






文章地址:https://openreview.net/pdf?id=vSVLM2j9eie
代码地址:https://github.com/Thinklab-SJTU/Crossformer
文章是阅读论文后的个人总结,可能存在理解上的偏差,欢迎大家一起交流学习,给我指出问题。
1.问题描述
作者认为之前的研究者在多元时序预测工作中花了很多精力对于时间依赖性的捕获,比如Informer、Autoformer提出了各种Attention变体。但是作者认为在多元时序预测中捕获变量之间的相关性也十分重要,但是之前的工作忽略了对变量依赖性的关注。
在这里我们需要回顾的是在传统的Transformer中Attention机制捕获的是时间依赖性,FNN中也不明显地进行了捕获变量之间的相关性。传统Transformer的建模策略是将同一时间点的不同变量嵌入为一个Token,然后再输入到Attention中计算时间依赖性,接着输入到FNN中。(因为这里的FNN作用在一个Token上,由单步时间点构成的Token,因为其感受野小,能够捕获的局部信息就比较少;同时由于在变量之间还可能存在时间不对齐这些都导致了在FNN中捕获的变量依赖性不准确)下面这幅图片描述的是传统Transformer的Point-Wise Embedding方式
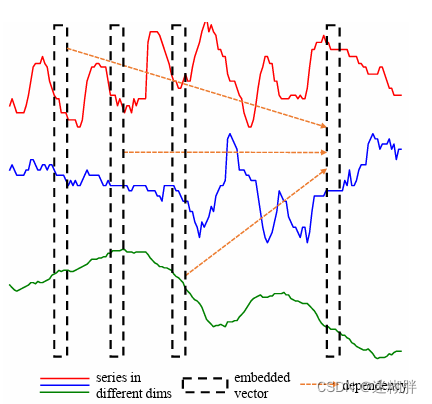
在长时间序列预测任务中,一个时间步的单独值只提供有限的信息,作者通过分析传统transformer的attention权值可视化图得到:时间序列倾向于被“切片”,因为在模型训练好后,时序的注意力权值出现了连续低数值和连续高数值的情况。
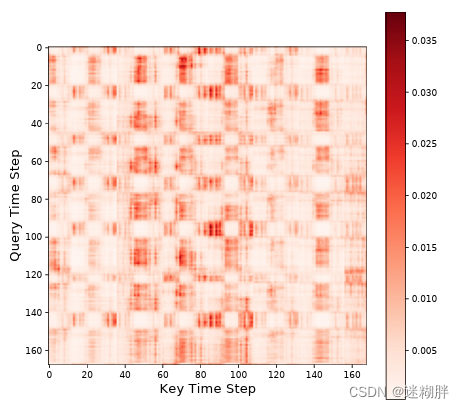
综上,可以把作者的问题总结为两点:
1. 之前的工作没有关注变量依赖性。
2. 传统的Transformer方式中的Point-wise Embedding不适合长时间的多元时序预测
2.创新点
- 维度-段式(DSW)嵌入:将多变量时间序列数据沿每个维度划分为段,将这些段嵌入到特征向量中。这种方法保持了时间和维度信息。
- 两阶段注意力(TSA)层:Crossformer使用TSA层来有效捕捉时间(Cross-Time Stage)和变量维度(Cross-DimensionStage)之间的依性。
- 分层编码器-解码器(HED)结构:模型使用HED来利用不同规模的信息进行预测。
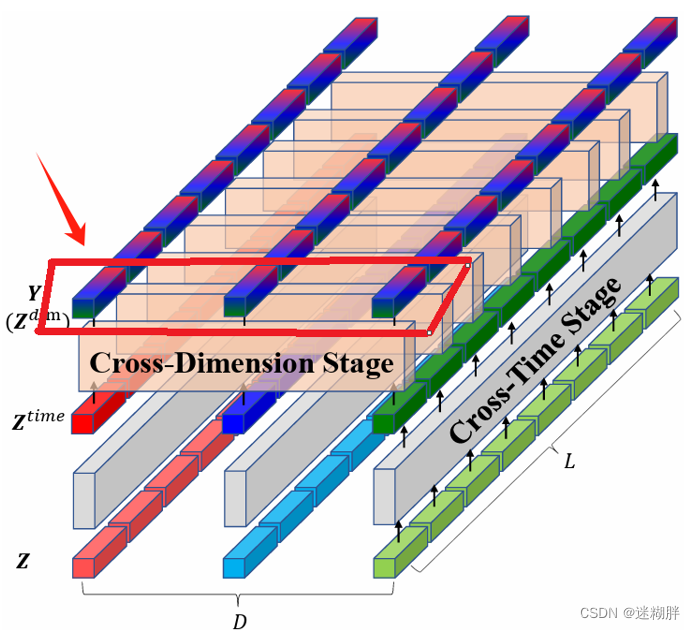
3.Crossformer
首先给出Crossformer的完整框架图
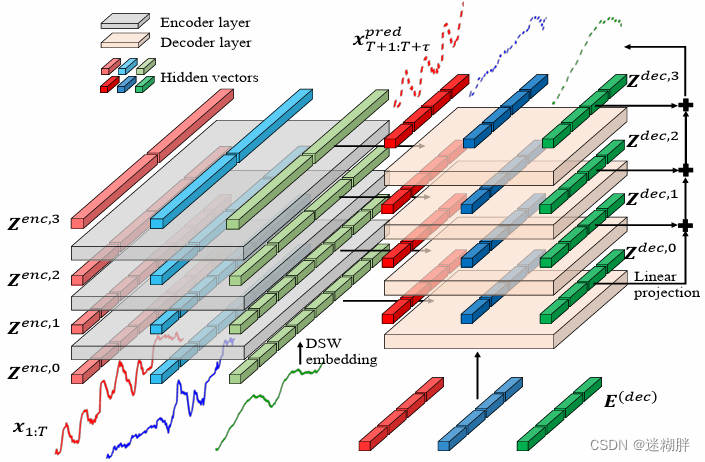
3.1 Dimension-Segment-Wise Embedding(DSW)
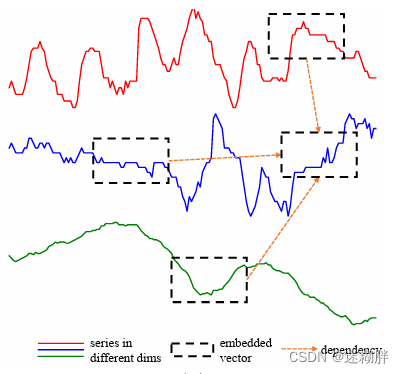
DSW嵌入中,每个维度的时间序列数据点被分成一定长度的段。然后,每个段被嵌入到一个向量中,方法是使用线性投影加上位置嵌入。线性投影矩阵E和位置嵌入Epos都是可学习的。这样,每个嵌入后的向量hid表示一个时间序列的单变量段,最终得到一个二维向量数组H。下面这幅图描述了本文的Patch-Wise Embedding方式
下面第一个式子表示每个序列中的第i个patch,第二个式子表示的是第i个patch的起始点具体位置。注意在这里分patch之前还需对序列先进行填充,然后再分成若干个连续的分块。
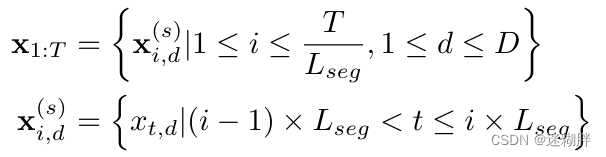
这个式子表示的是每个Patch进行Value_Embedding和Position_Embedding
,其中E为可学习的矩阵。
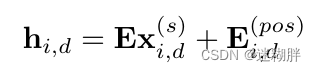
DSW embedding的优点在于它能够更好地捕捉时间序列中的局部模式。因为在时间序列中,相邻的数据点通常具有相似的取值,而DSW embedding将每个维度的时间序列分成若干个连续段,可以更好地保留这种局部模式。此外,DSW embedding还能够减少模型的参数量,因为它只需要对每个段做embedding,而不是每个时间步的所有数据点。
3.1 Two-Stage Attention Layer(TSA)
为什么作者要分两阶段来进行Attention计算?
- 首先在CV领域中的patch,对于一个patch的长和宽我们是可以互换的,但是在时序预测中的patch,其长和宽分别代表不同的含义,对于一个patch的长和宽我们不能互换,需要分开计算。
- 如果直接在各个Patch之间进行Attention计算它的计算复杂度是非常高的,所以作者提出分阶段进行来减少计算复杂度。原本计算复杂度为:
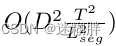
3.1.1 Cross-Time Stage
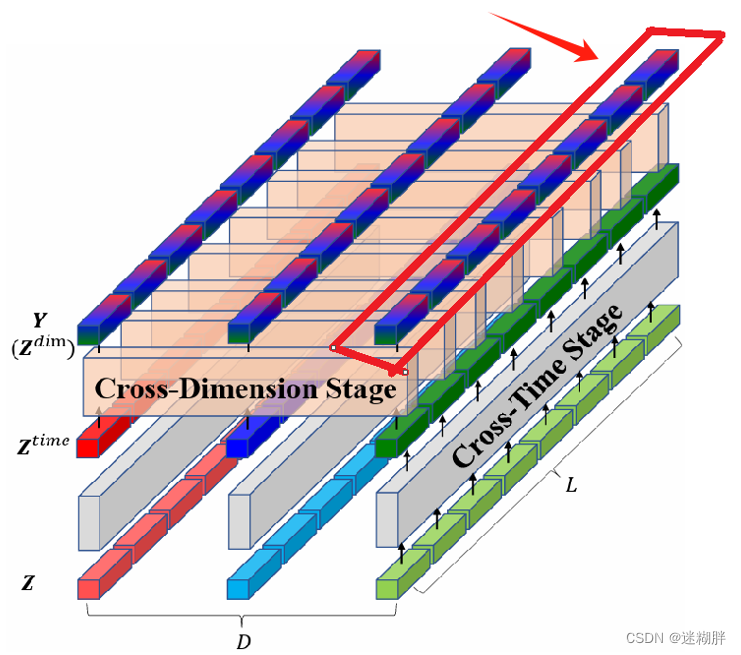
Cross-Time Stage模块的示意图如上所示。对于时间维度,直接应用多头自注意力(MSA)机制来捕捉同一维度内不同时间段之间的依赖关系。
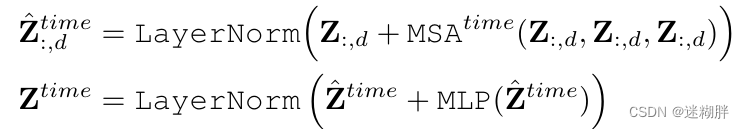
计算复杂度为: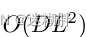
!!!注意:TSA层接收一个二维数组 Z 作为输入,这个数组可能是维度-段式(DSW)嵌入的输出或下层TSA层的输出。具体会在Encoder部分详细解释。
3.1.2 Cross-Dimension Stage
Cross-Dimension Stage模块的示意图如上所示,Cross-Dimension Stage也是本文的重要一个模块。
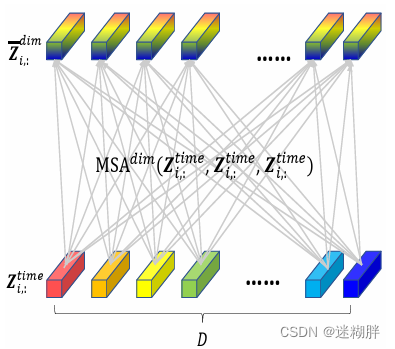
空间维度的attention,指的是对齐不同变量的各个时间步。如上图,空间维度的对齐,目的是在变量之间寻找两两时间步的关系,这样能深入刻画一个变量对另一个变量的影响。具体的做法为,在变量维度做self-attention,如上图所示。
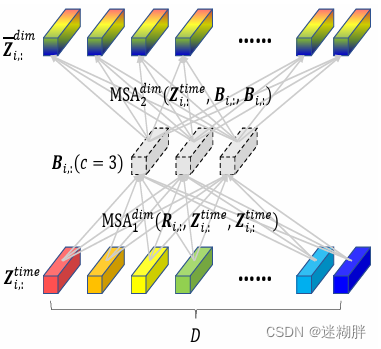
但是这种做法会导致运算复杂度较高,因此提出了使用路由的方式,增加几个中间向量,将变量各个时间步的信息先利用一层attention汇聚到中间向量上,再利用中间向量和原序列做self-attention,中间向量可以看成是一种路由。即先对输入信息做聚类,再进一步分发,起到了降低运算量的作用,过程如上图所示。
下面式子是Cross-Dimension Stage模块用到的关键式子,其中R表示可学习的向量矩阵,B就是路由。这里的两个MSA分别是将变量各个时间步的信息先利用一层attention汇聚到中间向量上,再利用中间向量和原序列做self-attention。
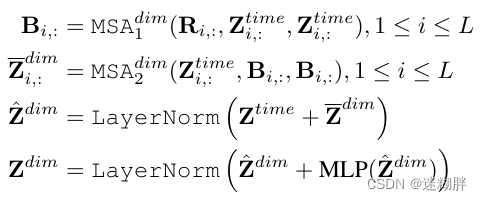
Cross-Dimension Stage计算复杂度: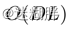
所以TSA总的计算复杂度为:
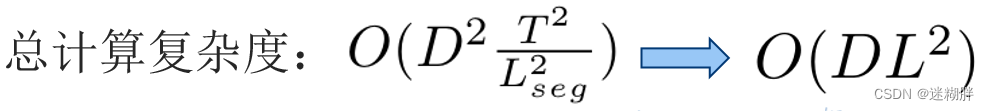
3.2 Hierarchical Encoder-Decoder(HED)
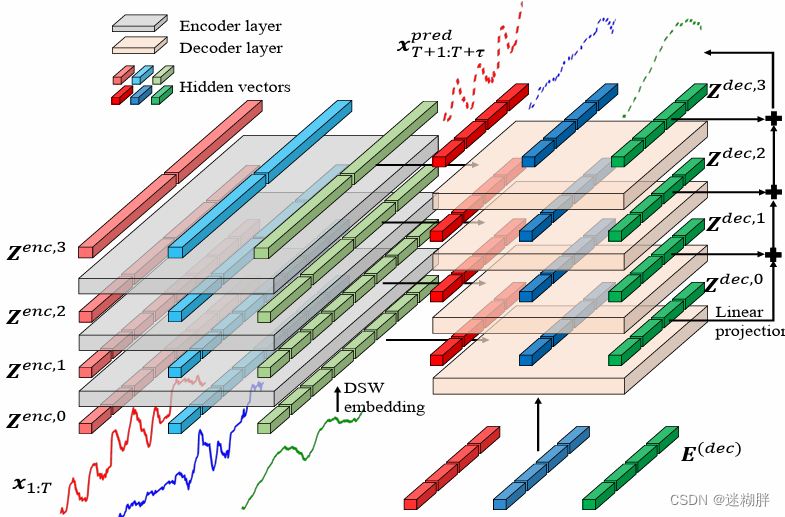
上面这幅图就是整个Encoder和Decoder模块的示意图了,我们可以看到Encoder一共了三层,Decoder有四层。
第一层的Encoder的输入为Embedding层的输出,第二层和第三层台地 输入为上一层Encoder的输出,作者在这里为了实现多尺度,在第二、三层进行注意力之前将上一层的Token多个合并为一个(这里具体是两个合并为一个)。所以在这里我们可以看到从上到下Encoder的每层Token数量分别为2,4,8。
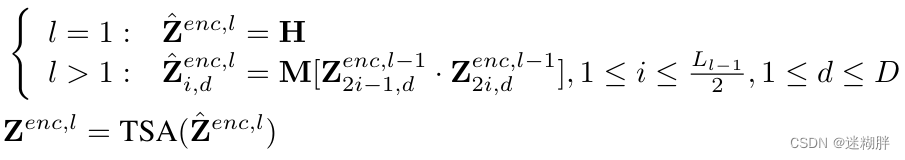
Decoder和Encoder类似,但是需要注意的是Decoder有一个交叉注意力计算,Decoder会利用不同层次的编码进行预测,各层的预测结果加到一起,得到最终的预测结果。

最后再将多尺度的Decoder输出通过Projector映射为最终的输出:
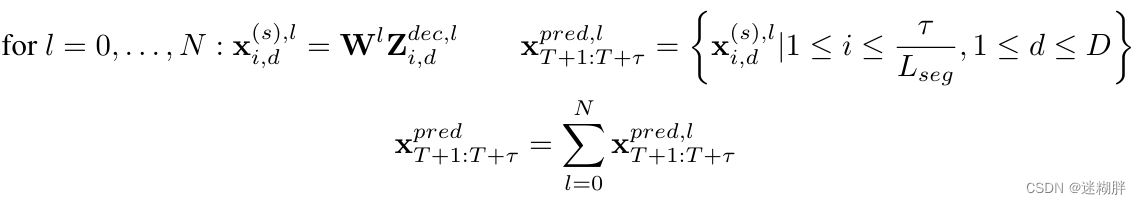
4.实验
4.1 和主流模型对比
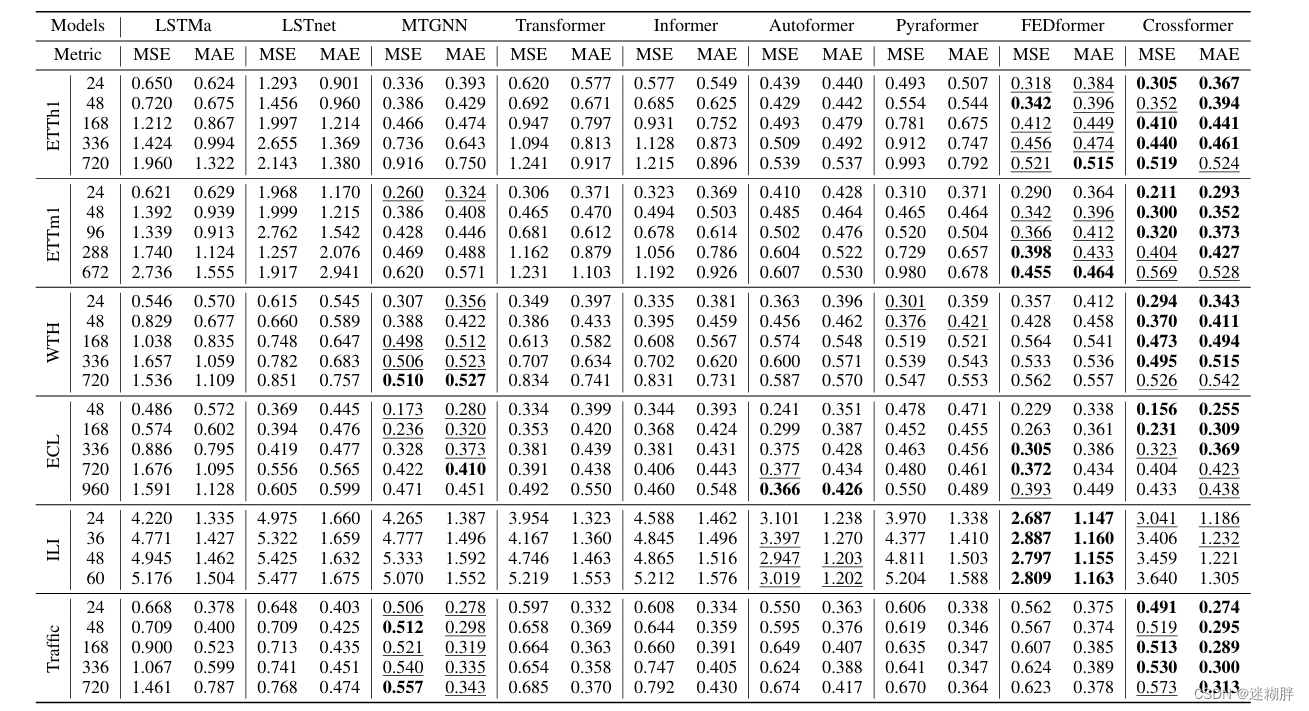
从结果我们可以看到Crossformer 基本上取得Sota效果,其中值得注意的是,也许是由于通过GNN明确使用跨维度依赖关系,MTGNN在许多基于Transformer的基线模型之上表现出色 。但是我觉得这里作者既然借鉴了PatchTST这篇工作(同样是将序列分块),却没有将其对比,我查看了PatchTST这篇文章,发现PatchTST这篇文章在很多数据集上的效果是比Crossformer效果好的,其实也间接说明,有时候简单的模型就适合时序预测了。
4.2 组件消融实验

DSW对应patch编码,TSA对应两阶段attention,HED对应层次Encoder-Decoder。可以看出,相比最初的Transformer建模,DSW、TSA、HED各个模块都会给模型效果带来显著的提升。
4.3 超参数有效性验证实验
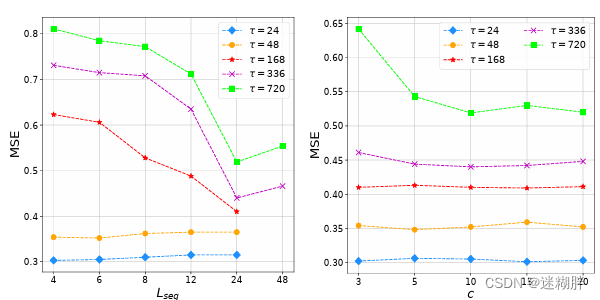
上面左边是Patch长度对比实验,可以看到在较长序列(L>168)随着patch长度增长MSE在减少,但是超过24之后就变大了
上面右边是路由器数量的对比实验,也是在超长序列路由器数量增加,MSE才会有 明显变化。在这里我有个疑问,路由器在文中是用来减少变量维度的计算复杂度,应该对比的是不同变量数量时,路由器数对其的影响呀?为什么这里是序列输入长度?
4.4 计算效率对比实验
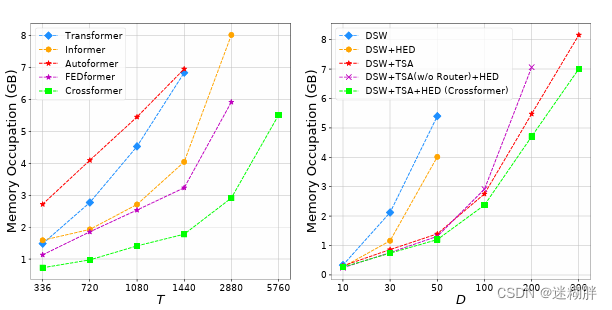
上面左边是输入序列长度实验,可以看到随着T的增加,本文的内存暂用变化是最缓慢的。
上面右边是变量维度的实验,也可以看到随着D的增加,完整Crossformer变化是最缓慢的。
5.结论
-
Crossformer是一种基于transformer的模型,利用跨维度依赖进行多元时间序列(MTS)预测。
-
通过DSW embedding,将输入数据嵌入到二维矢量数组中,以保留时间和维度信息。
-
为了捕获跨时间和跨维度依赖关系,设计两阶段注意(TSA)层。
-
利用DSW嵌入和TSA层,设计了一种分层编码器(HED)来利用不同尺度的信息。















 6558
6558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









