






变量相关性分析
接下来,我们尝试对变量和标签进行相关性分析。从严格的统计学意义讲,不同类型变量的
相关性需要采用不同的分析方法,例如连续变量之间相关性可以使用皮尔逊相关系数进行计算,
而连续变量和离散变量之间相关性则可以卡方检验进行分析,而离散变量之间则可以从信息增益
角度入手进行分析。但是,如果我们只是想初步探查变量之间是否存在相关关系,则可以忽略变
量连续/离散特性,统一使用相关系数进行计算,这也是pandas中的.corr方法所采用的策略。
计算相关系数矩阵
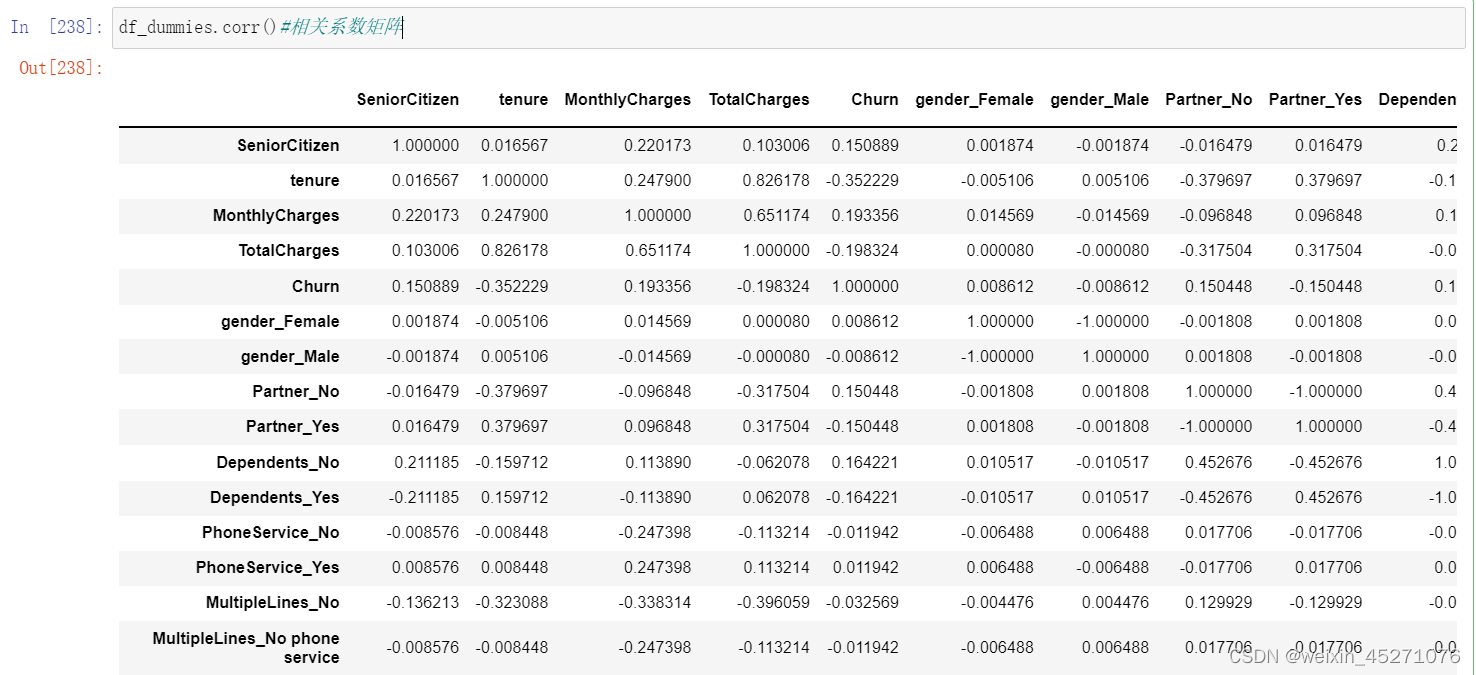
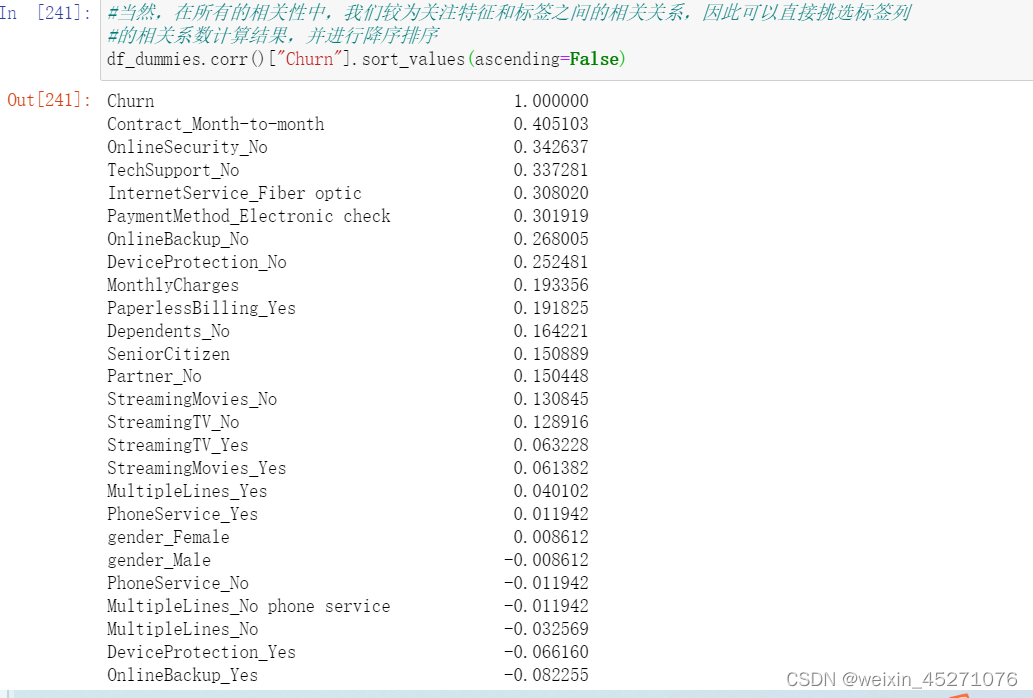
当然,首先我们可以先计算相关系数矩阵,直接通过具体数值大小来表示相关性强弱。不过
需要注意的是,尽管我们可以忽略变量的连续/离散特性,但为了更好的分析分类变量如何影响标
签的取值,我们需要将标签转化为整型(也就是视作连续变量),而将所有的分类变量进行哑变
量处理:

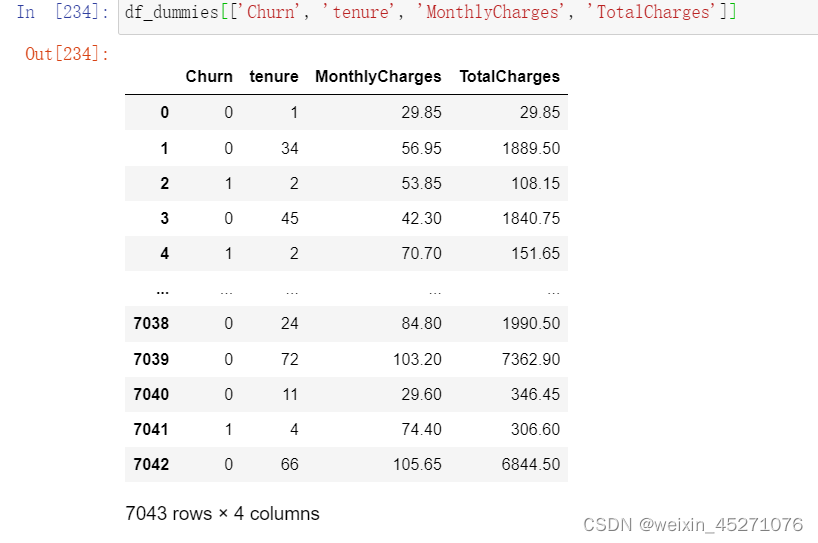
#柱状图展示相关性
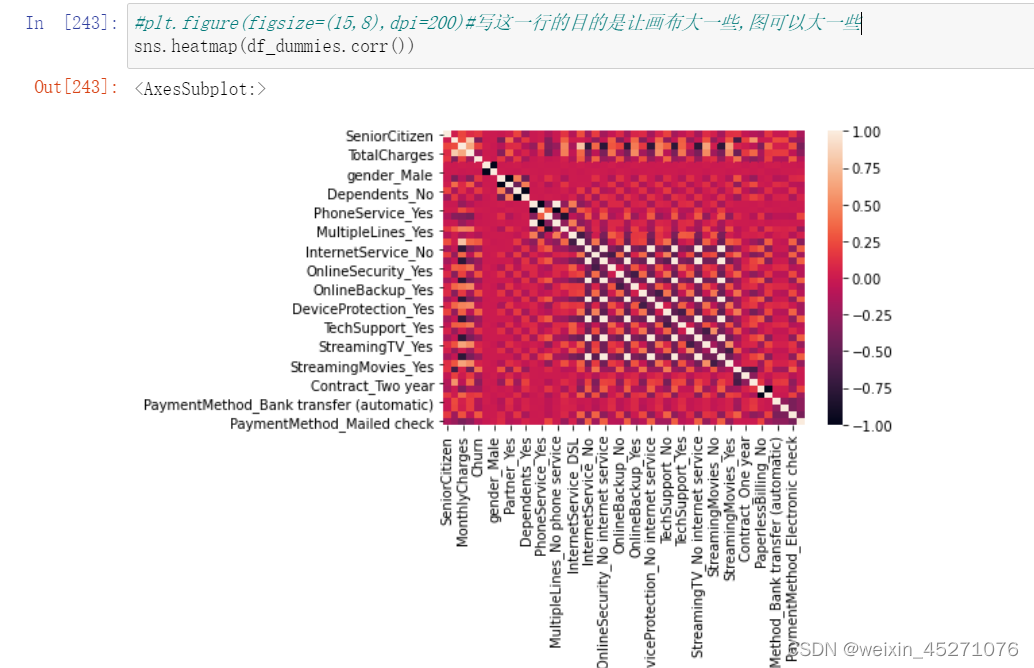
# 当然,很多时候如果特征较多,热力图的展示结果并不直观,此时我们可以考虑进一步使用
#柱状图来进行表示
plt.figure(figsize=(15,6))
df_dummies["Churn"].sort_values(ascending=False).plot(kind='bar')
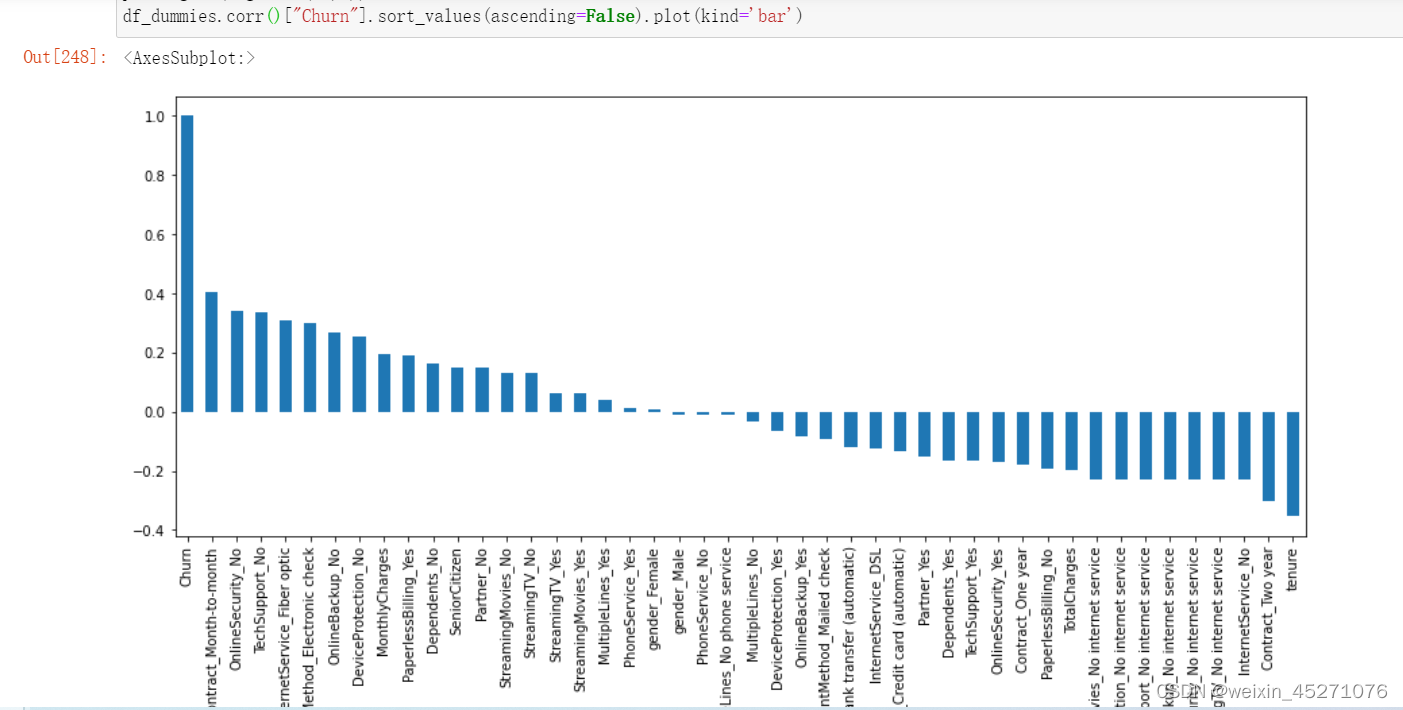
3.探索性数据分析
当然,直接计算整体相关系数矩阵以及对整体相关性进行可视化展示是一种非常高效便捷的
方式,在实际的算法竞赛中,我们也往往会采用上述方法快速的完成数据相关性检验和探索工
作。不过,如果是对于业务分析人员,可能我们需要为其展示更为直观和具体的一些结果,才能
有效帮助业务人员对相关性进行判别。此时我们可以考虑围绕不同类型的属性进行柱状图的展示
与分析。当然,此处需要对比不同字段不同取值下流失用户的占比情况,因此可以考虑使用柱状
图的另一种变形:堆叠柱状图来进行可视化展示
fig,axes=plt.subplots(nrows=1,ncols=2,figsize=(12,6),dpi=100)
#柱状图
plt.subplot(121)
sns.countplot(x="gender",hue="Churn",data=tcc,palette="Blues",dodge=True)
plt.xlabel("Gender")
plt.title("Churn by Gender")
#第一种方式
#x: x轴上的条形图,以x标签划分统计个数
#y: y轴上的条形图,以y标签划分统计个数
#hue: 在x或y标签划分的同时,再以hue标签划分统计个数
plt.subplot(122)#堆叠柱状图
sns.countplot(x="gender",hue="Churn",data=tcc,palette="Blues",dodge=False)
plt.xlabel("Gender")
plt.title("Churn by Gender")
'''x: x轴上的条形图,以x标签划分统计个数
y:y轴上的条形图,以y标签划分统计个数
hue:在x或y标签划分的同时,再以hue标签划分统计个数
data:df或array或array列表,用于绘图的数据集,x或y缺失时,data参数为数据集,同时x或y不可缺少,必须要有其中一个
order, hue_order:分别是对x或y的字段排序,hue的字段排序。排序的方式为列表
orient:强制定向,v:竖直方向;h:水平方向
palette:使用不同的调色板
ax:画子图的时候'''
注,此处堆叠图简单理解其实就是纯粹的重合,并不是上下堆叠,而是深色柱状图
覆盖在浅色柱状图的上面



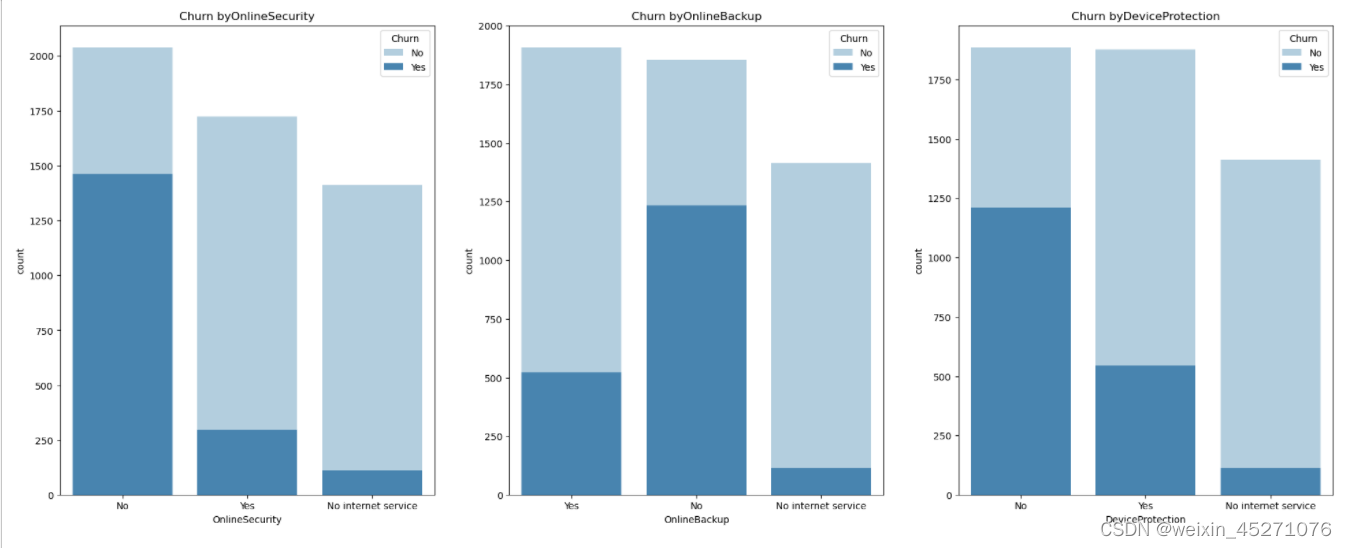
#首先是账户统计信息
col_2 = ["OnlineSecurity", "OnlineBackup", "DeviceProtection", "TechSupport", 'StreamingTV', 'StreamingMovies']
fig,axes=plt.subplots(nrows=2,ncols=3,figsize=(24,20),dpi=100)
#柱状图
for idex,col in enumerate(col_2):
plt.subplot(2,3,idex+1)#2行2列第几个
sns.countplot(x=col_2[idex],hue="Churn",data=tcc,palette="Blues",dodge=False)
plt.xlabel(col_2[idex])
plt.title("Churn by"+col)

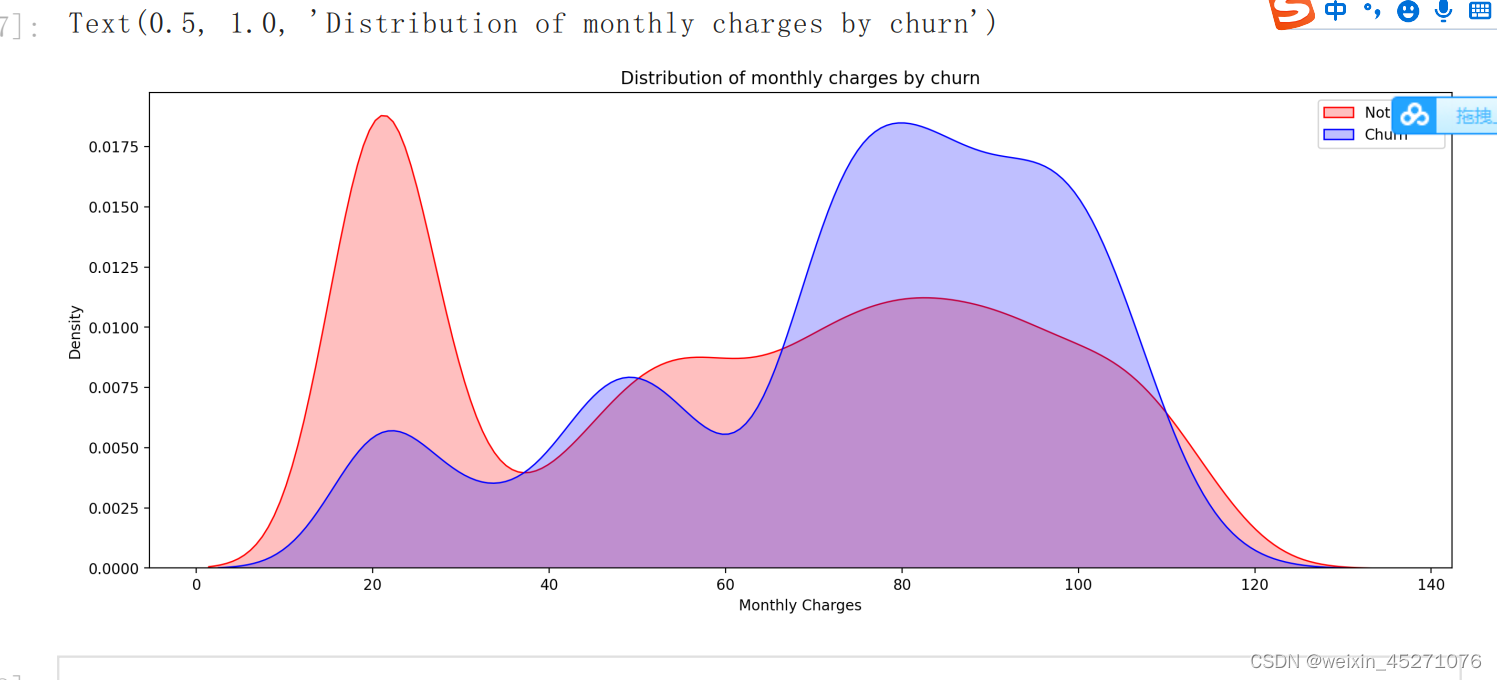


由于核密度估计是对变量分布的一种估计,因此不会受到变量当前取值范围的影响,该曲线会在
一个更大的取值范围内对变量分布进行估计。并且由于是概率密度分布的估计(即曲线下方面积
为1),因此也会更加适合进行对比分析。
通过上述对比分析不难发现,月度消费金额较大的用户更容易流失,而在过去的一个季度
内,总金额消费较小的用户更容易流失。当然该结论也和此前进行的相关性检验结果一致。
至此,我们就完成了对每个变量的单独分析。当然,如果能获取更多的实际业务背景知识,
则能够进行更加深入的数据分析与用户挽留策略的制定。不过需要知道的是,无论是作为实际建
模预测项目,还是结合实际业务进行数据分析,在完成数据清洗后对变量进行相关性分析,都是
了解数据情况的重要手段,也是所有建模过程中必备的环节。在后续的内容中,我们也将在此基
础上进一步来进行特征工程以及模型训练的相关工作,最终借助模型,来进行实时的用户流失预
测,并且根据最终的模型结果来更精确的判别变量重要性,以及根据模型方程来判断变量影响流
失概率的量化结果















 1718
1718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









