







随机抽特征和随机抽样本
n_estimators 是控制森林中树木的数量,即基评估器的数量。这个参数对随机森林模型的精确性影响是单调的,n_estimators越 大,模型的效果往往越好。但是相应的,任何模型都有决策边 n_estimators达到一定的程度之后,随机森林的 精确性往往不在上升或开始波动,并且,n_estimators越大,需要的计算量和内存也越大,训练的时间也会越来越 长。对于这个参数,我们是渴望在训练难度和模型效果之间取得平衡。



import pandas as pd
import numpy as np
import sklearn
import matplotlib as mlp
import matplotlib.pyplot as plt
import time
from sklearn.ensemble import RandomForestClassifier as RFR
from sklearn.ensemble import GradientBoostingRegressor as GBR
from sklearn.model_selection import cross_validate,KFold
import hyperopt
from hyperopt import hp,fmin,tpe,Trials,partial
from hyperopt.early_stop import no_progress_loss
data=pd.read_csv(r"D:\caicai_sklearn\caicai_datasets\House Price\train_encode.csv",index_col=0)
X=data.iloc[:,:-1]
y=data.iloc[:,-1]
#定义参数init需要的算法
rf=RFR(n_estimators=89,max_depth=22,max_features=14,min_impurity_decrease=0,
random_state=1412,verbose=False,n_jobs=-1)
#第三步骤,定义目标函数、参数空间,优化函数,验证函数
#目标函数:
def hyperopt_objective(params):
reg=GBR(n_estimators=int(params['n_estimators'])
,learning_rate=params['lr']
,criterion=params['criterion']
,loss=params['loss']
,max_depth=int(params['max_depth'])
,max_features=params['max_features']
,subsample=params['subsample']
,min_impurity_decrease=params['min_impurity_decrease']
,init=rf#初始化
,random_state=1412
,verbose=False#是否打印过程
)
cv=KFold(n_splits=5,shuffle=True,random_state=1412)
validation_loss=cross_validate(reg,X,y
,scoring='neg_root_mean_squared_error'
,cv=cv
,verbose=False
,n_jobs=-1
,error_score='raise'
)
return np.mean(abs(validation_loss['test_score']))
#cross_validate返回train/test数据集上的每折得分
'''cross_validate函数在error_score='raise'时,如果在交叉验证过程中出现错误,
它会抛出一个异常。这通常用于调试模型的目的,因为它会中断交叉验证过程,
提醒开发者注意到一些潜在的问题,如数据质量问题、模型不适合数据等。
2.2 平均平方误差(MSE)
均方误差是指参数估计值与参数真值之差平方的期望值,记为MSE。MSE是衡量平均误差的一种较方便的方法,
MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。
MSE数值大小本身没有意义,随着样本增加,MSE必然增加,也就是说,不同的数据集的情况下,MSE比较没有意义
均方根误差(RMSE====MSE取根号
'''
```c
#参数空间
param_grid_simple={'n_estimators':hp.quniform("n_estimators",25,200,25)#均匀分布的浮点数,所以参数里面需要int,
#不均匀分布的浮点数,用uniform
,'lr':hp.quniform("learning_rate",0.05,2.05,0.05)
,"criterion":hp.choice("criterion",['friedman_mse',"squared_error",'mse'])
,'loss':hp.choice('loss',['squared_error','absolute_error','huber','quantile'])
,'max_depth':hp.quniform('max_depth',2,30,2)
,'subsample':hp.quniform('subsample',0.1,0.8,0.1)
,'max_features':hp.choice('max_features',['log2','sqrt',16,32,64,'auto'])
,"min_impurity_decrease":hp.quniform('min_impurity_decrease',0,5,1)
}
#优化函数
def param_hyperopt(max_evals=100):
#保存迭代过程
trials=Trials()
#设置提前停止
early_stop_fn=no_progress_loss(100)#如果连续100次损失函数都没有下降的话,就停止
#定义代理模型
params_best=fmin(hyperopt_objective#目标函数
,space=param_grid_simple
,algo=tpe.suggest#代理模型,使用tpe
,max_evals=max_evals
,verbose=True
,trials=trials
,early_stop_fn=early_stop_fn
)
#打印最有参数,fmin会自动打印最佳分数
print("\n","\n",'best params:',params_best,"\n")
return params_best,trials#就返回最优的参数
#验证函数(可选),这个过程和目标函数一样,boosting随机性,不一定能够被复现
def hyperopt_validation(params):
reg=GBR(n_estimators=int(params['n_estimators'])
,learning_rate=params['lr']
,criterion=params['criterion']
,loss=params['loss']
,max_depth=int(params['max_depth'])
,max_features=params['max_features']
,subsample=params['subsample']
,min_impurity_decrease=params['min_impurity_decrease']
,init=rf#初始化
,random_state=1412
,verbose=False#是否打印过程
)
cv=KFold(n_splits=5,shuffle=True,random_state=1412)
validation_loss=cross_validate(reg,X,y
,scoring='neg_root_mean_squared_error'
,cv=cv
,verbose=False
,n_jobs=-1
,error_score='raise'
)
return np.mean(abs(validation_loss['test_score']))
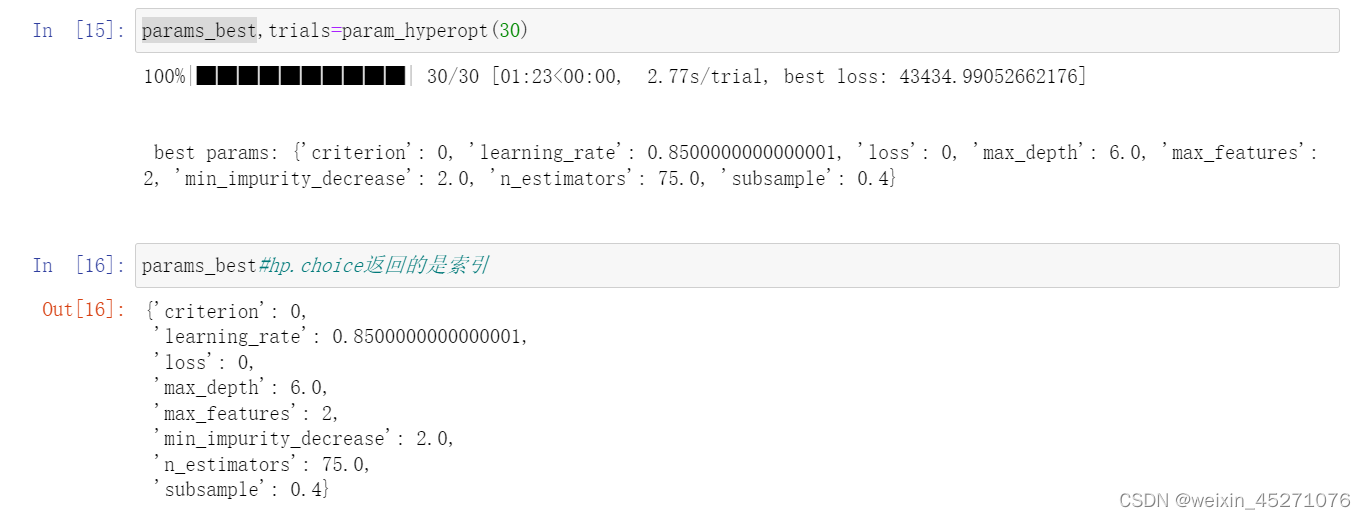

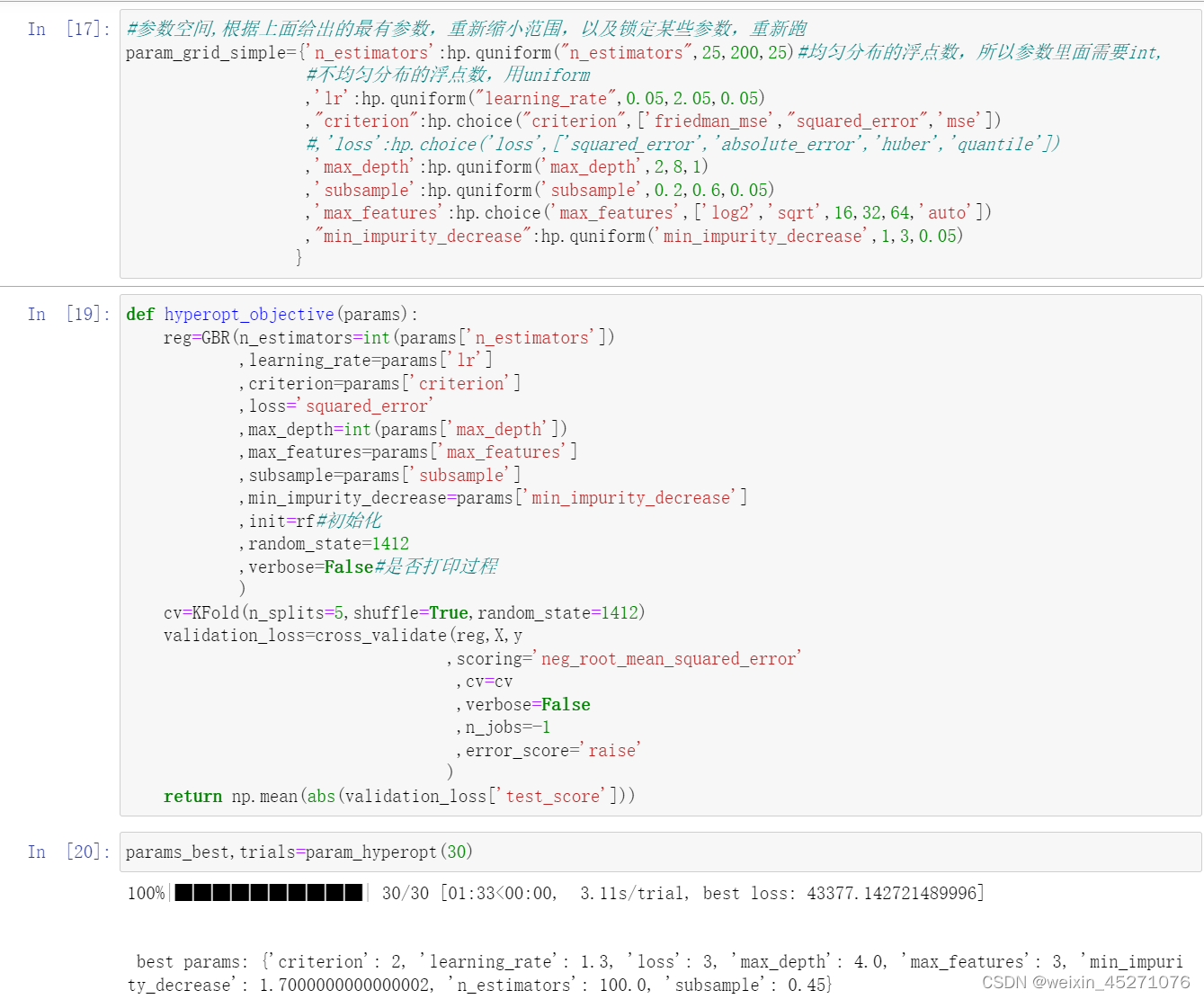
可以看到best loss逐渐在缩小,说明缩小参数空间的方向是对的,可以不断地迭代这个过程
















 5215
5215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









