







1. 服务器租用与配置
先上项目链接:
1.1 服务器租用与配置
根据环境要求,去租一个服务器:AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL
我租用的服务器配置如下:

1.2 克隆项目到服务器
打开服务器终端,切换目录
cd autodl-tmp/克隆命令:
git clone https://github.com/hustvl/Vim.git目录结构:

1.3 配置环境
打开服务器终端,按照Vim的环境进行配置:
(1)创建虚拟环境
conda create -n vim python=3.10.13刷新环境变量
conda init bash && source /root/.bashrc(2)安装torch-cuda 11.8
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 -i https://mirrors.aliyun.com/pypi/simple/(3) 安装其他依赖
pip install -r vim/vim_requirements.txt -i https://mirrors.aliyun.com/pypi/simple/(4)安装causal_conv1d 和 mamba,这里选择离线安装
wget https://github.com/Dao-AILab/causal-conv1d/releases/download/v1.1.3.post1/causal_conv1d-1.1.3.post1+cu118torch2.1cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
wget https://github.com/state-spaces/mamba/releases/download/v1.1.1/mamba_ssm-1.1.1+cu118torch2.1cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
安装
pip install causal_conv1d-1.1.3.post1+cu118torch2.1cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
pip install mamba_ssm-1.1.1+cu118torch2.1cxx11abiFALSE-cp310-cp310-linux_x86_64.whl (5)用官方的mamba_ssm 替换虚拟环境 vim 中对应的包
cp -rf mamba-1p1p1/mamba_ssm /root/miniconda3/envs/vim/lib/python3.10/site-packages注:下载慢可以启用加速,见《AutoDL使用手册》-->文件下载
1.4 测试能否运行(Optional)
需要去4.4节中,把datasets.py文件中相应部分进行修改(直接在服务器中修改),否则没有数据集。
CUDA_VISIBLE_DEVICES=0 torchrun --master_port=6666 --nproc_per_node=1 main.py \
--model vim_small_patch16_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2 --batch-size 2 \
--drop-path 0.05 --weight-decay 0.05 --lr 1e-3 --num_workers 1 \
--data-set CIFAR \
--data-path /media/amax/c08a625b-023d-436f-b33e-9652dc1bc7c0/DATA/liyuehang/Vim-main/vim/cifar-100-python \
--output_dir ./output/vim_small_patch16_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2 \
--no_amp 2. 添加distributed软连接
为了能够在本地的pycharm调试Vim的代码,我们需要下载服务器的distributed文件夹,首先给Vim项目添加软连接。
服务器新建一个终端,进入到我们的虚拟环境vim,输入命令
pip show torch查找python 3.10对应的torch的目录,输出如下:

进入到这个目录,然后继续找到distributed目录,进入,在终端输入pwd查看当前路径。

软连接命令:
ln -s /root/miniconda3/envs/vim/lib/python3.10/site-packages/torch/distributed Vim/执行完后,就可以在Vim目录下,看到distributed文件夹:

测试能否使用launch.py运行(Optional):
cd Vim/export CUDA_VISIBLE_DEVICES=0python distributed/launch.py --master_port=6666 --nproc_per_node=1 vim/main.py \
--model vim_small_patch16_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2 --batch-size 2 \
--drop-path 0.05 --weight-decay 0.05 --lr 1e-3 --num_workers 1 \
--data-set CIFAR \
--data-path /media/amax/c08a625b-023d-436f-b33e-9652dc1bc7c0/DATA/liyuehang/Vim-main/vim/cifar-100-python \
--output_dir ./output/vim_small_patch16_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2 \
--no_amp 3. 克隆项目到本地
在本地克隆项目文件
git clone https://github.com/hustvl/Vim.git4. Pycharm配置
用pycharm打开Vim文件夹,按照下面的操作设置python解释器。
4.1 设置远程python解释器
按照图示操作:
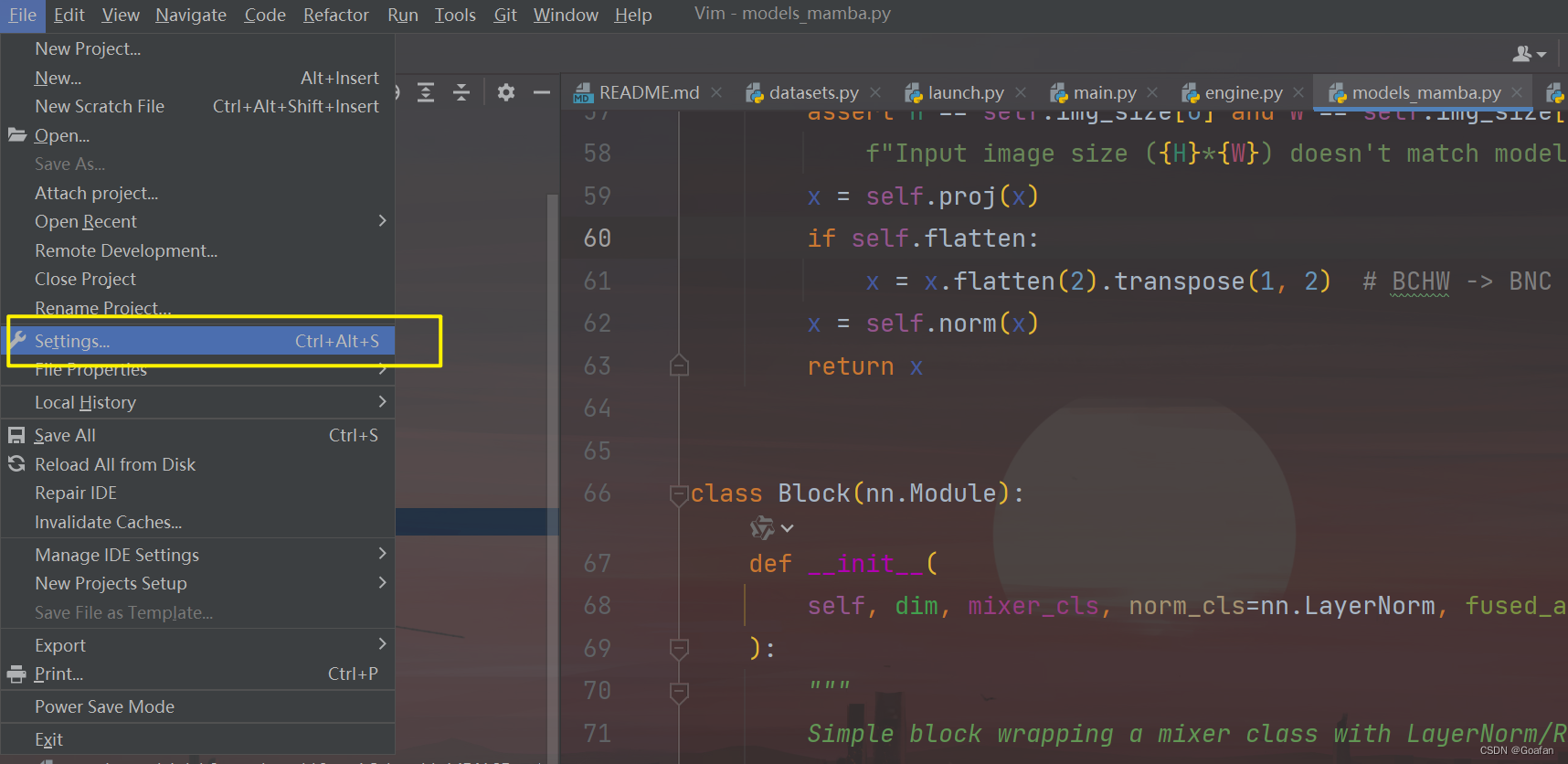


去容器实例,复制ssh指令,输入到pycharm中:
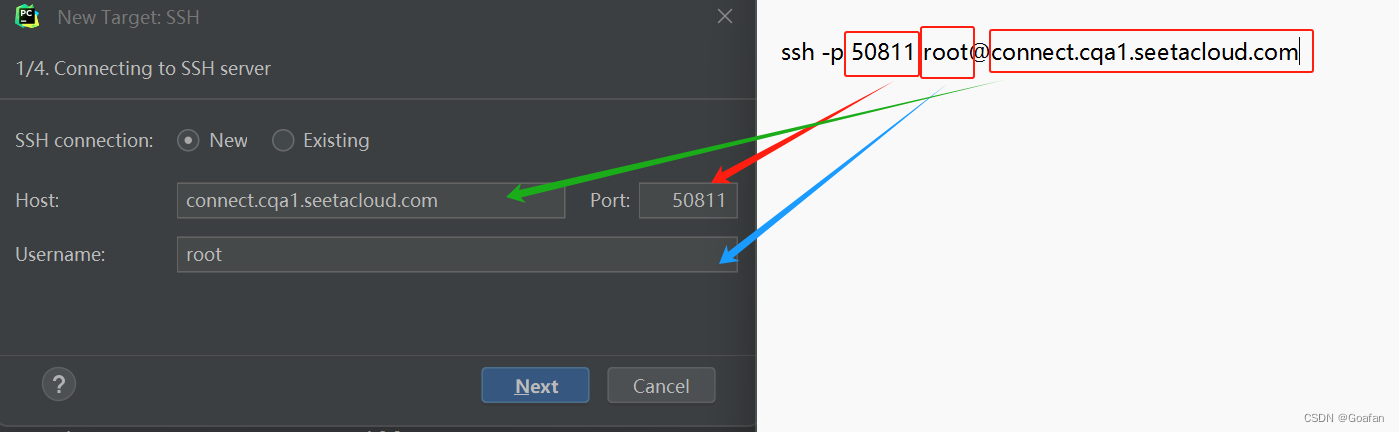
点击Next,会让你输入密码,直接去容器实例复制密码输入,点击Next。
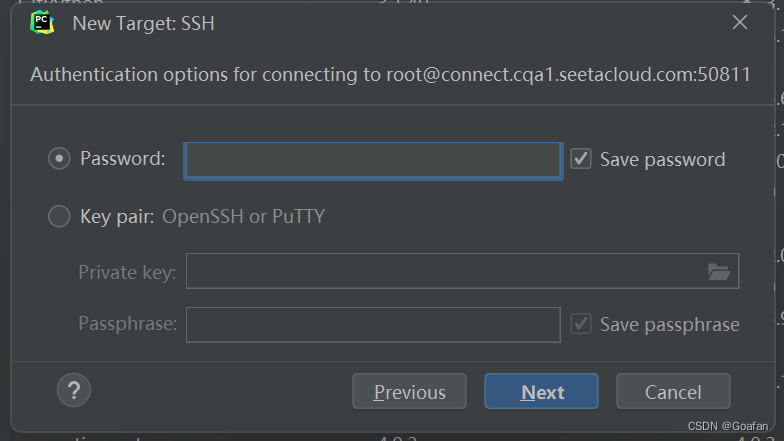
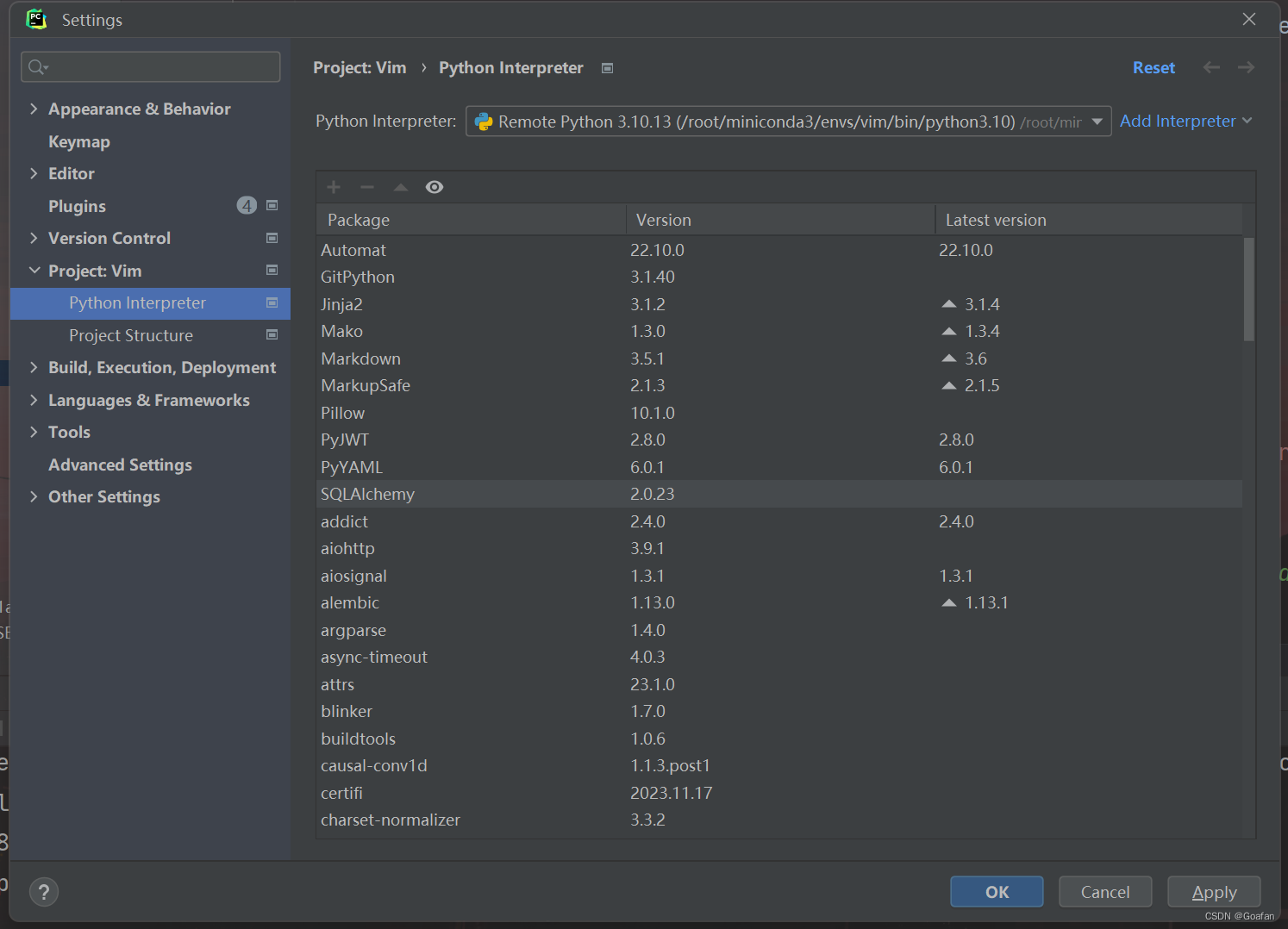
连接到远程后,需要选择服务器上的python解释器路径,点击Existing:

点击最右面的三个点,找到/root/miniconda3/envs/vim/bin/python3.10,点击OK
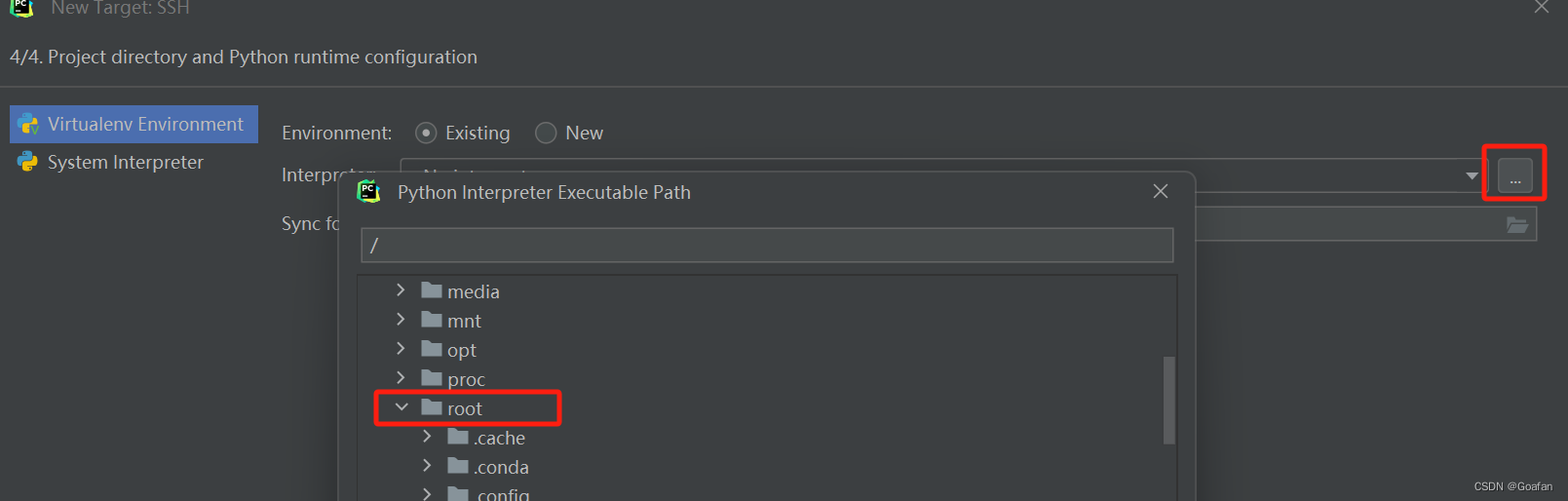
然后我们需要配置本地的工作目录和服务器的工作目录,点击最右侧的文件夹图标:
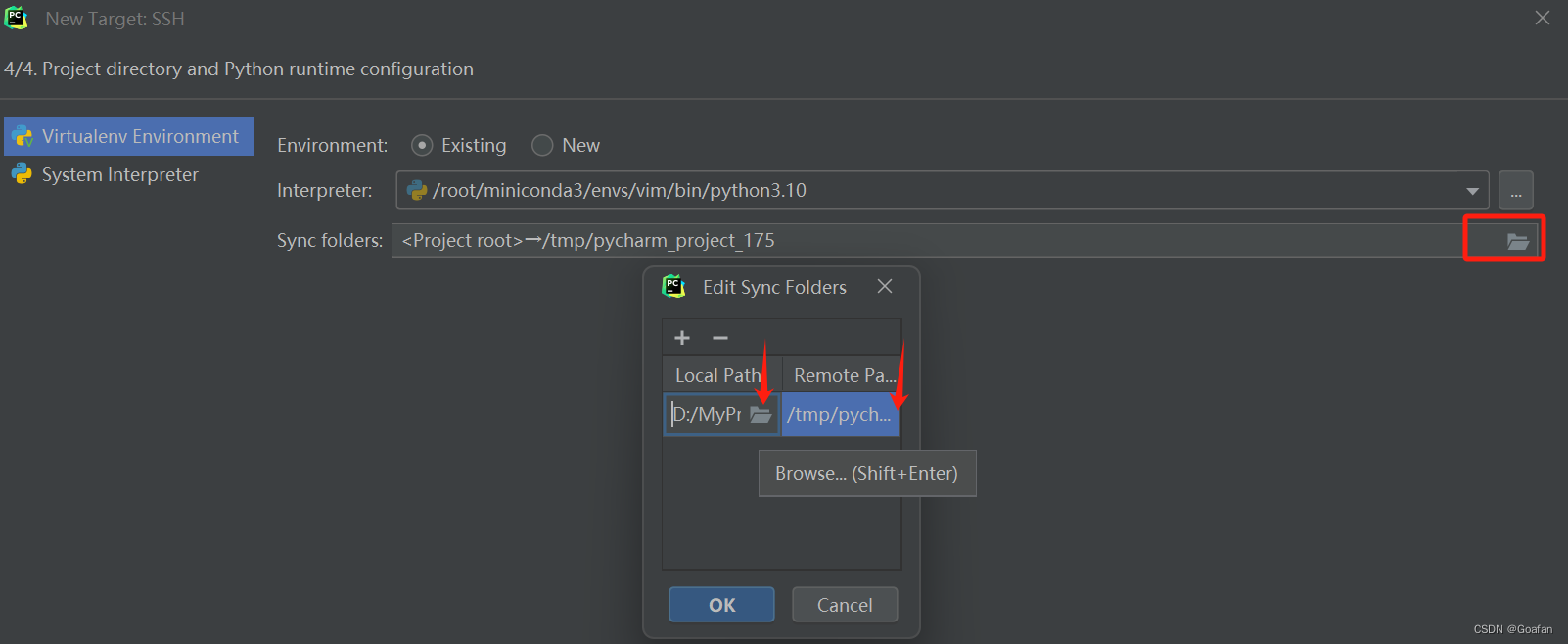
LocalPath我选择的是本地的Vim文件夹,RemotePath选择的是服务器的Vim文件夹:

工作目录设置好后,点击OK,点击Create,就可以看到我们添加的python解释器了:
点击apply , OK 即可。
4.2 目录内容同步
配置好python解释器和工作目录后,我们需要对服务器的Vim文件夹和本地的Vim文件夹的内容进行同步,因为服务器上还添加了distributed文件夹,想要调试需要下载到本地。
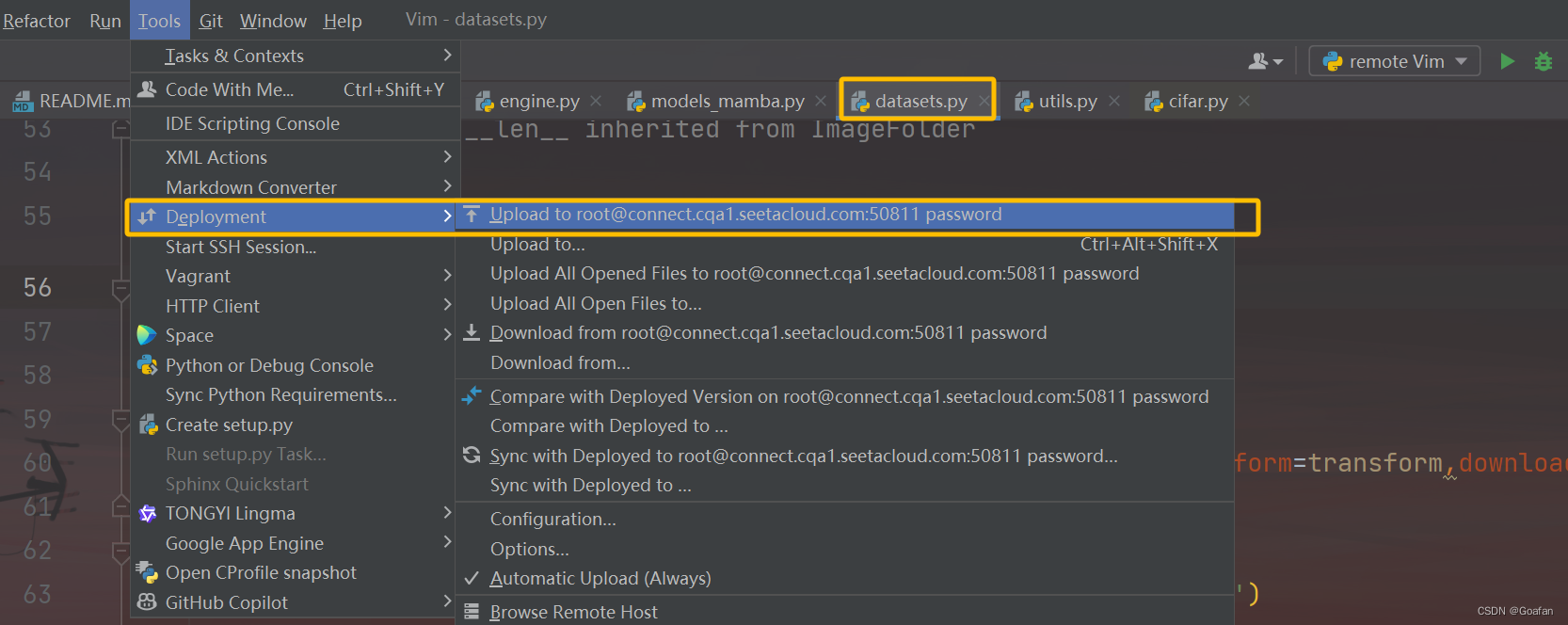
pycharm中选中项目文件夹,点击Tools--DeployMent--Download from root@ ....
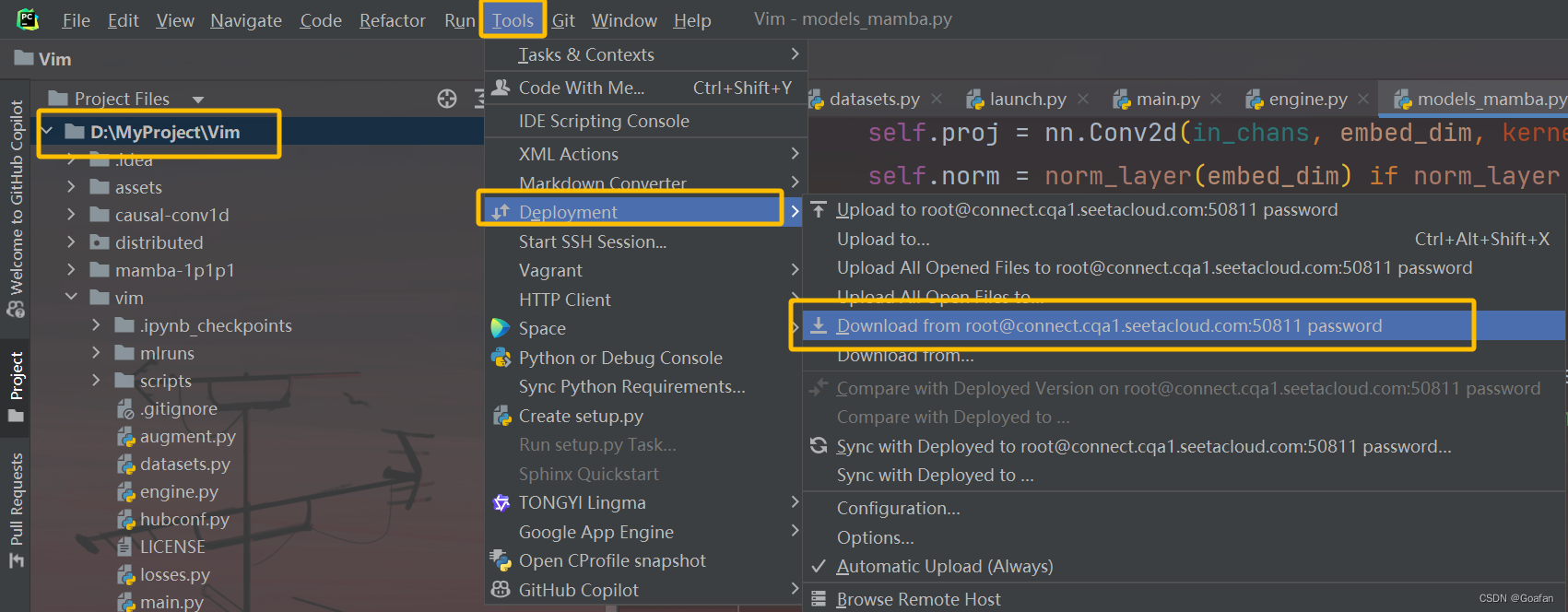
下载完后,Vim文件夹中就会出现distributed文件夹。
4.3 修改pycharm的运行参数
首先是Script path,要修改成Distributed文件夹中的launch.py文件。
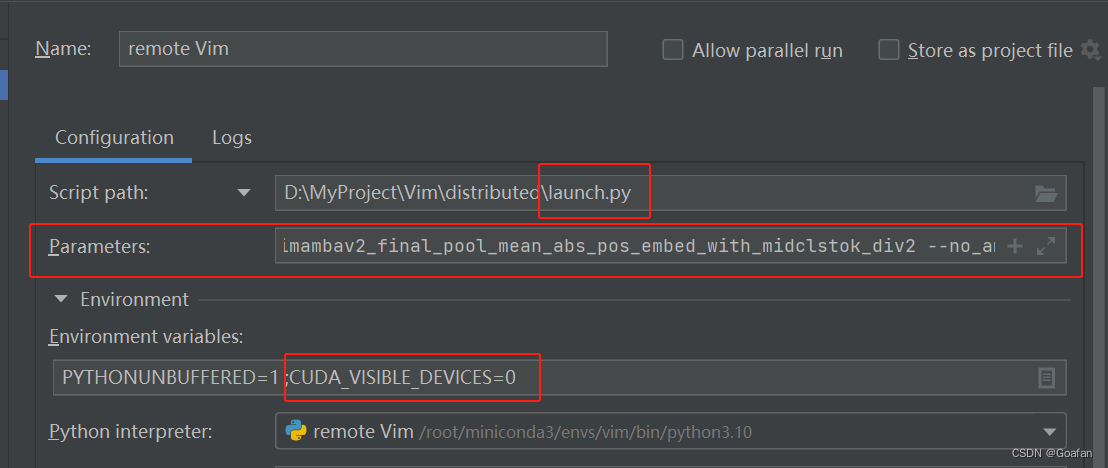
设置环境变量Environment variables
CUDA_VISIBLE_DEVICES=0设置运行参数Parameters,注意main.py是服务器中的绝对目录 。
--master_port=6666
--nproc_per_node=1
/root/autodl-tmp/Vim/vim/main.py
--model
vim_small_patch16_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2
--batch-size
2
--drop-path
0.05
--weight-decay
0.05
--lr
1e-3
--num_workers
1
--data-set
CIFAR
--data-path
/media/amax/c08a625b-023d-436f-b33e-9652dc1bc7c0/DATA/liyuehang/Vim-main/vim/cifar-100-python
--output_dir
./output/vim_small_patch16_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2
--no_amp4.4 设置自动下载CiFar数据集
在pycharm中,找到Vim/vim/datasets.py,在CIFAR100数据集后面加一个download=True
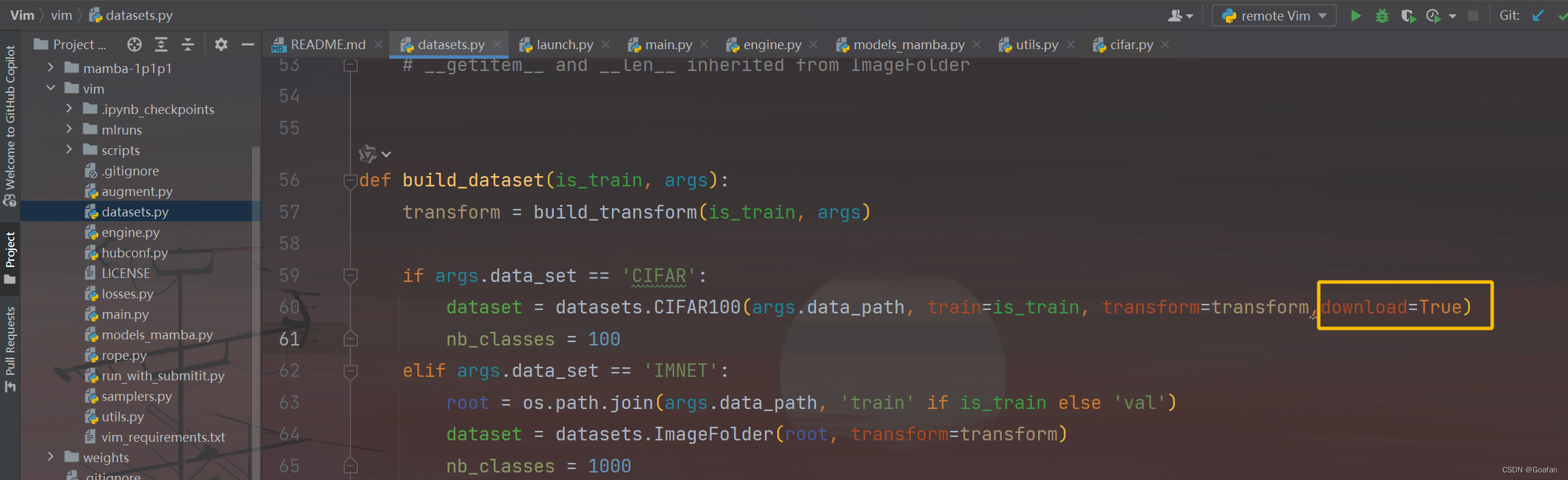
然后选中datasets.py,将修改后的py文件上传到服务器并覆盖。
5. 开始调试
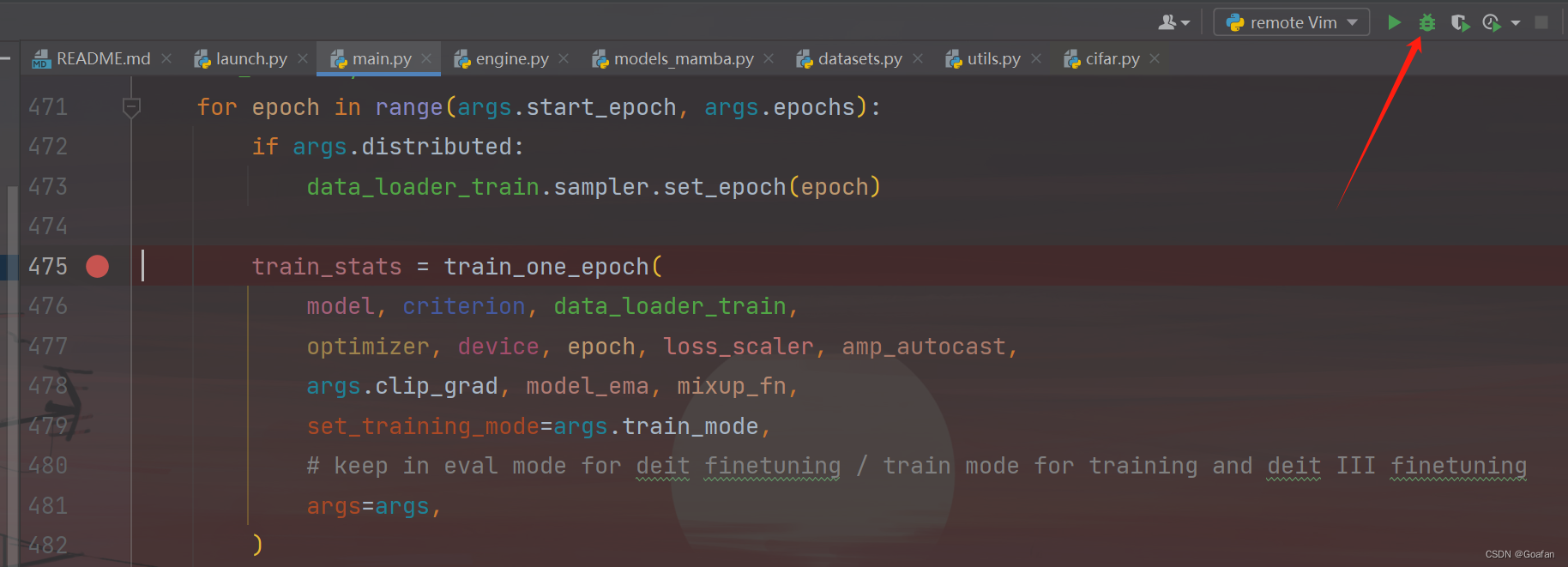
我们可以在main.py打个断点,然后点击debug按钮,看看是否可以跳到断点处:
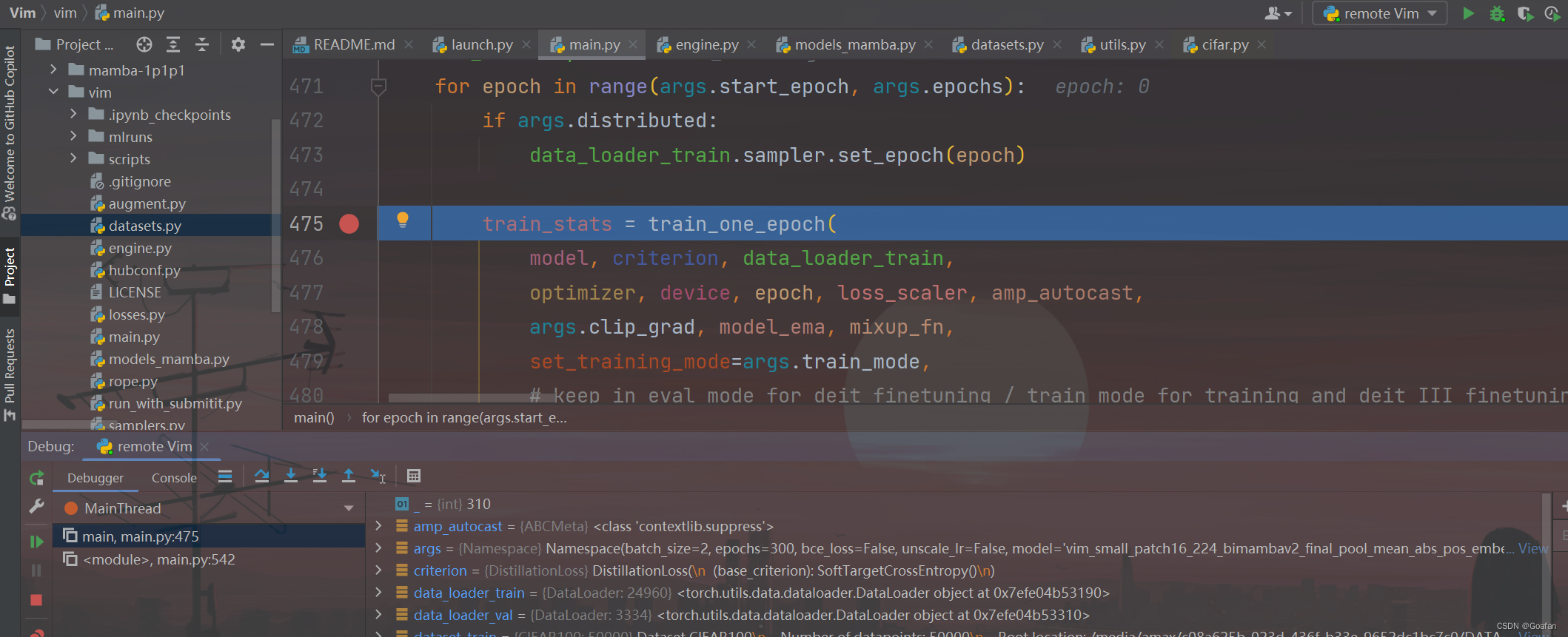
终端输出:

6. 补充调试1
我们调试的时候发现,在 models_mamba.py 的大约134行跳不进去::

但是我们可以看到 self.mixer() 是:
Mamba(
(in_proj): Linear(in_features=384, out_features=1536, bias=False)
(conv1d): Conv1d(768, 768, kernel_size=(4,), stride=(1,), padding=(3,), groups=768)
(act): SiLU()
(x_proj): Linear(in_features=768, out_features=56, bias=False)
(dt_proj): Linear(in_features=24, out_features=768, bias=True)
(conv1d_b): Conv1d(768, 768, kernel_size=(4,), stride=(1,), padding=(3,), groups=768)
(x_proj_b): Linear(in_features=768, out_features=56, bias=False)
(dt_proj_b): Linear(in_features=24, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=384, bias=False)
)因此我们可以去 mamba_sample.py 最后,添加如下代码,然后 debug 运行 mamba_sample.py 即可:
if __name__ == "__main__":
import torch
# 确保CUDA可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 定义输入张量的尺寸
batch_size, seq_length, d_model = 2, 197, 384
# 创建输入张量,并将其发送到CUDA设备
x = torch.randn(batch_size, seq_length, d_model, device=device)
# 实例化 Mamba 模型,确保将其放置在CUDA设备上
# 注意:这里的参数需要根据实际情况进行调整
mamba_model = Mamba(
d_model=d_model,
d_state=16,
d_conv=4,
expand=2,
dt_rank="auto",
dt_min=0.001,
dt_max=0.1,
dt_init="random",
dt_scale=1.0,
dt_init_floor=1e-4,
conv_bias=True,
bias=False,
use_fast_path=True,
layer_idx=None,
device=device,
dtype=torch.float32, # 确保数据类型与设备兼容
bimamba_type="v2",
if_devide_out=False,
init_layer_scale=None,
).to(device)
# 运行前向传播
output = mamba_model(x)
# 打印输出张量的大小
print(output.shape)7. 补充调试2
在调试 mamba_simple.py 文件时,216行函数也无法跳进去:
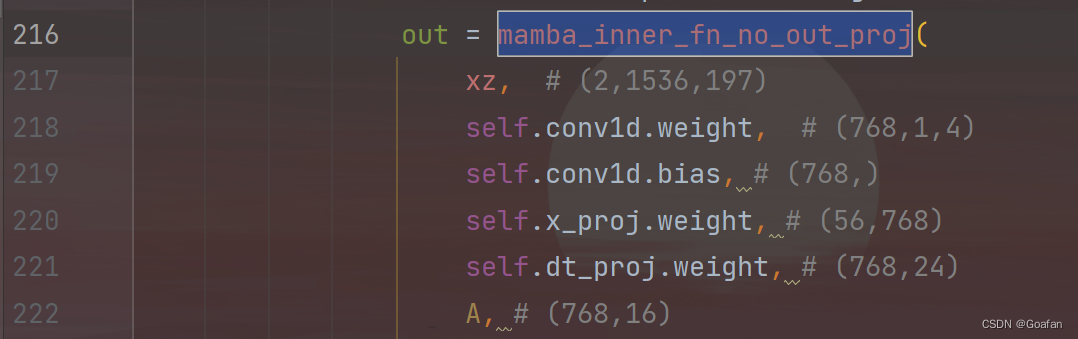
而该函数是在mamba_ssm/ops/selective_scan_interface.py文件中,因此在该文件最后加入代码:然后调试这个文件即可。
if __name__ == "__main__":
import torch
import torch.nn.functional as F
# 指定设备为第一个CUDA设备,如果没有CUDA设备,则回退到CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 创建模拟输入数据和模型参数,并将它们移动到CUDA设备上
xz = torch.randn(2, 1536, 197, device=device) # (batch_size, dim, seq_len)
conv1d_weight = torch.randn(768, 1, 4, device=device) # (out_channels, 1, kernel_size)
conv1d_bias = torch.randn(768, device=device) # (out_channels)
x_proj_weight = torch.randn(56, 768, device=device) # (new_dim, out_channels)
delta_proj_weight = torch.randn(768, 24, device=device) # (out_channels, delta_rank)
A = torch.randn(768, 24, device=device) # (out_channels, delta_rank)
# 创建模型参数,这些通常在实际应用中由模型定义
class FakeModel:
def __init__(self):
self.conv1d = torch.nn.Conv1d(1, 768, kernel_size=4, bias=True).to(device)
self.x_proj = torch.nn.Linear(768, 56).to(device)
self.dt_proj = torch.nn.Linear(56, 768).to(device)
# 初始化模型,并将模型参数移动到CUDA设备上
model = FakeModel()
model.conv1d.weight = torch.nn.Parameter(conv1d_weight)
model.conv1d.bias = torch.nn.Parameter(conv1d_bias)
model.x_proj.weight = torch.nn.Parameter(x_proj_weight)
model.dt_proj.weight = torch.nn.Parameter(delta_proj_weight)
# 测试mamba_inner_fn_no_out_proj函数
out = mamba_inner_fn_no_out_proj(
xz,
model.conv1d.weight, # (768,1,4)
model.conv1d.bias, # (768,)
model.x_proj.weight, # (56,768)
model.dt_proj.weight, # (768,24)
A, # (768,16)
None, # input-dependent B
None, # input-dependent C
model.dt_proj.bias.float().to(device), # (768)
delta_bias=model.dt_proj.bias.float().to(device), # (768)
delta_softplus=True,
)
# 打印输出结果的形状以验证
print("Output shape:", out.shape)8. 补充调试3
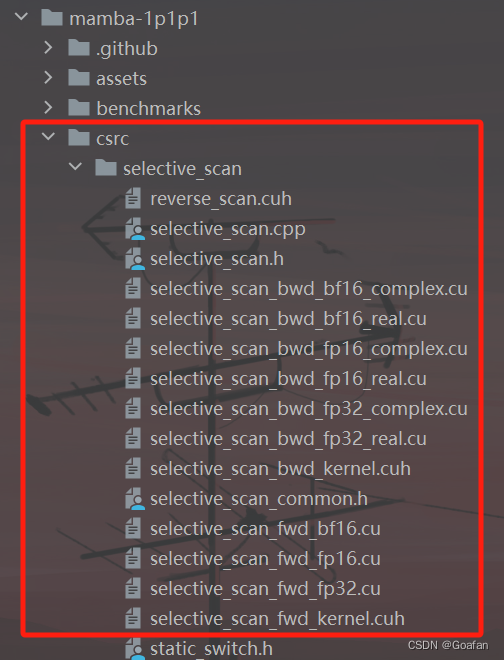
selective_scan_interface.py 文件的第213行的函数无法跳进去调试,暂无解决方案

相关代码应该在 csrc 文件夹中:
视频教程
跳转![]() https://www.bilibili.com/video/BV1vU411o7BT/?vd_source=ed3b3fce9a933b6e4d353c21df8a929d
https://www.bilibili.com/video/BV1vU411o7BT/?vd_source=ed3b3fce9a933b6e4d353c21df8a929d
参考
《vision mamba 运行训练记录,解决bimamba_type错误》

















 9282
9282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











