






一、LSTM预测类型
- 数据类型:单变量、多变量与面板数据
- 数据处理(滑窗方式):单变量有seq2seq,seq2point;多变量:特征滑窗,带标签滑窗
1. 数据类型:单变量、多变量与面板数据
在时间序列的世界中,除了最常见的单变量时间序列之外,我们还有多变量时间序列数据和面板数据两种复杂经典数据结构。我们在深度学习/机器学习以及无数的时间序列课程中都曾讲解过这几种数据的关键定义与区别。
- 单变量时间序列:只包含时间索引和唯一列的序列,在这样的序列中,时间与标签是一一绑定的,我们只需要知道时间即可确定唯一的标签。由于日期能够确定唯一的标签,因此这种数据集中的日期一定不会重复。如果出现了重复的日期,则需要深入调查、或予以删除。例如:<time, 平均温度>,平均温度是唯一的单变量。
- 多变量时间序列:多变量时间序列数据的定义指代一个时间点下拥有多个不同的特征的时间序列数据。例如,预测一支股票在不同日期下的收盘价时,数据集为: <time, 开盘价、当日最高价、当日最底价、成交量、交易额> 。由于日期能够确定唯一的标签,因此这种数据集中的日期一定不会重复。如果出现了重复的日期,则需要深入调查、或予以删除。
- 单变量数据和多变量数据之间的差异就在于特征数量的多少。单变量数据可以转成多变量数据,给单变量时间序列加上特征,那单变量时间序列可以转变为多变量时间序列,比如<time, 平均温度,最高温度, 最低温度,降水量,风速,湿度>
- 面板数据(Pedal Data):用于描述除了时间之外、还有另外的索引辅助我们确定唯一标签的数据。例如:<股票ID | 日期 | 开盘价 | 最高价 | 最低价 | 收盘价(标签) | 交易量 | 成交额 >中,<股票ID | 日期 > 确定唯一的标签收盘价。在这样的数据中,我们称时间为该数据的一个截面,股票ID为数据的另一个截面,两个截面数据归拢在同一张表单中,构成了面板数据。
在深度学习预测的现实、以及大多数深度学习、机器学习竞赛当中,我们所面临的数据都是面板数据。在介绍RNN和LSTM这类深度学习算法的输入数据结构时,我们也多次提过(batch_size, time_step, input_dim)的三维结构;如下图所示,你或许已经注意到了,RNN和LSTM数据所要求的输入数据格式就是为面板数据量身打造的。虽然在实际分割数据的时候、我们可能不能将数据分割得像下图这样完美,但深度学习所要求的三维时间序列数据的格式是很适合面板数据的。

2. 处理数据:滑窗方式
1. 单变量滑窗
序列到序列(Seq2Seq)预测和序列到点(Seq2Point)预测在处理时间序列数据时各有优势。特别是对于LSTM这样的循环神经网络,这两种方法都可以被有效地利用。让我们来比较一下它们各自的优势:
序列到序列(Seq2Seq)预测
-
捕获长期依赖关系:Seq2Seq模型特别适合于那些需要理解整个输入序列来生成整个输出序列的任务。LSTM的优势在于能够捕获长期的时间依赖性,这使得它在Seq2Seq预测中非常有效。
-
连续输出预测:当需要连续预测多个未来时间点时,Seq2Seq模型可以一次性提供整个输出序列,这对于需要连续决策或规划的应用非常有用。
-
灵活性和泛化能力:Seq2Seq模型可以被训练来处理不同长度的输入和输出序列,提供更高的灵活性和泛化能力。
-
多功能性:Seq2Seq模型不仅限于时间序列预测,还可以用于其他任务,如机器翻译、文本摘要等。
序列到点(Seq2Point)预测
-
简单性和高效性:Seq2Point模型通常比Seq2Seq模型更简单,易于实现和训练。这种方法在计算上更高效,因为它仅预测单个输出值。
-
准确性:在某些情况下,Seq2Point模型可能比Seq2Seq模型提供更准确的单点预测,因为它专注于预测一个特定的未来时刻,而不是整个序列。
-
降低过拟合风险:由于模型结构较为简单,Seq2Point模型可能较少受到过拟合的影响,尤其是在数据量较少的情况下。
-
适用性:Seq2Point预测非常适用于那些只需预测一个未来时刻的任务,例如短期负载预测或股价预测。
选择Seq2Seq还是Seq2Point模型取决于具体的应用需求。如果任务涉及到对未来一系列时间点的连续预测,Seq2Seq模型是更好的选择。然而,如果任务只需要预测一个特定的未来时刻,Seq2Point模型可能更为合适,因为它更简单、更高效,并且可能更准确。在实际应用中,考虑数据的特性、预测的需求和可用资源是非常重要的。
2. 多变量滑窗
- 特征滑窗
这种滑窗方式常见于标签本身与时间的关系并不大的情况。与气温、股价这种上个时间点明显会影响下一个时间点的标签不同,某些依据时间进行预测的标签之间并不存在特别强烈的关联。
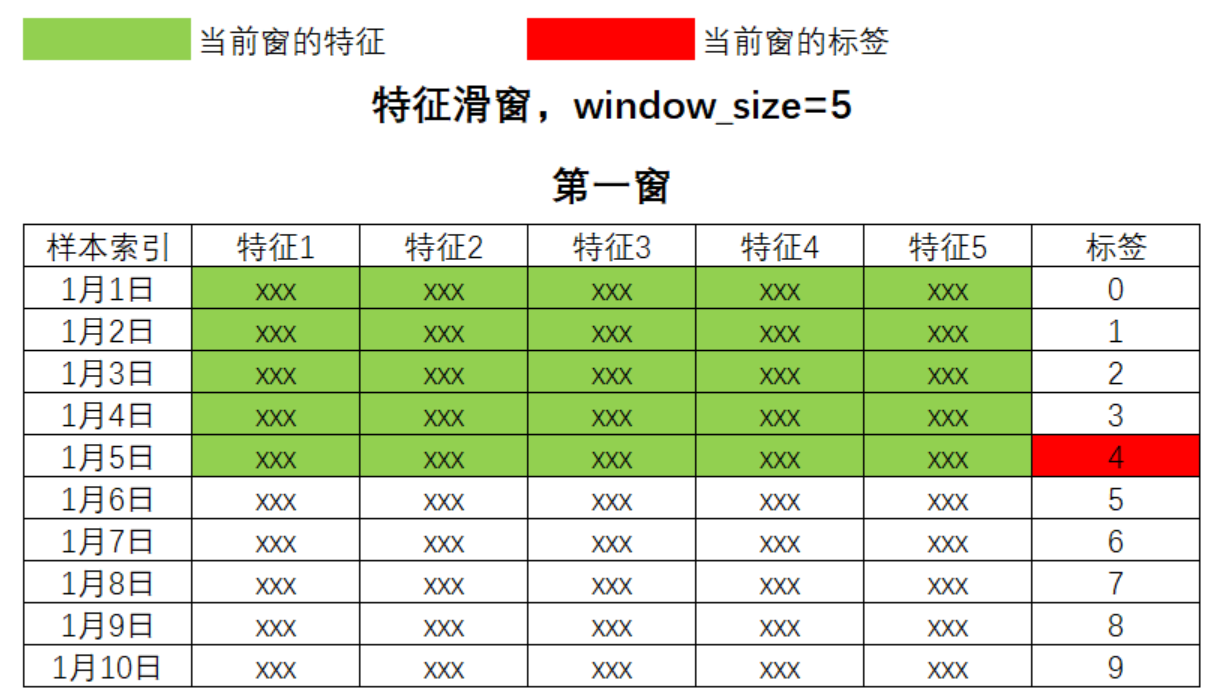
这样最终构建的数据集结构为(batch_size, 5, 5),其中第一个5是window_size,也就代表一张表单中的time_step时间步步数,第二个5代表5个特征,两个数字都是5纯属巧合。
- 带标签的滑窗
这种滑窗方式适应于除了特征之外,标签之间也随着时间互相影响的数据集。
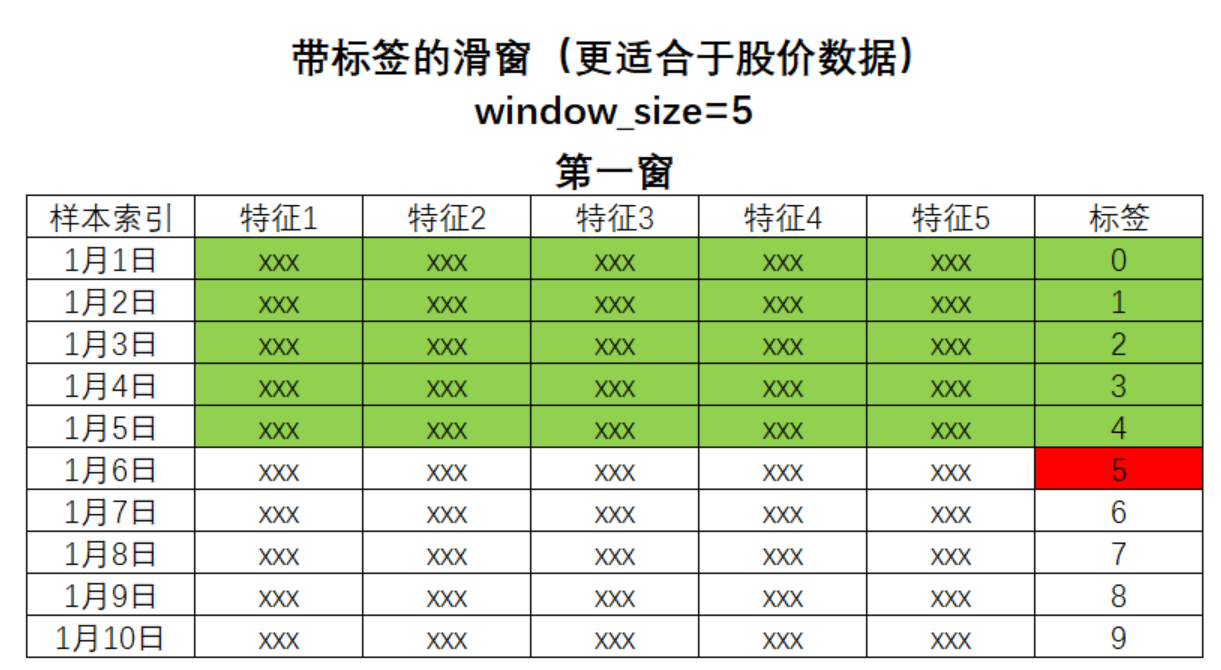
相比只拥有特征的滑窗方式,携带标签的滑窗方式在很多场景下会给与算法更好的表现,这是因为——
- 增加信息量:通过将之前时间点的标签纳入到当前窗口的输入中,模型可以利用更多的上下文信息进行预测。这种方式可以提供更丰富的序列信息,可能有助于模型捕捉到更复杂的时间序列依赖关系。
- 改善序列预测:在某些情况下,特别是当连续的标签之间存在一定的序列相关性时,使用之前的标签作为额外的特征可以提高预测的准确性。
- 增强模型的泛化能力:通过学习如何将过去的标签和当前的特征结合起来进行预测,模型可能更好地理解序列数据的内在规律,从而在遇到新的、未见过的序列时表现得更好。
但是这种滑窗方式也会带来相应的问题——
- 过拟合的风险:更复杂的模型和更多的输入特征可能会增加过拟合的风险,尤其是在数据较少的情况下。需要适当的正则化策略和模型评估方法来避免这一问题。
- 可能的数据泄露:如果在预测时无法获取之前时间点的真实标签(例如,在实时预测或未来预测中),这种方法可能不适用。此外,如果不小心处理,使用未来数据(即“未来泄露”)可能会导致预测结果过于乐观。
- 实施复杂性:需要在数据预处理阶段更加小心地处理数据,确保每个窗口中包含正确的特征和标签,且在实际预测时能够符合模型的输入要求。
总的来说,这种滑窗方式可以为模型提供更多的上下文信息,可能有助于改善预测性能,但同时也带来了更高的模型复杂度和过拟合的风险。
3. LSTM预测的具体流程
- 数据准备:
包括了数据导入、数据探索、数据预处理等步骤 - 数据重组与数据分割
对数据进行结构变化、以满足时序算法对输入数据的结构要求,同时也需要满足时间序列模型评估过程对数据结构的要求。 - 模型构建与模型训练
包括构建模型、训练模型、选择模型、参数调整等流程。 - 验证与评估
对时间序列预测而言,模型评估的过程极为重要。 - 模型预测
当我们所使用最经典的“序列到点”的预测方法时,三种数据在步骤3、4、5中都是非常相似的,但是在1 数据准备和2 数据重组过程中却有较大的区别。
二、LSTM实现
1、单变量时间序列预测:seq2point
import numpy as np #数据处理
import pandas as pd #数据处理
import matplotlib as mlp
import matplotlib.pyplot as plt #绘图
from sklearn.preprocessing import MinMaxScaler #·数据预处理
from sklearn.metrics import mean_squared_error
import torch
import torch.nn as nn #导入pytorch中的基本类
from torch.autograd import Variable
from torch.utils.data import DataLoader, TensorDataset
import torch.optim as optim
import torch.utils.data as data
# 导入以下包从而使得可以在jupyter中的一个cell输出多个结果
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "last_expr"
# 一、导入数据
df = pd.read_csv(r'airline-passengers.csv')
timeseries = df[["Passengers"]].values.astype('float32')
# 二、数据分割与滑窗
# 2.1 按时间顺序对训练集测试集进行分割
train_size = int(len(timeseries) * 0.67)
test_size = len(timeseries) - train_size
train, test = timeseries[:train_size], timeseries[train_size:] # 训练集(96,1) 测试集(48,1)
# 2.2 单变量时间序列滑窗函数
def create_dataset(dataset, lookback):
"""
将时间序列转变为能够用于训练和预测的数据
参数:
dataset: ndarry,第一个维度是时间
lookback: 滑窗的窗的大小
"""
X, y = [], []
for i in range(len(dataset)-lookback):
feature = dataset[i:i+lookback] # 特征:长度为7的数组
target = dataset[i+lookback] # 标签:数组的下一个值
X.append(feature)
y.append(target)
return torch.FloatTensor(X), torch.FloatTensor(y)
# 2.3 创建训练集与测试集
lookback = 7
X_train, y_train = create_dataset(train, lookback=lookback) # 96-7=89 训练集的特征及标签 [89,7,1] [89,1]
X_test, y_test = create_dataset(test, lookback=lookback) # 48-7=41 训练集的特征及标签 [41,7,1] [41,1]
# 三、定义网络架构与训练元素
# LSTM网络架构
class AirModel(nn.Module):
def __init__(self):
super().__init__()
self.lstm = nn.LSTM(input_size=1, hidden_size=50, num_layers=1, batch_first=True)
self.linear = nn.Linear(50, 1)
def forward(self, x):
x, _ = self.lstm(x) # (8,7,1) --> (8,7,50)
#现在我要的是最后一个时间步,而不是全部时间步了
x = self.linear(x[:,-1,:]) # (8,50) --> (8,1)
return x
# 设置GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
# 设置参数
input_size = 1 #输入特征的维度
hidden_size = 50 #LSTM隐藏状态的维度
num_layers = 1 #LSTM层的数量
output_size = 1 #模型的输出维度
n_epochs = 2000 #迭代epoch
learning_rate = 0.001 #学习率
# 加载数据,将数据分批次
# 训练集 12组,每组8行数据
loader = data.DataLoader(data.TensorDataset(X_train, y_train), shuffle=True, batch_size=8)
# 实例化模型
model = AirModel().to(device)
optimizer = optim.Adam(model.parameters(),lr=learning_rate) #定义优化器
loss_fn = nn.MSELoss() #定义损失函数
# 四、实际训练流程
for epoch in range(n_epochs):
model.train()
for X_batch, y_batch in loader: # (8,7,1) (8,1)
y_pred = model(X_batch.to(device)) # (8,1)
loss = loss_fn(y_pred, y_batch.to(device)) # (8,1) (8,1)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 打印
if epoch % 100 != 0:
continue
# 验证
model.eval()
with torch.no_grad():
y_pred = model(X_train.to(device)).cpu()
train_rmse = np.sqrt(loss_fn(y_pred, y_train))
y_pred = model(X_test.to(device)).cpu()
test_rmse = np.sqrt(loss_fn(y_pred, y_test))
print("Epoch %d: train RMSE %.4f, test RMSE %.4f" % (epoch, train_rmse, test_rmse))
测试结果:
Epoch 0: train RMSE 230.9661, test RMSE 428.4506
Epoch 100: train RMSE 179.9486, test RMSE 375.1864
Epoch 200: train RMSE 140.8188, test RMSE 332.6957
Epoch 300: train RMSE 107.6553, test RMSE 293.6115
Epoch 400: train RMSE 81.6868, test RMSE 258.8818
Epoch 500: train RMSE 59.9566, test RMSE 224.5932
Epoch 600: train RMSE 45.7904, test RMSE 197.0976
Epoch 700: train RMSE 36.7074, test RMSE 185.9116
Epoch 800: train RMSE 30.9898, test RMSE 156.5260
Epoch 900: train RMSE 26.9548, test RMSE 141.3668
Epoch 1000: train RMSE 23.1397, test RMSE 132.8655
Epoch 1100: train RMSE 20.7870, test RMSE 119.9717
Epoch 1200: train RMSE 18.6490, test RMSE 113.3812
Epoch 1300: train RMSE 16.5863, test RMSE 107.5541
Epoch 1400: train RMSE 15.7316, test RMSE 103.9520
Epoch 1500: train RMSE 15.0654, test RMSE 101.1125
Epoch 1600: train RMSE 14.4755, test RMSE 99.7093
Epoch 1700: train RMSE 14.3179, test RMSE 101.0579
Epoch 1800: train RMSE 12.4393, test RMSE 97.4818
Epoch 1900: train RMSE 12.2507, test RMSE 96.7813
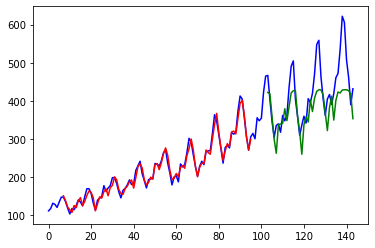
画图展示:
with torch.no_grad():
# 绘制训练集上的损失的图像
train_plot = np.ones_like(timeseries) * np.nan
y_pred = model(X_train.to(device)).cpu()
train_plot[lookback:train_size] = y_pred
# 绘制测试集上的损失的图像
test_plot = np.ones_like(timeseries) * np.nan
test_plot[train_size+lookback:len(timeseries)] = model(X_test.to(device)).cpu()
# plot
plt.plot(timeseries, c='b')
plt.plot(train_plot, c='r')
plt.plot(test_plot, c='g')
plt.show()

2、单变量时间序列预测:seq2seq
# 序列到序列
# 一、导入数据
df = pd.read_csv(r'airline-passengers.csv')
timeseries = df[["Passengers"]].values.astype('float32')
# 二、数据分割与滑窗
# 2.1 按时间顺序对训练集测试集进行分割
train_size = int(len(timeseries) * 0.67)
test_size = len(timeseries) - train_size
train, test = timeseries[:train_size], timeseries[train_size:] # 训练集(96,1) 测试集(48,1)
# 2.2 单变量时间序列滑窗函数
def create_dataset_2(dataset, lookback):
"""
序列到序列预测的滑窗函数
"""
X, y = [], []
for i in range(len(dataset)-lookback):
feature = dataset[i:i+lookback] # 特征:一个时间窗口
target = dataset[i+1:i+lookback+1] # 标签:下一个时间窗口
X.append(feature)
y.append(target)
return torch.FloatTensor(X), torch.FloatTensor(y)
# 2.3 创建训练集与测试集
lookback = 7
X_train, y_train = create_dataset_2(train, lookback=lookback) # 训练集的特征和标签 [89, 7, 1] [89, 7, 1]
X_test, y_test = create_dataset_2(test, lookback=lookback) # 测试集的特征和标签 [41, 7, 1] [41, 7, 1]
# 三、定义网络架构与训练元素
# LSTM网络架构
class AirModel(nn.Module):
def __init__(self):
super().__init__()
self.lstm = nn.LSTM(input_size=1, hidden_size=50, num_layers=1, batch_first=True)
self.linear = nn.Linear(50, 7) # 输出7个特征组作为标签
def forward(self, x):
x, _ = self.lstm(x) # (8,7,1) --> (8,7,50)
x = self.linear(x) # (8,7,50) --> (8,7,7)
return x
#device = "cpu"
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
model = AirModel().to(device)
optimizer = optim.Adam(model.parameters())
loss_fn = nn.MSELoss()
loader = data.DataLoader(data.TensorDataset(X_train, y_train), shuffle=True, batch_size=8)
n_epochs = 2000
for epoch in range(n_epochs):
model.train()
for X_batch, y_batch in loader: # x(8,7,1) y(8,7,1)
y_pred = model(X_batch.to(device)) # y_(8,7,7)
loss = loss_fn(y_pred, y_batch.to(device)) # y_(8,7,7) y(8,7,1) 广播计算
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Validation
if epoch % 100 != 0:
continue
model.eval()
with torch.no_grad():
y_pred = model(X_train.to(device)).cpu()
train_rmse = np.sqrt(loss_fn(y_pred
, y_train))
y_pred = model(X_test.to(device)).cpu()
test_rmse = np.sqrt(loss_fn(y_pred, y_test))
print("Epoch %d: train RMSE %.4f, test RMSE %.4f" % (epoch, train_rmse, test_rmse))
Epoch 100: train RMSE 173.4320, test RMSE 369.8485
Epoch 200: train RMSE 132.7849, test RMSE 325.2895
Epoch 300: train RMSE 101.3175, test RMSE 287.1393
Epoch 400: train RMSE 79.5517, test RMSE 255.5599
Epoch 500: train RMSE 60.5385, test RMSE 226.0344
Epoch 600: train RMSE 47.4734, test RMSE 199.4823
Epoch 700: train RMSE 38.1845, test RMSE 176.1875
Epoch 800: train RMSE 31.8101, test RMSE 156.5770
Epoch 900: train RMSE 27.5062, test RMSE 139.5727
Epoch 1000: train RMSE 24.5809, test RMSE 125.2263
Epoch 1100: train RMSE 22.6187, test RMSE 113.7144
Epoch 1200: train RMSE 21.6528, test RMSE 104.2128
Epoch 1300: train RMSE 19.8239, test RMSE 96.3471
Epoch 1400: train RMSE 18.7835, test RMSE 90.2540
Epoch 1500: train RMSE 18.2689, test RMSE 86.3394
Epoch 1600: train RMSE 17.6720, test RMSE 82.2808
Epoch 1700: train RMSE 17.4463, test RMSE 78.7087
Epoch 1800: train RMSE 16.8598, test RMSE 76.6019
Epoch 1900: train RMSE 16.2736, test RMSE 75.1124
# 结果分析:采用seq2seq的预测方式比seq2point的预测方式更好,有效缓解过拟合。
# 说明:seq2seq单纯取最后一个时间步的结果不比seq2point的好,但是取全部时间步并进行广播计算,获取的信息更多,所以效果更好。
with torch.no_grad():
# shift train predictions for plotting
train_plot = np.ones_like(timeseries) * np.nan
y_pred = model(X_train.to(device)).cpu()
y_pred = y_pred[:, -1, :]
train_plot[lookback:train_size] = model(X_train.to(device)).cpu()[:, -1, -1].reshape(89,1)
# shift test predictions for plotting
test_plot = np.ones_like(timeseries) * np.nan
test_plot[train_size+lookback:len(timeseries)] = model(X_test.to(device)).cpu()[:, -1, -1].reshape(41,1)
# plot
plt.plot(timeseries, c='b')
plt.plot(train_plot, c='r')
plt.plot(test_plot, c='g')
plt.show()
3、多变量时序数据的重组流程
数据重组是通过在数据上进行滑窗或其他变化,将数据改造成符合LSTM要求的三维数据集的操作。在这里,我们使用Kaggle顶级竞赛:JPX股价预测赛题中的股票数据集来举例,给大家展示多变量时序数据的数据重组流程。
df_stock_prices = pd.read_csv(r'D:\MyData\MyCourse\04_python深度学习\Lesson 20\stock_prices.csv')
df_stock_prices.head()
df_stock_prices.shape # (2332531, 12)
df_stock_prices["SecuritiesCode"].unique().__len__() #一共包含2000支股票
# 提取其中一支股票的数据作为例子
# 选择单只股票的数据
single_stock = df_stock_prices[df_stock_prices['SecuritiesCode'] == 1332]
single_stock['Date']
pd.to_datetime(single_stock['Date']).to_numpy()
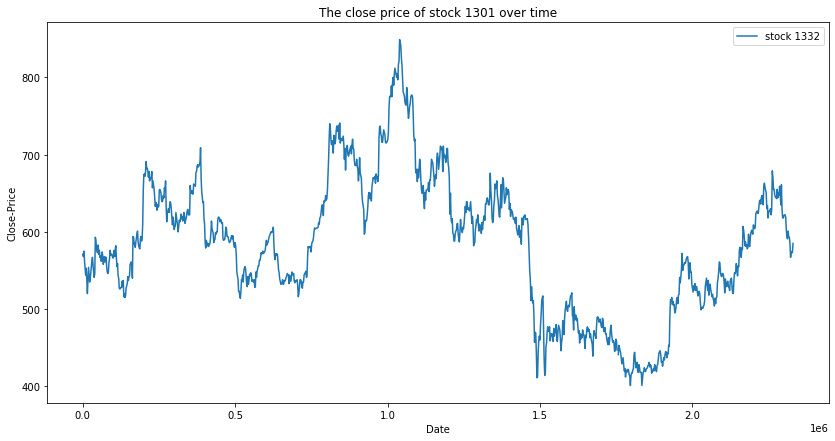
# 绘制单只股票的'close'价格的时间序列图
plt.figure(figsize=(14, 7))
plt.plot(single_stock['Close'],label='stock 1332')
plt.xlabel('Date')
plt.ylabel('Close-Price')
plt.title('The close price of stock 1332 over time')
plt.legend()
plt.show()
#按时间顺序对训练集测试集进行分割
train_size = int(len(single_stock) * 0.67)
test_size = len(single_stock) - train_size
train, test = single_stock[:train_size], single_stock[train_size:]
train.head()
train.shape # (805, 12)
single_stock.shape # (1202, 12)
- 多变量时间序列:特征滑窗
import torch
import numpy as np
def create_multivariate_dataset(dataset, window_size):
"""
将多变量时间序列转变为能够用于LSTM训练和预测的数据【特征法】
参数:
dataset: DataFrame,其中包含特征和标签,特征从索引3开始,最后一列是标签
window_size: 滑窗的窗口大小
"""
X, y = [], []
for i in range(len(dataset) - window_size):
# 使用.values将Pandas DataFrame的切片转换为NumPy数组
feature = dataset.iloc[i:i + window_size, 3:-1].values # 转换为NumPy数组
target = dataset.iloc[i + window_size - 1, -1] # 目标值保持为标量即可
X.append(feature)
y.append(target)
# 直接使用np.array转换列表为NumPy数组,并指定dtype确保数组类型正确
return torch.FloatTensor(np.array(X, dtype=np.float32)), torch.FloatTensor(np.array(y, dtype=np.float32))
X_train, y_train = create_multivariate_dataset(train, 2)
X_train.shape # torch.Size([803, 2, 8]) 特征除掉 index,date,股票id,标签,12-4=8个
- 多变量时间序列:带标签滑窗
import torch
import numpy as np
def create_multivariate_dataset_2(dataset, window_size):
"""
将多变量时间序列转变为能够用于训练和预测的数据【带标签的滑窗】
参数:
dataset: DataFrame,其中包含特征和标签,特征从索引3开始,最后一列是标签
window_size: 滑窗的窗口大小
"""
X, y = [], []
for i in range(len(dataset) - window_size):
# 选取从第4列到最后一列的特征和标签
feature_and_label = dataset.iloc[i:i + window_size, 3:].values # 包括标签在内的特征
# 下一个时间点的标签作为目标
target = dataset.iloc[i + window_size, -1] # 使用下一个时间点的标签作为预测目标
X.append(feature_and_label)
y.append(target)
return torch.FloatTensor(np.array(X, dtype=np.float32)), torch.FloatTensor(np.array(y, dtype=np.float32))
X_train_2, y_train_2 = create_multivariate_dataset_2(train, 2)
X_train_2.shape # torch.Size([803, 2, 9]) 带标签滑窗
X_train.shape # torch.Size([803, 2, 8]) 特征滑窗
4、面板数据的重组流程
df_stock_prices = pd.read_csv(r'stock_prices.csv')
multi_stock = pd.concat([df_stock_prices[df_stock_prices['SecuritiesCode'] == 1332]
,df_stock_prices[df_stock_prices['SecuritiesCode'] == 1301]
,df_stock_prices[df_stock_prices['SecuritiesCode'] == 1376]
])
df_stock_prices[df_stock_prices['SecuritiesCode'] == 1332].shape
df_stock_prices[df_stock_prices['SecuritiesCode'] == 1301].shape
df_stock_prices[df_stock_prices['SecuritiesCode'] == 1376].shape
multi_stock.shape
(1202, 12)(1202, 12)(1202, 12)(3606, 12)
- 跨截面的滑窗
import torch
import numpy as np
def create_multivariate_dataset_2(dataset, window_size):
"""
将多变量时间序列转变为能够用于训练和预测的数据
参数:
dataset: DataFrame,其中包含特征和标签,特征从索引3开始,最后一列是标签
window_size: 滑窗的窗口大小
"""
X, y = [], []
for i in range(len(dataset) - window_size):
# 选取从第4列到最后一列的特征和标签
feature_and_label = dataset.iloc[i:i + window_size, 3:].values # 包括标签在内的特征
# 下一个时间点的标签作为目标
target = dataset.iloc[i + window_size, -1] # 使用下一个时间点的标签作为预测目标
X.append(feature_and_label)
y.append(target)
return torch.FloatTensor(np.array(X, dtype=np.float32)), torch.FloatTensor(np.array(y, dtype=np.float32))
- 避免跨截面的滑窗
有填补和截取两种方式,下面的使用截取的方式。
#按时间顺序对训练集测试集进行分割
train_size = int(len(multi_stock) * 0.67)
test_size = len(multi_stock) - train_size
train, test = multi_stock[:train_size], multi_stock[train_size:]
train.shape # (2416, 12)
import torch
import numpy as np
def create_multivariate_dataset_4(dataset, window_size):
"""
将多变量时间序列转变为能够用于训练和预测的数据,确保每个窗口内的Securities Code唯一
参数:
dataset: DataFrame,其中包含特征和标签,特征从索引3开始,最后一列是标签
window_size: 滑窗的窗口大小
"""
X, y = [], []
for i in range(len(dataset) - window_size):
# 检查窗口内的Securities Code是否唯一
securities_code = dataset.iloc[i:i + window_size, 2]
if len(securities_code.unique()) == 1: # 如果Securities Code在窗口内唯一
# 选取从第4列到最后一列的特征和标签
feature_and_label = dataset.iloc[i:i + window_size, 3:].copy().values
# 下一个时间点的标签作为目标
target = dataset.iloc[i + window_size, -1]
X.append(feature_and_label)
y.append(target)
return torch.FloatTensor(np.array(X, dtype=np.float32)), torch.FloatTensor(np.array(y, dtype=np.float32))
train.shape # (2416, 12)
X_train_4, y_train_4= create_multivariate_dataset_4(train, 10)
X_train_4.shape # (2388,10,9), 应该有2416 - 10个窗,但是其中有多个窗涉及到跨越了截面(涉及到不同的股票,因此被删除了)
X_train.shape # (803,2,8) 特征滑窗,win_size=2
5、单步预测、多步预测、递归预测
在之前的课程中我们了解了3类不同的时间序列数据、以及这些数据所涉及到的7-8类数据重组方式,相信你已经意识到、时间序列任务会比一般的机器学习/深度学习更复杂、更灵活、更有挑战性。尽管3种不同的时序数据已经让我们应接不暇,但事实上时序预测过程中难度更高的是预测方法本身。在过去的课程中,我们都是以最为经典的“点到序列”的预测方式给大家举例,但事实上,依据时间序列预测的不同细节,时序预测手段可以被分为以下四种——
- 单步预测:在每次预测时只预测序列的下一个时间点的值,也就是常见的“序列到点”(seq-2-point)的预测。
- 多步预测:在每次预测时预测序列接下来多个时间点的值,也就是之前提过的“序列到序列”(seq-2-seq)的预测。
- 递归预测:模型预测出下一个时间点或多个时间点的值后,将这些预测值作为输入的一部分来预测下一个时间点或多个时间点的值,如此递归下去。
- 直接预测:在预测过程中,模型只使用已存在的历史数据和历史标签作为输入,并不会将上一时刻预测出的结果作为下一时刻输入的一部分。
在这4种分类下,我们实际可以有单步递归预测、单步直接预测、多步递归预测和多步直接预测四种预测方法,之前我们所呈现的最经典的“序列到点”的预测就是单步直接预测法。本节就让我们一起来认识一下这4种预测方法。
- 从单步直接预测到多步直接预测
从单步直接预测过渡到多步直接预测,是一个“牵一发而动全身”的策略,会涉及到一系列的改变和挑战,这些改变不仅会影响数据的预处理过程,例如滑窗方式的调整,还会影响到模型的架构和训练过程,如LSTM的输出方式和损失函数的计算。在多步预测中,滑窗方式可能需要根据预测范围进行优化,以确保每个窗口能够有效地捕获到对未来多个时间点预测所需的信息。同时,LSTM模型的输出层需要调整,以便能够一次性输出多个时间点的预测值,这可能要求模型学习和捕获更复杂的时间序列依赖关系。
此外,损失函数的计算也变得更加复杂,因为现在需要考虑模型对多个未来时间点预测的整体准确性。这可能会影响到模型的训练策略,包括早停机制的应用,因为早停判断现在需要基于多步预测的性能来进行。最后,从多步直接预测中提取最终预测值时,还需要考虑如何综合和处理模型输出的多个预测结果,以便得到对未来序列的最佳估计。这些问题共同构成了从单步直接预测到多步直接预测转变的复杂性,需要细致的方法和策略来有效地解决。
6、LSTM多步预测完整代码
6.1 数据加载与处理
# 一、数据处理
# 1、数据导入
df_stock_prices = pd.read_csv('stock_prices.csv')
df_stock_prices.shape # (2332531, 12)
df_stock_prices["SecuritiesCode"].unique().__len__() #一共包含2000支股票
# 提取其中一支股票的数据作为例子
# 选择单只股票的数据
single_stock = df_stock_prices[df_stock_prices['SecuritiesCode'] == 1332]
single_stock.shape # (1202, 12)
# 2、完成简单预处理**
# 我们修改预测目标,我们预测股价,而不预测原始竞赛中的Target(夏普比率)
single_stock = single_stock.copy()
#将Target名字修改为Sharpe Ratio
single_stock.rename(columns={'Target': 'Sharpe Ratio'}, inplace=True)
#将Close列取出
close_col = single_stock.pop('Close')
#将Close列添加到最后
single_stock.loc[:,'Close'] = close_col
#填补缺失值
single_stock.loc[:,"ExpectedDividend"] = single_stock.loc[:,"ExpectedDividend"].fillna(0)
single_stock.dropna(inplace=True)
#恢复索引
single_stock.index = range(single_stock.shape[0])
# 3、绘制单只股票的'High'价格的时间序列图
plt.figure(figsize=(14, 7))
plt.plot(single_stock['Close'],label='stock 1332')
plt.xlabel('Date')
plt.ylabel('Close Price')
plt.title('The close price of stock 1301 over time')
plt.legend()
plt.show()

6.2 数据分割与数据重组
# 二、数据分割与带标签的滑窗
# 1、按时间顺序对训练集测试集进行分割
train_size = int(len(single_stock) * 0.67)
test_size = len(single_stock) - train_size
train, test = single_stock[:train_size], single_stock[train_size:]
# 2、数据重组,带标签的滑窗
def create_multivariate_dataset_2(dataset, window_size, pred_len):
"""
将多变量时间序列转变为能够用于训练和预测的数据【带标签的滑窗】
参数:
dataset: DataFrame,其中包含特征和标签,特征从索引3开始,最后一列是标签
window_size: 滑窗的窗口大小
pred_len:多步预测的预测范围/预测步长
"""
X, y, y_indices = [], [], []
for i in range(len(dataset) - window_size - pred_len + 1):
# 选取从第4列到最后一列的特征和标签
feature_and_label = dataset.iloc[i:i + window_size, 3:].values
# 下一个时间点的标签作为目标
target = dataset.iloc[(i + window_size):(i + window_size + pred_len), -1]
# 记录本窗口中要预测的标签的时间点
target_indices = list(range(i + window_size, i + window_size + pred_len))
X.append(feature_and_label)
y.append(target)
#将每个标签的索引添加到y_indices列表中
y_indices.extend(target_indices) # 对应时间点,即索引
X = torch.FloatTensor(np.array(X, dtype=np.float32))
y = torch.FloatTensor(np.array(y, dtype=np.float32))
return X, y, y_indices
window_size = 32
pred_len = 5 #进行5步的多步预测
X_train_2, y_train_2, y_train_indices = create_multivariate_dataset_2(train, window_size, pred_len)
X_test_2, y_test_2, y_test_indices = create_multivariate_dataset_2(test, window_size, pred_len)
# 查看数据集情况
X_train_2.shape # torch.Size([768, 32, 9])
X_train_2[0] # 第一个滑动窗口的所有样本 torch.Size([32, 9])
y_train_2[0] # 索引为32、33、34、35、36五个标签,tensor([562., 562., 574., 569., 558.])
y_train_indices[:10] #由于设置的pred_len是5,所以5个标签为一轮,[32, 33, 34, 35, 36, 33, 34, 35, 36, 37]
6.3 网络架构与参数设置
# 三、架构建立与参数设置
#选择了最为简单的网络架构来进行实验
import torch.nn as nn
class MyLSTM(nn.Module):
def __init__(self,input_dim, pred_len):
super().__init__()
self.lstm = nn.LSTM(input_size=input_dim, hidden_size=50, num_layers=1, batch_first=True)
self.linear = nn.Linear(50, pred_len)
def forward(self, x):
x, _ = self.lstm(x)
#现在我要的是最后一个时间步,而不是全部时间步了
x = self.linear(x[:,-1,:])
return x
# model = MyLSTM(input_dim = 9, pred_len = pred_len)
# model(X_train_2).shape #针对全部的768窗口,都输出5个预测值,torch.Size([768, 5])
#设置GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
#设置参数
input_size = 1 #输入特征的维度
hidden_size = 50 #LSTM隐藏状态的维度
num_layers = 1 #LSTM层的数量
output_size = 1 #模型的输出维度
n_epochs = 2000 #迭代epoch
learning_rate = 0.001 #学习率
#实例化模型
model = MyLSTM(input_dim=9,pred_len = pred_len).to(device)
optimizer = optim.Adam(model.parameters(),lr=learning_rate) #定义优化器
loss_fn = nn.MSELoss() #定义损失函数
loader = data.DataLoader(data.TensorDataset(X_train_2, y_train_2)
#每个表单内部是保持时间顺序的即可,表单与表单之间可以shuffle
, shuffle=True
, batch_size=8) #将数据分批次
6.4 实际训练流程
# 四、实际训练流程
# 初始化早停参数
early_stopping_patience = 3 # 设置容忍的epoch数,即在这么多epoch后如果没有改进就停止
early_stopping_counter = 0 # 用于跟踪没有改进的epoch数
best_train_rmse = float('inf') # 初始化最佳的训练RMSE
for epoch in range(n_epochs):
model.train()
for X_batch, y_batch in loader:
y_pred = model(X_batch.to(device))
loss = loss_fn(y_pred, y_batch.to(device))
optimizer.zero_grad()
loss.backward()
optimizer.step()
#验证与打印
if epoch % 100 == 0:
model.eval()
with torch.no_grad():
y_pred = model(X_train_2.to(device)).cpu()
train_rmse = np.sqrt(loss_fn(y_pred, y_train_2))
y_pred = model(X_test_2.to(device)).cpu()
test_rmse = np.sqrt(loss_fn(y_pred, y_test_2))
print("Epoch %d: train RMSE %.4f, test RMSE %.4f" % (epoch, train_rmse, test_rmse))
# 早停检查
if train_rmse < best_train_rmse:
best_train_rmse = train_rmse
early_stopping_counter = 0 # 重置计数器
else:
early_stopping_counter += 1 # 增加计数器
if early_stopping_counter >= early_stopping_patience:
print(f"Early stopping triggered after epoch {epoch}. Training RMSE did not decrease for {early_stopping_patience} consecutive epochs.")
break # 跳出训练循环
结果:
Epoch 0: train RMSE 624.8842, test RMSE 518.7423
Epoch 100: train RMSE 514.5184, test RMSE 408.8167
Epoch 200: train RMSE 405.5827, test RMSE 300.8127
Epoch 300: train RMSE 298.6700, test RMSE 196.3940
Epoch 400: train RMSE 196.2972, test RMSE 104.2254
Epoch 500: train RMSE 108.4778, test RMSE 76.9970
Epoch 600: train RMSE 73.7087, test RMSE 122.7074
Epoch 700: train RMSE 73.3154, test RMSE 128.8437
Epoch 800: train RMSE 73.3153, test RMSE 128.9358
Epoch 900: train RMSE 73.3153, test RMSE 128.9346
Epoch 1000: train RMSE 73.3153, test RMSE 128.9217
Epoch 1100: train RMSE 73.3153, test RMSE 128.9151
Early stopping triggered after epoch 1100. Training RMSE did not decrease for 3 consecutive epochs.
6.5 输出预测值,绘制预测图像
# 五、输出预测值,绘制预测图像
def get_predictions(model, X, y_indices):
# 将模型移至CPU
model.cpu()
# 对输入数据X进行预测,调整形状,脱离计算图,并转换为numpy数组,然后移除单一维度
y_pred = model(X).view(-1, 1).detach().numpy().squeeze()
# 创建一个DataFrame,包含时间步和对应的预测值
result = pd.DataFrame(zip(y_indices, y_pred), columns=["time_step", "prediction"])
# 按时间步分组,并计算每个时间步的预测值的平均值,以处理重复预测的情况
result = result.groupby(by="time_step").mean()
print(result.shape)
return result
train_result = get_predictions(model,X_train_2,y_train_indices)
test_result = get_predictions(model,X_test_2,y_test_indices)
# 画图
with torch.no_grad():
plt.figure(figsize=(14, 7))
plt.xlabel('Date')
plt.ylabel('Close Price')
# 绘制训练集上的损失的图像
train_plot = np.ones_like(single_stock.index) * np.nan
train_plot[window_size:train_size] = train_result.loc[:,"prediction"]
# 绘制测试集上的损失的图像
test_plot = np.ones_like(single_stock.index) * np.nan
test_plot[train_size:(train_size + test_size - window_size)] = test_result.loc[:,"prediction"]
plt.plot(single_stock.loc[:,"Close"], c='b')
plt.plot(train_plot, c='r')
plt.plot(test_plot, c='g')
plt.show()
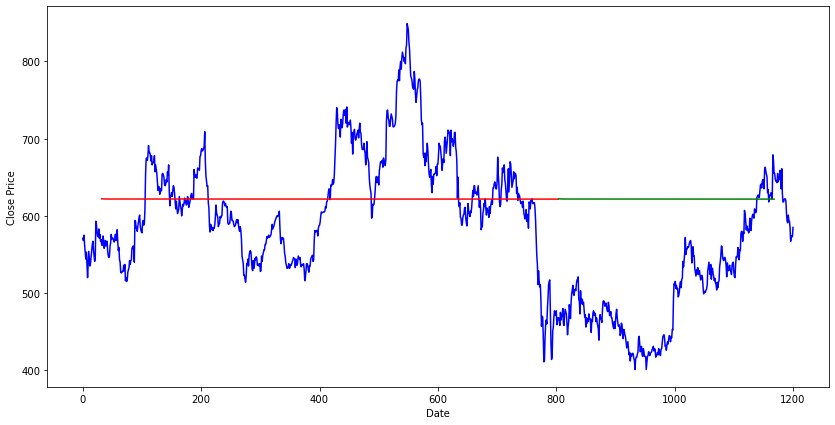
总结一下,从单步预测到多步预测,我们需要改变的流程与代码是——
- 数据滑窗与数据分割流程、尤其是标签的分割流程
- 模型架构、主要是修改最终线性层输出的标签数量需与多步预测的步数一致
- 由于时间窗口会囊括重复的样本、因此一个样本会被预测多次,因此要设置单独的预测值提取流程
- 注意损失函数的计算流程,如果LSTM的输出层输出的标签数量为1,那损失函数的计算的代码不会报错、但是损失值却会大幅偏移
保证这些流程的完善,才能够保证我们在执行正确的多步预测。
7、递归多步预测
从多步直接预测转向多步递归预测时,会遇到一系列挑战和考量,这些不仅涉及模型架构的调整,还包括数据处理、预测策略和性能评估等多个方面的变化。在多步递归预测中,模型不再一次性输出所有未来时间点的预测值,而是逐步使用前一步的预测结果作为下一步预测的输入。这种预测方式带来了以下挑战:
预测依赖性增加:由于每一步的预测都依赖于前一步的输出,错误可能会在预测过程中逐步累积,导致长期预测的准确性降低。这种依赖性要求模型具有很高的短期预测准确性,以减少误差传播。
滑窗策略的调整:在多步递归预测中,滑窗的策略需要灵活调整,以适应逐步生成预测值的需要。每次预测后,新的预测值需要被整合到后续窗口的输入中,这可能要求动态调整窗口的内容。
损失函数和训练过程的复杂性:在递归预测中,损失函数的计算可能需要在每一步预测后即时进行,以便及时调整模型参数。这种即时反馈机制增加了训练过程的复杂性,并可能需要特别设计的训练循环。
早停机制的适应性:传统的早停机制可能需要针对递归预测进行调整,因为模型性能的评估现在涉及到连续多步的预测结果。确定何时停止训练以避免过拟合,可能需要考虑递归预测的特殊性质和误差累积的影响。
最终预测值的确定性问题:在多步递归预测中,由于每一步预测都是基于先前的预测结果,因此如何从一系列递归生成的预测中确定最终的预测值可能会更加复杂。可能需要采取额外的策略,比如使用多种模型的预测结果进行综合,以提高预测的可靠性。
实时数据的整合问题:在实际应用中,如果有新的实时数据可用,将这些数据有效地整合到递归预测过程中,以及如何平衡模型对新数据和自身预测结果的依赖,是另一个需要考虑的挑战。
总的来说,从多步直接预测到多步递归预测的转变,虽然为模型提供了更大的灵活性和适应性,但也带来了一系列挑战,需要通过精心的模型设计和训练策略来克服。
# 假设 single_stock 是原始的 DataFrame,包含 130 行和 6 列,其中最后一列是标签
single_stock = pd.DataFrame(np.random.rand(130, 6), columns=[f'Feature_{i}' for i in range(1, 6)] + ['Label'])
class MyLSTM(nn.Module):
def __init__(self, input_dim, pred_len):
super().__init__()
self.lstm = nn.LSTM(input_size=input_dim, hidden_size=50, num_layers=1, batch_first=True)
self.linear = nn.Linear(50, pred_len)
def forward(self, x):
x, _ = self.lstm(x)
x = self.linear(x[:, -1, :]) # 使用最后一个时间步
return x
def train_lstm_with_dynamic_window(single_stock, window_size=10, pred_len=5):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
input_dim = single_stock.shape[1] - 1 # 减去1是因为最后一列是标签
model = MyLSTM(input_dim=input_dim, pred_len=pred_len).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
loss_fn = nn.MSELoss()
# 将 DataFrame 转换为张量
data_tensor = torch.tensor(single_stock.values, dtype=torch.float32)
for start_idx in range(0, len(single_stock) - window_size - pred_len + 1):
# 分割出当前窗口的数据
current_window = data_tensor[start_idx:start_idx + window_size].unsqueeze(0).to(device) # 增加批次维度
# 目标标签为窗口之后的 pred_len 个标签
target = data_tensor[start_idx + window_size:start_idx + window_size + pred_len, -1].unsqueeze(0).to(device)
# 预测
model.train()
optimizer.zero_grad()
output = model(current_window)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
# 使用预测结果更新原始数据中对应的标签
data_tensor[start_idx + window_size:start_idx + window_size + pred_len, -1] = output.detach().squeeze()
# 返回更新后的数据
return data_tensor
【后续待补充,递归预测的完整代码】

















 1408
1408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











