







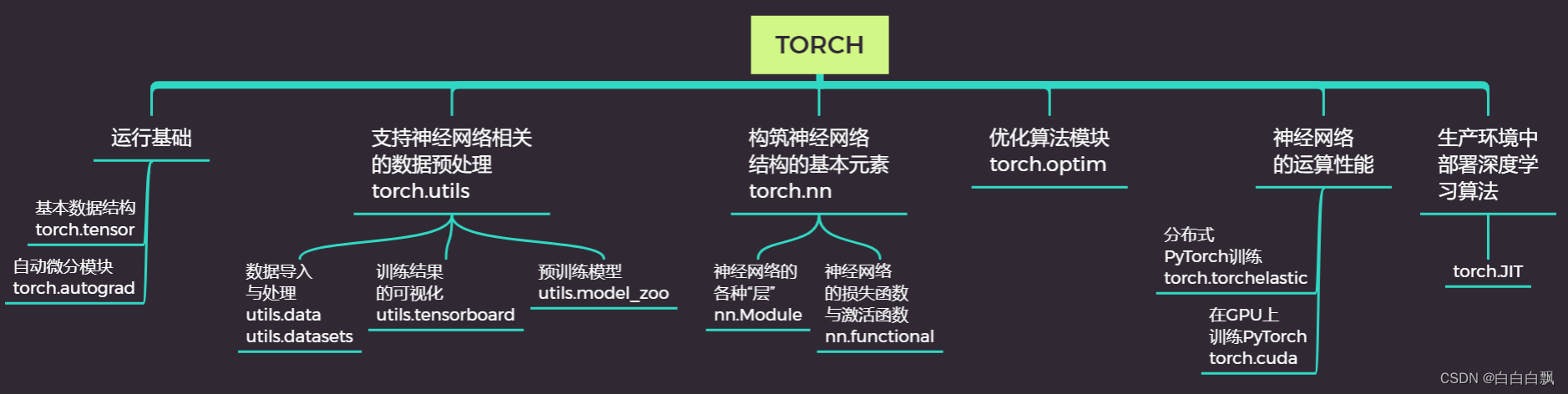
一、单层回归网络:线性回归
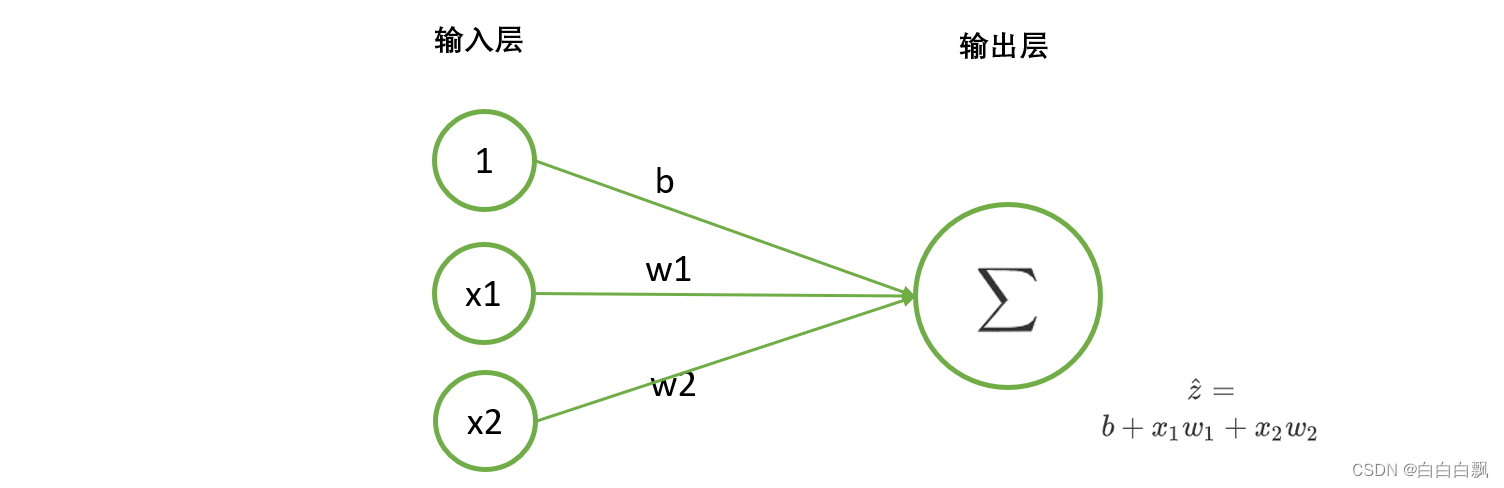
1. tensor手动实现单层回归神经网络的正向传播
# tensor手动实现单层回归神经网络的正向传播
import torch
from torch.nn import functional as F
X = torch.tensor([[1,0,0],[1,1,0],[1,0,1],[1,1,1]], dtype = torch.float32) # 特征张量
w = torch.tensor([-0.2, 0.15, 0.15]) # 定义常量b和权重w,即b为-0.2,w为(0.15, 0.15)
z = torch.tensor([-0.2, -0.05, -0.05, 0.1]) # 标签张量
# 定义线性回归计算的函数
def LinearR(X,w):
zhat = torch.mv(X,w) # 预测值z, 矩阵X与向量w相乘
return zhat
zhat = LinearR(X, w)
zhat
注意踩坑:
- 标签和特征类型:PyTorch中的许多函数都不接受浮点型的分类标签,但也有许多函数要求真实标签的类型必须与预测值的类型一致,因此标签的类型定义总是一个容易踩坑的地方。通常来说,我们还是回将标签定义为float32,如果在函数运行时报错,要求整形,我们再使用.long()方法将其转换为整型。
- 标签维度:另一个非常容易踩坑的地方是,PyTorch中许多函数不接受一维张量但同时也有许多函数不接受二维标签,因此我们在生成标签时,可以默认生成二维标签,若函数报错说不能接受二维标签,我们再使用view()函数将其调整为一维。
2. torch.nn.Linear实现单层回归神经网络的正向传播
# torch.nn.Linear实现单层回归神经网络的正向传播
import torch
X = torch.tensor([[0,0],[0,1],[1,0],[1,1]], dtype= torch.float32)
output = torch.nn.Linear(2,1) # 随机分配的参数w,b
zhat = output(X)
zhat
二、二分类神经网络:逻辑回归
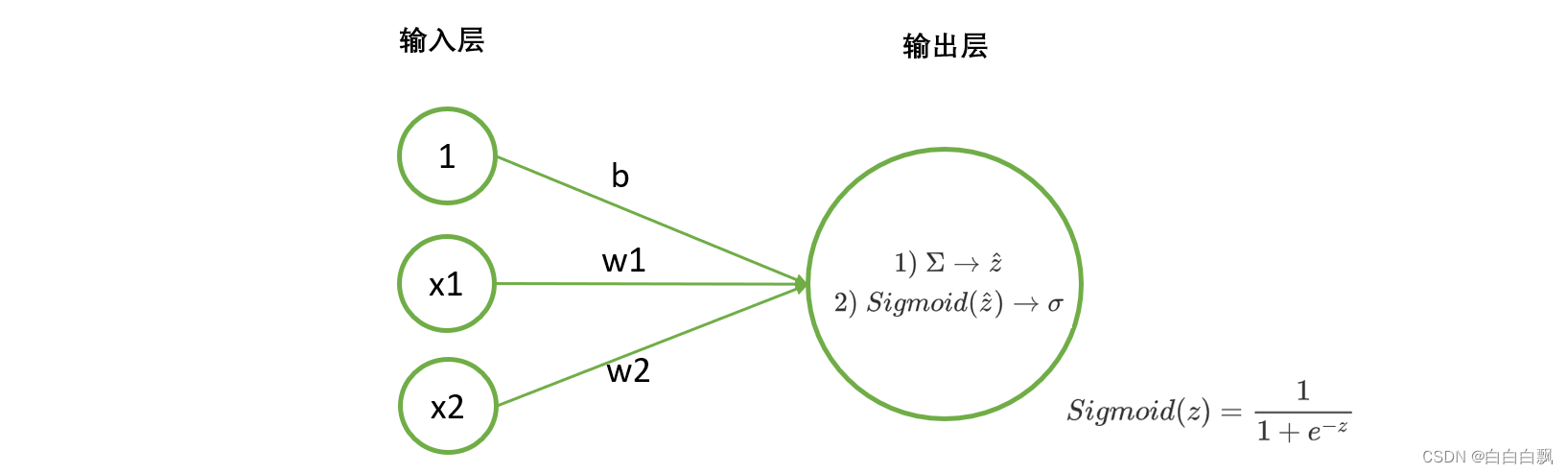
1. tensor实现二分类神经网络的正向传播
要拟合这组数据,只需要在刚才我们写好的代码后面加上sigmoid函数以及阈值处理后的变化。
# tensor实现二分类神经网络的正向传播
import torch
X = torch.tensor([[1,0,0],[1,1,0],[1,0,1],[1,1,1]], dtype = torch.float32)
andgate = torch.tensor([[0],[0],[0],[1]], dtype = torch.float32) #保险起见,生成二维的、float32类型的标签
w = torch.tensor([-0.2,0.15,0.15], dtype = torch.float32)
def LogisticR(X,w):
zhat = torch.mv(X,w)
sigma = torch.sigmoid(zhat) # 非线性函数处理
#sigma = 1/(1+torch.exp(-zhat))
andhat = torch.tensor([int(x) for x in sigma >= 0.5], dtype = torch.float32) # 二分类,阈值0.5
return sigma, andhat
sigma, andhat = LogisticR(X,w)
sigma, andhat, andgate.flatten()
2. torch.functional实现单层二分类神经网络的正向传播
# torch.functional实现单层二分类神经网络的正向传播
import torch
from torch.nn import functional as F
X = torch.tensor([[0,0],[1,0],[0,1],[1,1]], dtype = torch.float32)
dense = torch.nn.Linear(2,1) # 实例化线性层
zhat = dense(X)
sigma = F.sigmoid(zhat) # sigmod函数,主流
# sigma = torch.sign(zhat) # sign函数
# sigma = F.relu(zhat) # Relu函数,主流
# sigma = torch.tanh(zhat) # tanh函数
y = [int(x) for x in sigma > 0.5]
三、多分类神经网络:Softmax回归
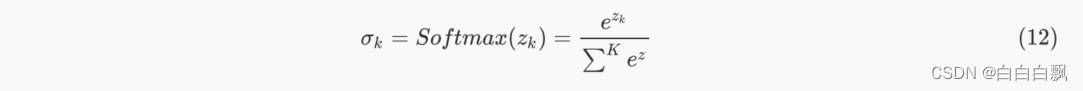
1. Softmax函数
Softmax函数是深度学习基础中的基础,它是神经网络进行多分类时,默认放在输出层中处理数据的函
数。
#假设三个输出层神经元得到的z分别是10,9,5
# 手动实现softmax
z = torch.tensor([10,9,5], dtype=torch.float32)
torch.exp(z) / torch.sum(torch.exp(z)) # 手动实现softmax的运算
# 函数实现softmax
z = torch.tensor([10,9,5], dtype=torch.float32)
torch.softmax(z,0)
2. sotfmax函数的dim含义
# softmax的dim含义
s = torch.tensor(torch.arange(1,25).reshape(2,3,4), dtype=torch.float32)
sd0 = torch.softmax(s,dim=0) # 按0维分类别, 2类, [:,i,j].sum()为1
sd1 = torch.softmax(s,dim=1) # 按1维分类别, 3类, [i,:,j].sum()为1
sd2 = torch.softmax(s,dim=2) # 按2维分类别, 4类, [i,j,:].sum()为1
sd0, sd1, sd2
sd0[:,1,2].sum(), sd1[1,:,2].sum(),sd2[1,2,:].sum()
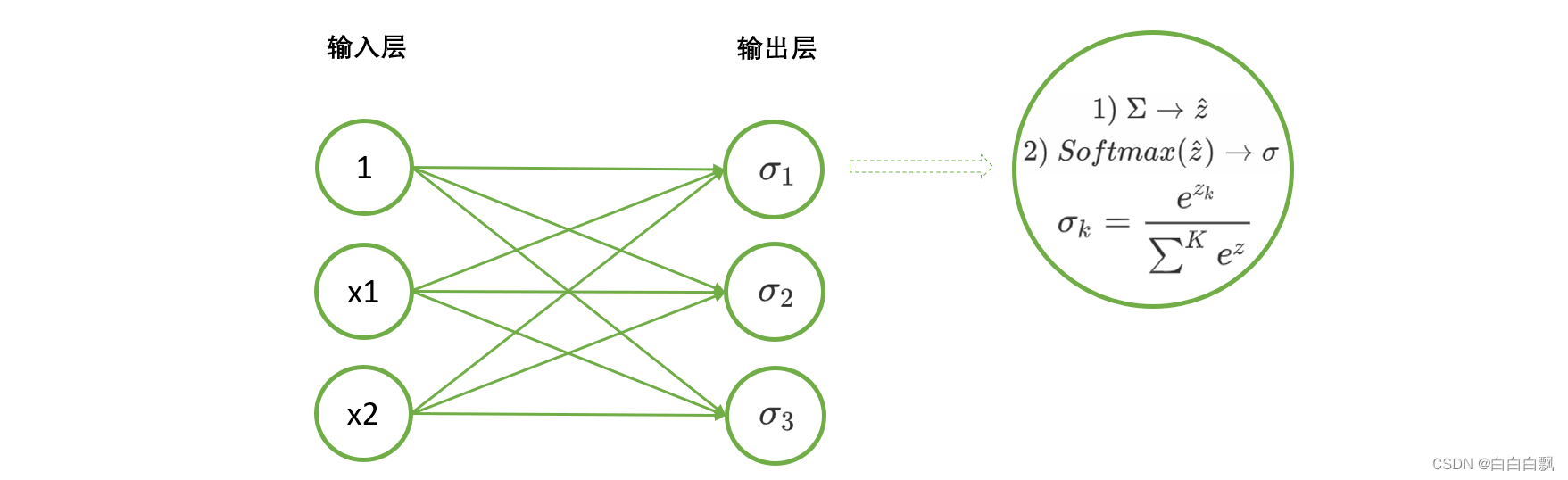
3. 使用nn.Linear与functional实现多分类神经网络的正向传播
# 使用nn.Linear与functional实现多分类神经网络的正向传播
import torch
from torch.nn import functional as F
X = torch.tensor([[0,0],[0,1],[1,0],[1,1]],dtype= torch.float32)
dense = torch.nn.Linear(2,3)
zhat = dense(X) # (4, 3)
softmax1 = F.softmax(zhat, dim =1) # 对1维, 加和为1
softmax1
四、激活函数
1. sigmoid函数
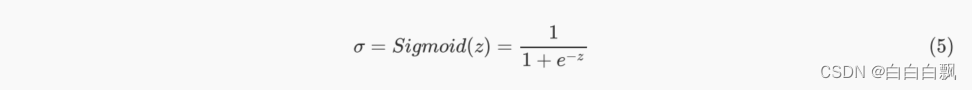
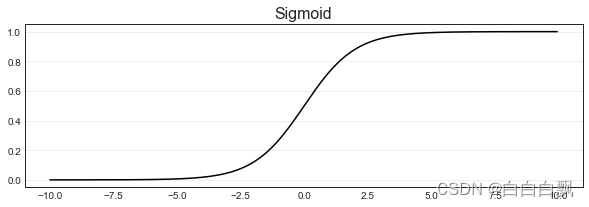
Sigmoid函数是一个S型的函数,从图像上就可以看出,这个函数的性质相当特别。当自变量z趋近正无穷时,因变量σ趋近于1,而当z趋近负无穷时,σ趋近于0,这使得sigmoid函数能够将任何实数映射到(0,1)区间。同时,Sigmoid的导数在z=0点时最大(这一点的斜率最大),所以它可以快速将数据从 的附近排开,让数据点到远离自变量取0的地方去。这样的性质,让sigmoid函数拥有将连续性变量z转化为离散型变量σ的力量,这也就是化回归算法为分类算法的力量。
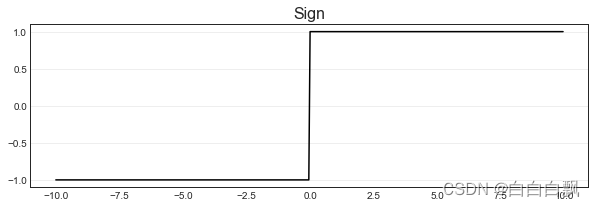
2. sign符号函数(阶跃函数)
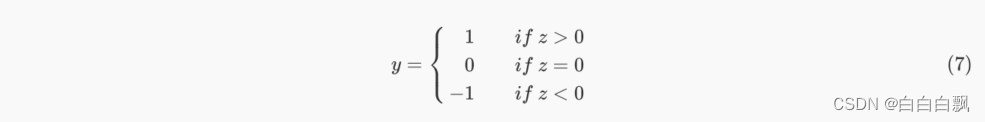
3. ReLU函数
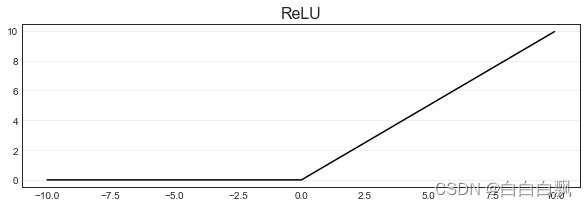
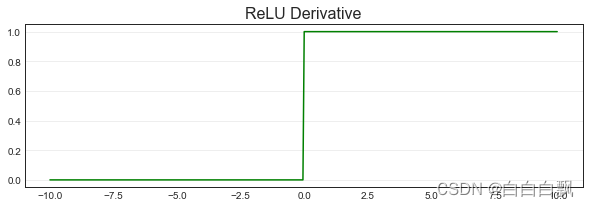
ReLU函数是一个非常简单的函数,本质就是max(0,z)。max函数会从输入的数值中选择较大的那个值进行输出,以达到保留正数元素,将负元素清零的作用。
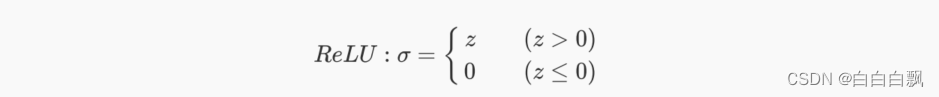
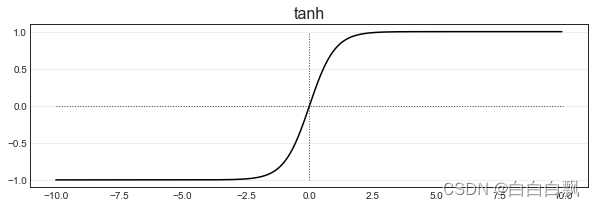
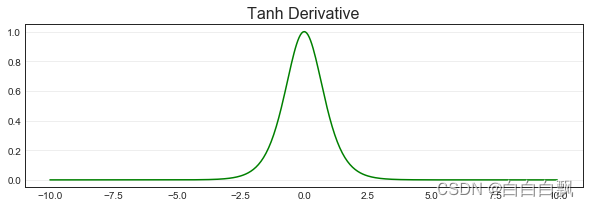
4. Tanh函数
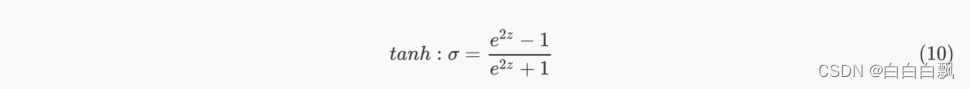
五、总结回归、二分类、多分类

实际上,神经网络的处理原理是一致的,就连算法的限制、优化方法和求解方法也都是一致的。回归和分类神经网络唯一的不同只有输出层上的σ 。
















 1670
1670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











