







机器学习
没有免费午餐定理和三大机器学习任务
如何对模型进行评估
K-Means(K均值聚类)原理及代码实现
KNN(K最近邻算法)原理及代码实现
KMeans和KNN的联合演习
前言
现在,我们已经有了一个聚类算法KMeans和一个分类算法KNN。
我们随机生成一个数据集来进行测试。
1.导入必要的头文件:
# 之前完成的代码
from KMeans import KMeans, plotKmeans
from KNN import KNN, plotKNN
import random
import numpy as np
2.随机生成二维数据用以测试:
if __name__ == '__main__':
# 随机生成二维点图用以测试
points = []
data = []
i = 0
# 数据是不重复的
while i < 30:
point = [random.randint(1, 10), random.randint(1, 10)]
if point not in points:
points.append(point)
data.append(np.array(point, dtype='float64'))
i += 1
3.使用Kmeans将数据聚为四类
cluster = KMeans(data, 4)
cluster.cluster()
# 绘制类别图
plotKmeans(cluster)
4.给data添加标签:
data = []
for i in range(cluster.k):
for item in cluster.clusters[i]:
data.append(np.r_[item, np.array([i])])
random.shuffle(data)
n = 4
test_data = data[:n]
test_data_labels = []
for i in range(len(test_data)):
test_data_labels.append(test_data[i][-1])
test_data[i] = test_data[i][:-1]
train_data = data[n:]
5.使用KNN分类:
correct = 0
incorrect = 0
classifier = KNN(train_data, test_data, 5, 'E')
classifier.classify()
result = classifier.result
for i in range(len(test_data)):
if test_data_labels[i] == result[i]:
correct += 1
else:
incorrect += 1
print("Correct: " + str(correct))
print("Incorrect: " + str(incorrect))
print("AC Rate: {:.2f}%".format(100 * (correct / (correct + incorrect))))
plotKNN(classifier)
结果
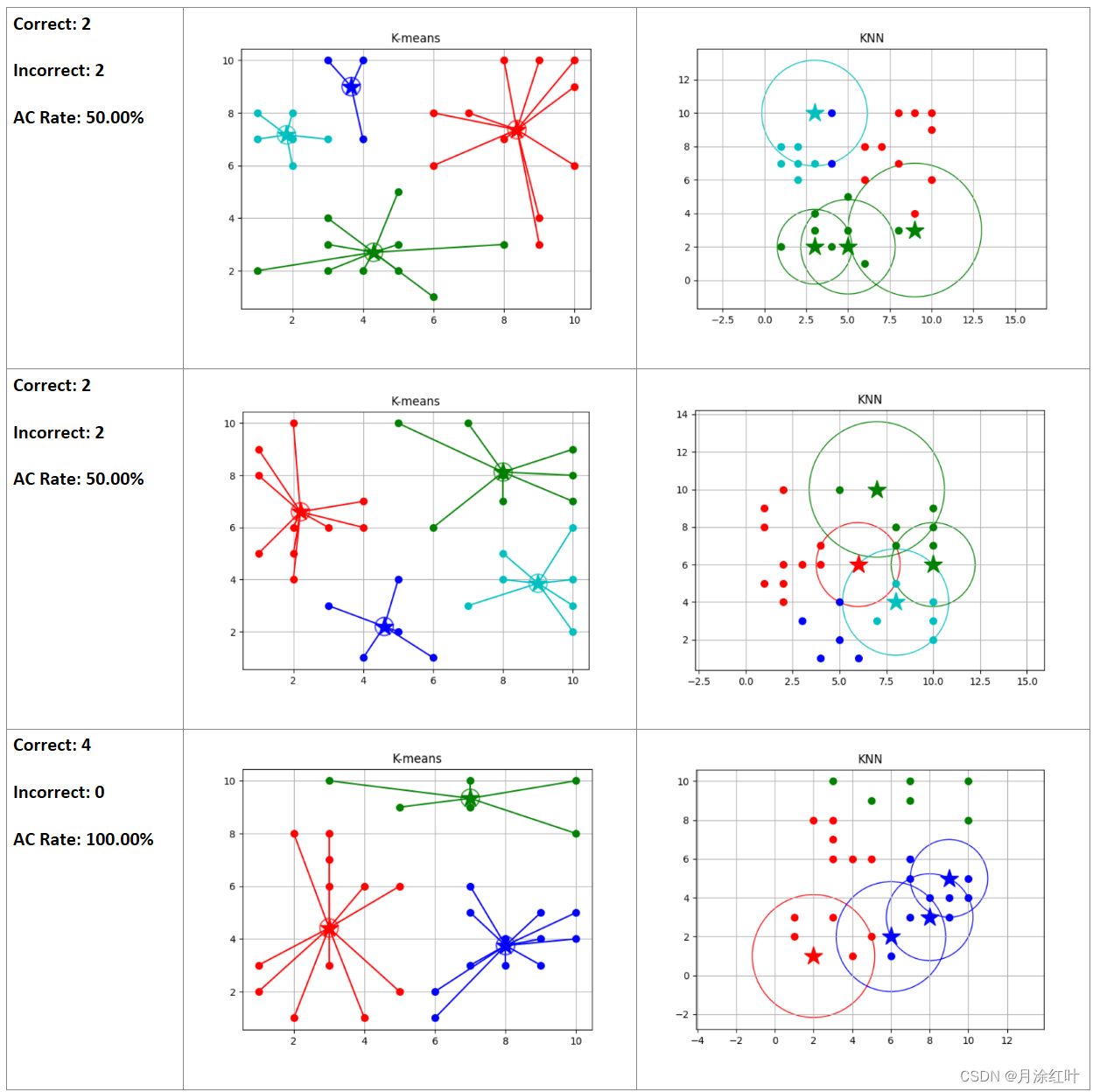















 3343
3343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









