







第四章. Pandas进阶
4.7 数据导出
1.导出.xlsx文件
1).语法:
DataFrame.to_excel(excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None)
参数说明:
excel_writer:xlsx文件所在路径
sheet_name:数据表的名称
na_rep:缺失数据的表示方法
float_format:格式化浮点数的字符串
encoding:指定Excel文件的编码格式
2).示例
- 示例1:单个.xlsx文件的导出方式
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True) # 处理数据的列标题与数据无法对齐的情况
pd.set_option('display.unicode.east_asian_width', True) # 无法对齐主要是因为列标题是中文
df1 = pd.read_excel('F:\\Note\\图书采购清单.xlsx', sheet_name='Sheet1')
print(df1)
print('*' * 50)
df2 = pd.read_excel('F:\\Note\\图书采购清单.xlsx', sheet_name='Sheet2')
print(df2)
print('*' * 50)
df_merge = pd.merge(df1, df2)
print(df_merge)
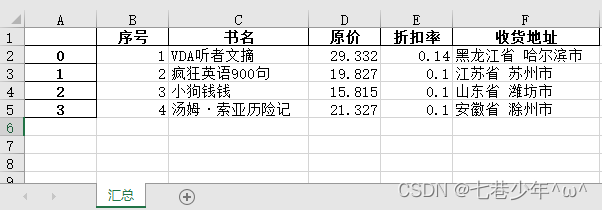
# 导出一个Excel文件
df_merge.to_excel('F:\\Note\\图书采购清单汇总.xlsx',sheet_name='汇总')
结果展示:
- 示例2:多个.xlsx文件的导出方式
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True) # 处理数据的列标题与数据无法对齐的情况
pd.set_option('display.unicode.east_asian_width', True) # 无法对齐主要是因为列标题是中文
df1 = pd.read_excel('F:\\Note\\图书采购清单.xlsx', sheet_name='Sheet1')
print(df1)
print('*' * 50)
df2 = pd.read_excel('F:\\Note\\图书采购清单.xlsx', sheet_name='Sheet2')
print(df2)
print('*' * 50)
df_merge = pd.merge(df1, df2)
print(df_merge)
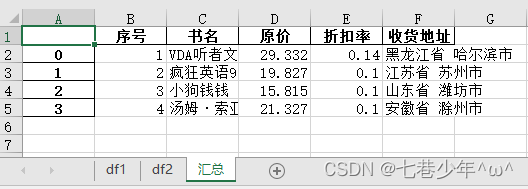
#导出多个Excel文件
excel_Path='F:\\Note\\图书采购清单汇总.xlsx'
with pd.ExcelWriter(excel_Path) as writer:
df1.to_excel(writer, sheet_name='df1')
df2.to_excel(writer, sheet_name='df2')
df_merge.to_excel(writer, sheet_name='汇总')
结果展示:
2.导出.csv文件
1).语法:
DataFrame.to_csv(path_or_buf=None, sep=',', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression='infer', quoting=None, quotechar='"', line_terminator=None, chunksize=None, date_format=None, doublequote=True, escapechar=None, decimal='.', errors='strict')
参数说明:
path_or_buf:csv文件所在路径
sep:分隔符,默认“ ,”
na_rep:缺失数据的表示方式
float_format:浮点数的输出格式
encoding:编码方式:utf-8(默认),gbk
2).示例
- 示例1:相同字段的表首尾相连
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True) # 处理数据的列标题与数据无法对齐的情况
pd.set_option('display.unicode.east_asian_width', True) # 无法对齐主要是因为列标题是中文
df1 = pd.read_excel('F:\\Note\\图书采购清单.xlsx', sheet_name='Sheet1')
print(df1)
print('*' * 50)
df2 = pd.read_excel('F:\\Note\\图书采购清单.xlsx', sheet_name='Sheet2')
print(df2)
print('*' * 50)
df_merge = pd.merge(df1, df2)
print(df_merge)
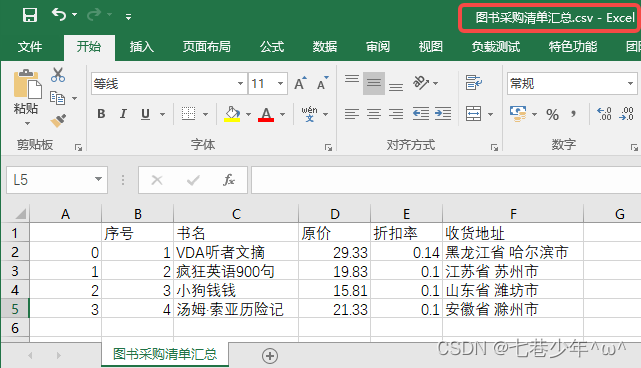
# 导出csv文件
df_merge.to_csv('F:\\Note\\图书采购清单汇总.csv', sep=',', float_format='%.2f', encoding='gbk')
结果展示:














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









