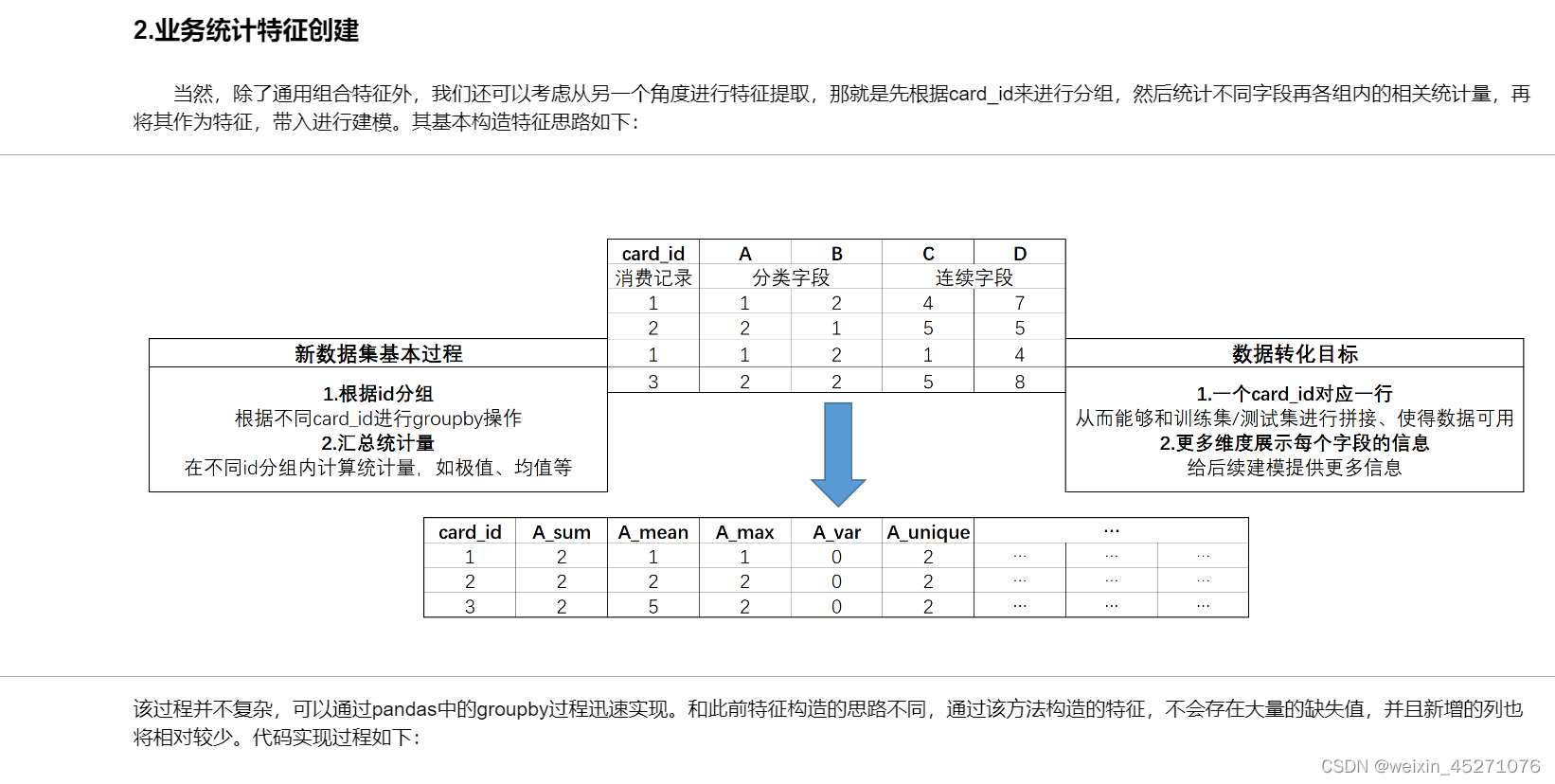
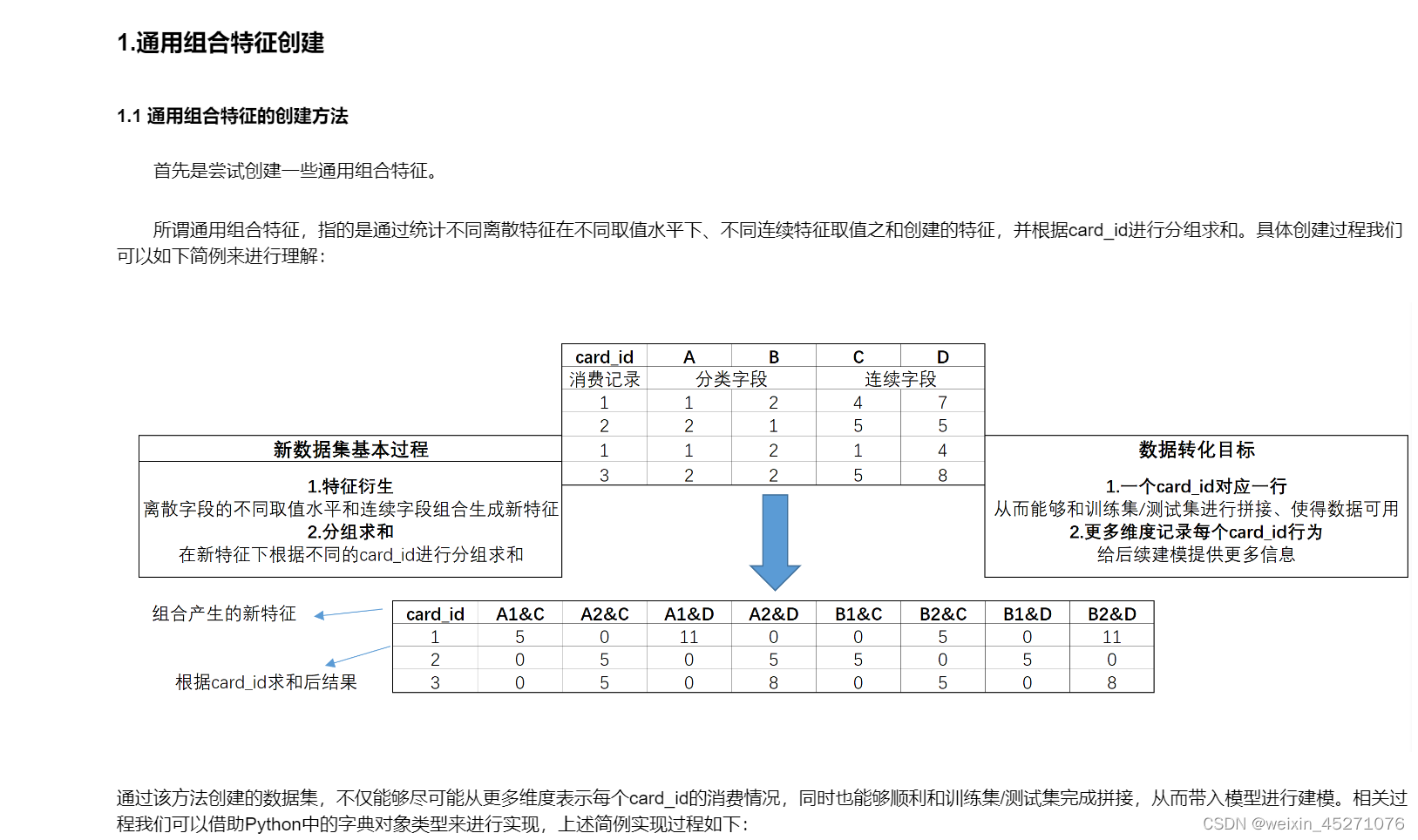
# 创建空字典
aggs = {}
# 连续/离散字段统计量提取范围
for col in numeric_cols:
aggs[col] = ['nunique', 'mean', 'min', 'max','var','skew', 'sum']
for col in categorical_cols:
aggs[col] = ['nunique']
aggs['card_id'] = ['size', 'count']
cols = ['card_id']
# 借助groupby实现统计量计算
for key in aggs.keys():
cols.extend([key+'_'+stat for stat in aggs[key]])
df = transaction[transaction['month_lag']<0].groupby('card_id').agg(aggs).reset_index()
df.columns = cols[:1] + [co+'_hist' for co in cols[1:]]
df2 = transaction[transaction['month_lag']>=0].groupby('card_id').agg(aggs).reset_index()
df2.columns = cols[:1] + [co+'_new' for co in cols[1:]]
df = pd.merge(df, df2, how='left',on='card_id')
df2 = transaction.groupby('card_id').agg(aggs).reset_index()
df2.columns = cols
df = pd.merge(df, df2, how='left',on='card_id')
del transaction
gc.collect()
# 生成训练集与测试集
train = pd.merge(train, df, how='left', on='card_id')
test = pd.merge(test, df, how='left', on='card_id')
del df
train.to_csv("preprocess/train_groupby.csv", index=False)
test.to_csv("preprocess/test_groupby.csv", index=False)
gc.collect()






















 2290
2290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









