






word2vec和RNN
对图像而言图像本身即是数据,可以被深度学习模型直接用来提取特征,但是自然语言需要将语言比如汉字或单词转换成数据,进而才能被深度学习模型提取特种。为了解决这一问题word2vec被提出,在BERT之前,NLP领域一直使用word2vec将语言转换成词向量,然后再进行一系列的操作。
RNN即循环神经网络,NLP问题是一个序列模型。
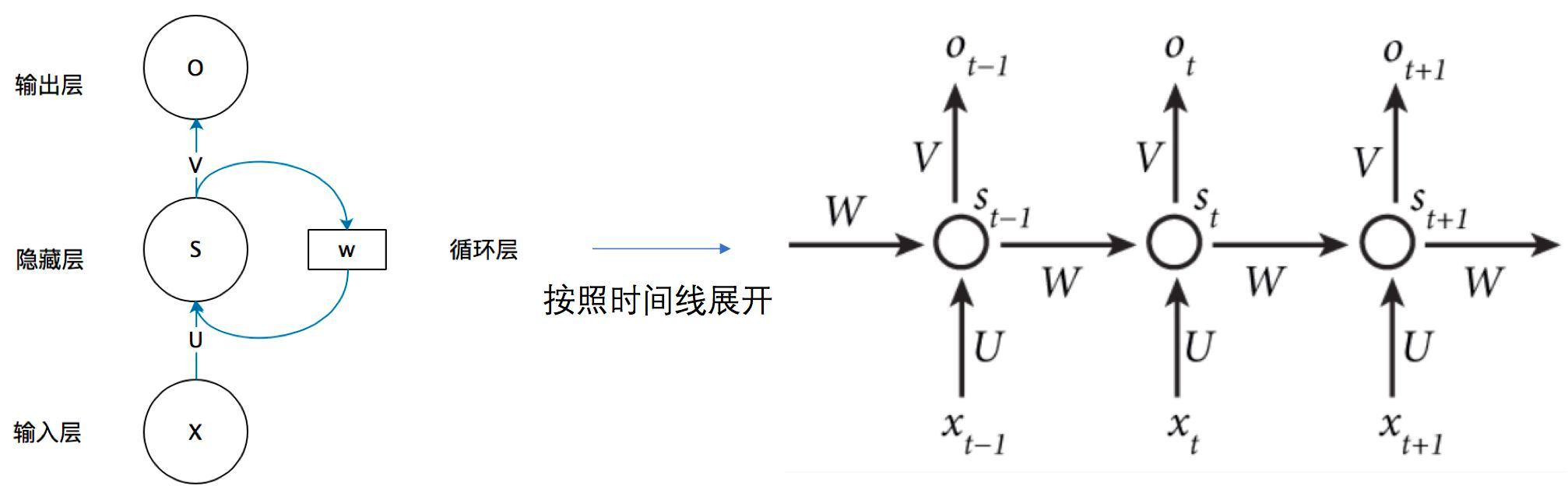
Transformer
来自于谷歌的论文attention is all you need(2016年),可以简单的理解为一种特征提取器。transformer解决了RNN难以捕获长期依赖关系的缺点。
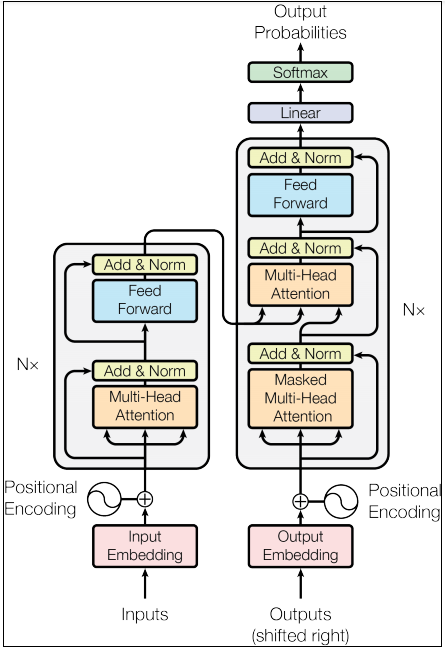
BERT
BERT:Bidirectional Encoder Representations from Transformers
来自于谷歌的论文BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(2018),可以简单的理解成使用transformer对单词,文字进行编码,将语言表示为向量。
1.Mask LM(MLM):Masked language model
随机将15%的词隐藏,让模型去做"填空题",比如:我经常(晚上)跑步,我经常晚上(跑步),让括号内的词隐藏起来,让模型预测。
2.双向语言模型Bidirectional
我经常(晚上)跑步,我经常晚上(跑步)
3.预训练+微调的模式
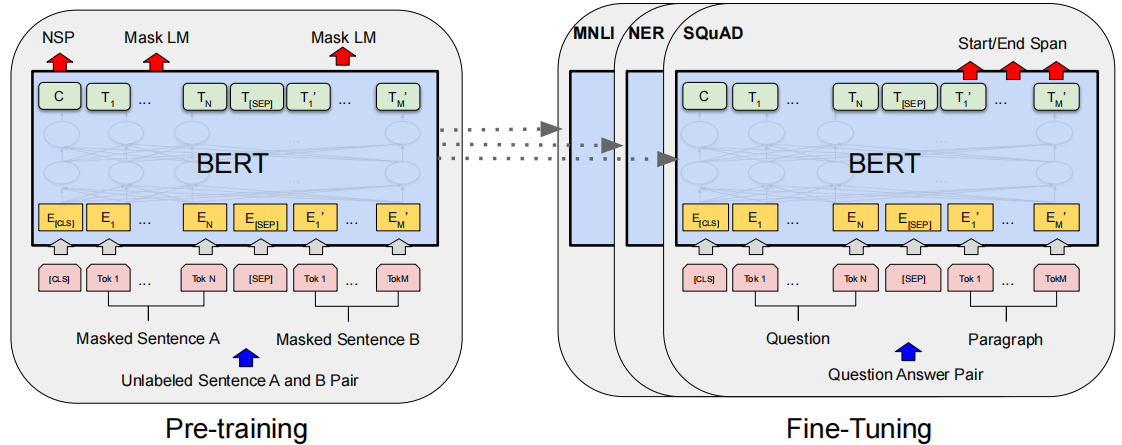
预训练阶段的数据不需要进行人工标注,属于无监督的预训练
微调阶段是有监督的微调,即需要提供人工标注的数据集
上图中的MNLI、NER和SQuAD是NLP中的不同的下游任务
- MNLI 是 Multi-Genre Natural Language Inference 的缩写,它是一个自然语言推理数据集。该数据集包含了大量的文本对,旨在评估模型在理解自然语言文本之间的逻辑关系方面的能力。
- NER 是 Named Entity Recognition 的缩写,意为命名实体识别。它是自然语言处理中的一个任务,旨在从文本中识别出命名实体,如人名、地名、组织机构名等。
- SQuAD 是 Stanford Question Answering Dataset 的缩写,它是一个大规模的阅读理解数据集。该数据集包含了大量的问题和答案对,旨在评估模型在阅读理解方面的能力。
GPT1
来自于openai的论文Improving Language Understanding by Generative Pre-Training(2018)。
GPT(Generative Pre-Training),是NLP生成式的预训练模型,如下图所示,该模型分为2个阶段:
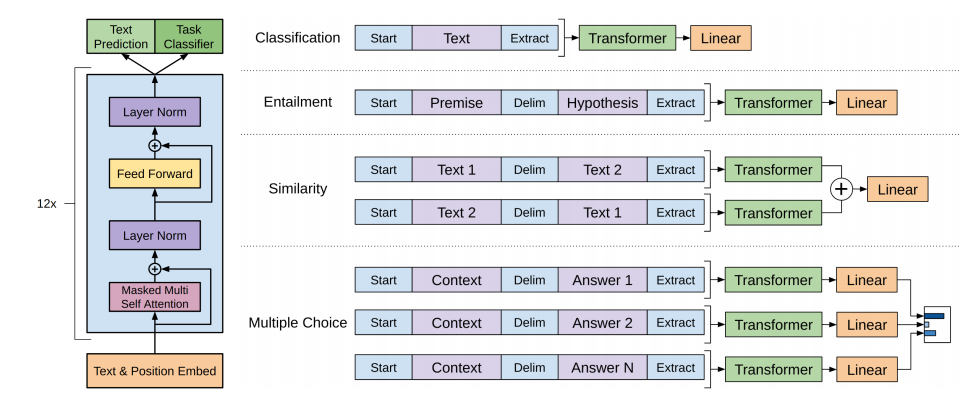
1.预训练阶段
上图中的左边是基于transformer的预训练模型。预训练阶段的数据不需要进行人工标注,属于无监督的预训练
2.微调阶段
上图中的右边是将不同的下游任务数据通过预训练模型转换成词向量,然后再使用线性层+softmax对其进行分类或预测,这里是有监督的微调,即需要提供人工标注的数据集
Classification:文本分类任务
Entailment:在自然语言处理中,Entailment 常用来描述文本之间的逻辑关系
Similarity:在自然语言处理中,Similarity指的是两个文本之间的相似度。它常用于搜索引擎排名结果或向读者推荐类似内容等实际应用
Multiple Choice:在自然语言处理中,Multiple Choice是一种常见的问答任务。它需要模型在给定问题和可选上下文的情况下,从一组选项中做出决策。
GPT与BERT的区别
GPT和BERT的区别如下图所示,BERT是一个双向的语言模型,而GPT是一个单向的语言模型,比如,我经常(晚上)跑步,我经常晚上(跑步)
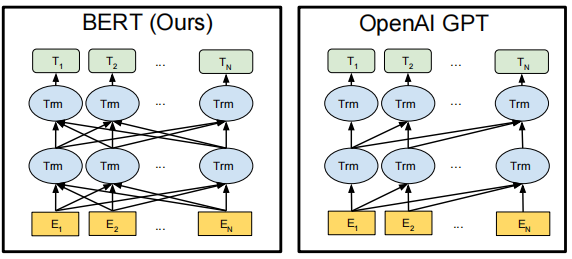
BERT是bidirectional Transformer,而GPT是left-to-right Transformer。
GPT2
来自于openai的论文Language Models are Unsupervised Multitask Learners(2019)
改进点:
1.相比于GPT1,在已有的网络结构设计上使用了更大的网络和更多的数据
2.GPT1在微调阶段使用的是有监督的训练,而GPT2去掉了微调阶段,只是保留了预训练阶段,大胆的构想了一种可能,仅通过大数据和大模型的训练完成所有NLP任务,方法是在训练和预测过程中一次只是预测一个单词,以实现zero-shot learning的语言模型。想法非常大胆,但是效果一般。
GPT3
来自openai的论文Language Models are Few-Shot Learners(2020)
改进点:
1.通过GPT2 openai证明了训练一个通用的NLP模型的可行性,即只是训练一个预训练模型,而不进行微调即可以完成所有NLP的下游任务。因此GPT3在没有改变网络结构的基础上再次加大了模型的参数和数据量。
2.吸取GPT2 zero-shot learning效果一般的教训,分别测试了zero-shot learning和one-shot learning和few-shot learning,最终效果few-shot learning>one-shot learning>zero-shot learning
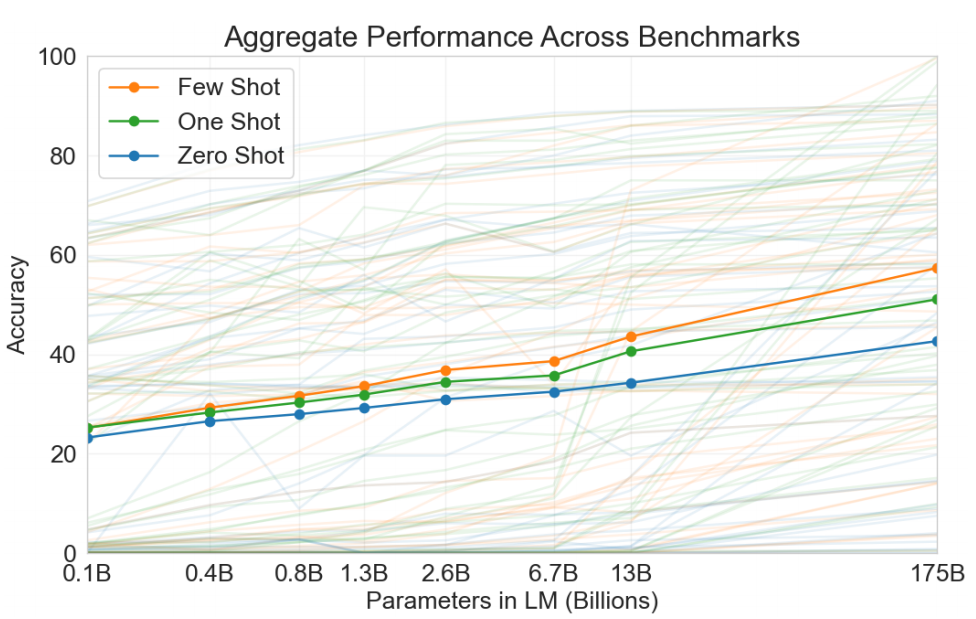
InstructGPT
来自openai的论文Training language models to follow instructions with human feedback(2022)
指示学习(Instruct Learning)
改进点:
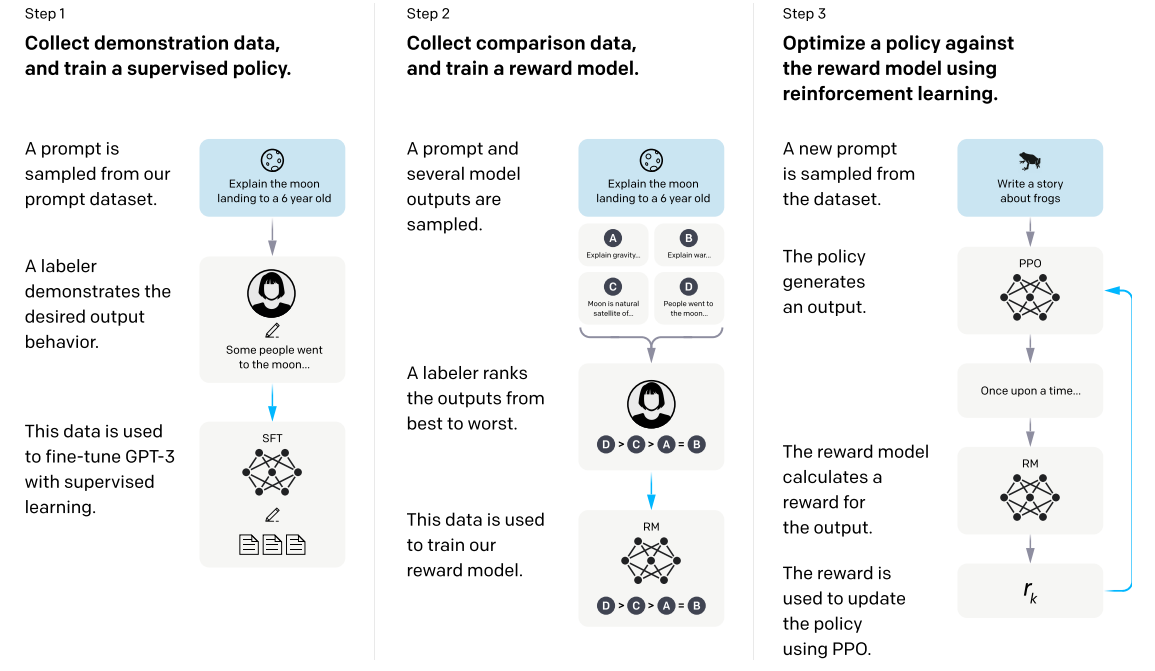
作为研究而言,GPT3已经足够惊艳了,但是GPT3的输出会带有偏见以及输出一些负面的消息,因此openai想将GPT3进行一些调整以使其输出符合人类的期望,即输出一些人们喜欢的回答。方式如下:
1.利用人类的标注数据去对GPT3进行监督训练,生成一个SFT(Supervised fine-tuning)模型
2.用SFT模型再次预测第一步中的数据集,并输出4个结果,让标注人员给这4个结果由好至坏排序,然后将这些数据通过RLHF思路训练奖励模型RM
3.用SFT模型再次预测一次数据集的结果,然后使用RM模型给结果打分,最后将这个奖励分数通过PPO给到SFT模型
ChatGPT
没有发文章
GPT总结
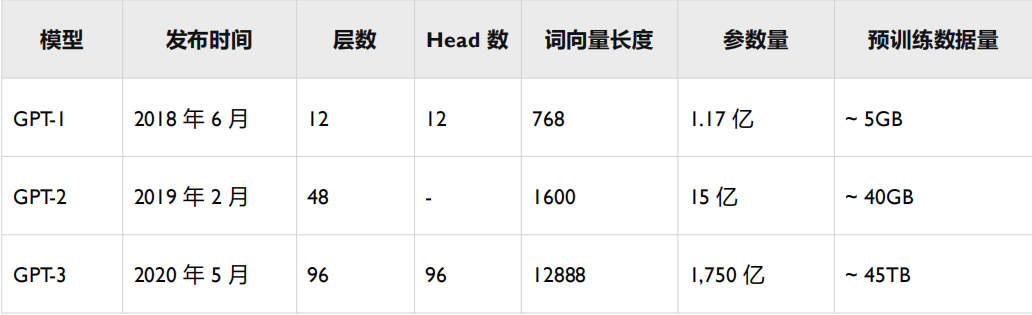
GPT都是采用以transformer为核心结构的模型,不同的是模型的层数和词向量长度















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









