




文章目录
参考文章:写的比较碎,相对来讲参考文章总结的更好,更容易理解。
kaggle比赛案例:Elo Merchant Category Recommendation(1)
kaggle比赛案例:Elo Merchant Category Recommendation(2)
一、Kaggle赛题分析及数据获取
Elo Merchant Category Recommendation
1、赛题分析
- 业务目标:更好地进行本地服务推荐
- 算法目标:对用户忠诚度评分进行预测(回归问题)
- 借助论坛挖掘更多的信息:出于保密原则,主办方会刻意隐瞒部分信息的,脱敏、创造新字段、不给字段解释等;且对于机器学习来说,数字规律可能会强于业务逻辑,对可解释性的要求不高
2、数据获取
- kaggle用户注册登录
- data页面查看数据集基本信息
- pip安装kaggle包
- 创建获取kaggle的API
- 下载相关数据集
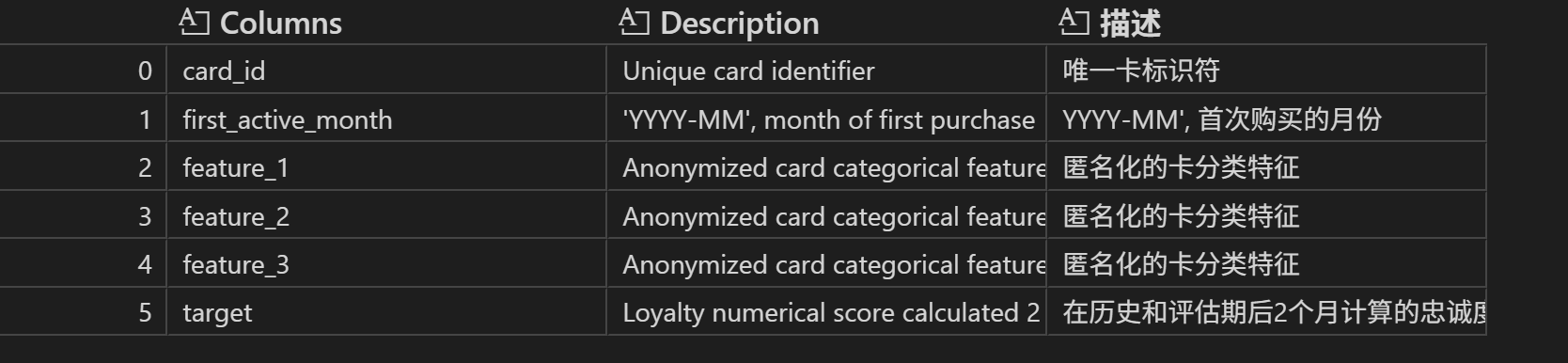
3、数据集介绍
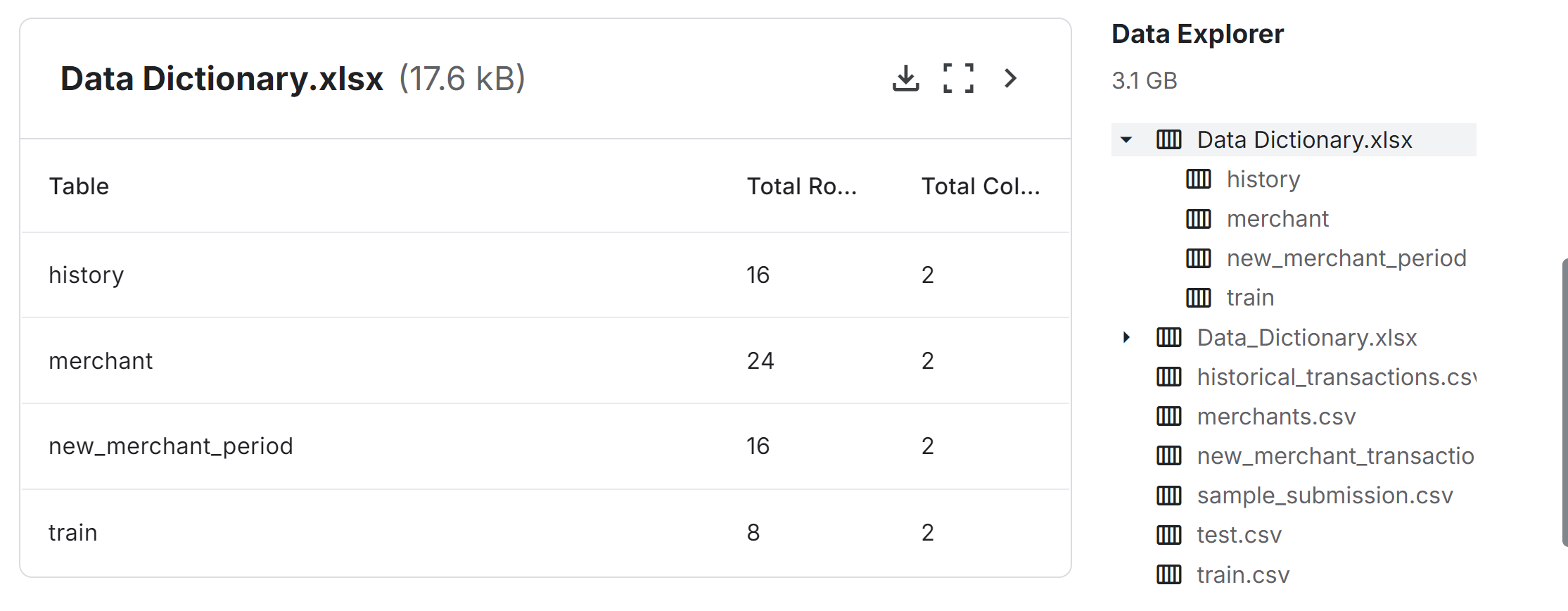
1.3.1 数据集描述(官网信息)
注:所有数据都是模拟和虚构的,不是真实的客户数据
1、我需要什么文件?
(1)您至少需要train.csv和test.csv文件。这些包含我们将用于训练和预测的card_ids。(信用卡信息)
(2)historian_transactions.csv和new_merchant_transactions.csv文件包含有关每张卡交易的信息。其中,historical_transactions.csv包含每张卡在可提供商家中的3个月的历史交易记录。newmerchant_transactions.csv包含每张卡在未访问的新商家上的两个月的历史交易记录。(信用卡的消费记录)
(3)merchants.csv包含数据集中表示的每个merchant_id的聚合信息。(商家信息)
2、我应该期望数据格式是什么?
(1)train.csv和test.csv包含卡片ID和卡片本身的信息,即卡片激活的第一个月等。train.csv还包含目标。
(2)historical_transactions.cv和newmemarch_transactions.csv被设计为与train.csv、test.csv和merchants.csv连接。如上所述,它们包含每张卡的交易信息。
(3)商家可以加入交易集以提供额外的商家级别信息。
3、我在预测什么?
您正在预测test.csv和sample_submission.csv中表示的每个card_id的忠诚度得分。
4、文件描述
- train.csv-训练集
- test.csv-测试集
- sample_submission.csv-一个格式正确的示例提交文件-包含您需要预测的所有card_id。
- historical_transactions.cv-每张卡id最多可存储3个月的历史交易记录
- merchants.csv-数据集中所有商家/商家ID的附加信息。
- new_merchant_transactions.csv-每个card_id的两个月数据,包含card_id在历史数据中未访问的商品id上进行的所有购买。(每张卡在未访问的新商家上的两个月的历史交易记录。)
5、数据字段
- Data_Dictionary.xlsx描述其他所有数据表中数据字段的含义,数据表的说明书。
1.3.2 查看数据集文件
# 第三行开始读取,读取train表
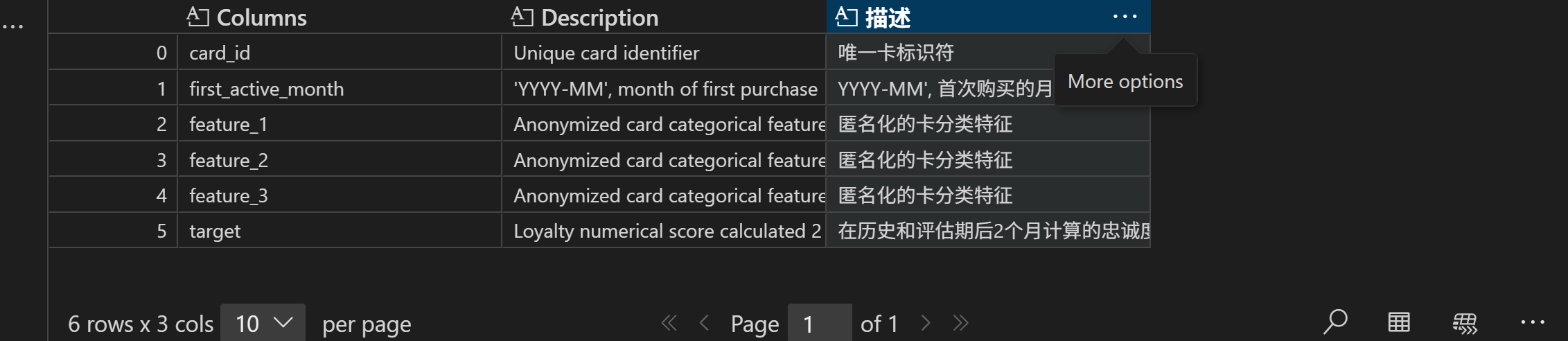
pd.read_excel('./eloData/Data_Dictionary.xlsx', header=2, sheet_name='train')
# 读取sample_submission文件数据
pd.read_csv('./eloData/sample_submission.csv', header=0).head(5)
# 查看数据集基本信息
pd.read_csv('./eloData/train.csv', header=0).info()

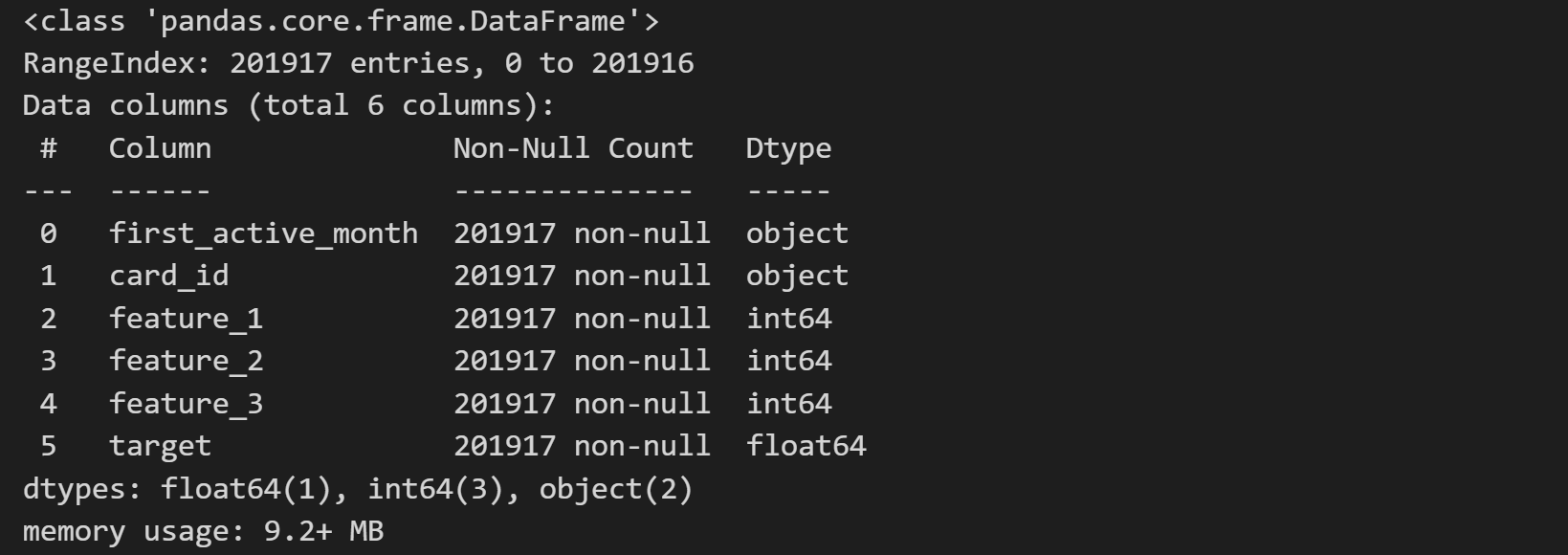
总的来说,数据表主要分为三类:
(1)基本信息数据集,Data_Dictionary数据字典和sample_submission提交结果格式(card_id, target),官网给出评估指标为RMSE,target为用户的忠诚度评分(回归);
(2)必要数据集,train和test数据集,在train上训练,test上预测;
(3)补充数据集,historical_transactions、new_merchant_transactions和merchants数据集,前两个记录了test和train中信用卡的消费记录,最后一个是两个数据集中商铺信息(某特征)的进一步解释。在实际建模中,纳入更多数据信息进行规律挖掘,可能达到更好的效果。
二、train和test的解读与初步探索
1、train和test数据集解读
# 读取数据
train = pd.read_csv('./eloData/train.csv')
test = pd.read_csv('./eloData/test.csv')
# 查看数据集规模
(train.shape,test.shape)

训练集201917条数据(含标签),测试集123623条数据(无标签)
# 1、train:训练数据集
# 查看前5条数据
train.head(5)
# 查看数据集信息
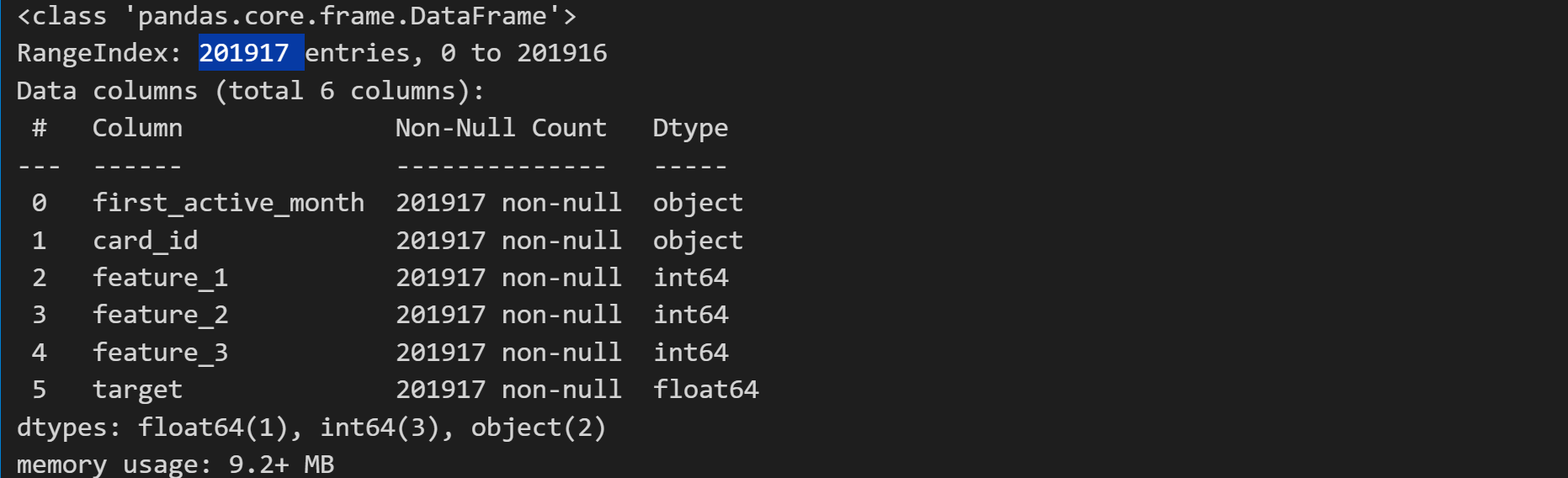
train.info()
# 回顾数据字典中的train表,查看train数据集中各字段解释
pd.read_excel('./eloData/Data_Dictionary.xlsx', header=2, sheet_name='train')

# 2、test:测试数据集
# 查看前5条数据,和submission一致
test.head(5)
# test数据集信息
test.info()
# test数据集的字段描述与train一致


实际比赛过程中,由于test测试集的标签“不可知”(无标签),所以需要在训练集train上划分出验证集来进行模型泛化能力评估。
2、数据质量分析
对数据集进行简单的数据探索。在实际建模过程中,需要校验数据的正确性、检测缺失值、异常值等情况。
2.2.1 数据正确性校验
数据正确性,指的是数据本身是否符合基本逻辑,例如此处信用卡id作为建模分析对象的唯一标识,我们需要验证其是否确实唯一,并且训练集和测试集信用卡id无重复。
# 检验训练集id无重复
train['card_id'].nunique() == train.shape[0]
# 检验测试集id无重复
test['card_id'].nunique() == test.shape[0]
# 检验训练集和测试集id都是唯一值,两者没有重复id
test['card_id'].nunique()+ train['card_id'].nunique() == len(set(test['card_id'].values.tolist() + train['card_id'].values.tolist()))

2.2.2 数据缺失情况
# 按列求缺失值并汇总
train.isnull().sum()
test.isnull().sum()
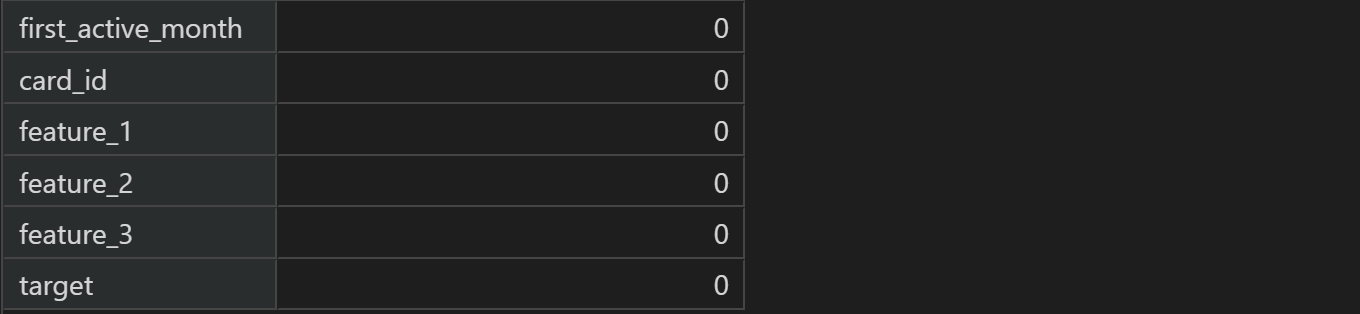

能够发现数据集基本无缺失值,测试集中的唯一一个缺失值我们可以通过多种方式来进行填补,整体来说一条缺失值并不会对整体建模造成太大影响。
2.2.3 数据异常值(连续型变量)
由于没有对特征进行处理,这里只分析标签列(连续值)的异常值情况。查看数据的基本统计信息及数据分布情况。
# 查看target列的描述性统计信息
statistics = train['target'].describe()
statistics
# 由于该列是连续变量,可以借助概率密度直方图查看数据分布情况
import seaborn as sns
import matplotlib.pyplot as plt
sns.set()
sns.histplot(train['target'], kde=True)


能够发现,大部分用户忠诚度评分都集中在[-10,10]之间,并且基本符合正态分布,唯一需要注意的是有个别异常值取值在-30以下,该数据在后续分析中需要额外注意。我们可以简单查看有多少用户的标签数值是小于30的:
(train['target'] < -30).sum() # 2207个,约占整体20万数据的1%。

当然,对于连续变量,一般可以采用 3 δ 3\delta 3δ原则进行异常值识别,此处我们也可以简单计算下异常值范围及异常值数量
# 异常值范围
outline = statistics.loc['mean'] - 3 * statistics.loc['std']
outline
# 计算异常值数量
num_outliers = (train['target'] < -abs(outline)).sum() + (train['target'] > abs(outline)).sum()
num_outliers

由于这里的标签值是根据主办方人工计算得到的值,因此该异常值可能为某些特殊用户的标记,不宜进行异常值处理,而应该将其单独视作特殊的一类,在后续建模分析时候单独对此类用户进行特征提取与建模分析。
3、规律一致性分析(竞赛需要)
接下来,进行训练集和测试集的规律一致性分析。
所谓规律一致性,指的是需要对训练集和测试集特征数据的分布进行简单比对,以“确定”两组数据是否诞生于同一个总体,即两组数据是否都遵循着背后总体的规律,即两组数据是否存在着规律一致性。
我们知道,尽管机器学习并不强调样本-总体的概念,但在训练集上挖掘到的规律要在测试集上起到预测效果,就必须要求这两部分数据受到相同规律的影响。一般来说,对于标签未知的测试集,我们可以通过特征的分布规律来判断两组数据是否取自同一总体。
2.3.1 单变量分布(离散型变量)
首先我们先进行简单的单变量分布规律的对比。由于数据集中四个变量都是离散型变量,因此其分布规律我们可以通过概率分布来进行比较。
# 特征列名 首次激活月份,特征1,特征2,特征3
features = ['first_active_month','feature_1','feature_2','feature_3']
# 训练集/测试集样本总数
train_count = train.shape[0]
test_count = test.shape[0]
for feature in features:
# 不同取值水平汇总后排序再除以样本总数,概率分布图
(train[feature].value_counts().sort_index()/train_count).plot()
(test[feature].value_counts().sort_index()/test_count).plot()
plt.legend(['train','test'])
plt.xlabel(feature)
plt.ylabel('ratio')
plt.show()
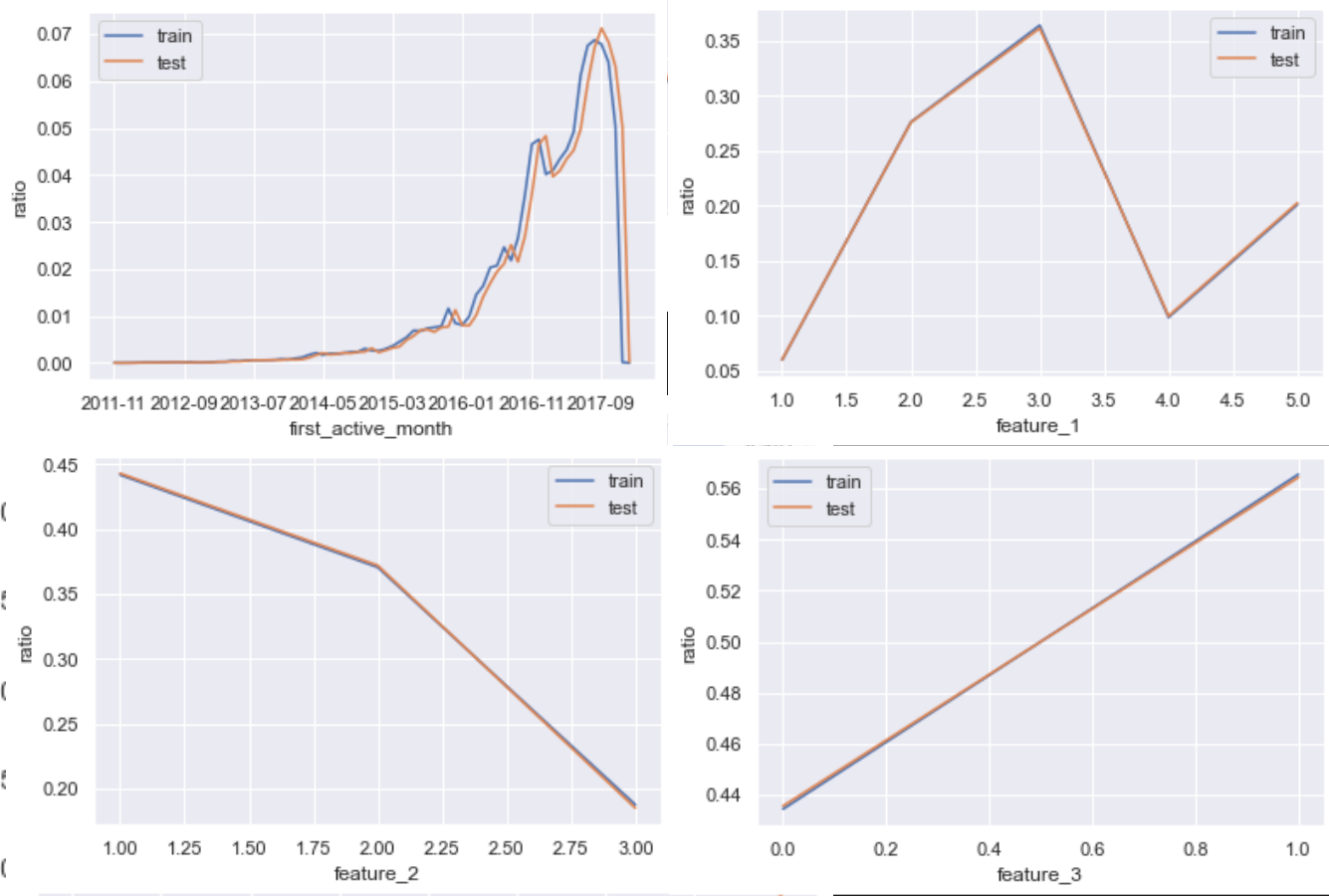
train和test数据集的数据规律(单变量分布)基本一致。
2.3.2 多变量联合分布
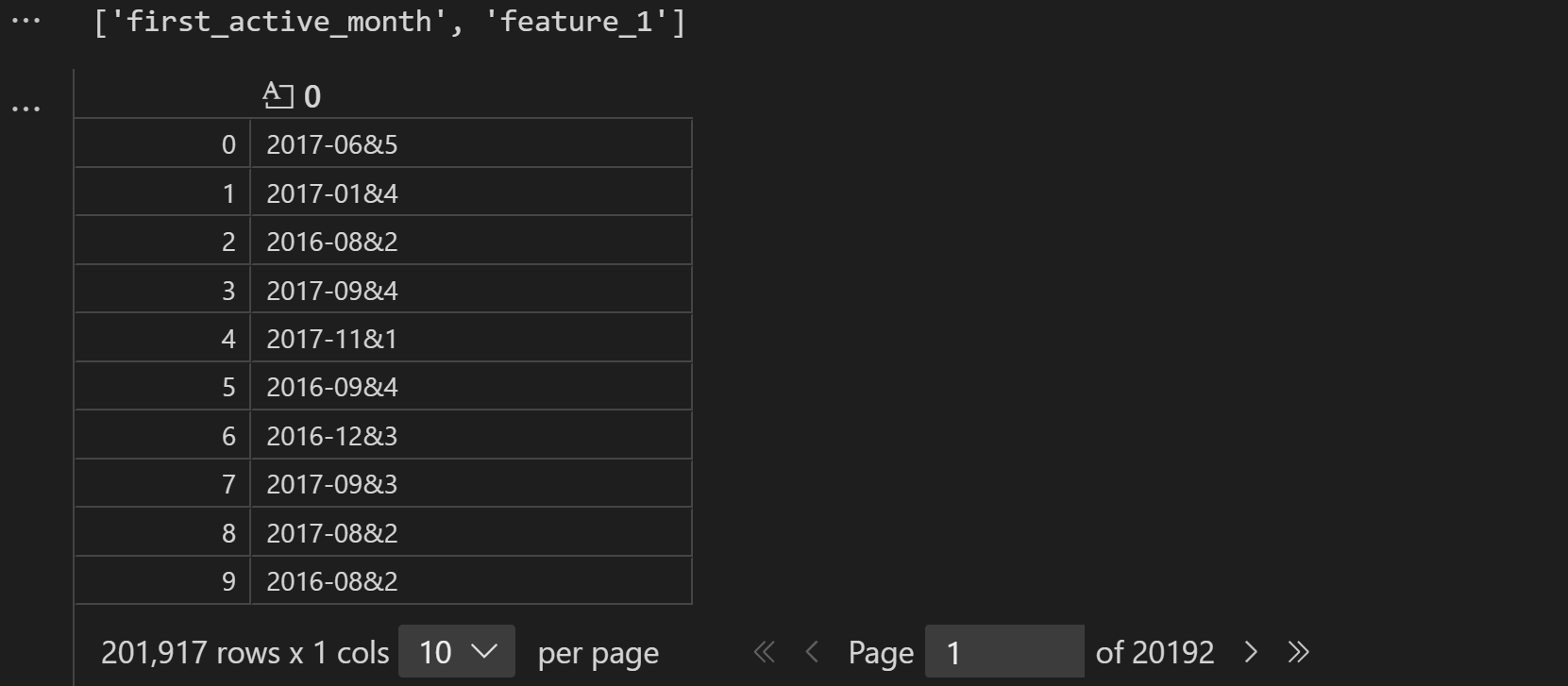
接下来,我们进一步查看联合变量分布。所谓联合概率分布,指的是将离散变量两两组合,然后查看这个新变量的相对占比分布。例如特征1有0/1两个取值水平,特征2有A/B两个取值水平,则联合分布中就将存在0A、0B、1A、1B四种不同取值水平,然后进一步查看这四种不同取值水平出现的分布情况。
# 函数:联合两个特征
def combine_feature(df):
cols = df.columns
feature1 = df[cols[0]].astype(str).values.tolist()
feature2 = df[cols[1]].astype(str).values.tolist()
# 两两结合,并去重
return pd.Series([feature1[i]+'&'+feature2[i] for i in range(df.shape[0])])
# 选取两个特征
cols = [features[0], features[1]]
cols
# 查看合并特征后结果
train_com = combine_feature(train[cols])
train_com
# 进一步计算训练集和测试集的离散型联合变量的占比分布
train_dis = train_com.value_counts().sort_index()/train_count
train_dis.head(5)
test_dis = combine_feature(test[cols]).value_counts().sort_index()/test_count
train_dis.head(5)


# 可视化训练集和测试集的分布以进行对比
# 创建新的index,两个数据集结合并去重
index_dis = pd.Series(train_dis.index.tolist() + test_dis.index.tolist()).drop_duplicates().sort_values()
# 对缺失值填补为0
(index_dis.map(train_dis).fillna(0)).plot()
(index_dis.map(train_dis).fillna(0)).plot()
# 绘图
plt.legend(['train','test'])
plt.xlabel('&'.join(cols))
plt.ylabel('ratio')
plt.show()
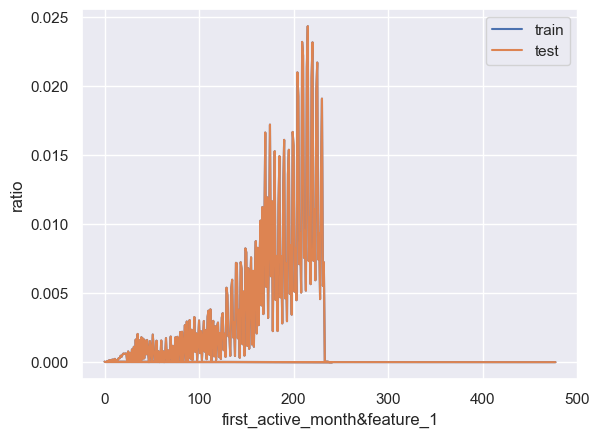
能够发现其分布基本一致。当然我们可以通过如下代码快速致性所有两两变量联合分布的比较:
n = len(features)
for i in range(n-1):
for j in range(i+1, n):
cols = [features[i], features[j]]
train_dis = combine_feature(train[cols]).value_counts().sort_index()/train_count
test_dis = combine_feature(test[cols]).value_counts().sort_index()/test_count
index_dis = pd.Series(train_dis.index.tolist() + test_dis.index.tolist()).drop_duplicates().sort_values()
(index_dis.map(train_dis).fillna(0)).plot()
(index_dis.map(train_dis).fillna(0)).plot()
plt.legend(['train','test'])
plt.xlabel('&'.join(cols))
plt.ylabel('ratio')
plt.show()

能够发现所有联合变量的占比分布基本一致。数据集整体质量较高,且基本可以确认,训练集和测试集取自同一样本总体。
2.3.3 规律一致性分析的实际作用
在实际建模过程中,规律一致性分析是非常重要但又经常容易被忽视的一个环节。通过规律一致性分析,我们可以得出非常多的可用于后续指导后续建模的关键性意见。通常我们可以根据规律一致性分析得出以下基本结论:
(1).如果分布非常一致,则说明所有特征均取自同一整体,训练集和测试集规律拥有较高一致性,模型效果上限较高,建模过程中应该更加依靠特征工程方法和模型建模技巧提高最终预测效果;
(2).如果分布不太一致,则说明训练集和测试集规律不太一致,此时模型预测效果上限会受此影响而被限制,并且模型大概率容易过拟合,在实际建模过程中可以多考虑使用交叉验证等方式防止过拟合,并且需要注重除了通用特征工程和建模方法外的trick的使用;
至此,我们就完成了核心数据集的数据探索,接下来,我们还将围绕其他的补充数据进行进一步的数据解读与数据清洗,并为最终的建模工作做好相关准备。
三、交易数据和商户数据的数据探索与数据清洗
在对train和test数据集完成探索性分析之后,接下来我们需要进一步围绕官方给出的商户数据与信用卡交易数据进行解读和分析,并对其进行数据清洗,从而为后续的特征工程和算法建模做准备。
1、数据预处理步骤
一般来说,在数据解读、数据探索和初步数据清洗都是同步进行的,都是前期非常重要的工作事项。
(1)数据解读的目的是为了快速获取数据集的基本信息,通过比对官方给出的字段解释,快速了解数据集的字段含义,这对于许多复杂数据场景下的建模是非常有必要的。
(2)数据探索,顾名思义,就是快速了解数据集的基本数据情况,主要工作包括数据正确性校验和数据质量分析,核心目的是为了能够快速了解各字段的基本情况,包括默认各字段的数据类型、数据集是否存在数据不一致的情况、数据集重复值情况、缺失值情况等,当然,通过一系列的数据探索,也能够快速加深对数据集的理解。
(3)数据清洗,指的是在建模/特征工程之前进行的必要的调整,以确保后续操作可执行,包括数据字段类型调整、重复值处理、缺失值处理等等,当然,有些操作可能在后续会进行些许优化,比如数据清洗阶段我们可以先尝试进行较为简单的缺失值填补,在后续的建模过程中我们还可以根据实际建模结果来调整缺失值填补策略。
我们也可将数据探索与数据清洗的过程总结如下:
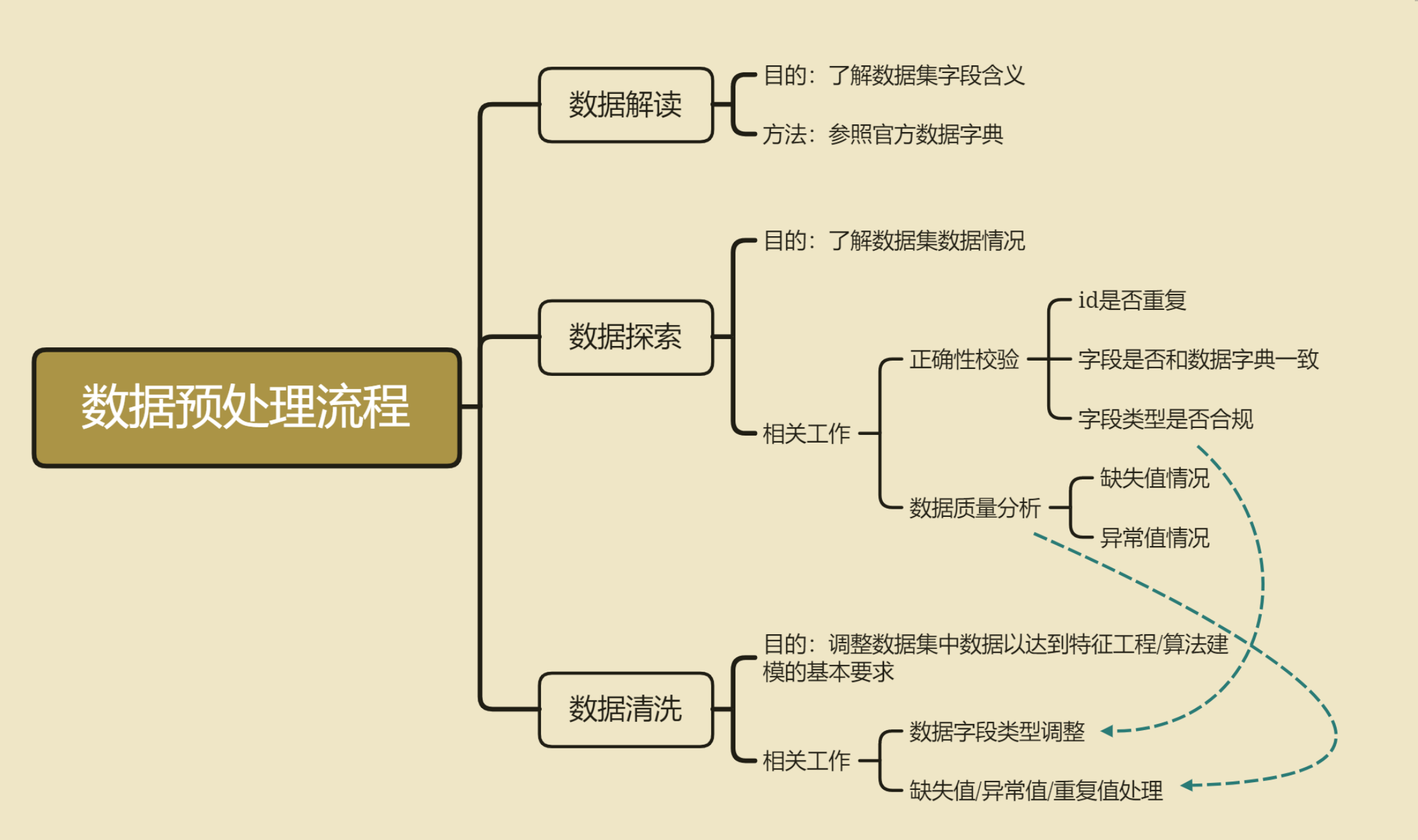
接下来我们将对商户数据、交易数据的三张表进行数据探索和数据清洗。根据主办方给出的拓展信息,也就是信用卡交易记录和商户相关数据,这几张表中同时包含了训练集、测试集中所有信用卡的部分记录,是挖掘有效信息、提高模型建模效果的重要渠道。
2、商户数据解读与探索
首先我们先来查看数据量相对较小的商户信息表,也就是merchants.csv中的相关信息。
3.2.1 数据解读
主要查看数据集的前五条数据、数据集信息和字典字段中的字段解释
# 导入数据
merchant = pd.read_csv('./eloData/merchants.csv', header=0)
# 查看数据的前5行
merchant.head(5)
# 查看数据的基本信息
merchant.info()
# 在数据字典中查看各字段的解释
df = pd.read_excel('./eloData/Data_Dictionary.xlsx', header=2, sheet_name='merchant')
df
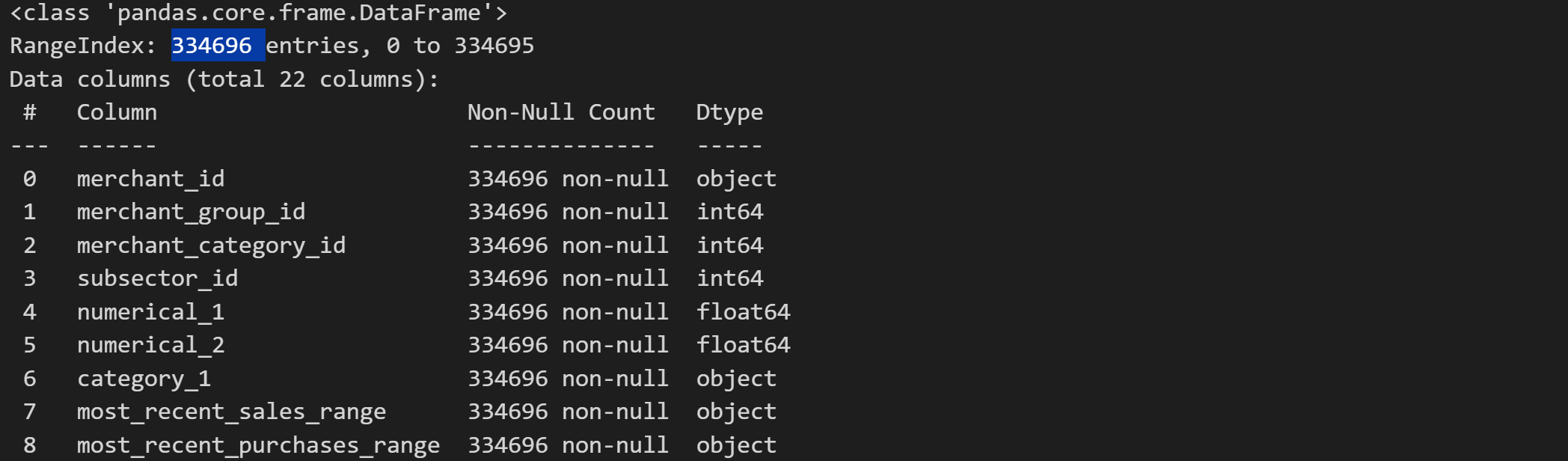
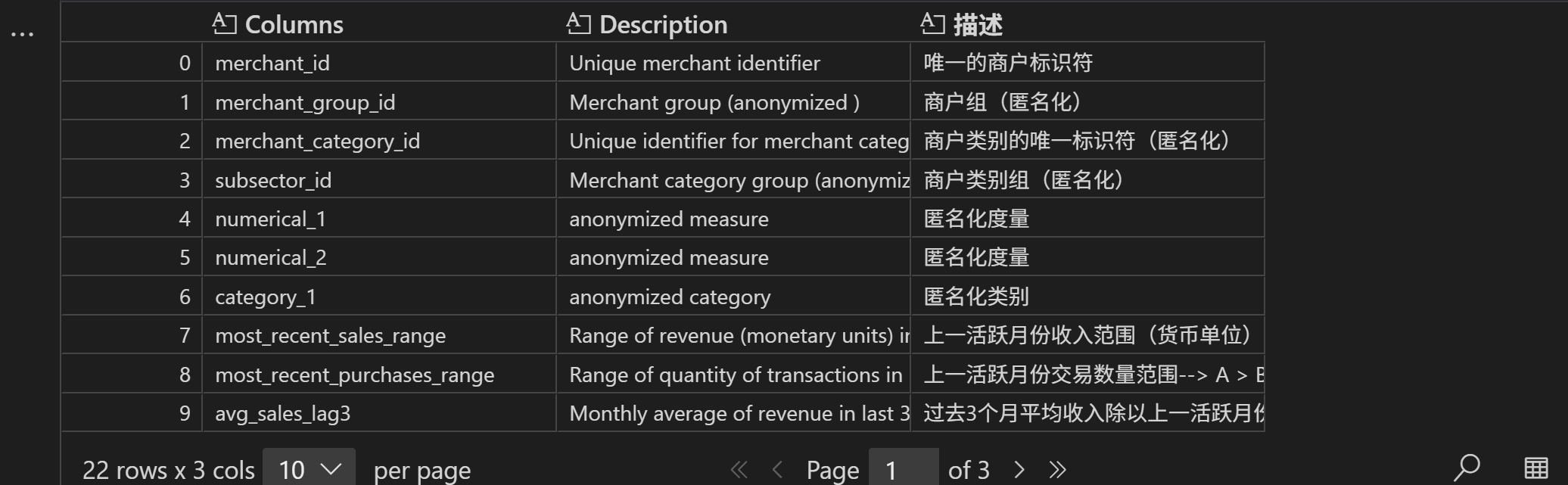

能够发现,数据表中提供不仅提供了商户的基本属性字段(如类别和商品种群等),同时也提供了商户近期的交易数据。不过和此前一样,仍然存在大量的匿名特征。
3.2.2 数据探索
在理解数据字段的基本含义后,接下来我们进一步进行数据探索:简单对数据集的基本情况进行验证。(1)检查商户id是否唯一;(2)商户数据集的字段与数据字典的字段是否一致;(3)缺失值情况。
- 正确性校验
# 商户id是否唯一,结果表明存在一个商户有多条记录的情况
merchant.shape, merchant['merchant_id'].nunique()
# 简单验证商户数据特征是否和数据字典中特征一致
pd.Series(merchant.columns.tolist()).sort_values().values == pd.Series([va[0] for va in df.values]).sort_values().values
# 查看商户数据缺失值情况
merchant.isnull().sum()


结果表明(1)存在一个商户有多条记录的情况,(2)能够看出商户特征与字典特征完全一致,(3)能够发现,第二个匿名分类变量存在较多缺失值,而avg_sales_lag3/6/12缺失值数量一致,则很有可能是存在13个商户同时缺失了这三方面信息。其他数据没有缺失,数据整体来看较为完整。
3.2.3 数据预处理
接下来对商户数据进行数据预处理。由于还未进行特征工程,此处预处理只是一些不影响后续特征工程、建模或多表关联的、较为初步但又是必须要做的预处理。
# 根据字段的说明对不同属性特征进行统一的划分
# 离散字段
category_cols = ['merchant_id', 'merchant_group_id', 'merchant_category_id',
'subsector_id', 'category_1',
'most_recent_sales_range', 'most_recent_purchases_range',
'category_4', 'city_id', 'state_id', 'category_2']
# 连续字段
numeric_cols = ['numerical_1', 'numerical_2',
'avg_sales_lag3', 'avg_purchases_lag3', 'active_months_lag3',
'avg_sales_lag6', 'avg_purchases_lag6', 'active_months_lag6',
'avg_sales_lag12', 'avg_purchases_lag12', 'active_months_lag12']
# 检验特征是否划分完全
assert len(category_cols) + len(numeric_cols) == merchant.shape[1]
3.2.3.1离散字段的数据预处理
查看离散变量的数据情况,补充缺失值,并进行字典编码。
- 离散变量数据情况
# 查看离散变量的取值水平
merchant[category_cols].nunique()
# 查看离散变量目前的类别
merchant[category_cols].dtypes
# 查看离散变量的缺失值情况
merchant[category_cols].isnull().sum()

- 离散变量的缺失值处理
注意到离散变量中的category_2存在较多缺失值,由于该分类变量取值水平为1-5,因此可以将缺失值先标注为-1,方便后续进行数据探索。
# 查看category_2的取值水平
merchant['category_2'].value_counts(dropna=False)
# 对于离散变量的缺失值,使用-1进行标注
merchant['category_2'] = merchant['category_2'].fillna(-1)

- 离散变量字典编码
接下来对离散变量进行字典编码,即将object对象类型按照sort顺序进行数值化(整数)编码。例如原始category_1取值为Y/N,通过sort排序后N在Y之前,因此在重新编码时N取值会重编码为0、Y取值会重编码为1。以此类推。
变量类型应该是有三类,分别是连续性变量、名义型变量以及有序变量。(1)连续变量较好理解;(2)名义变量,指的是没有数值大小意义的分类变量,例如用1表示女、0表示男,0、1只是作为性别的指代,而没有1>0的含义,通常对其进行独热编码;(3)有序变量,也是离散型变量,但却有数值大小含义,如上述most_recent_purchases_range字段,销售等级中A>B>C>D>E,该离散变量的5个取值水平是有严格大小意义的,在实际建模过程中,如果不需要提取有序变量(离散变量)的数值大小信息的话,可以考虑将其和名义变量一样进行独热编码。但本阶段初级预处理时暂时不考虑这些问题,先统一将object类型转化为数值型。
# 字典编码函数
def change_object_cols(se):
value = se.unique().tolist()
value.sort()
return se.map(pd.Series(range(len(value)), index=value)).values
# 对merchant对象中的四个object类型列进行类别转化
for col in ['category_1', 'most_recent_sales_range', 'most_recent_purchases_range', 'category_4']:
# 查看原始类别
print(merchant[col].unique().tolist())
# 对object类型列进行字典编码
merchant[col] = change_object_cols(merchant[col])
# 查看转化后的类别
print(merchant[col].unique().tolist())

3.2.3.2 连续字段的数据预处理
查看连续变量的数据情况,处理其中的无穷值和缺失值。
- 查看连续变量的数据情况
# 查看连续变量的类别
merchant[numeric_cols].dtypes
# 连续变量的缺失值情况
merchant[numeric_cols].isnull().sum()
# 查看连续变量整体情况
merchant[numeric_cols].describe()
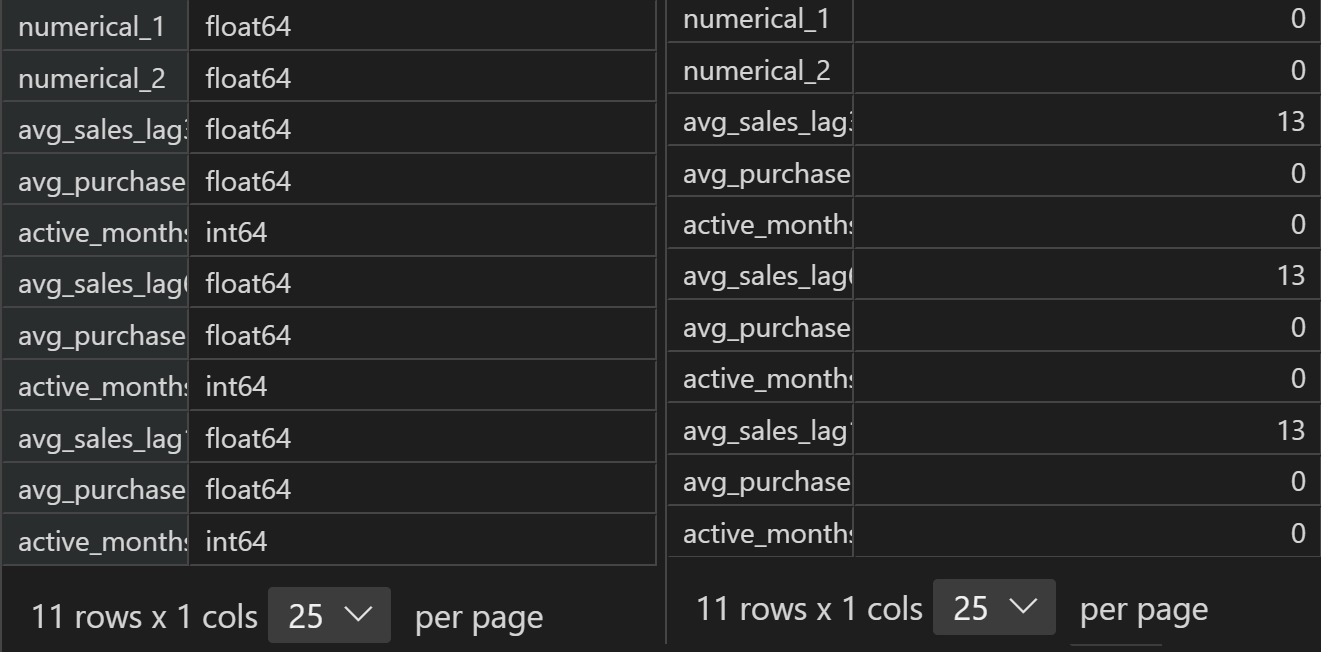
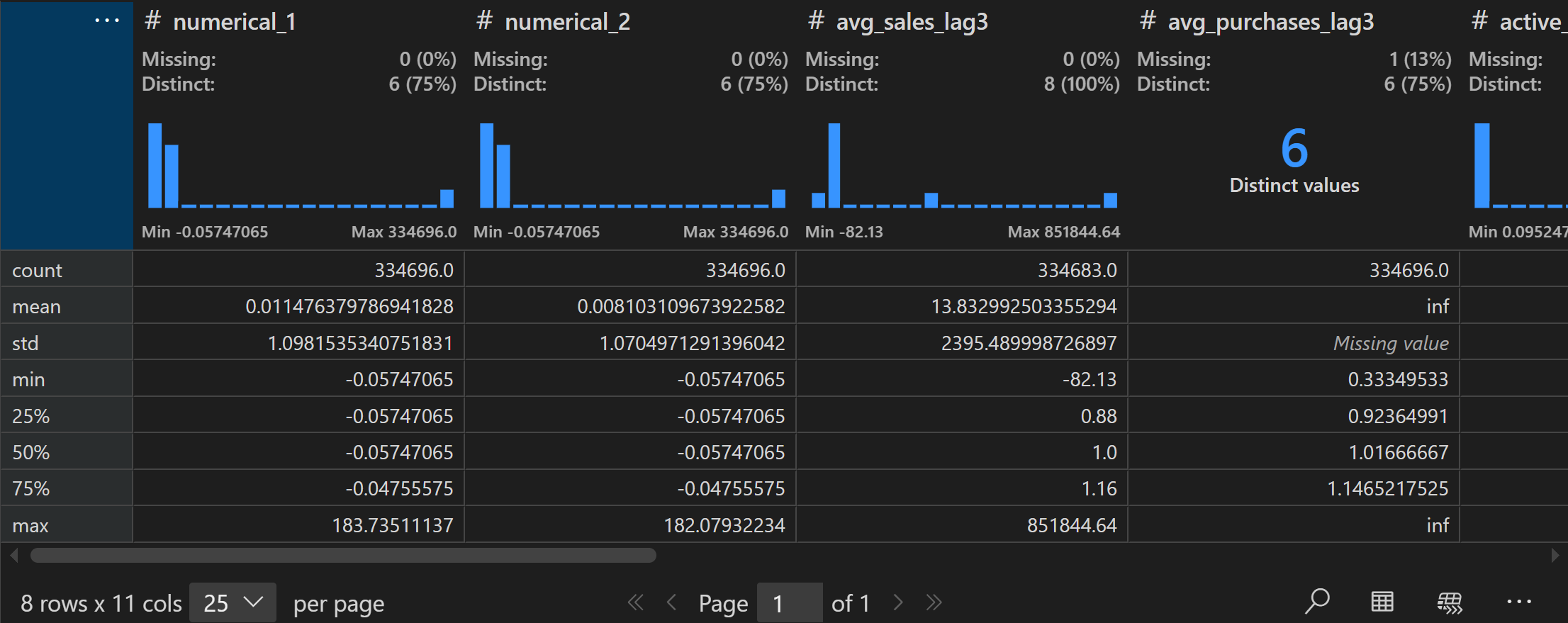
- 处理无穷值和缺失值
据此我们发现连续型变量中存在部分缺失值,并且部分连续变量还存在无穷值inf,需要对其进行简单处理。
# 将inf替换为该列的最大值
inf_cols = ['avg_purchases_lag3', 'avg_purchases_lag6', 'avg_purchases_lag12']
merchant[inf_cols] = merchant[inf_cols].replace(np.inf, merchant[inf_cols].replace(np.inf, -99).max())
# 缺失值只有13个,进行简单的均值填充
for col in numeric_cols:
merchant[col] = merchant[col].fillna(merchant[col].mean())
# 查看连续变量处理后的整体情况
merchant[numeric_cols].describe()
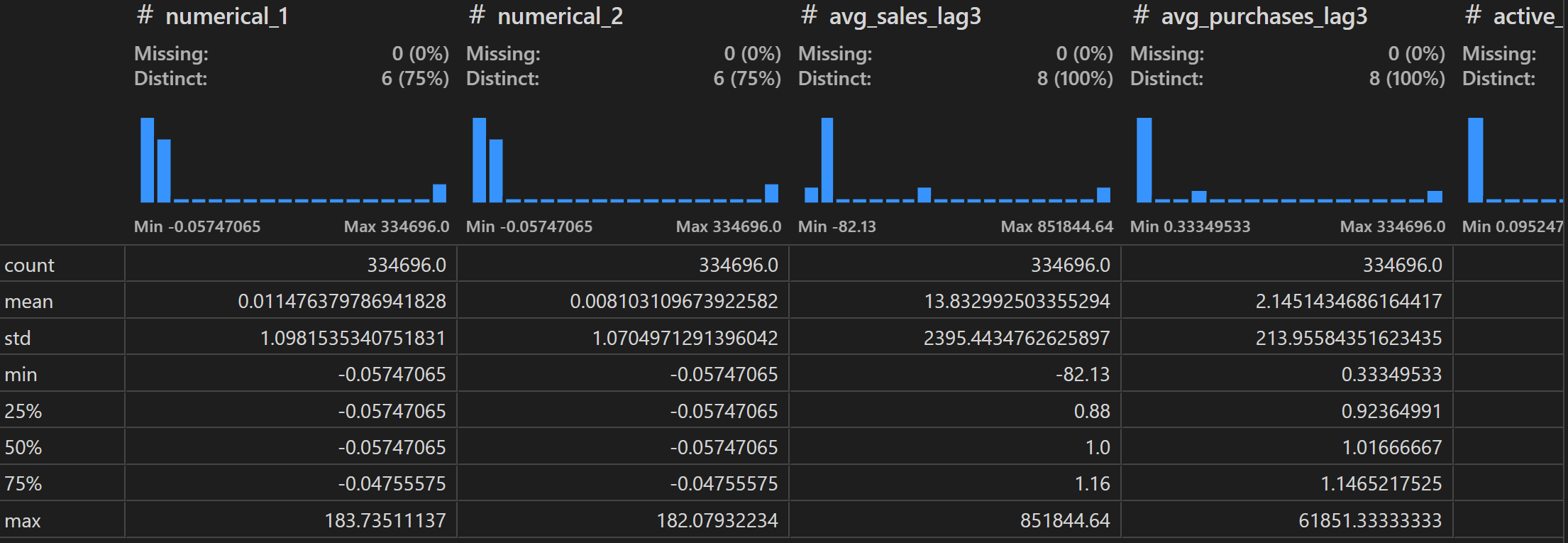
商户数据的预处理工作完成。
3、信用卡交易数据的解读与探索
接下来对信用卡交易数据进行解读与探索。交易数据是本次竞赛中给出的规模最大、同时也是信息量最大的数据集,在后续建模过程中将发挥至关重要的作用。
3.3.1 数据解读
首先还是对数据集进行解释,以及简单验证数据集的正确性。信用卡交易记录包括了两个数据集,分别是historical_transactions和new_merchant_transactions。两个数据集字段类似,只是记录了不同时间区间的信用卡消费情况:
(1)historical_transactions:信用卡消费记录。
该数据集记录了每张信用卡在特定商户中、三个月间的消费记录。该数据集数据规模较大,文件约有2.6G,并非必要建模字段,但若能从中提取有效信息,则能够更好的辅助建模。
history_transaction = pd.read_csv('./eloData/historical_transactions.csv', header=0)
# 查看数据的前5行
history_transaction.head(5)
# 查看数据的基本信息
history_transaction.info()
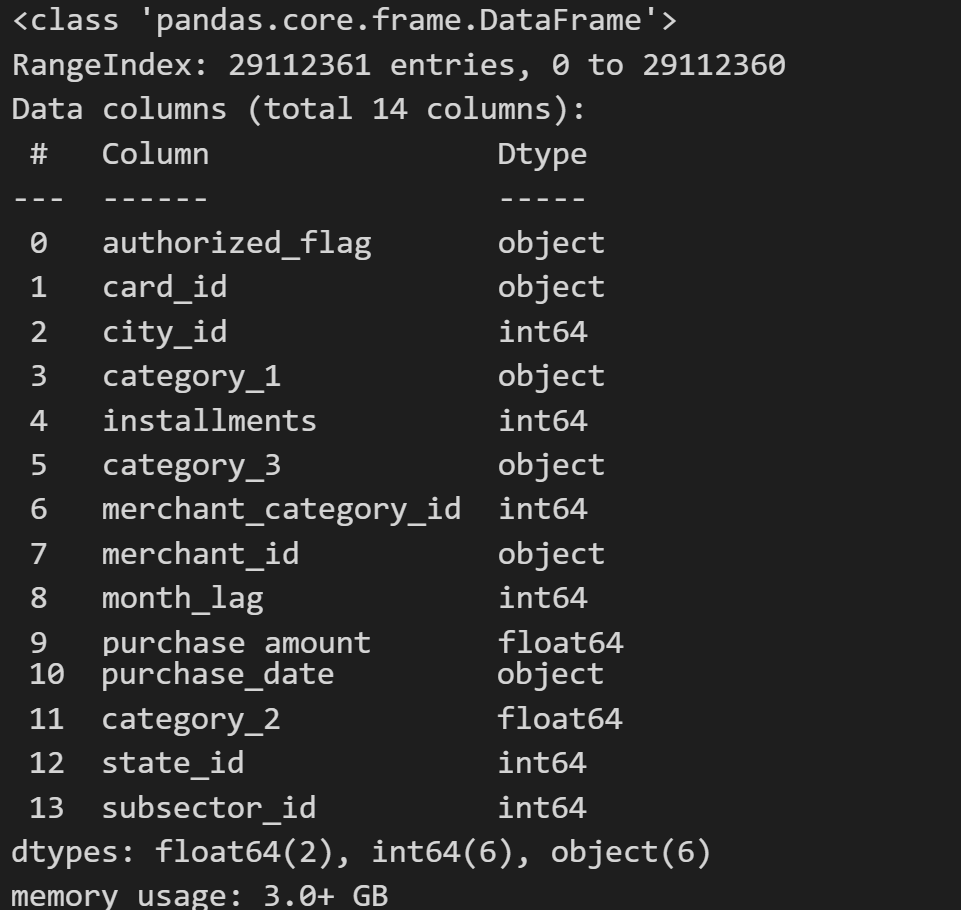
# 数据集总共包括将近三千万条数据,总共有十四个字段
# 每个字段在数据字典中的解释如下:
pd.read_excel('./eloData/Data_Dictionary.xlsx', header=2, sheet_name='history')


(2)new_merchant_transactions:信用卡近期的交易信息
信用卡在2018年2月之后的交易信息,和historical_transactions字段完全一致。
new_transaction = pd.read_csv('./eloData/new_merchant_transactions.csv', header=0)
new_transaction.head(5)
pd.read_csv('./eloData/new_merchant_transactions.csv', header=0).info()
我们发现,历史交易数据集(近三千万条数据)和最新交易数据集(近200万条数据)中,有较多字段和商家数据merchant重复,可以对其进行简单检验。
3.3.2 数据探索
(1)检查交易数据中的商户id与商户数据中的id是否对应;(2)商户数据集的字段与数据字典的字段是否一致;(3)缺失值情况。
- 检查交易数据中的商户id与商户数据中的id是否对应;
# 对比merchant数据集,获取两者的重复字段
duplicate_cols = []
for col in merchant.columns:
if col in new_transaction.columns:
duplicate_cols.append(col)
print(duplicate_cols)
# 取出交易数据表中和商户数据表重复的字段并去重
new_transaction[duplicate_cols].drop_duplicates().shape
# 商户id去重
new_transaction['merchant_id'].nunique()


- 检测字段一致性及缺失值
# 简单验证交易数据特征是否和数据字典中特征一致
df = pd.read_excel('./eloData/Data_Dictionary.xlsx', header=2, sheet_name="new_merchant_transaction")
pd.Series(new_transaction.columns.tolist()).sort_values().values == pd.Series([va[0] for va in df.values]).sort_values().values
# 查看交易数据缺失值情况
new_transaction.isnull().sum()
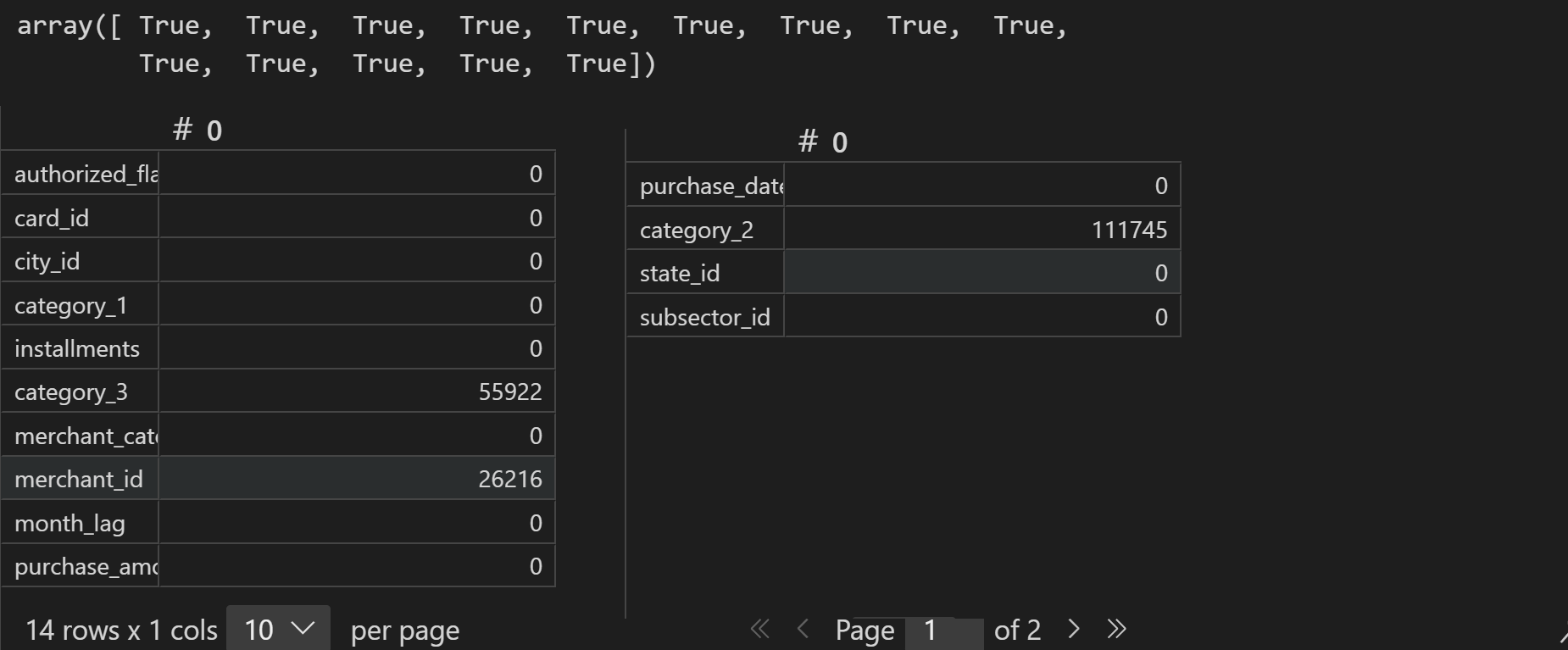
结果表明(1)可以发现交易记录中的merhcant_id信息和商户数据表中的merhcant_id并不对应(商户数据表的数据不全),造成该现象的原因可能是商铺在逐渐经营过程动态变化,新开的商铺还没有及时更新记录进去,在后续的建模过程中,我们将优先使用交易记录中表中的相应记录。(2)能够看出商户特征与字典特征完全一致,(3)能够发现,匿名分类变量1、匿名分类变量2和商铺id变量存在较多缺失值。
3.3.3 数据预处理
同样地,(1)划分离散变量和连续变量;(2)离散变量需要补充缺失值,并进行object的字典编码(除id以外);(3)连续变量需要处理其中的无穷值和缺失值。
# 连续/离散字段标注
numeric_cols = ['installments', 'month_lag', 'purchase_amount']
category_cols = ['authorized_flag', 'card_id', 'city_id', 'category_1',
'category_3', 'merchant_category_id', 'merchant_id', 'category_2', 'state_id',
'subsector_id']
time_cols = ['purchase_date']
assert len(numeric_cols) + len(category_cols) + len(time_cols) == new_transaction.shape[1]
# 查看离散变量情况
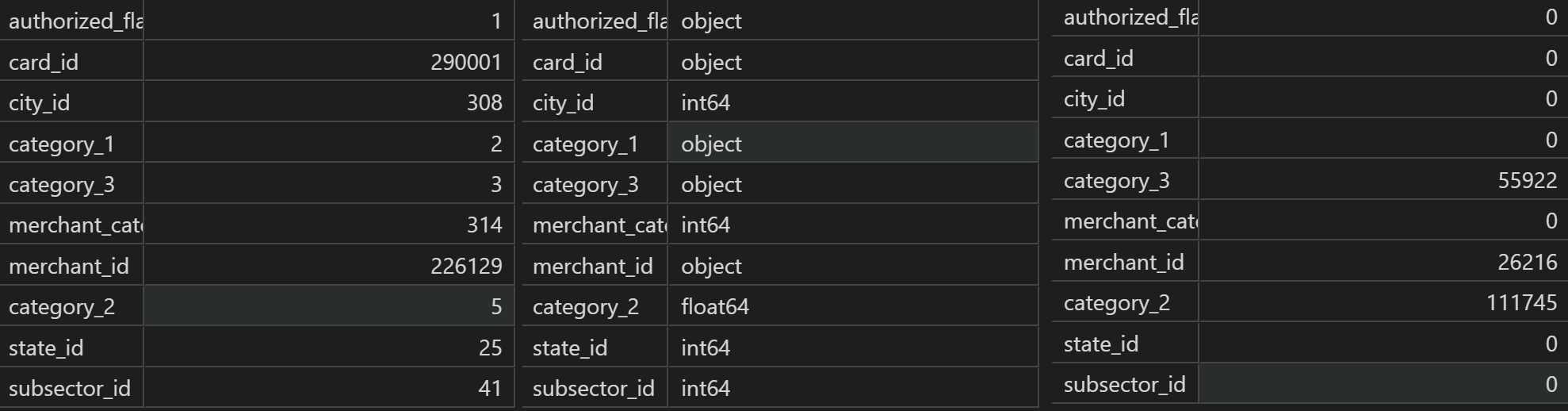
new_transaction[category_cols].nunique() # 取值水平
new_transaction[category_cols].dtypes # 数据类型
new_transaction[category_cols].isnull().sum() # 缺失值情况
# 补充缺失值
new_transaction[category_cols] = new_transaction[category_cols].fillna(-1)
# 字典编码
def change_object_cols(se):
value = se.unique().tolist()
value.sort()
return se.map(pd.Series(range(len(value)), index=value)).values
for col in ['authorized_flag', 'category_1', 'category_3']:
new_transaction[col] = change_object_cols(new_transaction[col].fillna(-1).astype(str))
# 查看连续变量的类别
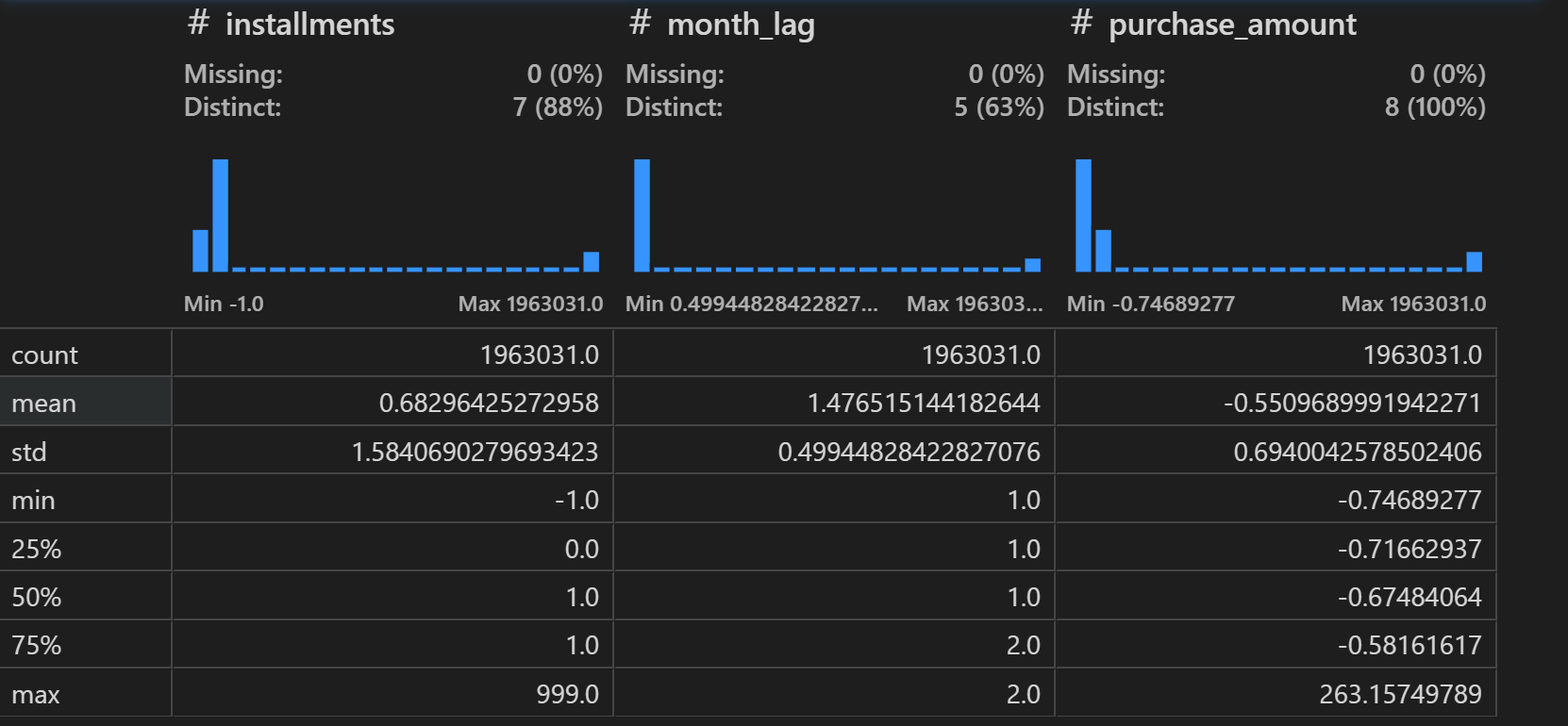
new_transaction[numeric_cols].dtypes
# 连续变量的缺失值情况
new_transaction[numeric_cols].isnull().sum()
# 查看连续变量整体情况
new_transaction[numeric_cols].describe()

至此,我们就完成了几张表的数据预处理工作。
4、对上述数据清洗工作进行总结
3.4.1 回顾商户数据、交易数据清洗流程
当然,由于上述工作较为繁琐,我们简单总结上述针对商户数据和交易数据的完整步骤如下:
(1)商户数据merchants.csv
- 划分连续字段和离散字段;
- 对字符型离散字段进行字典排序编码;
- 对缺失值处理,此处统一使用-1进行缺失值填充,本质上是一种标注;
- 对连续性字段的无穷值进行处理,用该列的最大值进行替换;
- 去除重复数据;
(2)交易数据new_merchant_transactions.csv和historical_transactions.csv
- 划分字段类型,分为离散字段、连续字段和时间字段;
- 和商户数据的处理方法一样,对字符型离散字段进行字典排序,对缺失值进行统一填充;
- 对新生成的购买欲分离散字段进行字典排序编码;
- 最后对多表进行拼接,并且通过month_lag字段是否大于0来进行区分。
3.4.2 创建清洗后数据
结合训练集和测试集的清洗流程,我们可以在此统一执行所有数据的数据清洗工作,并将其最终保存为本地文件,方便后续特征工程及算法建模过程使用,其流程如下:
(1)读取数据
import gc
import time
import numpy as np
import pandas as pd
from datetime import datetime
train = pd.read_csv('data/train.csv')
test = pd.read_csv('data/test.csv')
merchant = pd.read_csv('data/merchants.csv')
new_transaction = pd.read_csv('data/new_merchant_transactions.csv')
history_transaction = pd.read_csv('data/historical_transactions.csv')
# 字典编码函数
def change_object_cols(se):
value = se.unique().tolist()
value.sort()
return se.map(pd.Series(range(len(value)), index=value)).values
(2) 训练集/测试集的数据预处理
# 对首次活跃月份进行编码
se_map = change_object_cols(train['first_active_month'].append(test['first_active_month']).astype(str))
train['first_active_month'] = se_map[:train.shape[0]]
test['first_active_month'] = se_map[train.shape[0]:]
# 测试集/训练集导出
train.to_csv("preprocess/train_pre.csv", index=False)
test.to_csv("preprocess/test_pre.csv", index=False)
# 清理内存
del train
del test
gc.collect()
(3)商户信息预处理
# 1、根据业务含义划分离散字段category_cols与连续字段numeric_cols。
category_cols = ['merchant_id', 'merchant_group_id', 'merchant_category_id',
'subsector_id', 'category_1',
'most_recent_sales_range', 'most_recent_purchases_range',
'category_4', 'city_id', 'state_id', 'category_2']
numeric_cols = ['numerical_1', 'numerical_2',
'avg_sales_lag3', 'avg_purchases_lag3', 'active_months_lag3',
'avg_sales_lag6', 'avg_purchases_lag6', 'active_months_lag6',
'avg_sales_lag12', 'avg_purchases_lag12', 'active_months_lag12']
# 2、对非数值型的离散字段进行字典排序编码。
for col in ['category_1', 'most_recent_sales_range', 'most_recent_purchases_range', 'category_4']:
merchant[col] = change_object_cols(merchant[col])
# 3、为了能够更方便统计,进行缺失值的处理,对离散字段统一用-1进行填充。
merchant[category_cols] = merchant[category_cols].fillna(-1)
# 4、对离散型字段探查发现有正无穷值,这是特征提取以及模型所不能接受的,因此需要对无限值进行处理,此处采用最大值进行替换。
inf_cols = ['avg_purchases_lag3', 'avg_purchases_lag6', 'avg_purchases_lag12']
merchant[inf_cols] = merchant[inf_cols].replace(np.inf, merchant[inf_cols].replace(np.inf, -99).max().max())
# 5、平均值进行填充,后续有需要再进行优化处理。
for col in numeric_cols:
merchant[col] = merchant[col].fillna(merchant[col].mean())
# 6、去除与transaction交易记录表格重复的列,以及merchant_id的重复记录。
duplicate_cols = ['merchant_id', 'merchant_category_id', 'subsector_id', 'category_1', 'city_id', 'state_id', 'category_2']
merchant = merchant.drop(duplicate_cols[1:], axis=1)
merchant = merchant.loc[merchant['merchant_id'].drop_duplicates().index.tolist()].reset_index(drop=True)
# 7、对商户信息表格进行保存
merchant.to_csv("./preprocess/merchant_pre.csv", index=False)
处理完后先不着急导出或删除,后续需要和交易数据进行拼接。
(4)交易数据预处理
# 1、为了统一处理,首先拼接new和history两张表格,后续可以month_lag>=0进行区分。
transaction = pd.concat([new_transaction, history_transaction], axis=0, ignore_index=True)
del new_transaction
del history_transaction
gc.collect()
# 2、同样划分离散字段、连续字段以及时间字段。
numeric_cols = [ 'installments', 'month_lag', 'purchase_amount']
category_cols = ['authorized_flag', 'card_id', 'city_id', 'category_1',
'category_3', 'merchant_category_id', 'merchant_id', 'category_2', 'state_id',
'subsector_id']
time_cols = ['purchase_date']
# 3、可仿照merchant的处理方式对字符型的离散特征进行字典序编码以及缺失值填充。
for col in ['authorized_flag', 'category_1', 'category_3']:
transaction[col] = change_object_cols(transaction[col].fillna(-1).astype(str))
transaction[category_cols] = transaction[category_cols].fillna(-1)
transaction['category_2'] = transaction['category_2'].astype(int)
# 4、进行时间段的处理,简单起见进行月份、日期的星期数(工作日与周末)、以及时间段(上午、下午、晚上、凌晨)的信息提取。
transaction['purchase_month'] = transaction['purchase_date'].apply(lambda x:'-'.join(x.split(' ')[0].split('-')[:2]))
transaction['purchase_hour_section'] = transaction['purchase_date'].apply(lambda x: x.split(' ')[1].split(':')[0]).astype(int)//6
transaction['purchase_day'] = transaction['purchase_date'].apply(lambda x: datetime.strptime(x.split(" ")[0], "%Y-%m-%d").weekday())//5
del transaction['purchase_date']
# 5、对新生成的购买月份离散字段进行字典序编码
transaction['purchase_month'] = change_object_cols(transaction['purchase_month'].fillna(-1).astype(str))
# 6、保存预处理数据
transaction.to_csv("./preprocess/transaction_pre.csv", index=False)
完成交易数据预处理后,即可进行交易数据和商铺数据的表格合并。
(5)表格合并
在合并的过程中,有两种处理方案,(1)其一是对缺失值进行-1填补,然后将所有离散型字段化为字符串类型(为了后续字典合并做准备),(2)其二则是新增两列,分别是purchase_day_diff和purchase_month_diff,其数据为交易数据以card_id进行groupby并最终提取出purchase_day/month并进行差分的结果。
# 五、表格合并,方案一,数据标准化
transaction = pd.read_csv("preprocess/transaction_pre.csv")
merchant = pd.read_csv("preprocess/merchant_pre.csv")
# 为了方便特征的统一计算将其merge合并,重新划分相应字段种类。
cols = ['merchant_id', 'most_recent_sales_range', 'most_recent_purchases_range', 'category_4']
transaction = pd.merge(transaction, merchant[cols], how='left', on='merchant_id')
numeric_cols = ['purchase_amount', 'installments']
category_cols = ['authorized_flag', 'city_id', 'category_1',
'category_3', 'merchant_category_id','month_lag','most_recent_sales_range',
'most_recent_purchases_range', 'category_4',
'purchase_month', 'purchase_hour_section', 'purchase_day']
id_cols = ['card_id', 'merchant_id']
# 方案一:对缺失值进行-1填补,然后将所有离散型字段化为字符串类型
transaction[cols[1:]] = transaction[cols[1:]].fillna(-1).astype(int)
transaction[category_cols] =transaction[category_cols].fillna(-1).astype(str)
transaction.to_csv("./preprocess/transaction_norm_pre.csv", index=False)
del transaction
gc.collect()
# 五、表格合并,方案二,特征工程
transaction = pd.read_csv("preprocess/transaction_pre.csv")
merchant = pd.read_csv("preprocess/merchant_pre.csv")
cols = ['merchant_id', 'most_recent_sales_range', 'most_recent_purchases_range', 'category_4']
transaction = pd.merge(transaction, merchant[cols], how='left', on='merchant_id')
numeric_cols = ['purchase_amount', 'installments']
category_cols = ['authorized_flag', 'city_id', 'category_1',
'category_3', 'merchant_category_id','month_lag','most_recent_sales_range',
'most_recent_purchases_range', 'category_4',
'purchase_month', 'purchase_hour_section', 'purchase_day']
id_cols = ['card_id', 'merchant_id']
# 方案二:新增两列时间间隔(天数和月份),分别是purchase_day_diff和purchase_month_diff,
# 其数据为交易数据以card_id进行groupby并最终提取出purchase_day/month并进行差分的结果。
transaction['purchase_day_diff'] = transaction.groupby("card_id")['purchase_day'].diff()
transaction['purchase_month_diff'] = transaction.groupby("card_id")['purchase_month'].diff()
transaction.to_csv("./preprocess/transaction_diff_pre.csv", index=False)
del transaction
gc.collect()
# 五、表格合并,方案三,特征工程和数据标准化
transaction = pd.read_csv("preprocess/transaction_pre.csv")
merchant = pd.read_csv("preprocess/merchant_pre.csv")
cols = ['merchant_id', 'most_recent_sales_range', 'most_recent_purchases_range', 'category_4']
transaction = pd.merge(transaction, merchant[cols], how='left', on='merchant_id')
numeric_cols = ['purchase_amount', 'installments']
category_cols = ['authorized_flag', 'city_id', 'category_1',
'category_3', 'merchant_category_id','month_lag','most_recent_sales_range',
'most_recent_purchases_range', 'category_4',
'purchase_month', 'purchase_hour_section', 'purchase_day']
id_cols = ['card_id', 'merchant_id']
# 将方案一和方案二进行结合
# 1. 先做特征工程(方案二)
transaction['purchase_day_diff'] = transaction.groupby("card_id")['purchase_day'].diff()
transaction['purchase_month_diff'] = transaction.groupby("card_id")['purchase_month'].diff()
# 2. 再做数据标准化(方案一)
transaction['purchase_day_diff'] = transaction['purchase_day_diff'].fillna(-1).astype(int)
transaction['purchase_month_diff'] = transaction['purchase_month_diff'].fillna(-1).astype(int)
# 其他离散字段转字符串
transaction[cols[1:]] = transaction[cols[1:]].fillna(-1).astype(int)
transaction[category_cols] =transaction[category_cols].fillna(-1).astype(str)
# 将其导出为transaction_diff_norm_pre.csv
transaction.to_csv("./preprocess/transaction_diff_norm_pre.csv", index=False)
del transaction
gc.collect()



















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











