







前言
上一篇blog我们讲到了LeNet的方法,该方法在处理图像分类问题的效果还是不错的,但也仅限于少量数据集的情况下,当数据集较大的时候,LeNet效果并不好,这其实也受限于当时的处理器速度等问题,因此在十多年前,在图像分类领域中,机器学习仍然是占上风的,例如SVM这样的算法。但随着GPU的发展,处理速度提高了,那么我们就可以用更深的深度网络来解决一些数据量更大更复杂的问题了。AlexNet就是在那会因为一场图像分类竞赛大放异彩而变得流行,也推动了深度学习的发展。
AlexNet介绍
AlexNet相较于LeNet来说,有三个不同点:
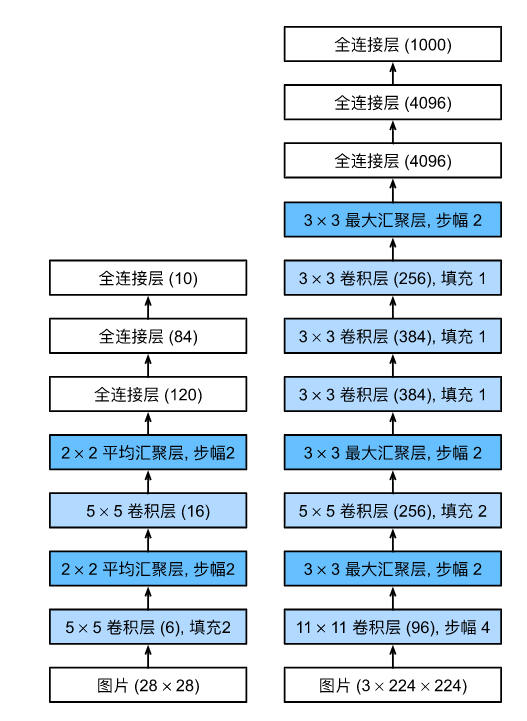
1、模型深度、模型复杂度、输入图像的分辨率都有进一步的提升,对比图如下:左LeNet右AlexNet
2、激活函数的改变:LeNet使用sigmoid,AlexNet使用ReLU。原因引用李沐老师的一句话:
一方面,ReLU激活函数的计算更简单,它不需要如sigmoid激活函数那般复杂的求幂运算。 另一方面,当使用不同的参数初始化方法时,ReLU激活函数使训练模型更加容易。 当sigmoid激活函数的输出非常接近于0或1时,这些区域的梯度几乎为0,因此反向传播无法继续更新一些模型参数。 相反,ReLU激活函数在正区间的梯度总是1。 因此,如果模型参数没有正确初始化,sigmoid函数可能在正区间内得到几乎为0的梯度,从而使模型无法得到有效的训练。
3、AlexNet的池化层选用最大池化层,LeNet选用的是平均池化层
4、全连接层用了暂退法(DropOut)
实现
实现代码比较简单,其中输入图像的分辨率为224*224
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
# 这里,我们使用一个11*11的更大窗口来捕捉对象。
# 同时,步幅为4,以减少输出的高度和宽度。
# 另外,输出通道的数目远大于LeNet
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 使用三个连续的卷积层和较小的卷积窗口。
# 除了最后的卷积层,输出通道的数量进一步增加。
# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合
nn.Linear(6400, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10))
可以通过如下方法,查看每一层神经元个数、神经元的像素数
X = torch.randn(1, 1, 224, 224)
for layer in net:
X=layer(X)
print(layer.__class__.__name__,'output shape:\t',X.shape)
结果:
Conv2d output shape: torch.Size([1, 96, 54, 54])
ReLU output shape: torch.Size([1, 96, 54, 54])
MaxPool2d output shape: torch.Size([1, 96, 26, 26])
Conv2d output shape: torch.Size([1, 256, 26, 26])
ReLU output shape: torch.Size([1, 256, 26, 26])
MaxPool2d output shape: torch.Size([1, 256, 12, 12])
Conv2d output shape: torch.Size([1, 384, 12, 12])
ReLU output shape: torch.Size([1, 384, 12, 12])
Conv2d output shape: torch.Size([1, 384, 12, 12])
ReLU output shape: torch.Size([1, 384, 12, 12])
Conv2d output shape: torch.Size([1, 256, 12, 12])
ReLU output shape: torch.Size([1, 256, 12, 12])
MaxPool2d output shape: torch.Size([1, 256, 5, 5])
Flatten output shape: torch.Size([1, 6400])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 10])
读取数据集
这里读取的仍然是LeNet的数据集,由于AlexNet当时竞赛跑的数据集实在太大,故使用resize方法来对原始28*28图像拉伸.。
batch_size = 32
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
训练
train_ch6的实现代码见上一篇blog:深度学习14-LeNet
lr, num_epochs = 0.01, 5
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
小结
AlexNet基于CNN+MLP实现的,该算法对于硬件配置还是比较高的,本人使用的1050显卡,已经跑不动了,因此深度学习是一个很贵的算法啊。














 5030
5030











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









