







一、背景概述
本实验在之前两篇文章的基础上设计的MATLAB与FPGA联合仿真平台设计,主要用于在MATLAB于FPGA之前提供收发数据的通道。该实验的应用背景为极化码的编译码流程,极化码的编译码的仿真流程如下:

本实验将把极化码的编译码器放在FPGA上进行实现,其余仿真步骤都将在MATLAB上进行。其中编码器采用Xilinx官方提供的ip核,可在其官网进行申请,连接如下,由于本实验所用开发板资源有限,因此译码器采用FIFO IP核进行替代
根据上文所述,本实验所设计的联合仿真平台如下图所示:
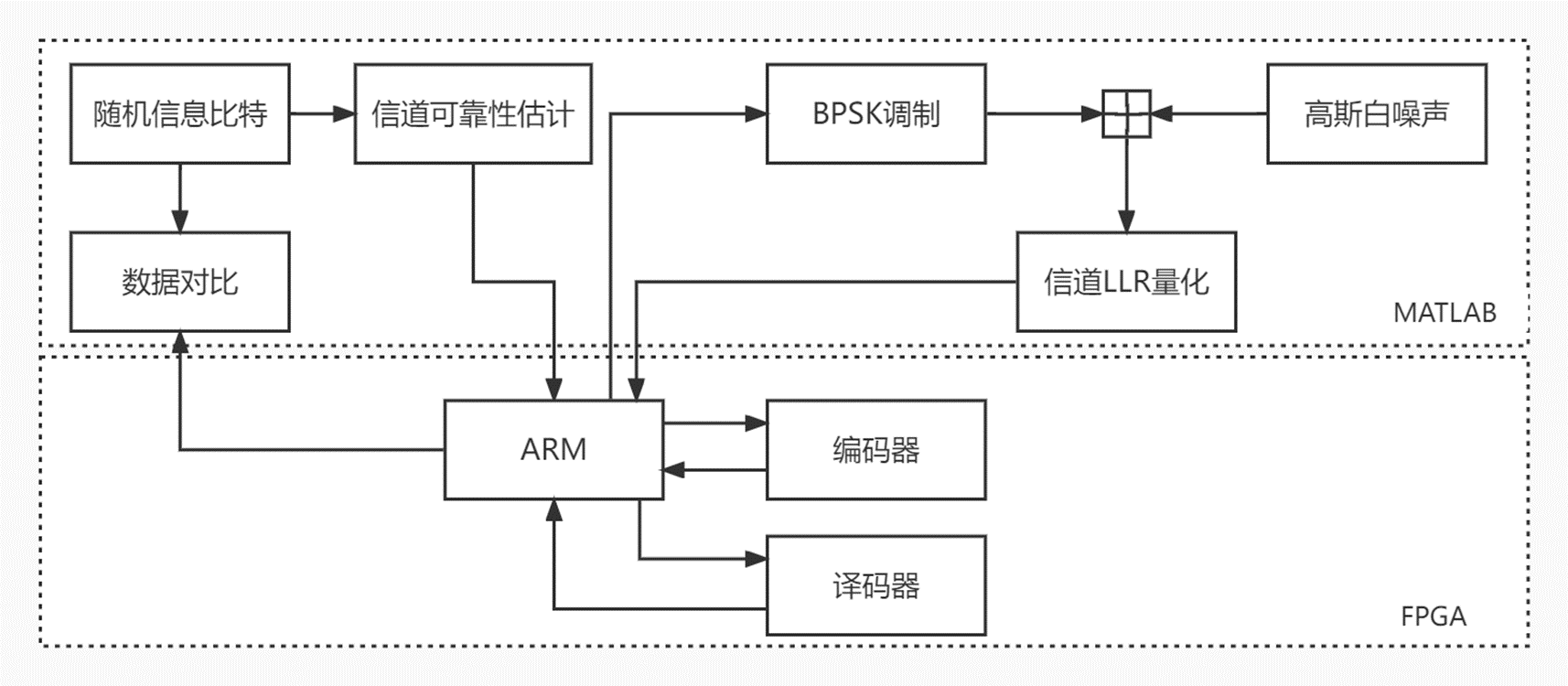
实际上,在上一篇讲述DMA的文章中的SG DMA环通实验便是基于一个完整的数据收发通道,但重点放在了DMA的学习及应用上。本次实验在上文的基础上增加了一条数据链路,对其所涉及的PL、PS及MATLAB端的更改将在下文分别叙述
二、MATLAB与FPGA联合仿真
硬件环境搭建
在之前实验的基础上进行扩展,其中FPGA硬件实现的结构图如下所示:
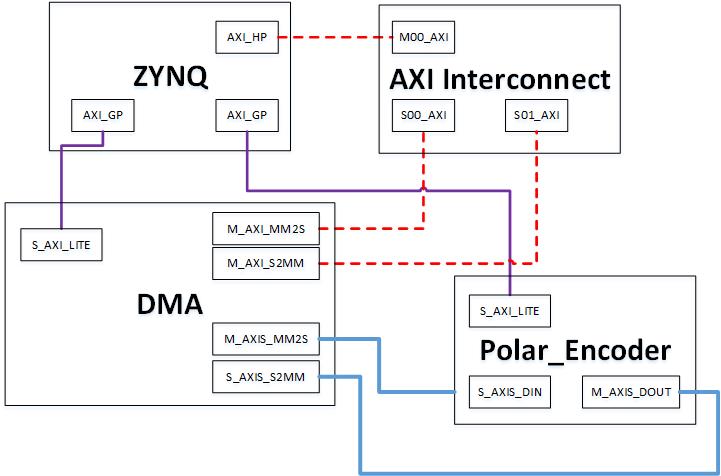
该图仅为译码器的数据链路,关于编码器(FIFO)的数据链路基本相同包括其各个控制、数据通路因此仅利用编码器的链路进行说明。AXI互联模块(AXI Interconnect) 是一种用于连接和管理AXI总线设备的IP核。在FPGA和SoC设计中,AXI Interconnect常用于构建多个AXI总线设备之间的连接,实现数据的传输和交换。DMA部分在上一篇文章中有过详细介绍。图中FPGA端硬件结构可以 大致分为以下几个部分:
- ARM对DMA及FPGA编、译码器的控制链路
紫色连线所示,ZYNQ处理器通过AXI_GP接口连接到DMA与FPGA编、译码器的AXI_LITE接口,读写DMA和FPGA编、译码器内部寄存器。
- DMA对DDR的数据通路
红色虚线所示,DMA通过M_AXI接口(MM2S与S2MM)连接到AXI互联模块的S_AXI接口,再通过互联模块的M00_AXI接口连接到ZYNQ的AXI_HP接口,从而实现DMA对DDR中数据的读写
- DMA对FPGA编译码器的数据通路
蓝色实线所示,DMA通过MM2S与S2MM端口与FPGA编译码器直连来实现对其的数据读写
软件设计
本次实验 对于主函数及涉及DMA部分的代码与之前的并无二致,因此本节仅记录关于ARM端LwIP开发所不同之处及针对该实验的应用背景做出的适应性调整。
首先,该实验是基于LwIP协议进行UDP服务器的开发。Xilinx支持两种操作模式的LwIP API:(1)底层的基于回调(callback)的RAW API;(2)高层顺序模型的SOCKET API。本设计采用的是RAW API,它的最大特点是较低的资源开销以及较低的延迟与更高的吞吐量,适用于对实时性和性能要求较高的应用场景。本文设置板级操作系统(Board Support Package OS)为standalone。LwIP库的主要参数配置如下表所示:
| 参数名 | 说明 | 推荐值 |
| api_mode | LwIP库的操作模式 | RAW_API |
| mem _size | 可用堆内存的总大小(字节) | 131072 |
| memp_n_pbuf | memp结构的pbuf数量 | 16 |
| pbuf_pool_size | pbuf池中的缓冲区数目 | 2048 |
| pbuf_pool_bufsize | Pbuf每个缓冲区的大小 | 2000 |
ARM端UDP服务器的代码流程如下所示:
| 基于网口连接的联合仿真方案中ARM端代码流程 | |
| 1: | LwIP初始化(包括设置板卡的MAC地址,IP地址等) |
| 2: | 调用udp应用函数(包含udp初始化、绑定回调函数(回调函数用于处理MATLAB发来的数据)) |
| 3: | While 1 |
| 4: | if ARM接收到udp客户端发来的待编码数据且编码标志位有效 |
| 5: | ARM写FPGA 编码器内部寄存器,初始化FPGA编码器 |
| 6: | ARM根据BSP提供的DMA接口函数,指示DMA将DDR数据传输给FPGA编码器,开始编码 |
| 7: | ARM根据BSP提供的DMA接口函数,指示DMA将编码结果传输给DDR ,中断标志位 s2mm_flag ← 1 |
| 8: | if s2mm_flag > 0 |
| 9: | udp服务器调用udp发送函数将编码结果发送到MATLAB的udp客户端 |
| 10: | end |
| 11: | end |
| 12: | if ARM接收到udp客户端发来的待译码数据且译码标志位有效 |
| 13: | ARM写FPGA 译码器内部寄存器,初始化FPGA译码器 |
| 14: | ARM根据BSP提供的DMA接口函数,指示DMA_1将DDR数据传输给FPGA译码器,开始 译码 |
| 15: | ARM根据BSP提供的DMA接口函数,指示DMA_1将编码结果传输给DDR ,中断标志位 s2mm_flag ← 1 |
| 16: | if s2mm_flag_1 > 0 |
| 17: | udp服务器调用udp发送函数将译码结果发送到MATLAB的udp客户端 |
| 18: | end |
| 19: | end |
| 20: | endwhlie |
ARM端UDP服务器在与MATLAB端的UDP客户端建立连接后将一直等待接受待编码(译码)数据。ARM在收到一帧数据后,将与极化码FPGA编码器(译码器)完成数据交互,并在编码(译码)完成后将结果返回给MATLAB,再等待接收下一帧待编码(译码)数据,直至完成对所有帧数据的编译码操作。
以下将对涉及LwIP的关键代码进行分析
xpolar enc;
// Define Polar parameters
xpolar_polar_parameters polar_params;
polar_params.N = 1024;
polar_params.K = 512;
polar_params.AUGMENT = AUGMENT_BOTH;
polar_params.CRC_SEL = CRC_SEL_11;
polar_params.ITLV = 0;
polar_params.CRC_INIT = 0;
xpolar_Initialize(&enc,XPAR_POLAR_ENC_DEVICE_ID);//Initialize polar
// Setup Polar Encoder/Decoder
// AXI_WIDTH
// o DIN_WORDS applies once per codeword
// o DOUT_WORDS applies once per codeword
xpolar_set_CORE_AXIS_WIDTH(&enc, 0x00000000);
// Interrupt Enable Register
// o Enables all (DIN, DIN_WORDS and DOUT_WORDS) tlast missing and unexpected interrupts
xpolar_set_CORE_IER(&enc, 0x0000007F);
// ECC Interrupt Enable Register
// o Enables all ECC interrupts
xpolar_set_CORE_ECC_IER(&enc, 0x00000FFF);
// Enable FECs
// o Enable all channesls
xpolar_set_CORE_AXIS_ENABLE(&enc,63);
/* start the application (web server, rxtest, txtest, etc..) */
start_udp(8080);
while (1) {
xemacif_input(echo_netif);
/* Wait for times */
if(Enc_dataTransfer_flag > 0)
{
// Define BA_TABLE of Polar parameters
u32 COMPRESSED_LENGTH = polar_params.N / 16;
u32 COMPRESSED_BA_TABLE[COMPRESSED_LENGTH];
u32 USER_DEFINED_BA_TABLE[HARD_BIT_NUM];
for (int i = 0; i < HARD_BIT_NUM; i++) {
USER_DEFINED_BA_TABLE[i] = (u32)Position_Matrix[i];
}
xpolar_compress_bit_allocation_table(USER_DEFINED_BA_TABLE, COMPRESSED_BA_TABLE, COMPRESSED_LENGTH);
for (int i = 0; i < COMPRESSED_LENGTH; i++) {
polar_params.BA_TABLE[i] = COMPRESSED_BA_TABLE[i];
}
xpolar_add_polar_params(&enc, &polar_params);
// xil_printf("PREPOS\n");
memcpy(DmaTxBuffer, Compressed_Hard_Bit, COMPRESSED_SIZE) ;
Xil_DCacheFlushRange((UINTPTR)DmaTxBuffer, COMPRESSED_SIZE);
/* Create BD and Start*/
CreateBdChain(BdChainBuffer, BD_COUNT, COMPRESSED_SIZE, (unsigned char*)DmaTxBuffer, TXPATH);//Create BD chain
XAxiDma_TX(BdChainBuffer, BD_COUNT, &AxiDma);//DMA_MM2S
/* Wait for times */
usleep(500);
Xil_DCacheFlushRange((UINTPTR)DmaRxBuffer, COMPRESSED_SIZE);
CreateBdChain(BdChainBuffer, BD_COUNT, COMPRESSED_SIZE, (unsigned char*)DmaRxBuffer, RXPATH);//Create BD chain
XAxiDma_RX(BdChainBuffer, BD_COUNT, &AxiDma);//DMA_MM2S
/* Check current frame length */
if (FrameLengthCurr > 0)
{
/* Check if DMA completed */
if (s2mm_flag >= 0)
{
int udp_len;
Xil_DCacheInvalidateRange((u32) DmaRxBuffer, FrameLengthCurr);
for (int i = 0; i < HARD_BIT_NUM; i++) {
unsigned char expanded_data = 0;
int expanded_index = i;
//int byte_index = i >> 3;
int byte_index = i / 8;
int bit_index = i % 8;
expanded_data |= ((DmaRxBuffer[byte_index] >> (7 - bit_index)) & 1);
DmaBufferTmp[expanded_index] = expanded_data;
}
fg = 0;
/* Separate data into package */
for (int i = 0; i < FrameLengthCurr; i += 1024)
{
fg = fg +1 ;
char buf[2] = {0};
buf[0] = (fg >> 8 & 0xFF);
buf[1] = fg & 0xFF;
memcpy((unsigned char*)(TargetHeader + 5),&buf,2);
if ((i + 1024) > FrameLengthCurr)
udp_len = FrameLengthCurr - i;
else
udp_len = 1024;
send_adc_data((const char *) DmaBufferTmp + i, udp_len);
}
/* Clear DMA flag and frame length */
s2mm_flag = -1;
FrameLengthCurr = 0;
}
}
Enc_dataTransfer_flag = 0;
}
if(Dec_dataTransfer_flag > 0){
memcpy(DmaTxBuffer_1, LLRs_Buffer, LLRs_NUM) ;
Xil_DCacheFlushRange((UINTPTR)DmaTxBuffer_1, LLRs_NUM);
/* Create BD and Start*/
CreateBdChain(BdChainBuffer_1, BD_COUNT, LLRs_NUM, (unsigned char*)DmaTxBuffer_1, TXPATH);//Create BD chain
XAxiDma_TX(BdChainBuffer_1, BD_COUNT, &AxiDma_1);//DMA_MM2S
/* Wait for times */
usleep(500);
Xil_DCacheInvalidateRange((UINTPTR)DmaRxBuffer_1, LLRs_NUM);
CreateBdChain(BdChainBuffer_1, BD_COUNT, LLRs_NUM, (unsigned char*)DmaRxBuffer_1, RXPATH);//Create BD chain
XAxiDma_RX(BdChainBuffer_1, BD_COUNT, &AxiDma_1);//DMA_MM2S
if (FrameLengthCurr_1 > 0)
{
/* Check if DMA completed */
if (s2mm_flag_1 >= 0)
{
int udp_len;
Xil_DCacheInvalidateRange((u32) DmaRxBuffer_1, FrameLengthCurr_1);
for(int i = 0 ; i < LLRs_NUM ; i++)
{
DmaBufferTmp_1[i] = (DmaRxBuffer_1[i]) ;
}
fg = 0;
/* Separate data into package */
for (int i = 0; i < FrameLengthCurr_1; i += 1024)
{
fg = fg +1 ;
char buf[2] = {0};
buf[0] = (fg >> 8 & 0xFF);
buf[1] = fg & 0xFF;
memcpy((unsigned char*)(TargetHeader + 5),&buf,2);
if ((i + 1024) > FrameLengthCurr_1)
udp_len = FrameLengthCurr_1 - i;
else
udp_len = 1024;
send_adc_data((const char *) DmaBufferTmp_1 + i, udp_len);
}
/* Clear DMA flag and frame length */
s2mm_flag_1 = -1;
FrameLengthCurr_1 = 0;
}
}
Dec_dataTransfer_flag = 0;
}
}该段代码中,首先对编码器的各个参数进行了设置,并初始化编码器,对于其各个参数的意义可以参考pg280。(由于编码器参数包括信道可靠性估计得来的位置矩阵,即参数中的BA_TABLE,而该位置矩阵需要上位机通过udp发送至板卡,因此关于编码器初始化的部分置于lwip_app()该函数当中)
(1)当上位机将待编码数据发送至板卡时Enc_dataTransfer_flag >0,启动编码器的数据传输链路。需要说明的是,由于编码器是按位编码,而板卡接收上位机发来的数据并以char类型进行保存,因此需要对存储的数据进行“压缩”,仅保留有效数据位(该部分代码体现在udp接收函数当中)。此外将板卡接收的位置矩阵Position_Matrix赋值给USER_DEFINED_BA_TABLE,并通过相关函数将参数写入polar编码器的寄存器中。随后启动DMA传输,当DMA将编码后的数据发送至板卡后发出中断信号,中断信号s2mm_flag >= 0(关于DMA及中断处理的部分可参考上一篇文章)告知CPU DMA传输数据结束,启动udp发送函数将编码完成的码字比特发包发送至上位机并在发送结束后将中断标志位s2mm_flag置为-1,FrameLengthCurr 、Enc_dataTransfer_flag 置0,跳出if语句;
(2)将上位机将板卡发来的码字比特经过BPSK调制、加噪、LLR计算后得到的待译码数据发送至板卡时Dec_dataTransfer_flag>0,启动译码器的传输链路。同样的,启动DMA传输并在传输结束后发出中断,使得中断标志位s2mm_flag_1 >=0,启动udp发送函数将译码结果发送至上位机并在发送结束后将中断标志位s2mm_flag_1置为-1,FrameLengthCurr _1、Dec_dataTransfer_flag 置0跳出if语句;
由于增加了一条数据链路,因此相较于之前的实验,对udp接收函数udp_recive进行了简化,其余的改动主要在于对发来的待编码数据先进行一个“数据压缩”的操作,保证FPGA端编码器按位编码。
void udp_recive(void *arg, struct udp_pcb *pcb, struct pbuf *p_rx,
const ip_addr_t *addr, u16_t port) {
char *pData;
if (p_rx != NULL)
{
pData = (char *) p_rx->payload;
if (p_rx->len >= 5) {
if (pData[4] == 0x01)
{
//specialPointer = ((void*)pData + 5);
for (int i = 0; i < HARD_BIT_NUM; i++) {
Hard_Bit_Buffer[i] = (unsigned char)(*(pData + 5 + i));
Position_Matrix[i] = (unsigned char)(*(pData + 1029 + i));
}
// Compress data and retain only valid data
for (int i = 0; i < COMPRESSED_SIZE; i++) {
unsigned char compressed_byte = 0;
for (int j = 0; j < 8; j++) {
int bit_index = i * 8 + j;
if (bit_index < HARD_BIT_NUM) {
compressed_byte |= (Hard_Bit_Buffer[bit_index] << (7 - j));
}
}
Compressed_Hard_Bit[i] = compressed_byte;
//free(Hard_Bit_Buffer);
}
Enc_dataTransfer_flag = pData[4];
TargetHeader[0] = pData[0] | 1;
target_addr.addr = addr->addr;
FrameLengthCurr = (FrameLengthCurr == 0)? HARD_BIT_NUM :FrameLengthCurr;
memset(pData , 0 , p_rx->len);
}
else if (pData[4] == 0x02)
{
for (int i = 0; i < LLRs_NUM; i++) {
LLRs_Buffer[i] = (unsigned char)(*(pData + 5 + i));
}
Dec_dataTransfer_flag = pData[4];
target_addr.addr = addr->addr;
FrameLengthCurr_1 = (FrameLengthCurr_1 == 0)? LLRs_NUM:FrameLengthCurr_1;
memset(pData , 0 , p_rx->len);
}
}
pbuf_free(p_rx);
}
}MATLAB端程序开发
clc;
clear;
close all;
warning off
%-------------------基本参数设置-------------------%
N=1024;%编码比特长度 必须得为2的指数次方
K=512;%信息比特长度
frame=100;%帧数100,又即迭代次数,
EbN0=1;%信噪比
sigma=sqrt(N/(2*10^(EbN0/10)*(K)));%高斯噪声标准差
[ERR,I,P] = Gaussian_approximation(N,K,EbN0);
%p=logical(P);%yyh:若继续改为逻辑值,位置矩阵中仍为0 1且不符合udp传输的数据类型
h=zeros(frame,K);
y = zeros(1,1029);%存储LLR值及LLR_header
uyima=zeros(frame,K); %最后估计的信息比特
%-------------------新建udp连接-------------------%
u1 = '192.168.1.42'; %Local IP,本地主机IP地址
port1 = 8080;%监听所有发到8080端口的消息;
u2 = '192.168.1.10';%远程主机IP地址
port2 = 8080;%监听所有发到8080端口的消息;
u = udpport("LocalHost","192.168.1.42","LocalPort",8080,"EnablePortSharing",true);%本地IP及端口,设置端口共享
u.Timeout = 30 ;%设置溢出时间,单位s
u.EnableBroadcast = true ;%是否可以收发广播包
u.OutputDatagramSize = 65507;
for zs=1:frame %loop variables
h(zs,:)=genSrc(K);
j=0;
hard_bit=zeros(1,N);
for i=1:N %我:
if(P(i)==2)
j=j+1;
hard_bit(i)=h(zs,j);
else
hard_bit(i)=0;
end
end
hard_bit_header = [0x28,0x00,0x01,0x00,0x01];
polar_enc = horzcat(hard_bit_header,hard_bit,P);
%--------------------发送待编码比特--------------------%
write(u, polar_enc, "uint8", "192.168.1.10", 8080);
codeword_bit = read(u,1031,"uint8");
codeword_bit = codeword_bit(8:1031);%利用切片操作符提取后1024位码字比特
x1=bpsk(codeword_bit,N);
y=awgn(x1,N,sigma);
LLR_matrix=2.*y./(sigma^2); %底层信道均值
LLR_header = [0x28,0x00,0x01,0x00,0x02];
y = horzcat(LLR_header,LLR_matrix);
%--------------------发送待译码LLR值--------------------%
write(u,y,"uint8","192.168.1.10",8080);
uk = read(u,1031,"uint8");
uk = uk(8:1031);
uyi(zs,:) = uk(1,1:K);
end本次实验的matlab程序在前实验的基础上,加入了关于极化码编译码流程的基础参数设置, 以及编译码相关函数如生成随机信息比特genSrc(),bpsk调制函数bpsk(),加噪awgn()等,并且为确保译码后所得误码率的可靠性设置了frame帧循环,由于本实验开发板资源有限,利用FIFO IP核替代了译码器,因此省略了误码率计算等后续步骤。
MATLAB端的代码流程如下所示:
| 基于网口连接的联合仿真方案中MATLAB代码流程 | |
| 输入:码长N,信息比特长度K,信息比特索引P,信噪比EbN0,帧长度frame | |
| 1: | 调用udpport函数建立UDP客户端 |
| 2: | for i = 1 to frame do |
| 3: | 随机生成N*K个信息比特,并通过高斯近似法得到信息比特索引P,调用udp发送函数将上述二者发送至UDP服务器,并接受编码结果codeword_bit |
| 4: | 对编码结果codeword_bit进行BPSK调制并加入高斯白噪声得到接受数据 |
| 5: | 由接收数据 |
| 6: | 调用udp发送函数将LLR值发送至UDP服务器并接受译码结果uyi |
| 7: | end for |
| 8: | 结束udp连接 |
| 9: | 计算 |
| 输出:误码率BER | |
三、下载验证
对上述设计进行上板验证,打开putty观察打印信息,打开wireshark观察抓包的结果,过滤规则为ip.addr ==192.168.1.10
下载程序到开发板,可以观察到打印信息如下:
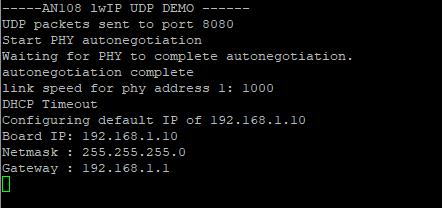
MATLAB端运行程序,建立UDP客户端
一次传输,wireshark的抓包情况如下
由于编码器相关数据polar_enc的构成为polar_enc=头+待编码比特+位置矩阵,共2053字节,超过了以太网MTU会发生分片

需要注意的是,本次实验中无法完成frame帧操作,因为在第一次发送待编码比特时以及传输几次后,板卡没有正常回传数据,经调试发现DMA没有正常发出中断。
通过Debug的方式,观察内存中的数据可以发现,polar ip在DMA发来数据时没有完成编码操作
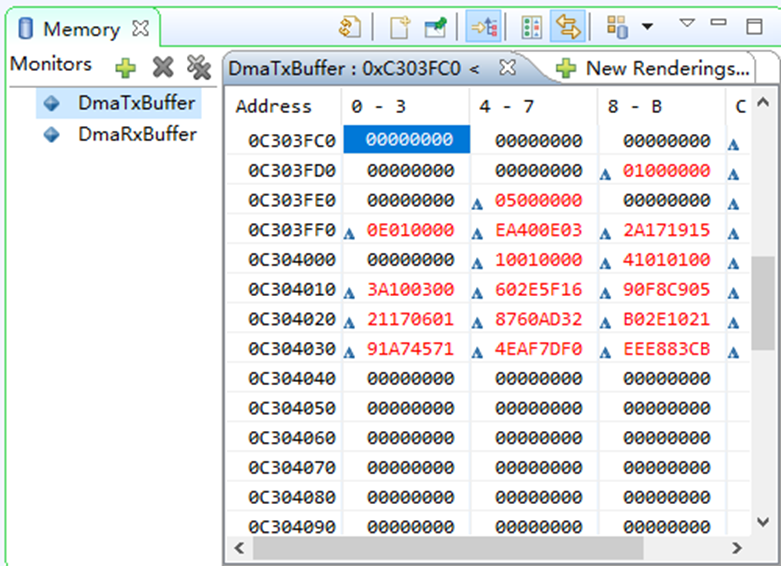
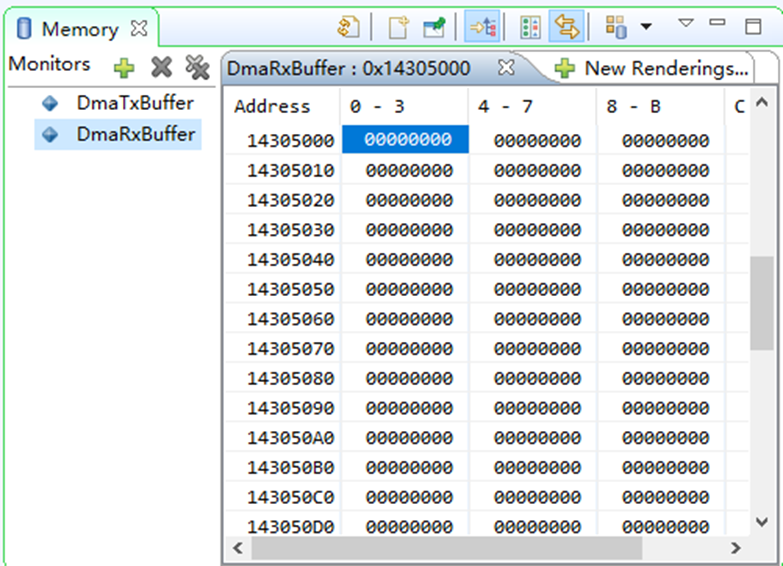
在中断处理函数及调用DMA传输函数将数据从polar ip核处搬移至DDR后添加输出语句,输出此时中断标志位s2mm_flag
观察putty中的打印信息如下,图中红框所示均为非正常传输现象:
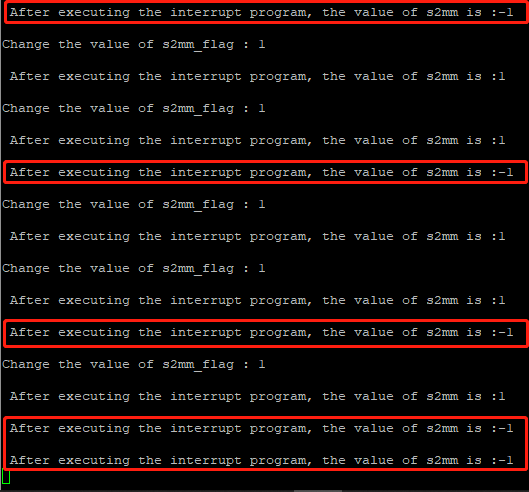
总结:可能是polar ip核的配置方式问题?由于本次实验仅申请了polar ip核,并没有深入的了解,所以问题暂存















 7966
7966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









