






一、模型融合:与集成算法一样,都是训练多个评估器,并将多个评估器以某种方式结合起来解决问题的机器学习办法。但是区别是模型融合能够再经典集成模型的基础上进一步提升分数,使用模型融合ji融合:与集成算法一样,都是训练多个评估器,并将多个评估器以某种方式结合起来解决问题的机器学习办法。但是区别是模型融合能够再经典集成模型的基础上进一步提升分数,使用模型融合









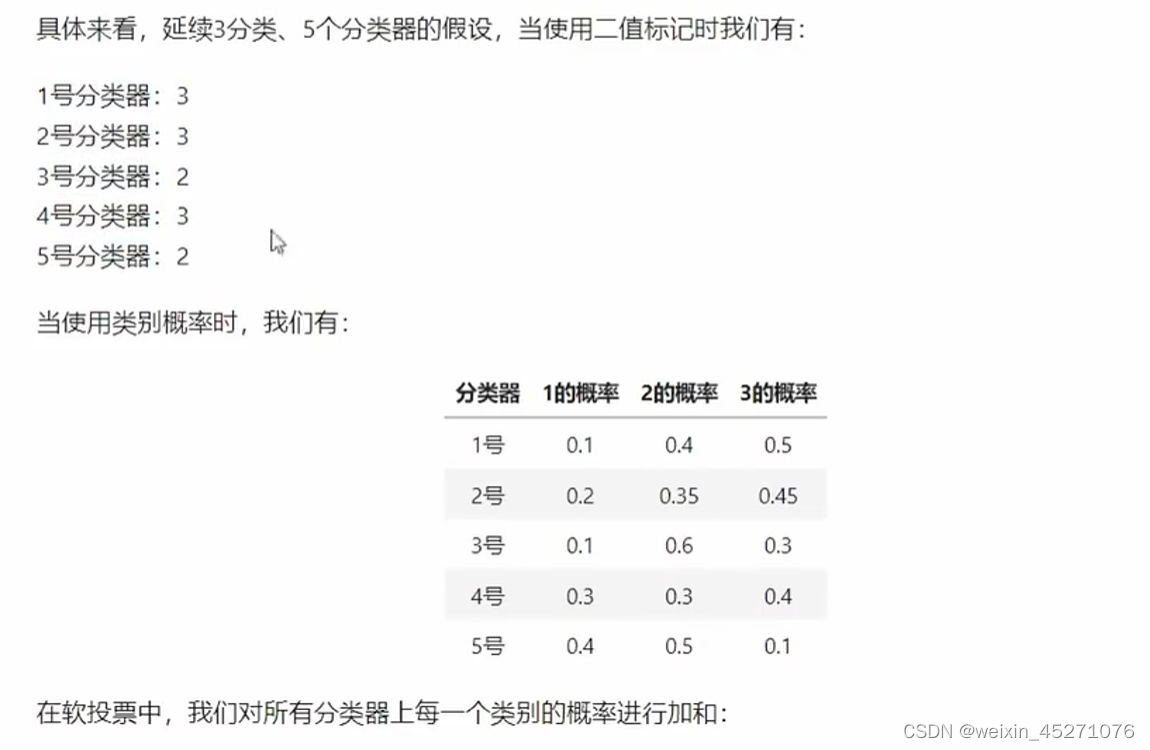
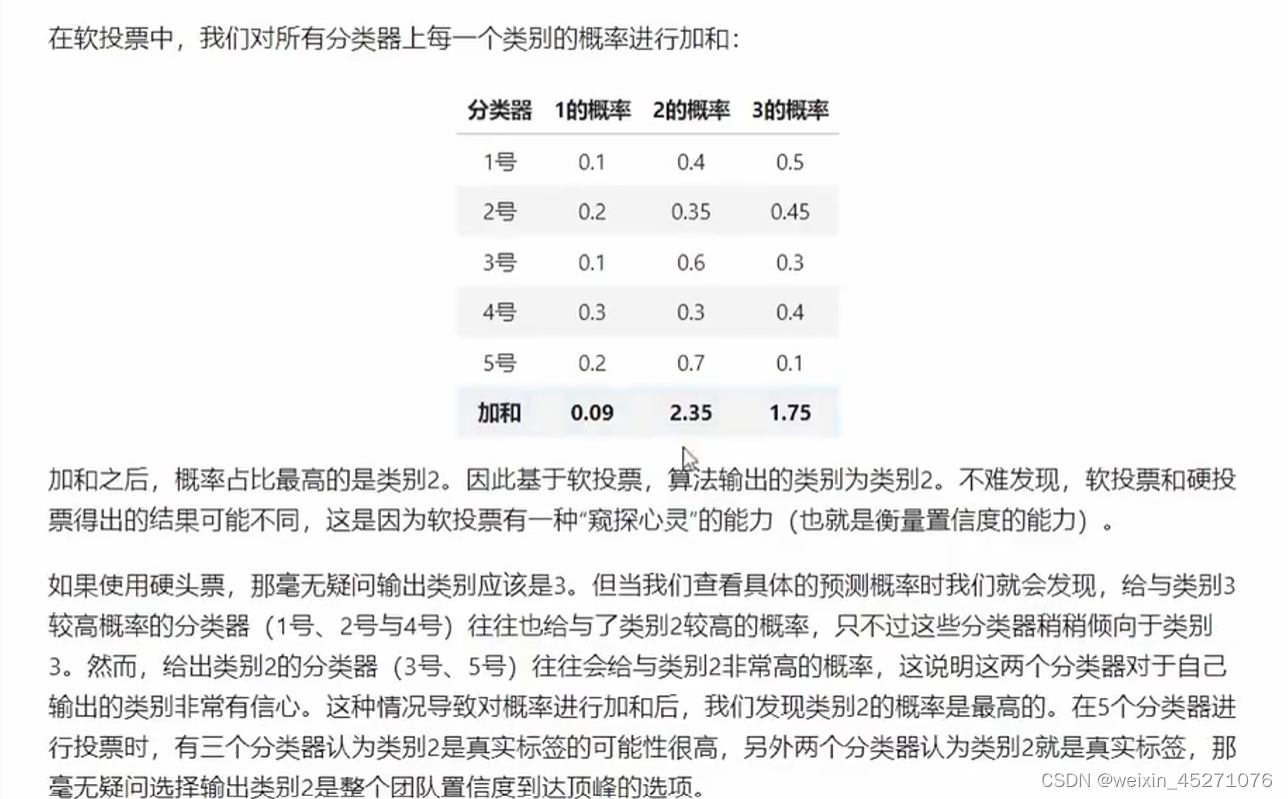
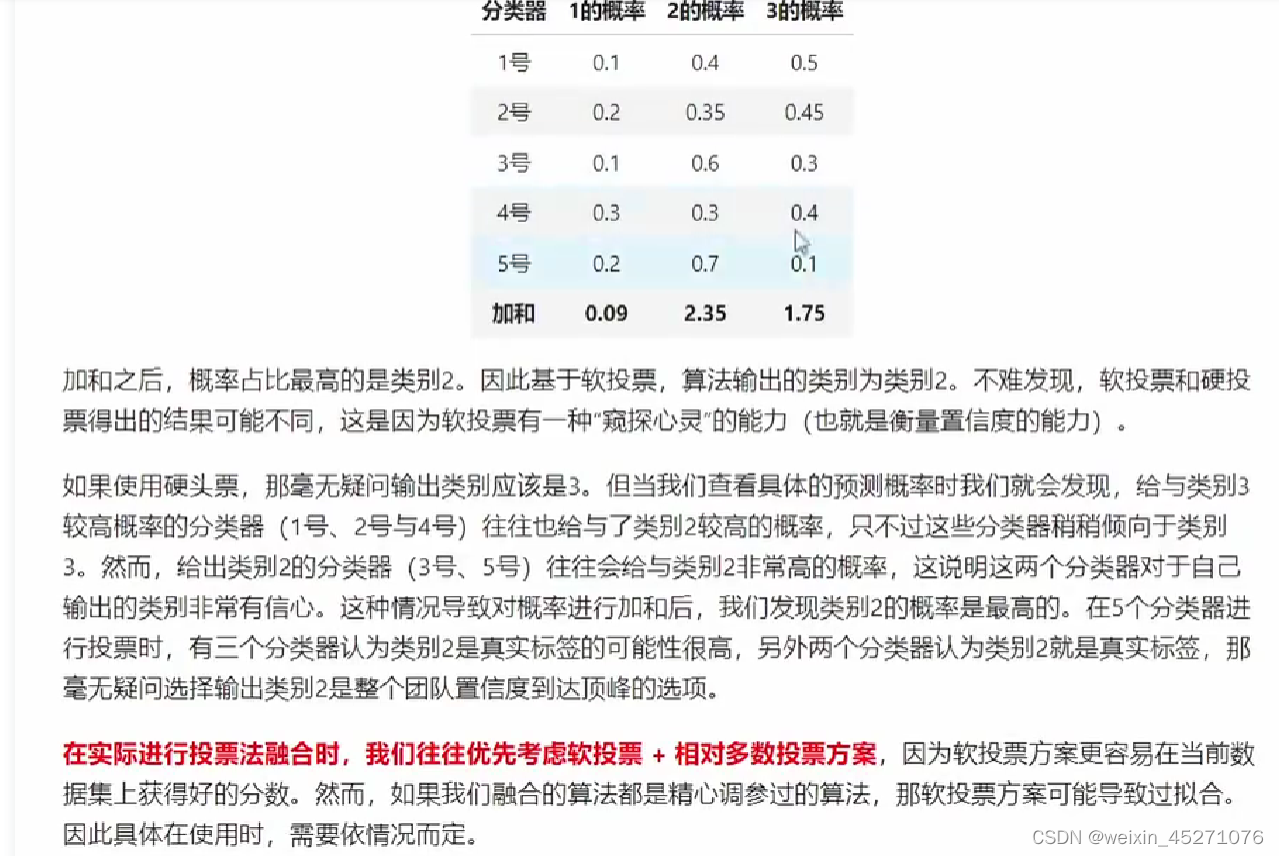
软投票前提是要求模型能够输出概率。


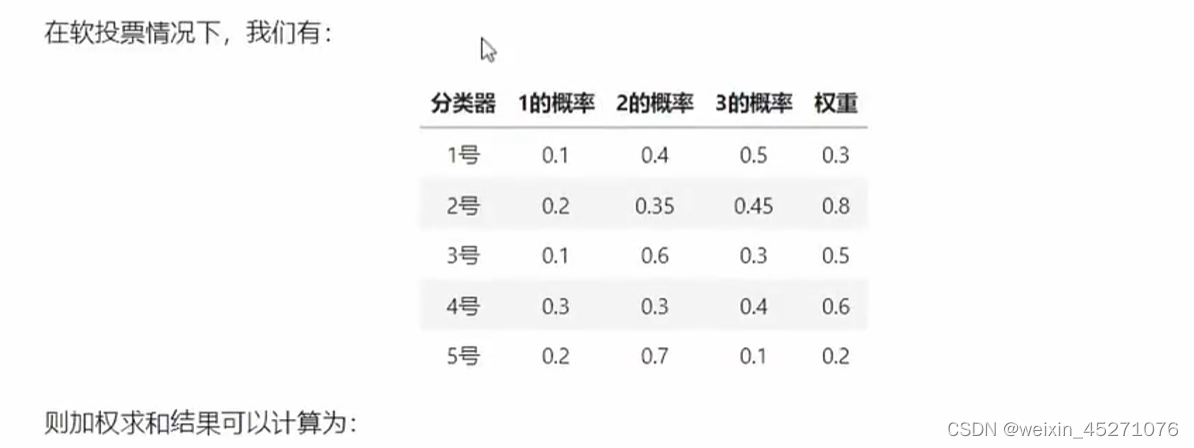
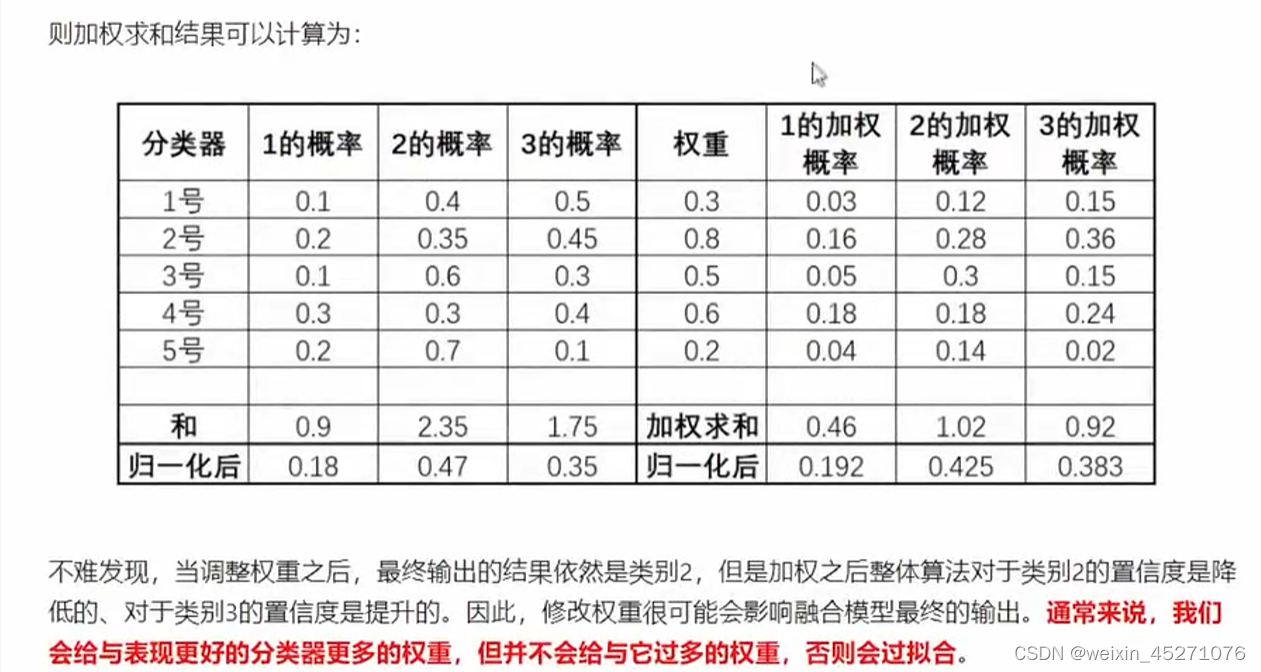


模型融合要求对算法非常熟悉
from sklearn.neighbors import KNeighborsClassifier as KNNC
from sklearn.neighbors import KNeighborsRegressor as KNNR
from sklearn.tree import DecisionTreeRegressor as DTR
from sklearn.tree import DecisionTreeClassifier as DTC
from sklearn.linear_model import LinearRegression as LR
from sklearn.linear_model import LogisticRegression as LogiR
from sklearn.ensemble import RandomForestRegressor as RFR
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.ensemble import GradientBoostingRegressor as GBR
from sklearn.ensemble import GradientBoostingClassifier as GBC
from sklearn.naive_bayes import GaussianNB
#import xgboost as xgb
#融合模型
from sklearn.ensemble import VotingClassifier
from sklearn.ensemble import VotingRegressor
data=load_digits()
X=data.data
y=data.target
Xtrain,Xtest,ytrain,ytest=train_test_split(X,y,test_size=0.2,random_state=1214)
#定义交叉验证所需要的函数,对模型融合中每个评估器做交叉验证,对单一评估器的表现进行评估
def individual_estimators(estimators):
for estimator in estimators:
cv=KFold(n_splits=5,shuffle=True,random_state=1214)
results=cross_validate(estimator[1],Xtrain,ytrain
,cv=cv
,scoring="accuracy"
,n_jobs=-1
,return_train_score=True
,verbose=False
)
test=estimator[1].fit(Xtrain,ytrain).score(Xtest,ytest)
print(estimator[0],"\n train_score:{}".format(results["train_score"].mean())
,"\n cv_mean:{}".format(results["test_score"].mean())
,"\n test_score:{}".format(test)
,"\n"
)
'''
返回:
scores:形状浮点数组的字典 (n_splits,)
每次交叉验证运行的估计器分数数组。
返回包含每个记分器的分数/时间数组的数组字典。此 dict 的可能键是:
test_score
每个 cv 拆分的测试分数的分数数组。如果评分参数中有多个评分指标,则 test_score 中的后缀 _score 更改为特定指标,例如 test_r2 或 test_auc。
train_score
每个 cv 拆分的火车分数的分数数组。如果评分参数中有多个评分指标,则 train_score 中的后缀 _score 更改为特定指标,例如 train_r2 或 train_auc。这仅在 return_train_score 参数为 True 时可用。
fit_time
为每个 cv 拆分在训练集上拟合估计器的时间。
score_time
为每个 cv 拆分在测试集上对估计器进行评分的时间。 (注意即使 return_train_score 设置为 True,也不包括在训练集上评分的时间
estimator
每个 cv 拆分的估计器对象。这仅在 return_estimator 参数设置为 True 时可用。
'''
#对融合模型做交叉验证,对融合模型的表现进行评估
def fusion_estimators(clf):
cv=KFold(n_splits=5,shuffle=True,random_state=1214)
results=cross_validate(clf,Xtrain,ytrain
,cv=cv
,scoring="accuracy"
,n_jobs=-1
,return_train_score=True
,verbose=False
)
test=clf.fit(Xtrain,ytrain).score(Xtest,ytest)#测试集上的结果
print(" train_score:{}".format(results["train_score"].mean())#再训练集上的结果
,"\n cv_mean:{}".format(results["test_score"].mean())#再五折交叉验证上的结果
,"\n test_score:{}".format(test)#再测试集上的结果
,"\n"
)
#在Python中,换行符"\n"是一个特殊的字符,用于在字符串中插入一个换行
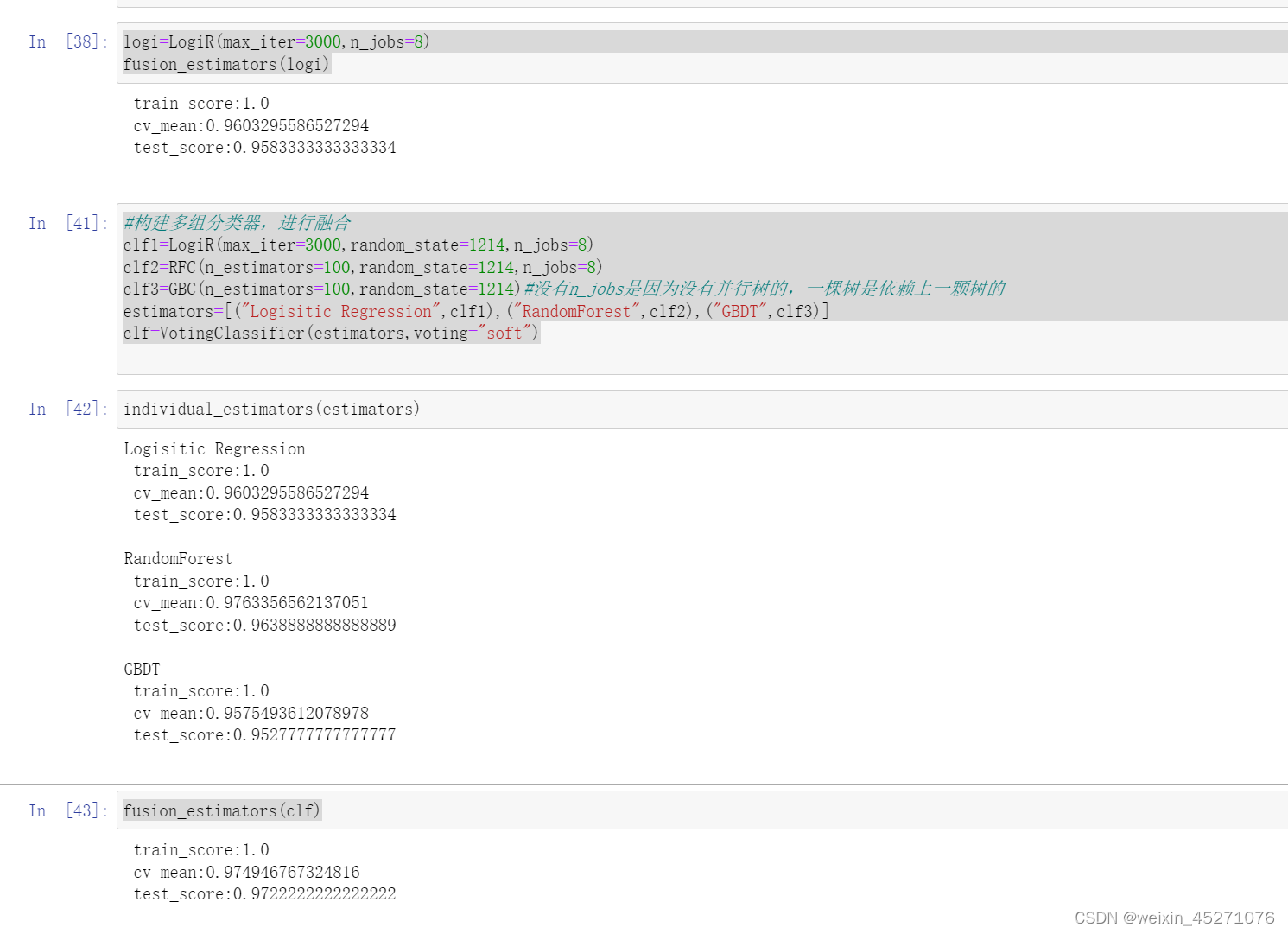
logi=LogiR(max_iter=3000,n_jobs=8)
fusion_estimators(logi)
#构建多组分类器,进行融合
clf1=LogiR(max_iter=3000,random_state=1214,n_jobs=8)
clf2=RFC(n_estimators=100,random_state=1214,n_jobs=8)
clf3=GBC(n_estimators=100,random_state=1214)#没有n_jobs是因为没有并行树的,一棵树是依赖上一颗树的
estimators=[("Logisitic Regression",clf1),("RandomForest",clf2),("GBDT",clf3)]
clf=VotingClassifier(estimators,voting="soft")
fusion_estimators(clf)














 5464
5464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









