







前言:总纲《计算机视觉学习路》
图像分割
概念:将前景物体从背景中分离出来
分类:传统的图像分割和基于深度学习的图像分割,本章主要介绍传统图像分割方法。
分水岭法
其基本原理为:
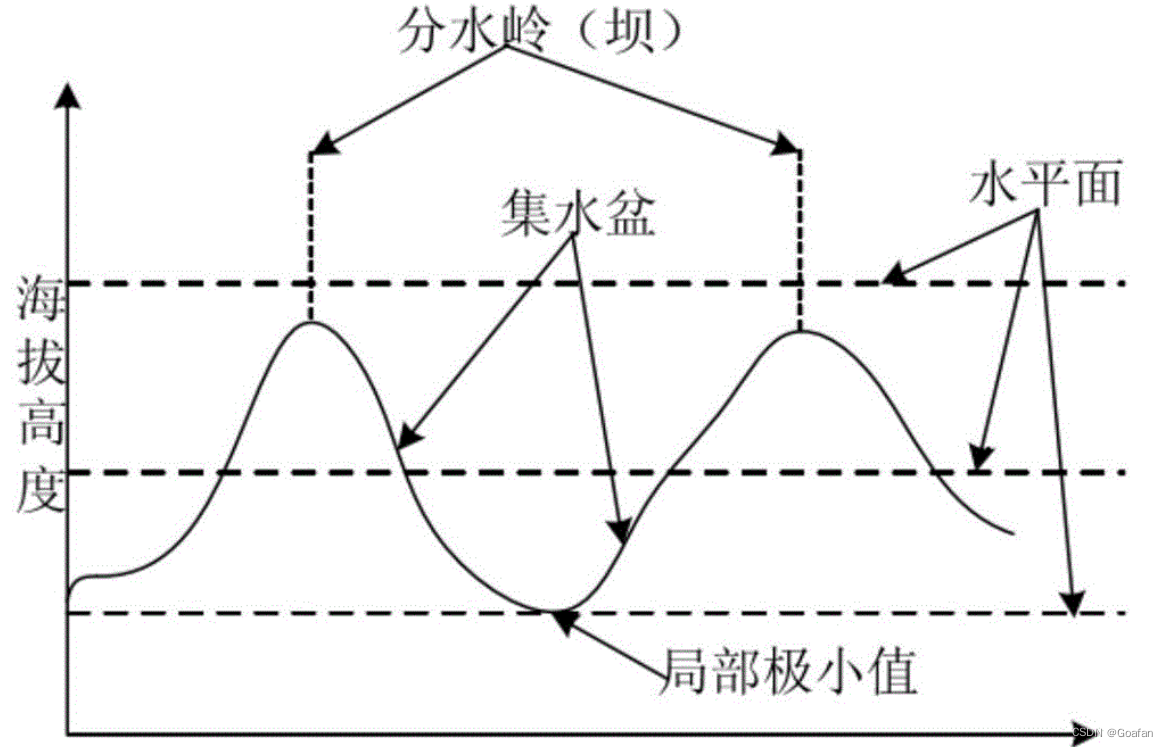
存在的问题:当图像存在过多的极小区域时,会产生许多小的集水盆
处理步骤:
1.标记背景:灰度化-二值化-开运算-膨胀
2.标记前景:距离变换-二值化
3.标记未知区域 : 背景减去前景
4.创建marker : 求前景的连通域,背景像素值设为1,位置区域设为0
5.进行分割 watershed(img , masker) # masker:前景、背景设置不同的值用以区分
还需要了解两个函数:
距离变换
distanceTransform(img , distanceType , maskSize) # 计算非零值到零值的距离
distanceType : DIST_L1 DIST_L2
maskSize : L1用3x3 L2用5x5
求连通域
connectedComponents(img , connectivity) # 求图像中所有非零元素的连通域
connectivity : 4 、8(默认) 连通域

import cv2
import numpy as np
import matplotlib.pyplot as mp
img = cv2.imread('../img/water_coins.jpeg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 获取背景
# 1. 二值化 , 这里的阈值设置0,其实是用到了OTSU自适应阈值,不需要我们自己设置
ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
# 得到背景为黑色,硬币为白色的图
cv2.imshow('thresh', thresh)
# 2. 形态学获取背景
kernel = np.ones((3, 3), np.uint8)
# 开运算去除噪点
open_ = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel, iterations=2)
# 膨胀 得到背景
bg = cv2.dilate(open_, kernel, iterations=1)
cv2.imshow('bg', bg)
# 获取前景物体
dist = cv2.distanceTransform(open_, cv2.DIST_L2, 5)
# fg 前景
ret1, fg = cv2.threshold(dist, 0.7 * dist.max(), 255, cv2.THRESH_BINARY)
cv2.imshow('fg', fg)
# mp.imshow(dist, cmap='gray') # 使用matplotlib显示出梯度
# mp.show()
# exit()
# 获取未知区域
fg = np.uint8(fg)
unknow = cv2.subtract(bg, fg)
cv2.imshow('unknow', unknow)
# 创建marker
# 创建连通域
ret2,marker = cv2.connectedComponents(fg)
marker = marker + 1 # 将所有的背景用1表示,前景255+1没什么影响
marker[unknow==255] = 0 # 设置未知区域的值为0
#进行图像分割
result = cv2.watershed(img , marker)
img[result == -1] = [0,0,255]
cv2.imshow('img',img)
cv2.waitKey(0)
GrabCut
通过交互的方式获取前景物体
原理:
- 用户指定前景的大体区域,剩下的为背景区域
- 用户明确指定某些地方为前景或背景
- GrabCut采用分段迭代的方法分析前景物体形成模型树
- 最后根据权重决定某个像素是前景还是背景
1.定义主体结构(类)
2.鼠标事件处理
3.调用GrabCut实现前景与背景的分离
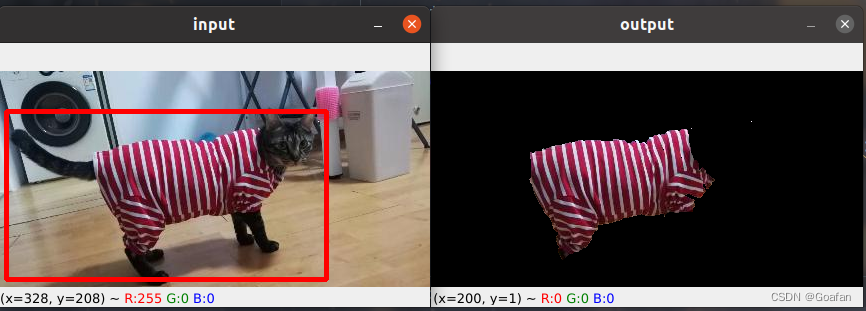
小衣服真不错,哈哈哈哈还是用PS吧
import cv2
import numpy as np
class App:
flag_rect = False
rect = (0, 0, 0, 0)
startX = 0
startY = 0
def onmouse(self, event, x, y, flags, param):
if event == cv2.EVENT_LBUTTONDOWN:
self.flag_rect = True
self.startX = x
self.startY = y
print("LBUTTIONDOWN")
elif event == cv2.EVENT_LBUTTONUP:
self.flag_rect = False
cv2.rectangle(self.img,
(self.startX, self.startY),
(x, y),
(0, 0, 255),
3)
self.rect = (min(self.startX, x), min(self.startY, y),
abs(self.startX - x),
abs(self.startY - y))
print("LBUTTIONUP")
elif event == cv2.EVENT_MOUSEMOVE:
if self.flag_rect == True:
self.img = self.img2.copy()
cv2.rectangle(self.img,
(self.startX, self.startY),
(x, y),
(255, 0, 0),
3)
print("MOUSEMOVE")
print("onmouse")
def run(self):
print("run...")
cv2.namedWindow('input')
cv2.setMouseCallback('input', self.onmouse)
self.img = cv2.imread('../img/cat.jpg')
self.img2 = self.img.copy()
self.mask = np.zeros(self.img.shape[:2], dtype=np.uint8)
self.output = np.zeros(self.img.shape, np.uint8)
while (1):
cv2.imshow('input', self.img)
cv2.imshow('output', self.output)
k = cv2.waitKey(100)
if k == 113: # q退出
break
if k == ord('g'): # g抠图
bgdmodel = np.zeros((1, 65), np.float64)
fgdmodel = np.zeros((1, 65), np.float64)
cv2.grabCut(self.img2, self.mask, self.rect,
bgdmodel, fgdmodel,
1,
cv2.GC_INIT_WITH_RECT)
mask2 = np.where((self.mask == 1) | (self.mask == 3), 255, 0).astype('uint8')
self.output = cv2.bitwise_and(self.img2, self.img2, mask=mask2)
App().run()
MeanShift
原理:色彩平滑,相近的颜色形成一片区域,以图像任意一点p为圆心,半径为sp,色彩幅值为sr进行不断迭代。
pyMeanShiftFiltering(img , double sp , doule sr)
可以自己调节sp和sr看看效果 。色彩平滑后就可以进行边缘提取和轮廓提取然后绘制。

import cv2
import numpy as np
img = cv2.imread('../img/flower.png')
m_img = cv2.pyrMeanShiftFiltering(img, 20, 30)
canny = cv2.Canny(m_img, 150, 300)
contours, h = cv2.findContours(canny, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cv2.imshow('img', img)
cv2.imshow('m_img', m_img)
cv2.imshow('canny', canny)
cv2.drawContours(img, contours, -1, (0, 0, 255, 2))
cv2.imshow('result',img)
cv2.waitKey(0)
视频背景抠除
视频背景抠除的原理:在某一组帧中,背景几乎是不变的
MOG
混合高斯模型为基础的前景/背景分离算法
mog = cv2.bgsegm.createBackgroundSubtratorMOG( )
result_frame = mog.apply(视频帧)
import cv2
import numpy as np
cap = cv2.VideoCapture('../img/vtest.avi')
mog = cv2.bgsegm.createBackgroundSubtractorMOG()
while(True):
ret, frame = cap.read()
fgmask = mog.apply(frame)
cv2.imshow('img',fgmask)
k = cv2.waitKey(10)
if k ==113: # q 退出
break
cap.release()
cv2.destroyAllWindows()MOG2
与MOG类似,对亮度产生的阴影有更好的识别
mog2 = cv2.createBackgroundSubtracorMOG2(history,detectShadows )
history : 默认500毫秒
detectShadows : True检测阴影, false不检测
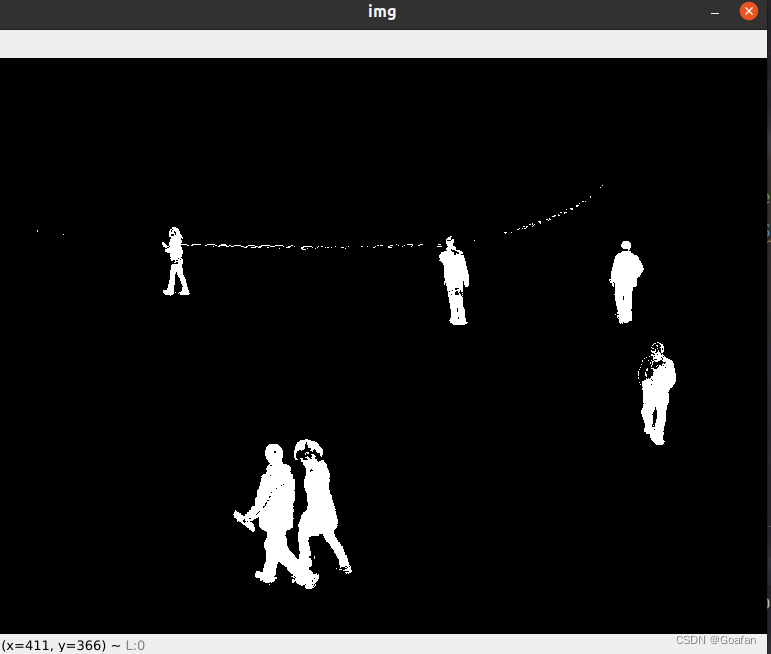
 可以看到人有阴影。缺点是会产生很多噪点
可以看到人有阴影。缺点是会产生很多噪点
import cv2
import numpy as np
cap = cv2.VideoCapture('../img/vtest.avi')
# mog = cv2.bgsegm.createBackgroundSubtractorMOG()
mog = cv2.createBackgroundSubtractorMOG2()
while (True):
ret, frame = cap.read()
fgmask = mog.apply(frame)
cv2.imshow('img', fgmask)
k = cv2.waitKey(10)
if k == 27:
break
cap.release()
cv2.destroyAllWindows()
GMG
静态背景图像估计和每个像素的贝叶斯分割,抗噪性强
cv2.bgsegm.createBackgroundSubtractorGMG( initializationFrames...) # 初始帧数默认120
 刚开始会有很长时间的黑屏。因为默认初始帧数为120,可以自己设置为10
刚开始会有很长时间的黑屏。因为默认初始帧数为120,可以自己设置为10
import cv2
import numpy as np
cap = cv2.VideoCapture('../img/vtest.avi')
# mog = cv2.bgsegm.createBackgroundSubtractorMOG()
# mog = cv2.createBackgroundSubtractorMOG2()
mog = cv2.bgsegm.createBackgroundSubtractorGMG(10)
while (True):
ret, frame = cap.read()
fgmask = mog.apply(frame)
cv2.imshow('img', fgmask)
k = cv2.waitKey(10)
if k == 113:
break
cap.release()
cv2.destroyAllWindows()
图像修复
inpaint(img , mask , inpaintRadius , flags)
inpaintRadius : 每个点的圆形领域半径
flags: INPAINT_NS , INPAINT_TELEA

import cv2
import numpy as np
img = cv2.imread('../img/inpaint.png')
mask = cv2.imread('../img/inpaint_mask.png', 0)
dst = cv2.inpaint(img, mask, 5, cv2.INPAINT_TELEA)
cv2.imshow('dst', dst)
cv2.imshow('img', img)
cv2.waitKey()
可以看到只要有掩码图像,就可以恢复原图。
那么怎么找到掩码图片呢?可以自己定义一个函数,定义鼠标事件,圈出图片中需要还原的位置。

















 3068
3068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











