas as pd
pd.set_option("display.unicode.east_asian_width", True)
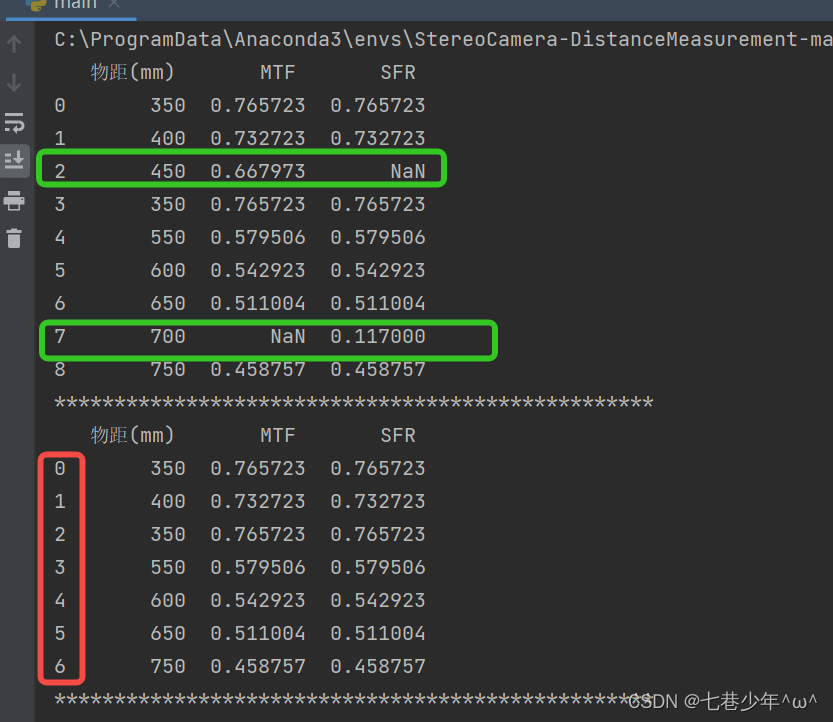
df = pd.read_excel('D:\\MTF_data.xlsx')
print(df)
print('*' * 50)
#数据重洗后重新设置连续的行索引
df1 = df.dropna().reset_index(drop=True)
print(df1)
print('*' * 50)
结果展示:















 1539
1539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









