






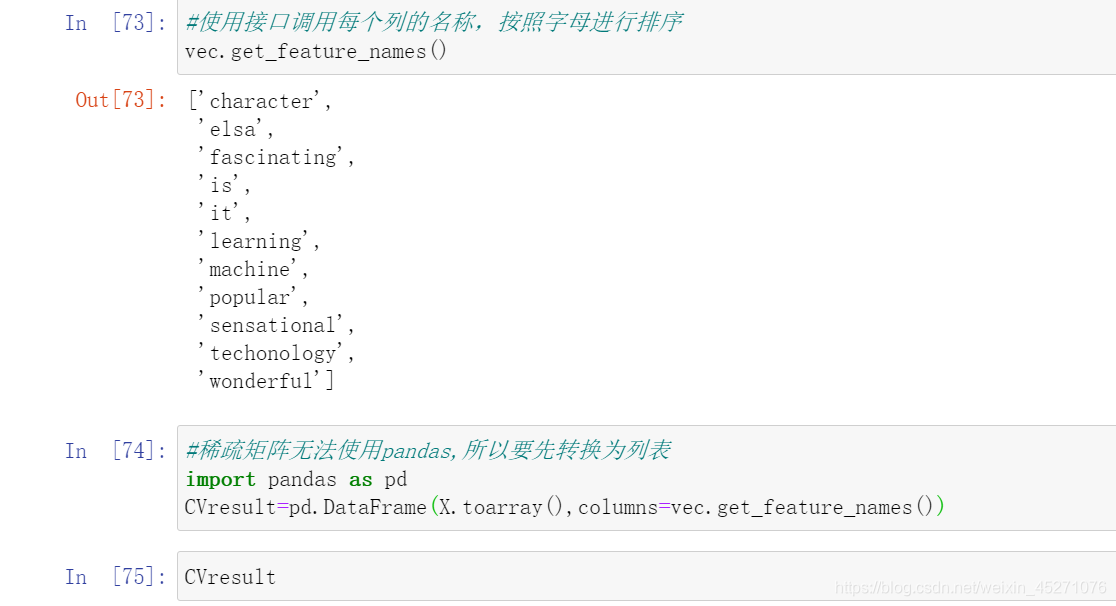
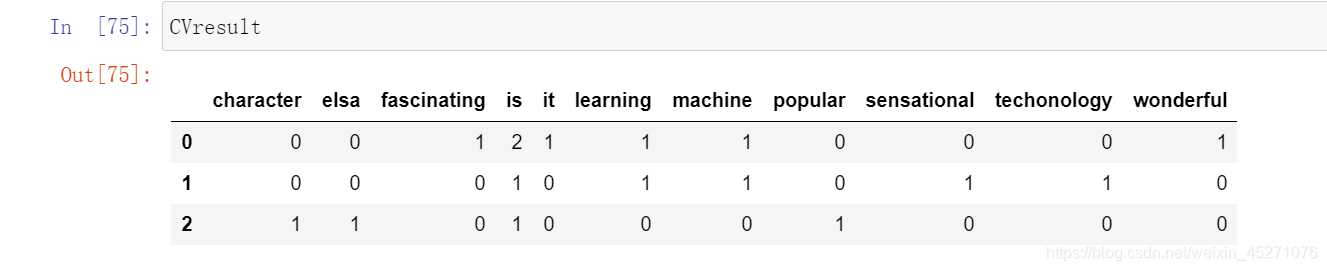
#单词计数向量
sample = ["Machine learning is fascinating, it is wonderful"
,"Machine learning is a sensational techonology"
,"Elsa is a popular character"]
from sklearn.feature_extraction.text import CountVectorizer
vec=CountVectorizer()
X=vec.fit_transform(sample)
X#拟合之后转换为稀疏矩阵

句子越长,对模型影响很大,所以要除以L2范式

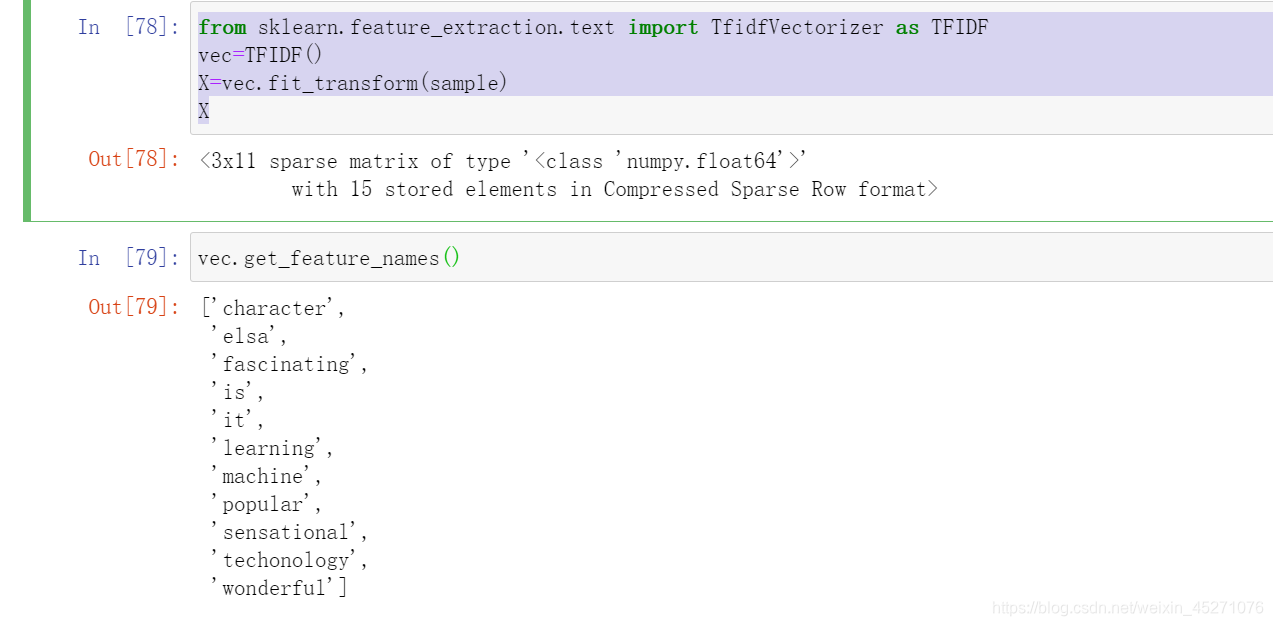
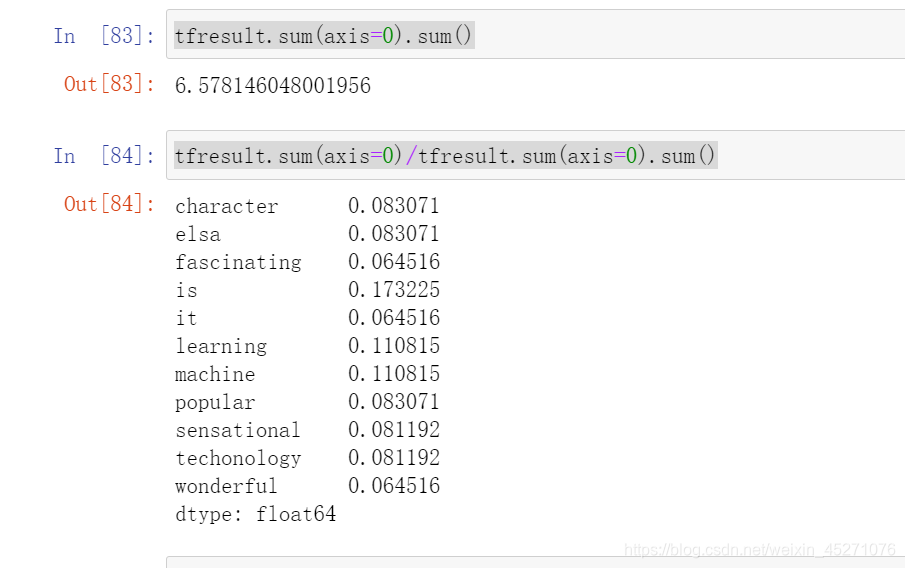
TF-IDF
TF-IDF全称term frequency-inverse document frequency,词频逆文档频率,是通过单词在文档中出现的频率来衡
量其权重,也就是说,IDF的大小与一个词的常见程度成反比,这个词越常见,编码后为它设置的权重会倾向于越
小,以此来压制频繁出现的一些无意义的词。在sklearn当中,我们使用feature_extraction.text中类TfidfVectorizer
来执行这种编码


















 2976
2976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









