









—0438今天早上要先花一些时间看zetero怎么使用。
感觉暂时还用不到,先读文叭!!!
文献阅读工具与标记
黄色用来标注想要引用的内容(添加标签文献综述或数据)
蓝色标注作者主要思想与行为逻辑
绿色标注可以借鉴学习的句型和词汇
红色标注自己感兴趣的内容

无监督学习太妙了
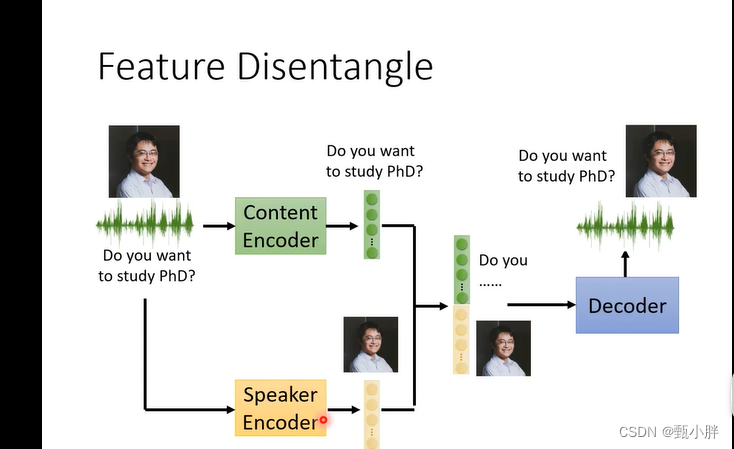
0631呜呜人类语言处理真的太妙了!!正式开始看论文!!!早上学了半天如何使用工具。
NER-BIO tagging schema

Open-CyKG
这篇真的可以,连超参数都写上了,不知道有没有源码,感觉可以复现。
天呐爱了呀,作者居然是个小姐姐,果断follow。
https://github.com/IS5882/Open-CyKG
2-不重要-已读
0-重要、需精读
1-重要、已读完
芜湖在群里分享以后,老师让复现,还好今天事情不多,争取今天把代码跑通。
一遍跑代码一遍刷题呜呜呜
799 最长不重复子序列
双指针核心思想是把n方的复杂度通过某种单调性降为2n。
具体模板为,外层一般作为end循环,里层满足作为起始,满足某种条件会往后走,直到不满足,然后做一些与题目相关的操作。
这道题另一点是判断重复不重复。由于这里数据范围较小,我们可以开一个数组记录窗口内数字出现的次数,每次可能重复的只有i,当S[a[i]]大于1了,就重复了,此时只能通过调整j来保证不重复。
嗯没找到数据,成功跑不通,去做题了。
还好做题比较顺,要不然心态非得崩塌了,不知为何,今天好慌。
n = int(input())
a = list(map(int,input().split()))
j = 0
res = 0
S = [0]*100010
for i in range(n):
S[a[i]]+=1
while j<n and S[a[i]]>1:
S[a[j]]-=1
j += 1
res = max(res,i-j+1)
print(res)
796 二维前缀和
鹅鹅鹅直接写叭,虽然这道题仍旧很丝滑,但想到下一道可能是kmp,就有点瑟瑟发抖。
n,m,q = map(int,input().split())
a = [[0]*(m+2) for _ in range(n+2)]
for i in range(1,n+1):
a[i][1:] = list(map(int,input().split()))
for i in range(1,1+n):
for j in range(1,1+m):
a[i][j] += a[i-1][j]+a[i][j-1]-a[i-1][j-1]
for _ in range(q):
x1,y1,x2,y2 = map(int,input().split())
print(a[x2][y2]-a[x1-1][y2]-a[x2][y1-1]+a[x1-1][y1-1])
800数组元素的目标和
主要先用暴力,后发现序列是单调的。当i保持一定时,若两者和大于目标值,j就一定要往前移动。i再向前移动时,值变大,此时j也只能往前移动。如此j为单调前移;i为单调后移。
n,m,x = map(int,input().split())
a = list(map(int,input().split()))
b = list(map(int,input().split()))
j = m-1
for i in range(n):
while a[i]+b[j]>x:
j -= 1
if a[i]+b[j]==x:
break
print(i,j)
整理了师兄的语录,又被安排了其他事情。。。真的是快速成长阶段。
不知道为什么,心很慌
做起来就好了一步一步的
max_len过大nlp会有影响吗
据说不会有诶
关于mask的细节
用序列模型的时候会用mask,就是mask的大小决定了你最后用哪个hidden state代表这个序列。
具体可以看看torch.nn.utils.rnn.pack_padded_sequence。
当然mask在不同地方有不同含义hh
呜呜呜要给小导师写计划了~















 1009
1009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









