









这里写目录标题
Unet
相关算法
这一部分涉及到的Conv2d二维卷积,,ReLU线性激活,MaxPool2d二维池化,之前文章已提及,这里不在赘述,详情可见上一篇博客
Softmax
归一化到范围0~1,总和为1,常用于将分类网络输出转为对应类别的非线性激活函数,
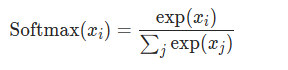
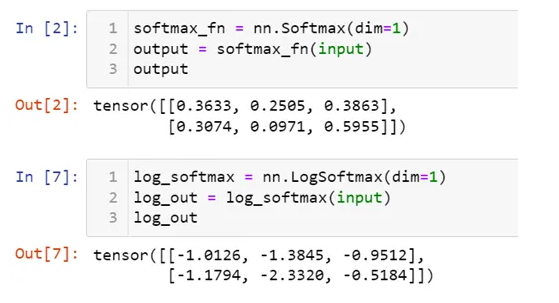
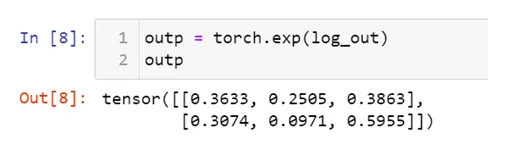
LogSoftmax
从数学本质上看,就是对Softmax做了log运算。这样产生的就是log probability 而不是 standard probability;
那为什么要log probability呢?
log probability计算更快,结果更稳定,虽然对于人的视角来看,计算结果不直观,但对于计算机在计算方面,效率更高。那又为什么效率高,详情可以看,下面几张图片都来自于链接
Softmax VS LogSoftmax
Why are log probabilities useful?
快:Log(a/b)=loga - logb

稳定:
BatchNorm2d
比较特殊,输入必须是4维,其中一定有batch
主要输入参数

作用:
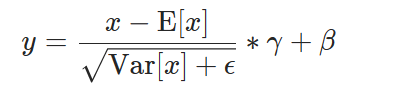
Var是 torch.var
见论文
训练深度神经网络是复杂的,因为在训练过程中,随着前一层的参数变化,每一层输入的分布都会发生变化。这需要更低的学习率和仔细的参数初始化,从而减慢了训练速度,并使训练具有饱和非线性的模型变得非常困难。我们将这种现象称为 internal covariate shift,并通过normalizing layer inputs来解决这个问题。我们的方法通过将规范化作为模型架构的一部分并对每个训练小批量执行规范化来发挥其优势。批量规范化允许我们使用更高的学习率,并且在初始化时不需要那么小心。在某些情况下,它还起到了正则化因子的作用,消除了Dropout(不知道干嘛的看上篇)的必要性。应用于最先进的图像分类模型,Batch Normalization以减少14倍的训练步骤实现了相同的精度,并以显著的优势击败了原始模型。使用批量归一化网络的集合,我们改进了ImageNet分类的最佳发布结果:达到4.9%的前五名验证误差(和4.8%的测试误差),超过了人类评分者的准确性。
Upsample
可以理解为:插值填充
主要步骤
-
上采样插值
-
计算要进行拼接的两个输入参数维度偏差,比如(128,128),(64,64),diff等于64和64
-
将维度小的周围填0(nn.functional.pad),使得输入input1和input2维度一样,然后concat
-
然后双卷积,注意,此处由于拼接了,所以卷积的输入通道,是函数是两个输入的通道之和
-
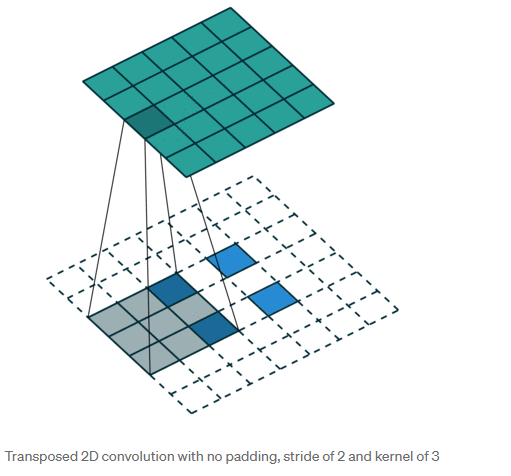
ConvTranspose2d
也是卷积,但是会改变输出shape,也是填充,但不是单单Upsample;等同于Conv2d的计算方式达到Upsample的效果
在Unet网络中,主要与Upsample做区分,具体区别如下
UpSampling2D is just a simple scaling up of the image by using nearest neighbour or bilinear upsampling, so nothing smart. Advantage is it’s cheap.
Conv2DTranspose is a convolution operation whose kernel is learnt (just like normal conv2d operation) while training your model. Using Conv2DTranspose will also upsample its input but the key difference is the model should learn what is the best upsampling for the job.
与Conv的区别见链接
Pad
补足周围元素使维度一致,即填充、膨胀
网络概述
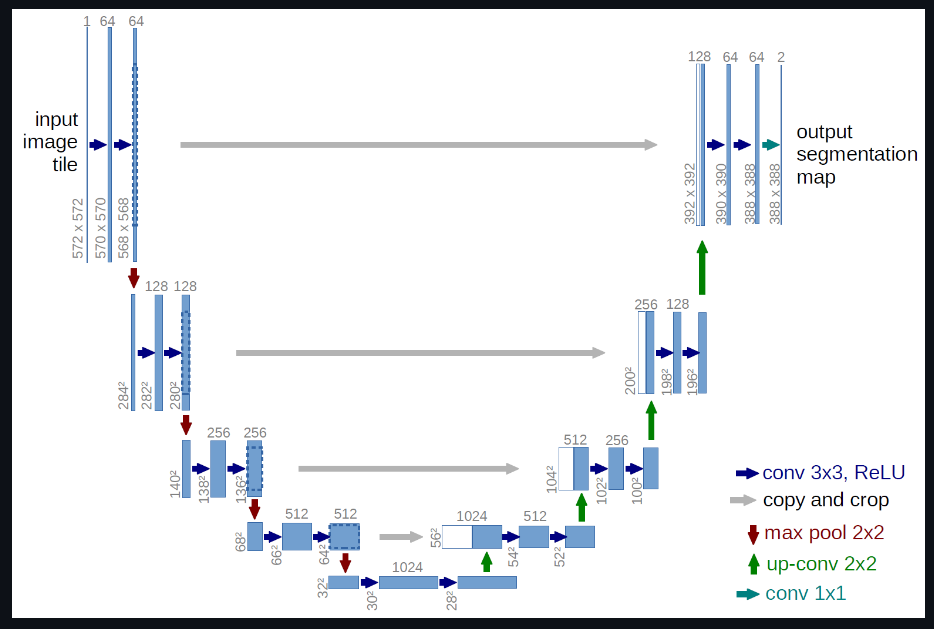
Unet经典网络,无更改;
2015年提出的UNet模型是我们学习语义分割必学的一个优秀模型,它兼具轻量化与高性能,因此通常作为语义分割任务的基线测试模型,至今仍是如此,其优秀程度可见一斑。
UNet从本质上来说也属于一种全卷积神经网络模型,它的取名来源于其架构形状:模型整体呈现"U"形。它的出生是为了解决医疗影像语义分割问题的,但之后几年的发展,也证实了它是语义分割任务中的全能选手,或许这就是优秀网络架构的优异之处。
图像分类有ResNet,语义分割有UNet,目标检测有YOLO,NLP有Transformer,生成式AI有Diffusion Model。
网络详解
由于这里我们进行图像缺陷检测,为了方便数据提取,需要对中间层做一些改动
下采样
主要是起到提取特征的作用
步骤:先进行最大池化,ks=2,然后进行两次卷积单元
下采样由一次池化何两次卷积单元组成
两次卷积单元也叫DoubleConv,由Conv2d,BatchNorm2d,ReLU组成
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
完整下采样单元
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
下采样代表网络中的前四个单元
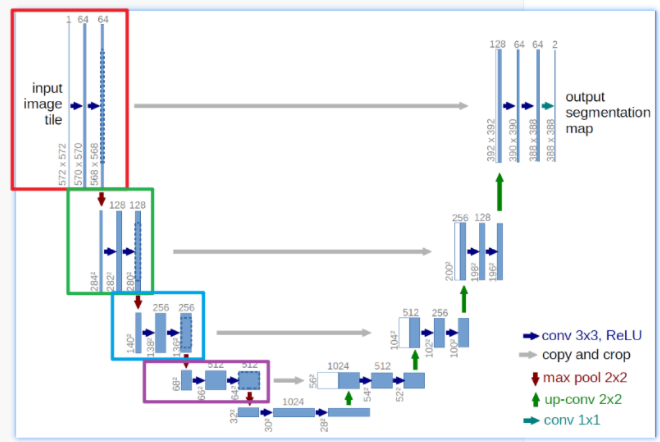
上采样
主要是起到拼接特征的作用
步骤:
-
上采样插值
-
计算要进行拼接的两个输入参数维度偏差,比如(128,128),(64,64),diff等于64和64
-
将维度小的周围填0(nn.functional.pad),使得输入x1和x2维度一样,然后concat
-
然后双卷积,注意,此处由于拼接了,所以卷积的输入通道,是函数是两个输入的通道之和
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
else:
self.up = nn.ConvTranspose2d(in_channels // 2, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = torch.tensor([x2.size()[2] - x1.size()[2]])
diffX = torch.tensor([x2.size()[3] - x1.size()[3]])
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
输出
最简单的一个卷积,输出通道数是类别
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
完整网络代码
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
self.down4 = Down(512, 512)
self.up1 = Up(1024, 256, bilinear)
self.up2 = Up(512, 128, bilinear)
self.up3 = Up(256, 64, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
注意点,Sigmoid VS softmax
在进行本质是二分类的语义分割时,计算probs的归一化函数请用sigmoid;
在进行本质是多分类的语义分割时,请用softmax
原因:
sigmoid何softmax都是非线性激活函数,本质在于

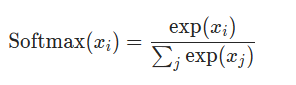
softmax相较于sigmoid,会计算j个类别的百分比,而sigmoid计算的只是1-的百分比
在两类逻辑回归中,使用sigmoid函数预测的概率如下:
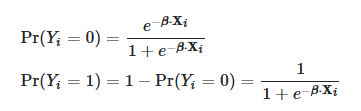
在多类逻辑回归中,K类,预测概率如下,使用softmax函数:
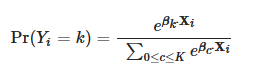
Softmax vs Sigmoid function in Logistic classifier?
简单点说,sigmoid只能表示“是不是这个的概率”,而softmax可以表示每一个可能性的概率

另外
如果在train时,突然把sigmoid换成softmax,或者反过来,在进行推理的时候也要注意,要同步修改,并且你对应标注的label也要修改,因为我们生成label的格式一般都是背景灰度是0,类别1灰度是1,一次类推来生成mask图。shape是【1,h,w】,对应到unet输出,维度并不一样;那么对应loss对比的维度也不一样,所以要做postprocess,同时对应选择sigmoid或者softmax
在网络输出中,【b,c,h,w】,b是batch,c是类别通道(不是图片通道),而你的标注是【b,1,h,w】,在进行普通的softmax后,要对loss进行分析格式化,不然得到的loss是假loss
Multi-label vs. Multi-class Classification: Sigmoid vs. Softmax
具体看下一篇博客















 4615
4615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









