







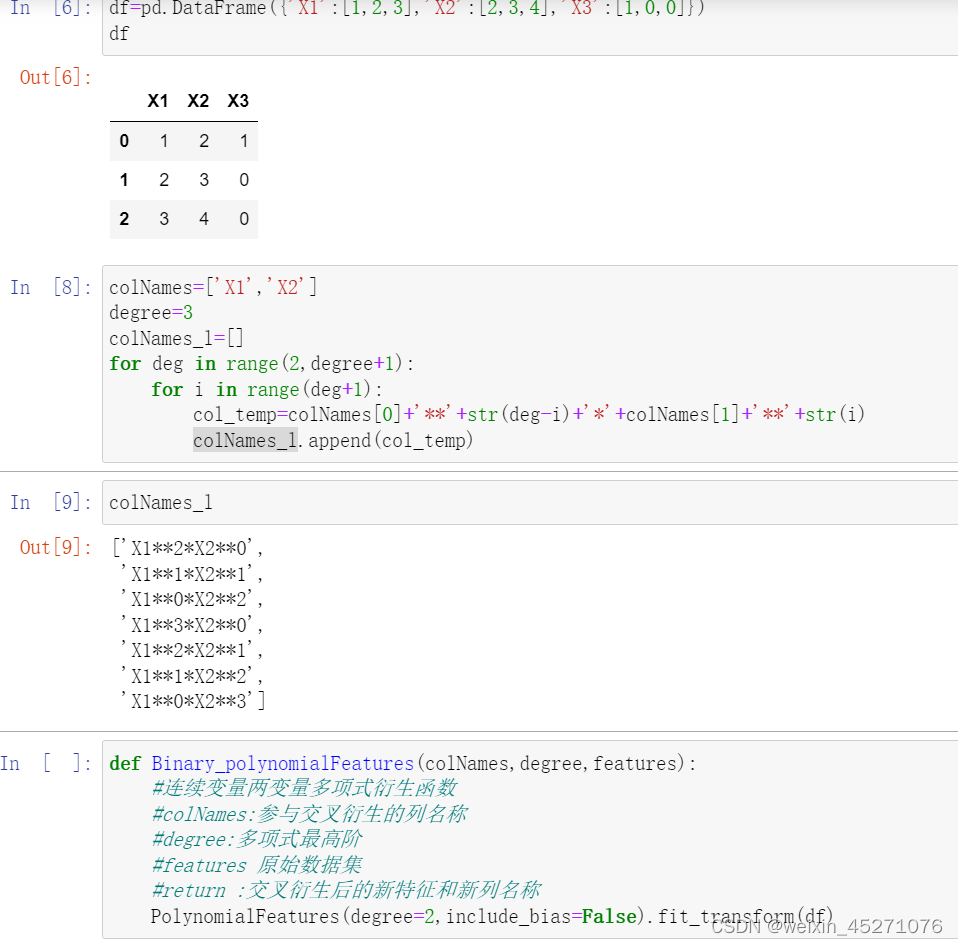
#交叉组合特征衍生
def Binary_cross_Combination(colNames,features,OneHot=True):
colNames_new_l=[]
features_new_l=[]
#提取需要组合的交叉特征
features=features[colNames]
for col_index,col_name in enumerate(colNames):
for col_sub_index in range(col_index+1,len(colNames)):
newNames=col_name+'&'+colNames[col_sub_index]
colNames_new_l.append(newNames)
newDF=pd.Series(features[col_name].astype('str')+'&'+features[colNames[col_sub_index]].astype('str'),
name=newNames)
features_new_l.append(newDF)
features_new=pd.concat(features_new_l,axis=1)
features_new.columns=colNames_new_l
colNames_new=colNames_new_l
if OneHot==True:
enc=preprocessing.OneHotEncoder()
enc.fit_transform(features_new)
colNames_new=cate_colName(enc,colNames_new_l,drop='if_binary')
features_new=pd.DataFrame(enc.fit_transform(features_new).toarray(),columns=colNames_new)
return features_new
```c
colNames=['SeniorCitizen','Partner','Dependents']
features = tcc.drop(columns=[ID_col, target]).copy()
Binary_cross_Combination(colNames,features)
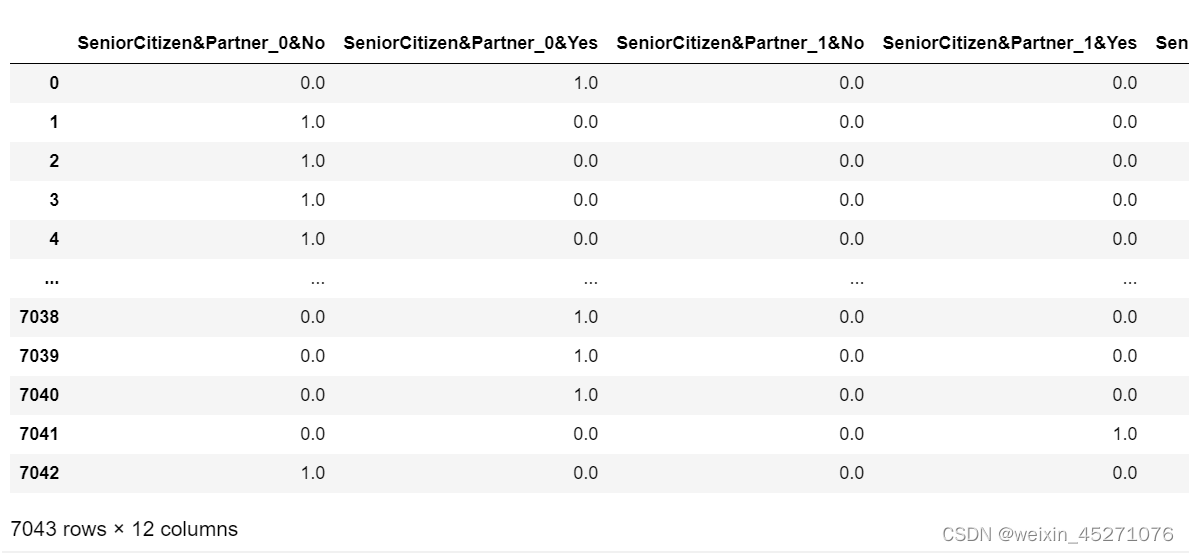
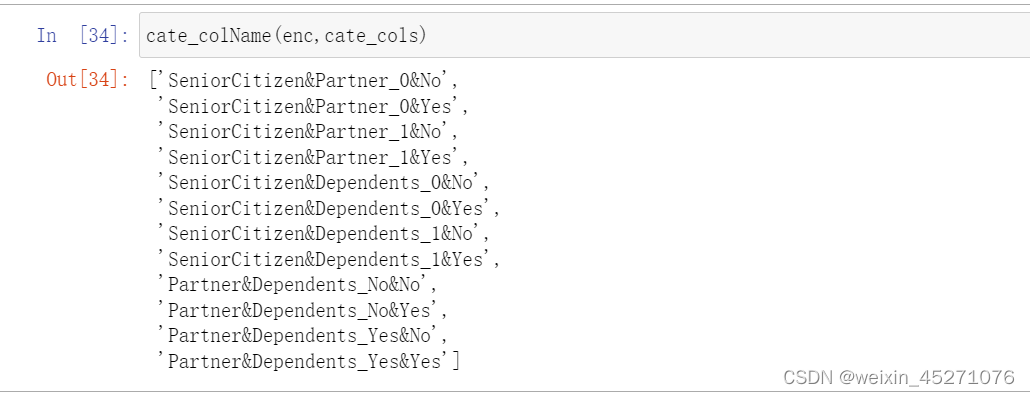
def cate_colName(Transformer,category_cols,drop='if_binary'):
#离散字段独热编码后字段名函数
#Transformer#独热编码转换器
#category_cols,输入转化器的离散变量
cate_cols_new=[]
col_value=Transformer.categories_
for index,name in enumerate(cate_cols):
if (drop=='if_binary')&len(Transformer.categories_[index]==2):
#如果是二分类,则不参与独热编码,列名就是子集
cate_cols_new.append(name)
else:
for f in enc.categories_[index]:
feature_name=name+'_'+f
cate_cols_new.append(feature_name)
return cate_cols_new
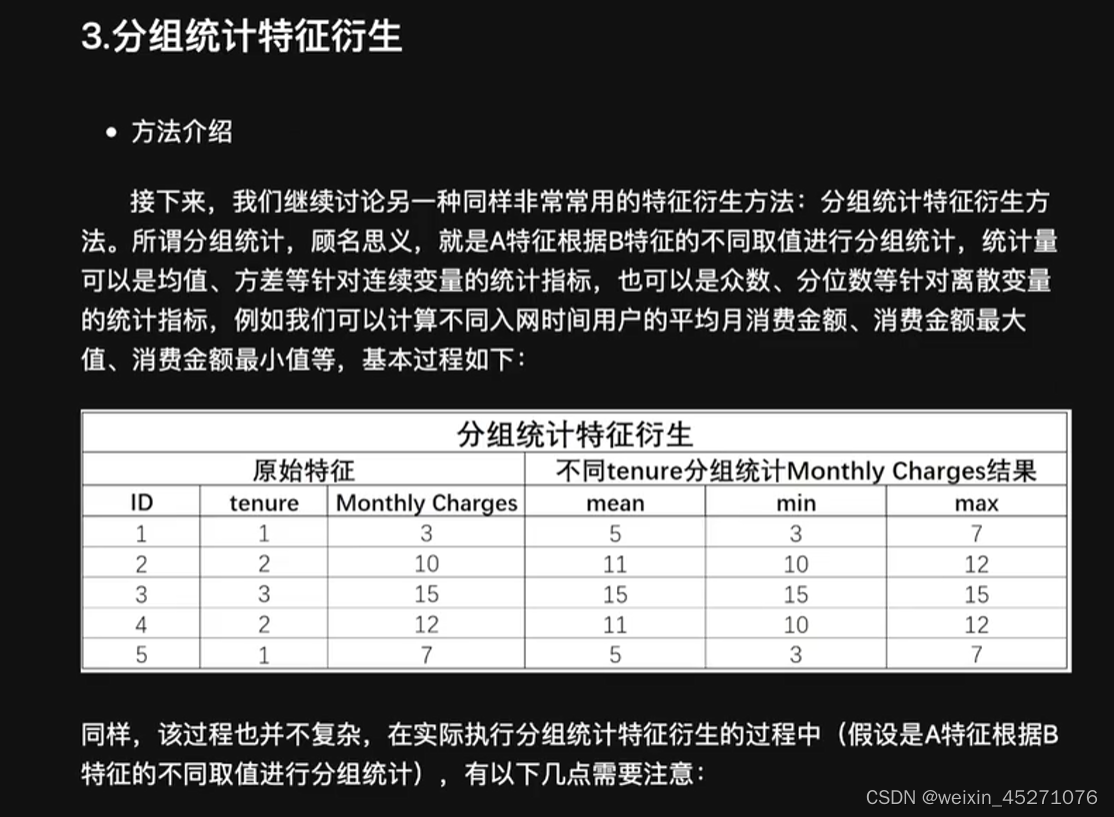
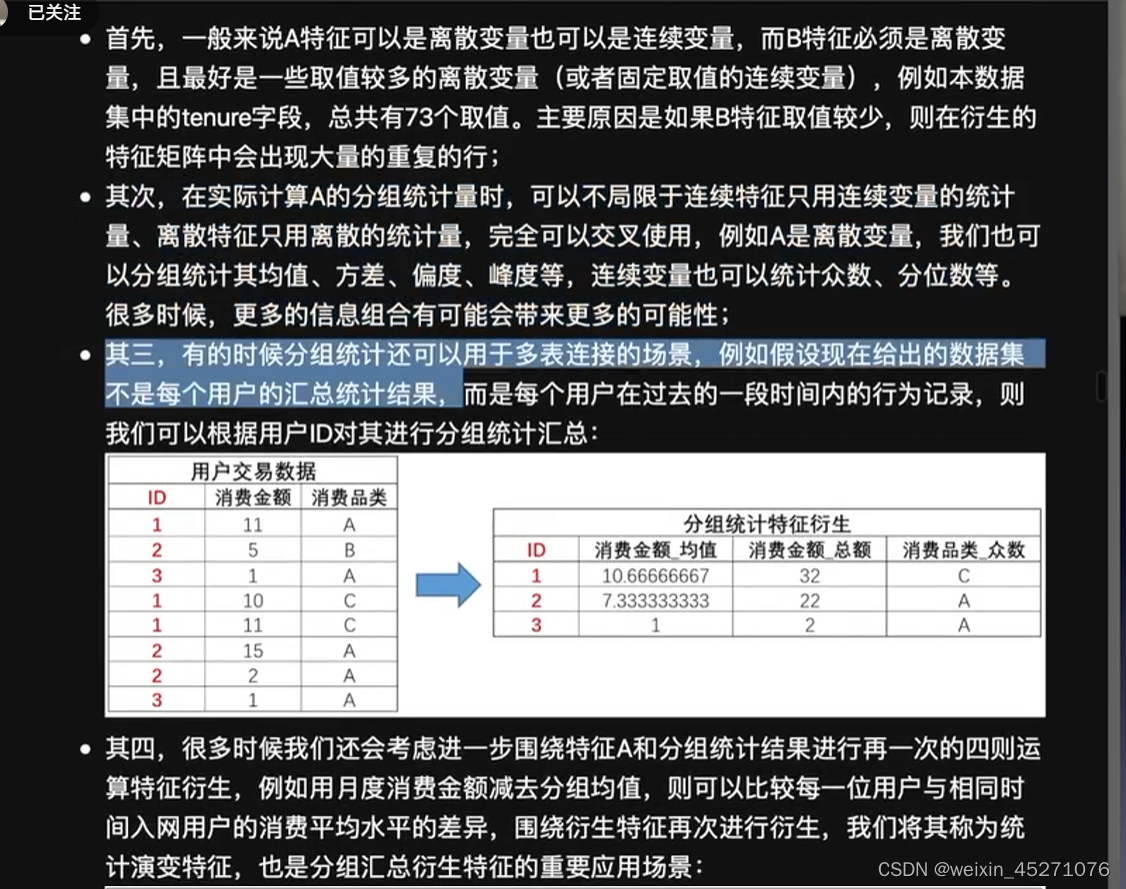
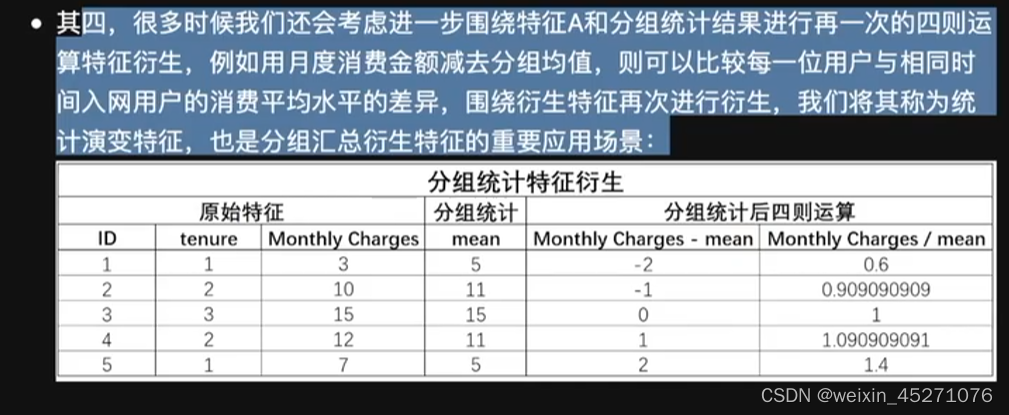
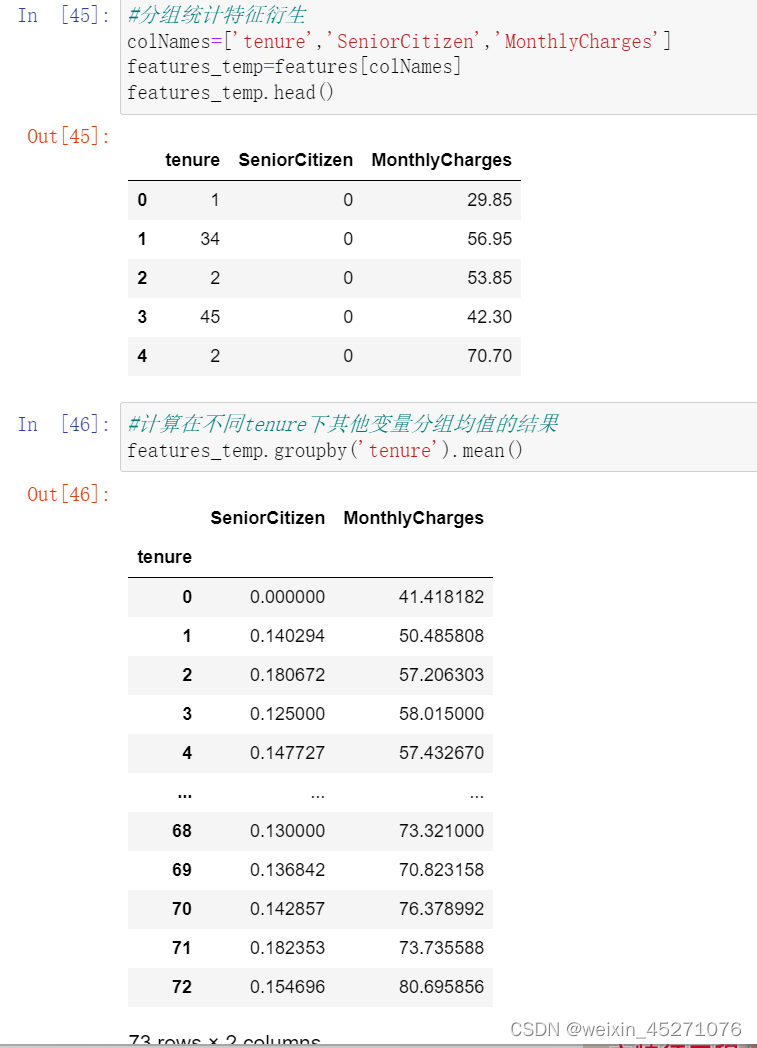
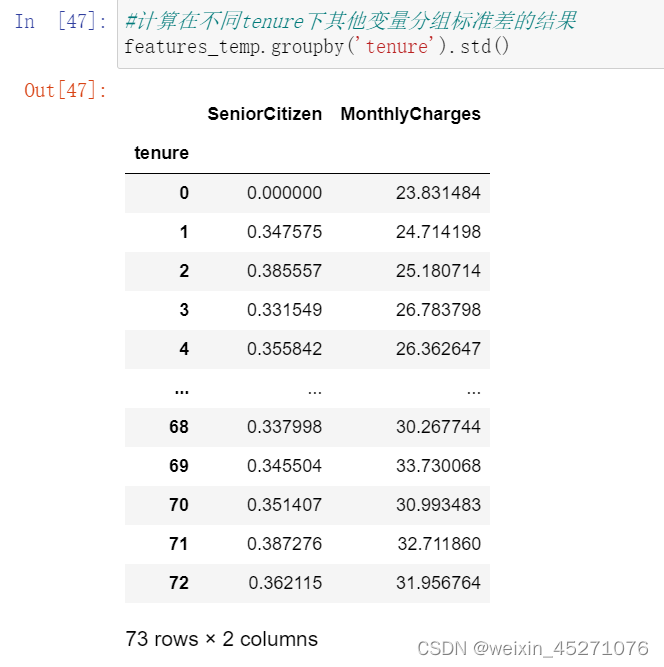
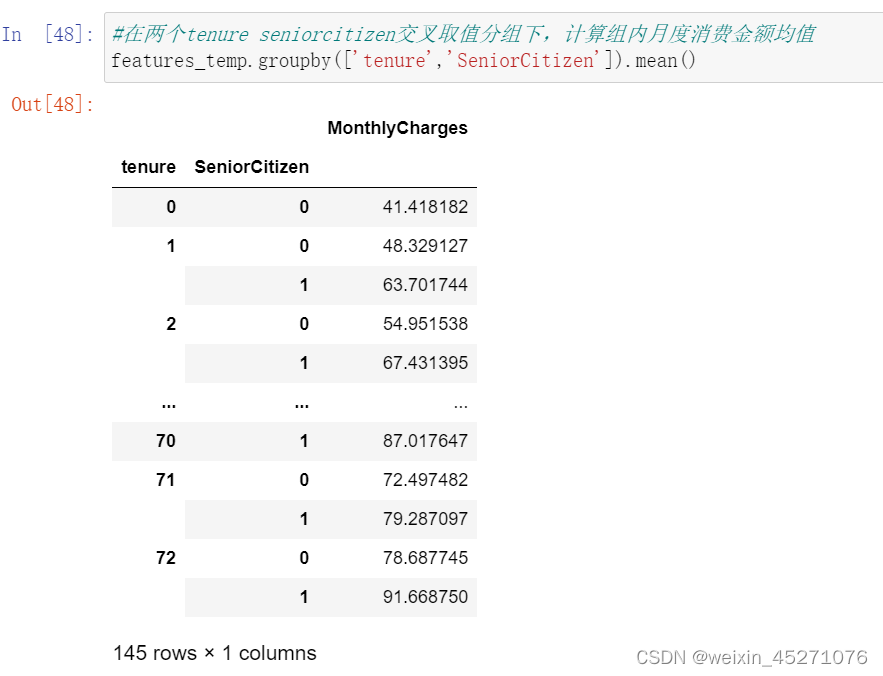
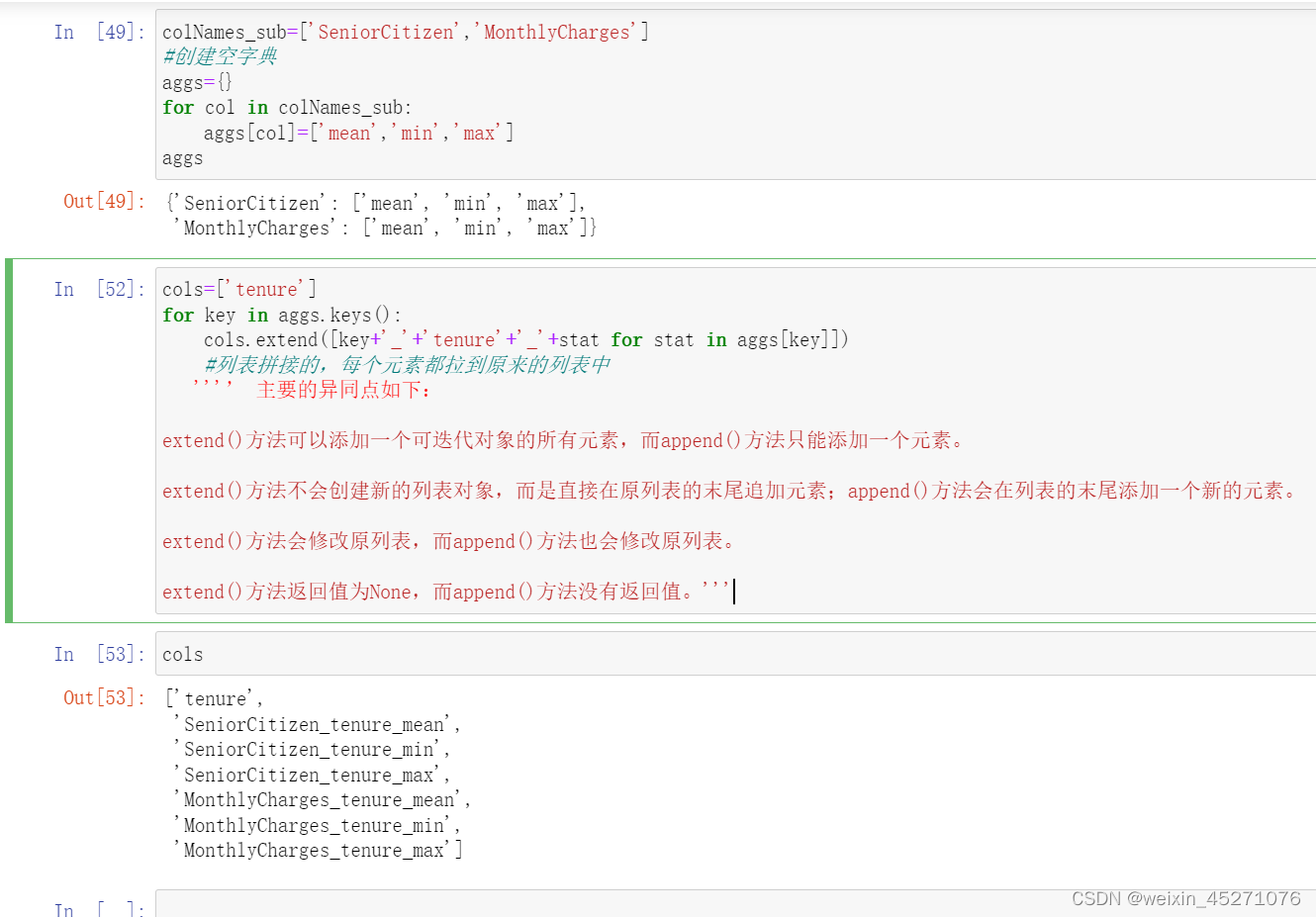
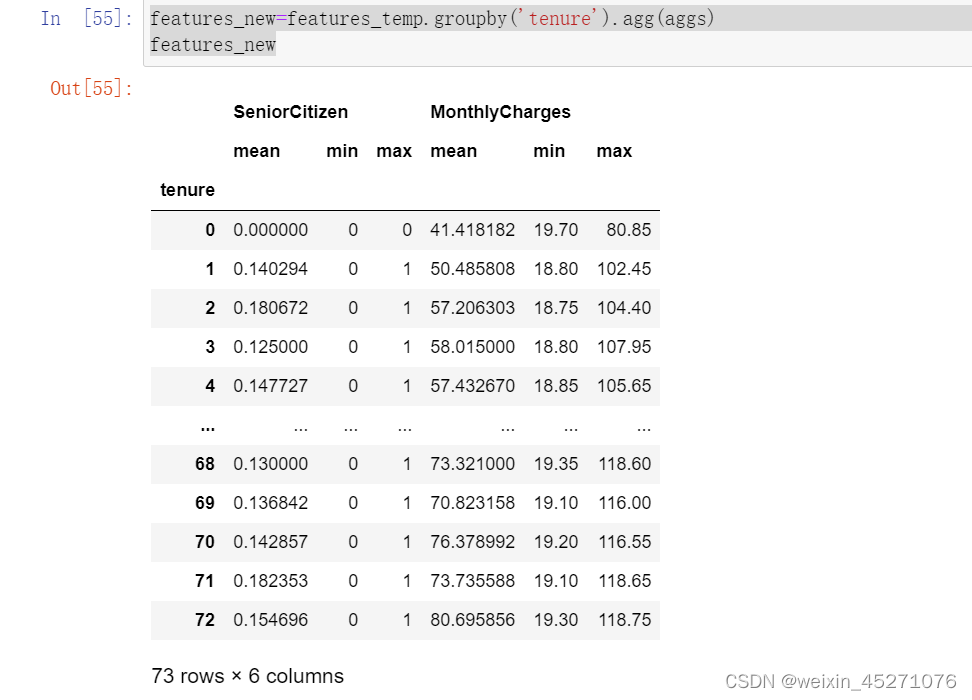
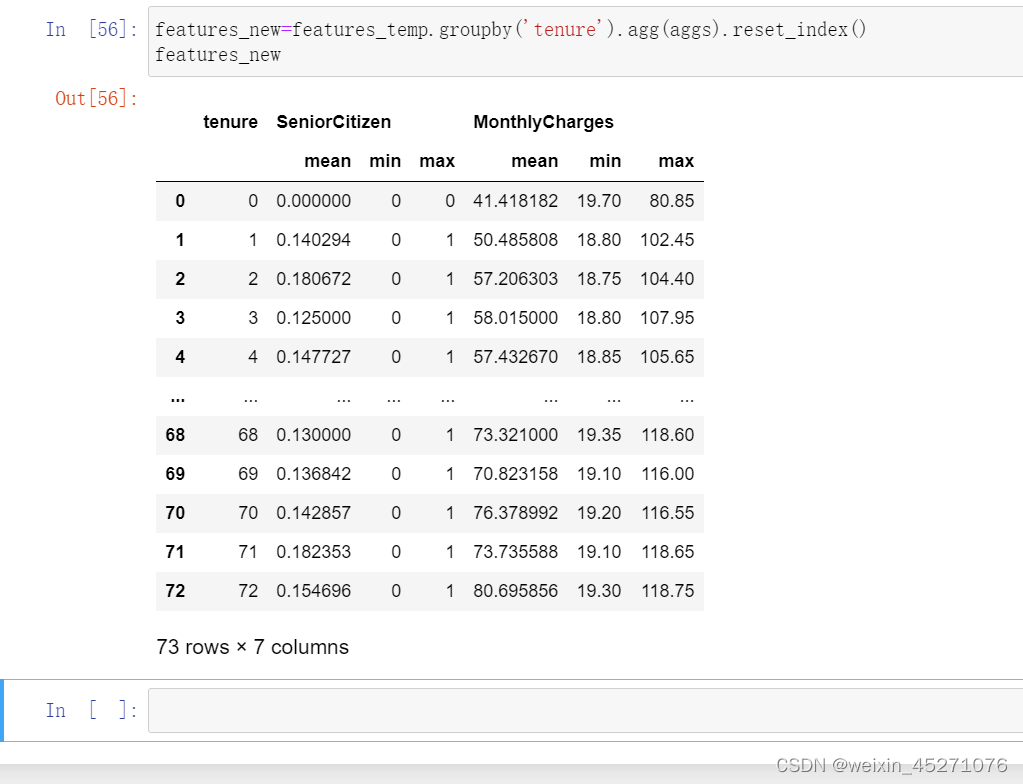
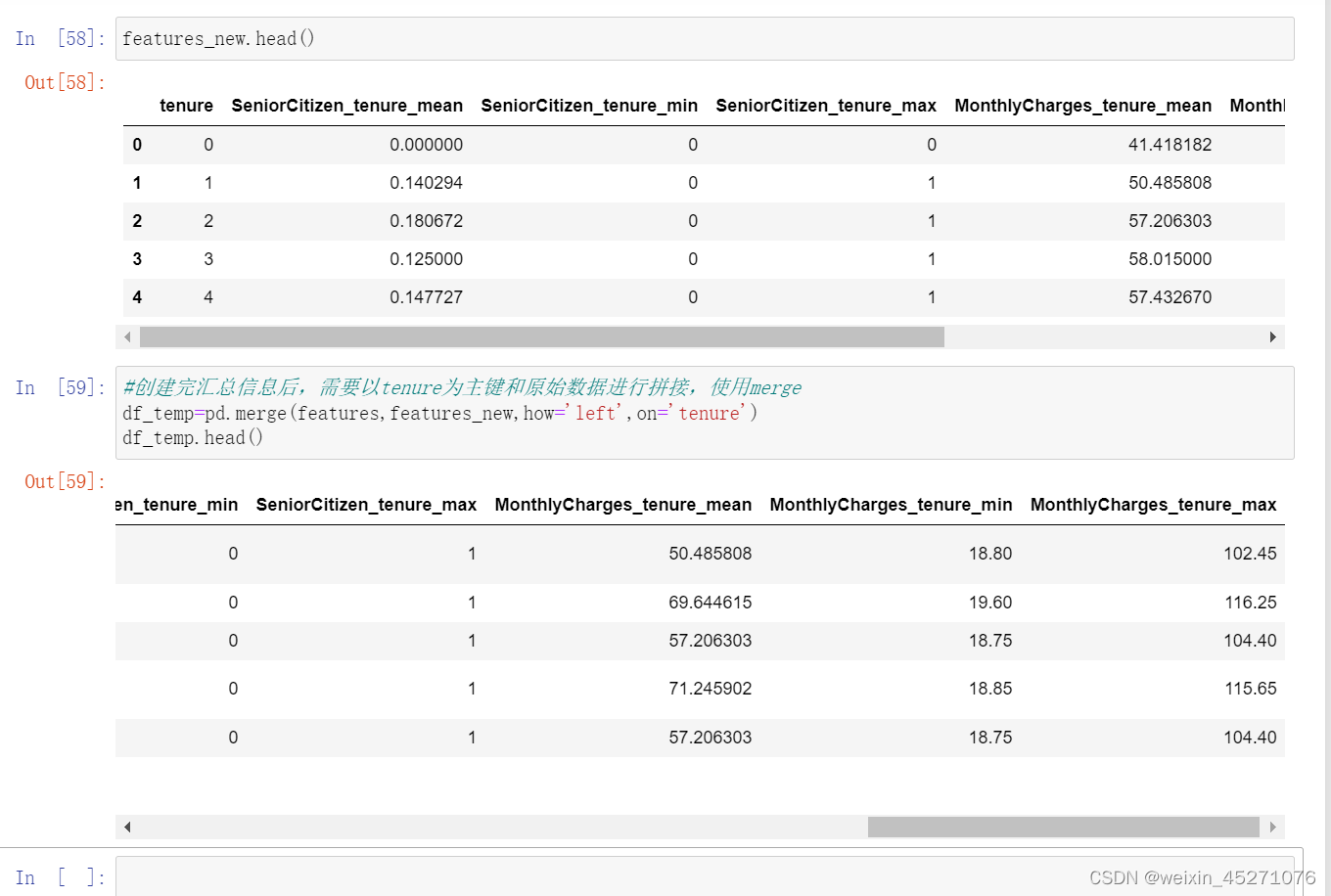
reset_index()可以把tenure拉回到列名的位置
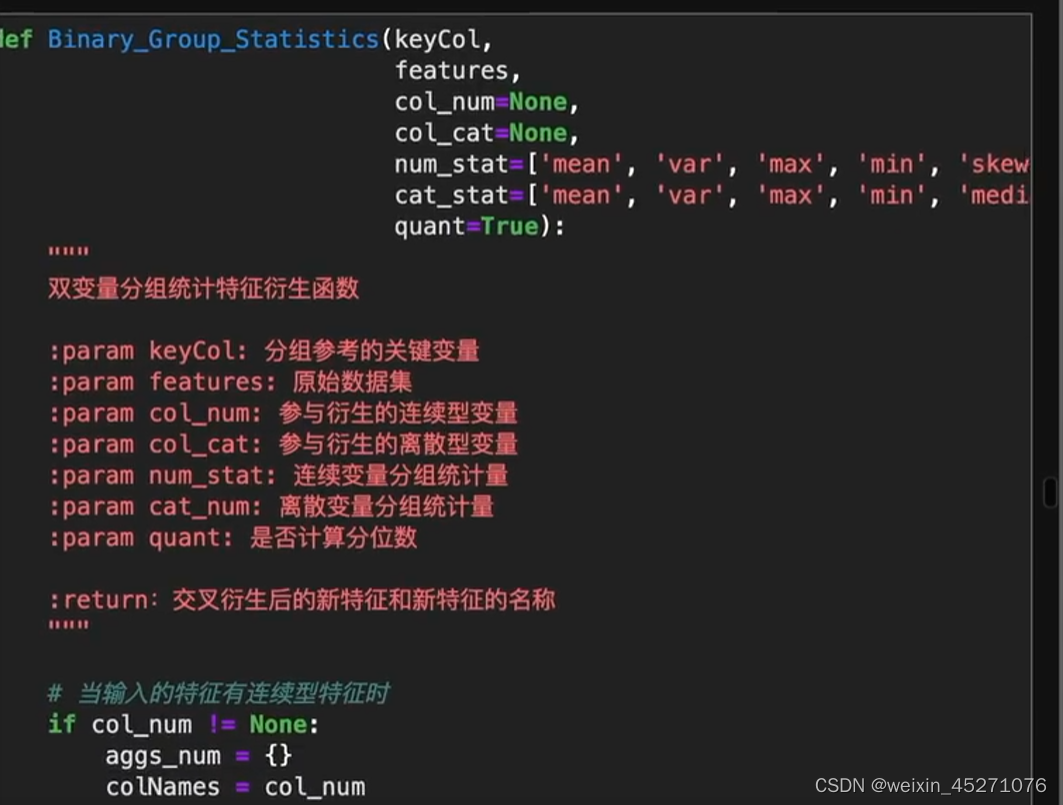
def Binary_Group_Statistics(keyCol,
features,
col_num=None,
col_cat=None,
num_stat=['mean', 'var', 'max', 'min', 'skew', 'median'],
cat_stat=['mean', 'var', 'max', 'min', 'median', 'count', 'nunique'],
quant=True):
"""
双变量分组统计特征衍生函数
:param keyCol: 分组参考的关键变量
:param features: 原始数据集
:param col_num: 参与衍生的连续型变量
:param col_cat: 参与衍生的离散型变量
:param num_stat: 连续变量分组统计量
:param cat_num: 离散变量分组统计量
:param quant: 是否计算分位数
:return:交叉衍生后的新特征和新特征的名称
"""
# 当输入的特征有连续型特征时
if col_num != None:
aggs_num = {}
colNames = col_num
# 创建agg方法所需字典
for col in col_num:
aggs_num[col] = num_stat
# 创建衍生特征名称列表
cols_num = [keyCol]
for key in aggs_num.keys():
cols_num.extend([key+'_'+keyCol+'_'+stat for stat in aggs_num[key]])
# 创建衍生特征df
features_num_new = features[col_num+[keyCol]].groupby(keyCol).agg(aggs_num).reset_index()
features_num_new.columns = cols_num
# 当输入的特征有连续型也有离散型特征时
if col_cat != None:
aggs_cat = {}
colNames = col_num + col_cat
# 创建agg方法所需字典
for col in col_cat:
aggs_cat[col] = cat_stat
# 创建衍生特征名称列表
cols_cat = [keyCol]
for key in aggs_cat.keys():
cols_cat.extend([key+'_'+keyCol+'_'+stat for stat in aggs_cat[key]])
# 创建衍生特征df
features_cat_new = features[col_cat+[keyCol]].groupby(keyCol).agg(aggs_cat).reset_index()
features_cat_new.columns = cols_cat
# 合并连续变量衍生结果与离散变量衍生结果
df_temp = pd.merge(features_num_new, features_cat_new, how='left',on=keyCol)
features_new = pd.merge(features[keyCol], df_temp, how='left',on=keyCol)
features_new.loc[:, ~features_new.columns.duplicated()]
colNames_new = cols_num + cols_cat
colNames_new.remove(keyCol)
colNames_new.remove(keyCol)
# 当只有连续变量时
else:
# merge连续变量衍生结果与原始数据,然后删除重复列
features_new = pd.merge(features[keyCol], features_num_new, how='left',on=keyCol)
features_new.loc[:, ~features_new.columns.duplicated()]
colNames_new = cols_num
colNames_new.remove(keyCol)
# 当没有输入连续变量时
else:
# 但存在分类变量时,即只有分类变量时
if col_cat != None:
aggs_cat = {}
colNames = col_cat
for col in col_cat:
aggs_cat[col] = cat_stat
cols_cat = [keyCol]
for key in aggs_cat.keys():
cols_cat.extend([key+'_'+keyCol+'_'+stat for stat in aggs_cat[key]])
features_cat_new = features[col_cat+[keyCol]].groupby(keyCol).agg(aggs_cat).reset_index()
features_cat_new.columns = cols_cat
features_new = pd.merge(features[keyCol], features_cat_new, how='left',on=keyCol)
features_new.loc[:, ~features_new.columns.duplicated()]
colNames_new = cols_cat
colNames_new.remove(keyCol)
if quant:
# 定义四分位计算函数
def q1(x):
"""
下四分位数
"""
return x.quantile(0.25)
def q2(x):
"""
上四分位数
"""
return x.quantile(0.75)
aggs = {}
for col in colNames:
aggs[col] = ['q1', 'q2']
cols = [keyCol]
for key in aggs.keys():
cols.extend([key+'_'+keyCol+'_'+stat for stat in aggs[key]])
aggs = {}
for col in colNames:
aggs[col] = [q1, q2]
features_temp = features[colNames+[keyCol]].groupby(keyCol).agg(aggs).reset_index()
features_temp.columns = cols
features_new = pd.merge(features_new, features_temp, how='left',on=keyCol)
features_new.loc[:, ~features_new.columns.duplicated()]
colNames_new = colNames_new + cols
colNames_new.remove(keyCol)
features_new.drop([keyCol], axis=1, inplace=True)
return features_new, colNames_new

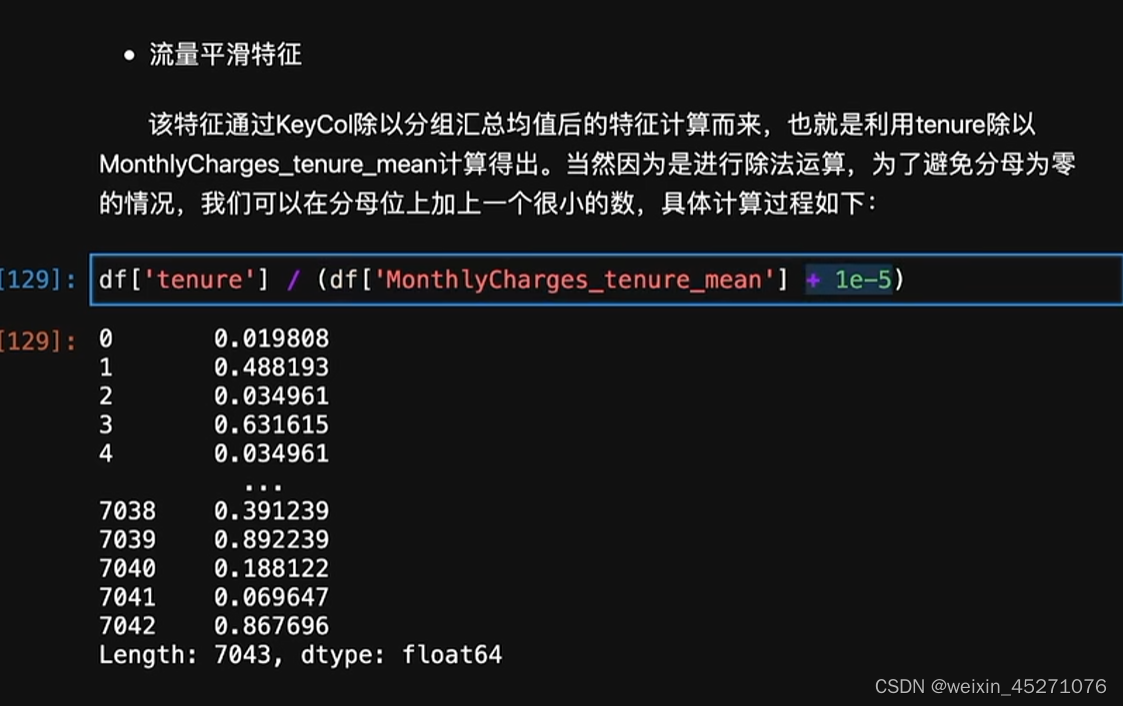
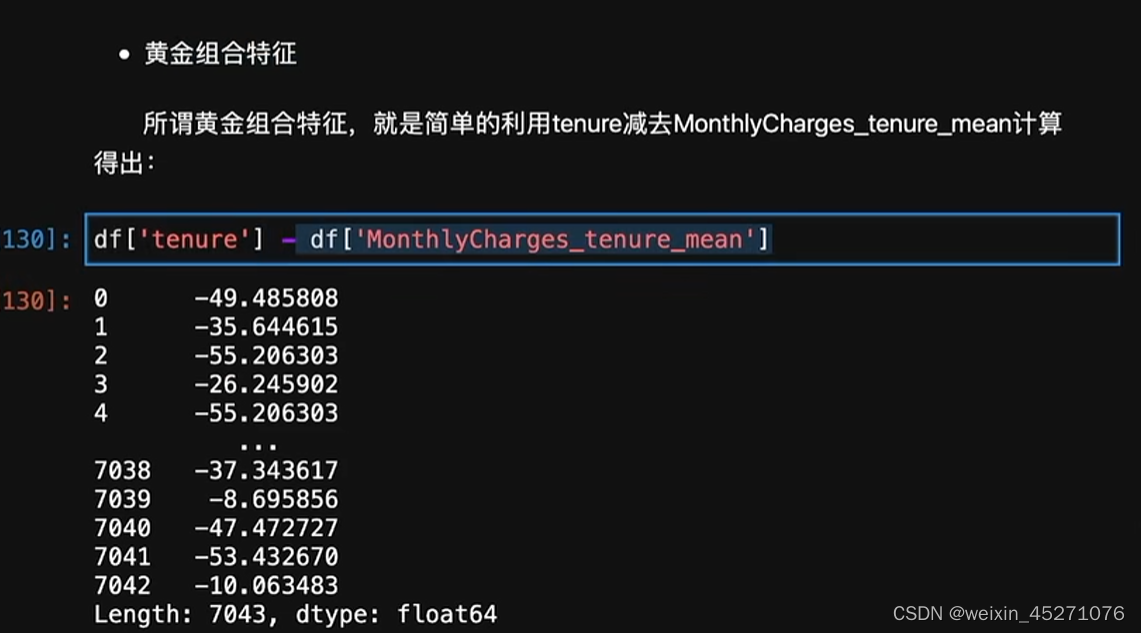
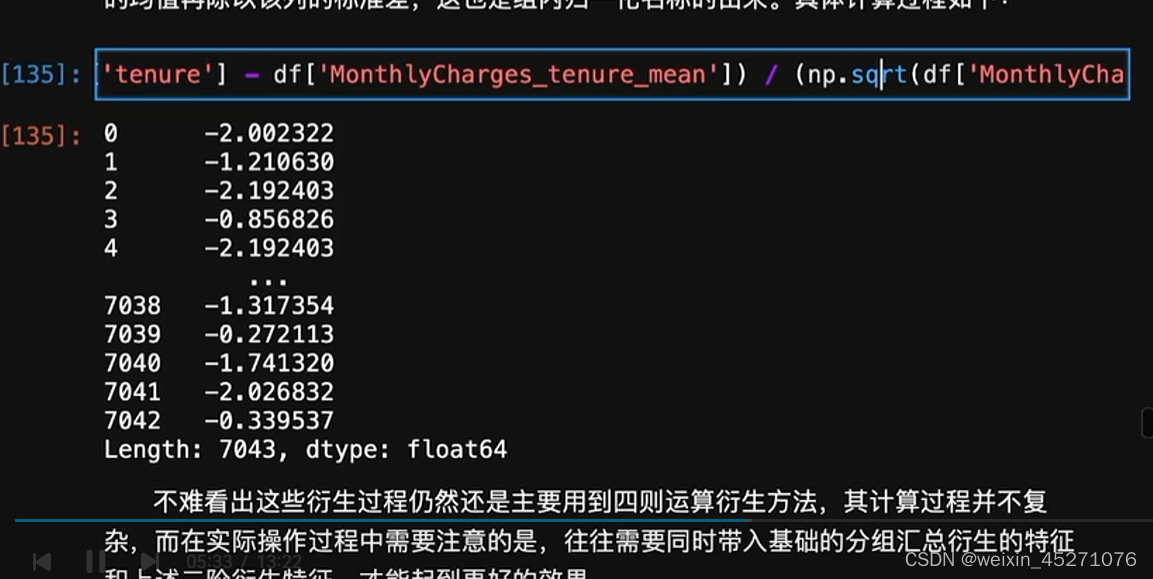
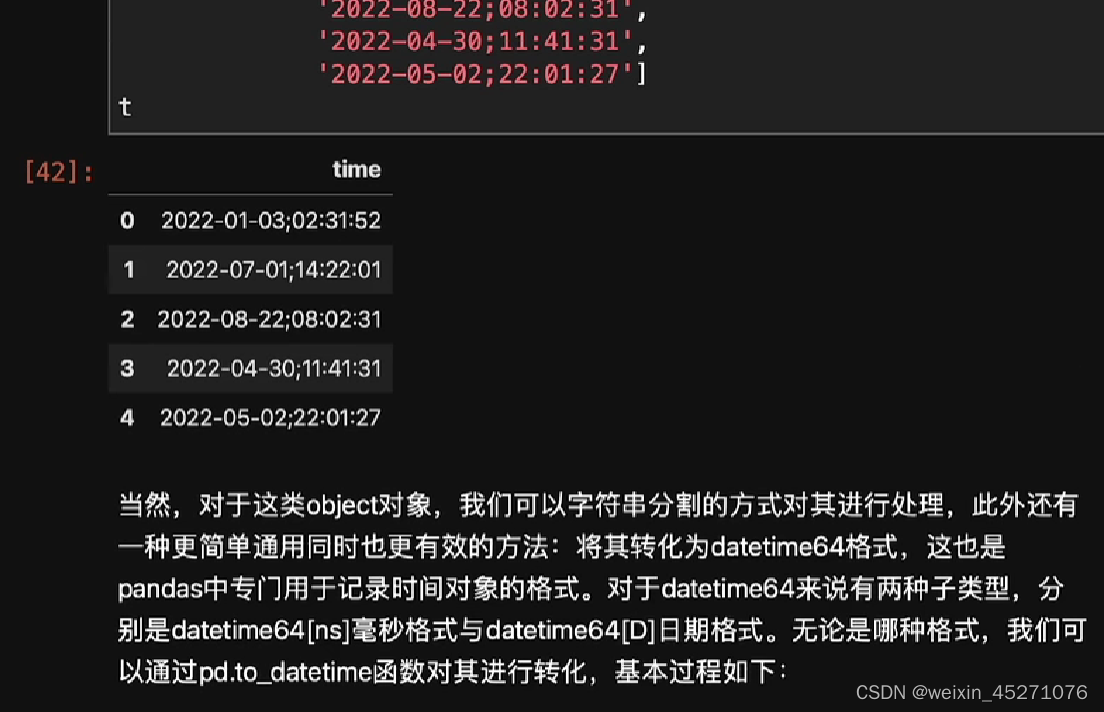
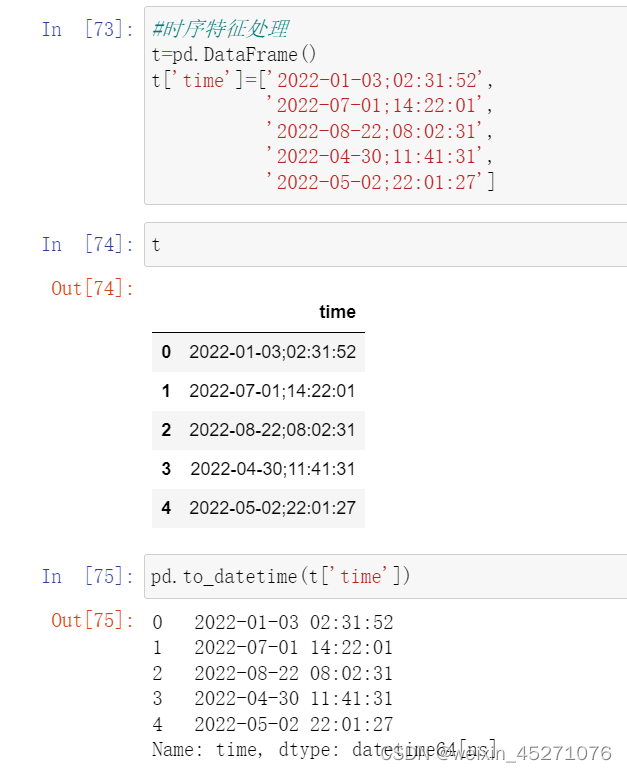
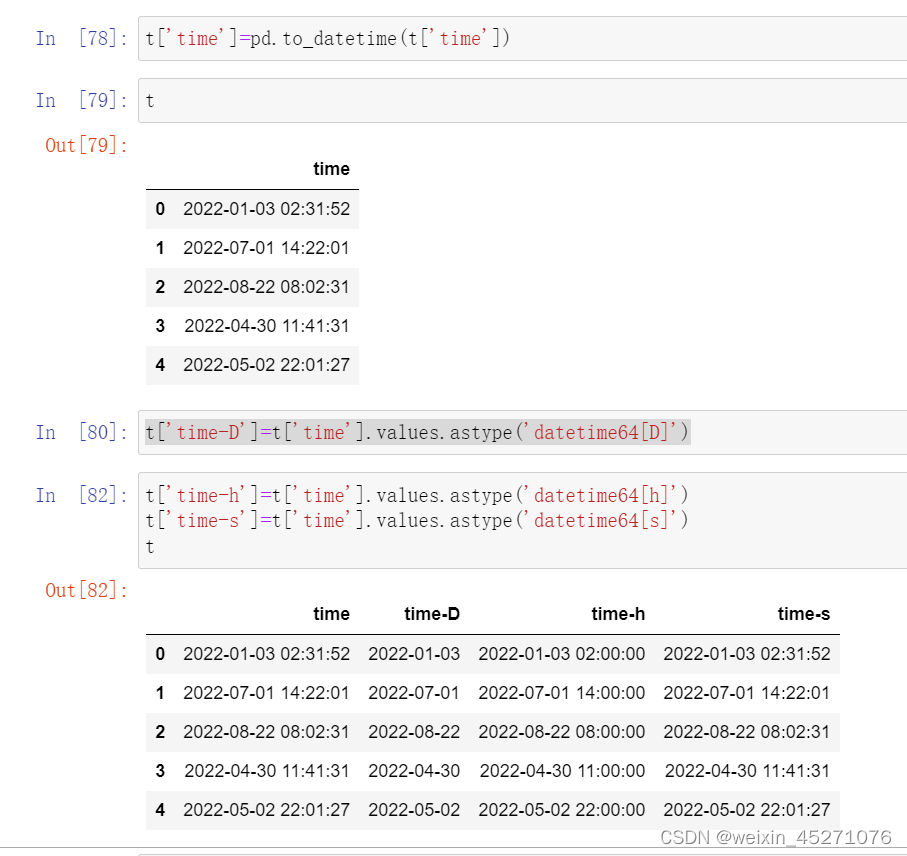
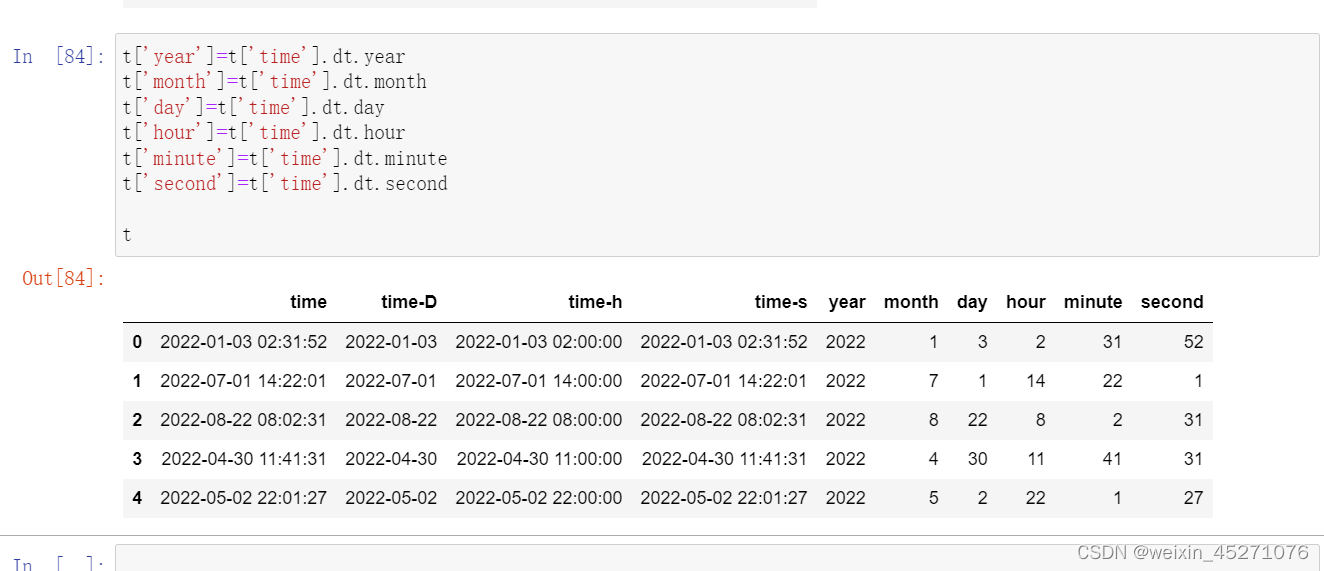
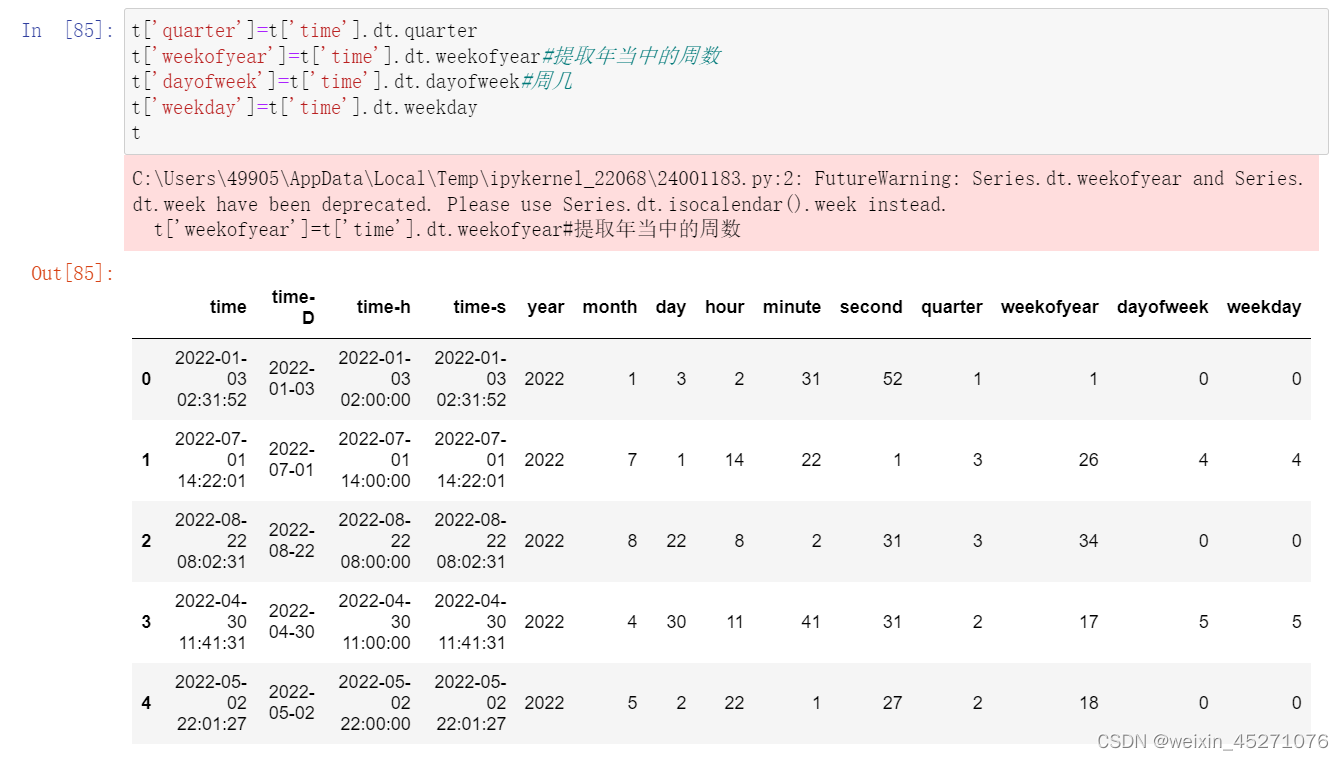
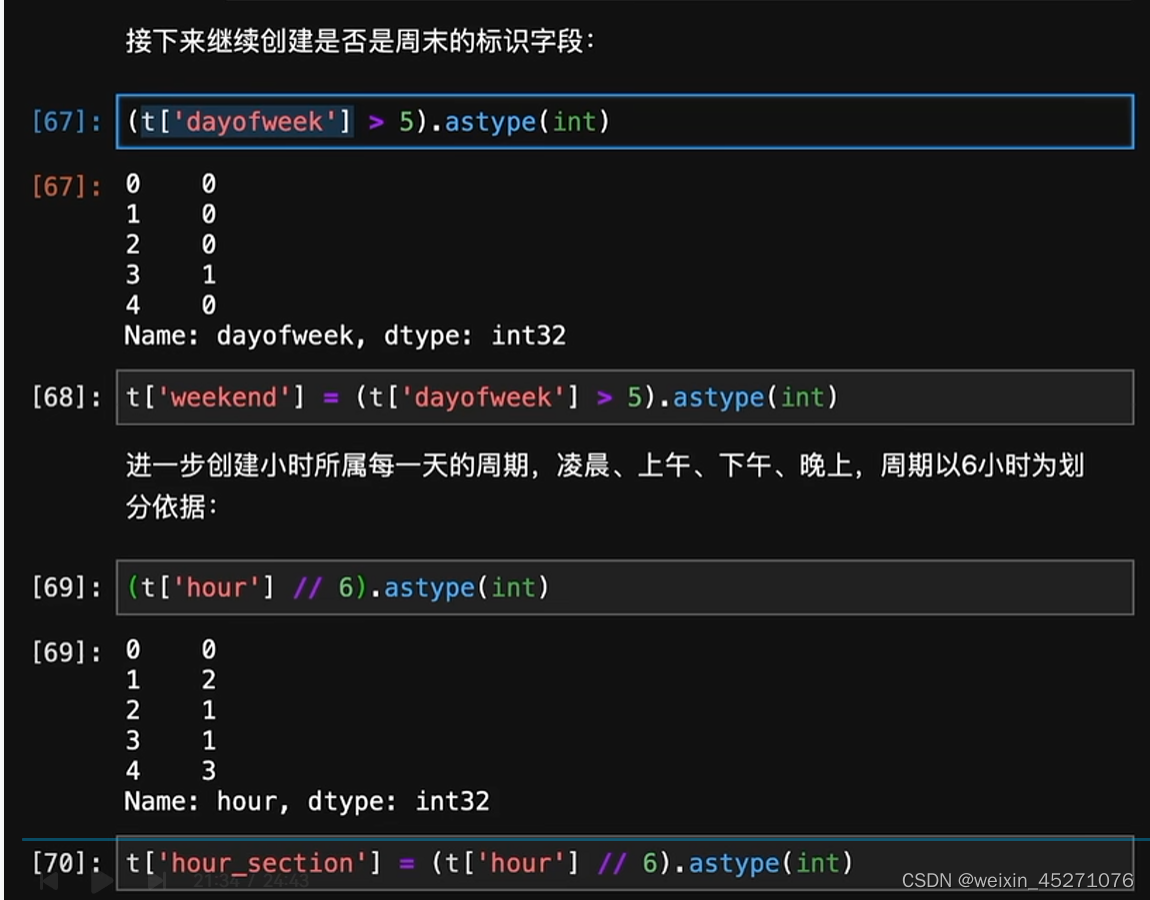
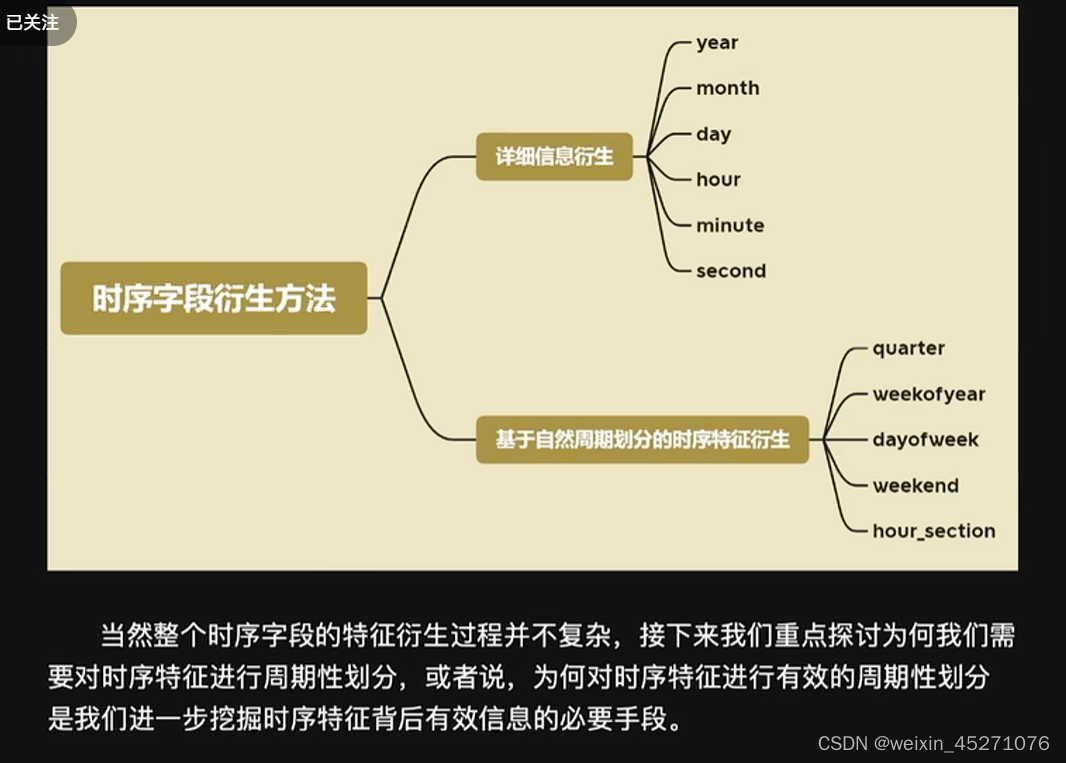
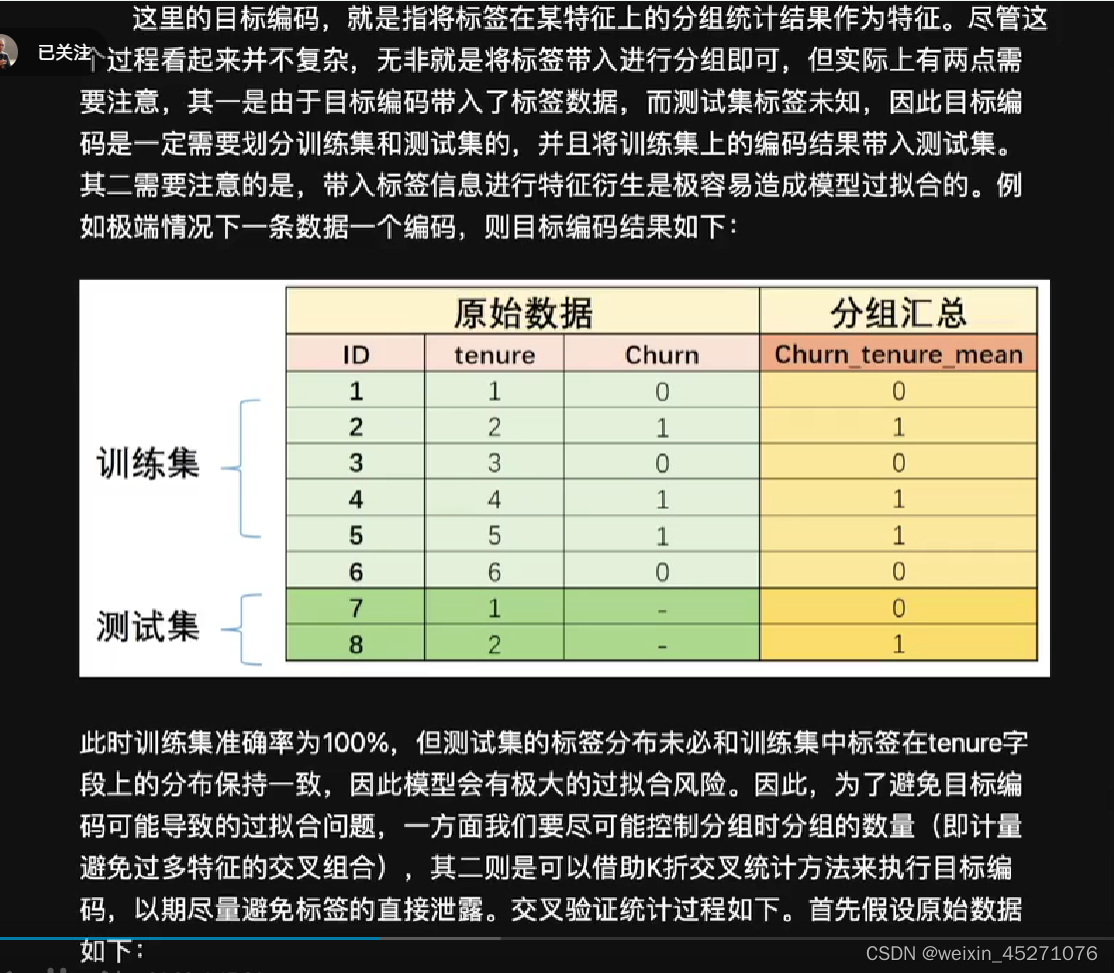
时序特征处理


















 9775
9775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









