






特征筛选
分类问题中筛选与离散标签相关性较强的连续变量——方差分析
衡量两个离散变量是否独立使用卡方检验;衡量连续变量和离散变量是否独立使用方差分析;衡量两个连续变量之间的相关性使用Pearson / Spearman相关系数,而衡量两个连续变量之间的独立性一般需要离散后使用卡方检验。
基本流程
一、提出假设
首先第一步是提出假设,不像卡方检验的零假设那样直接明了、就是假设变量之间相互独立,方差分析的零假设会更加复杂一些。
选取某个数据集的月消费金额(连续变量)和(类别)标签作为分析的对象,方差分析零假设如下:
首先是关于该假设如何帮助我们进行特征筛选。在建模的过程中,如果月消费金额这个字段对标签取值的预测能够起到帮助作用,一定是因为这个字段对标签具备一定的区分度,例如流失用户可能普遍月消费金额比较低,那么我们就能通过月消费金额较低的角度对用户是否可能会流失进行提前的预判;反之,如果流失用户和非流失用户,这两批用户在月消费金额的角度完全看不出差异,那么月消费金额这一字段也不太可能对后续建模提供任何有效信息,该字段完全可以考虑删除。
其次是关于如何判别这两类不同的群体是否存在差异。首先,统计学里判别两个样本是否存在差异,其实是在判别这两个样本是否取自不同的总体,也就是说这两个样本的差异(如果有的话),是否是统计误差导致、还是因为抽样自不同的总体。如果能判断样本取自不同的总体,则能判断两类样本存在明显差异,反之则不行。
那要怎么判断样本是否源于不同总体呢?关于样本和总体的统计指标一致性的特点,很多时候,样本的统计指标会和总体趋于一致。例如样本的均值为1,则总体的均值很有可能也在1附近。基于此,如果两个样本的均值相差巨大,则有较大把握两个样本是来自不同总体,反之则无法判断是否来自不同总体。很明显,为了通过均值差异程度而量化的判断是否取自不同总体,需要构造统计量。
二、获取特征和标签数据
# 采用月消费金额MonthlyCharges和标签Churn字段进行分析
X_train['MonthlyCharges']
4067 79.60
3306 80.00
3391 19.00
3249 55.55
2674 20.05
...
5478 106.30
356 54.10
4908 106.15
6276 20.35
2933 24.00
Name: MonthlyCharges, Length: 5282, dtype: float64
y_train
4067 0
3306 0
3391 0
3249 0
2674 0
..
5478 0
356 0
4908 1
6276 0
2933 0
Name: Churn, Length: 5282, dtype: int64
# 标签包含两类样本:流失用户样本和非流失用户
# 非流失用户的月消费金额
cat_0 = X_train_OE['MonthlyCharges'][y_train == 0]
# 流失用户的月消费金额
cat_1 = X_train_OE['MonthlyCharges'][y_train == 1]
三、设计统计量
最关键的环节是如何构造统计量来判断两类样本均值差异程度。假设目前有n条数据被分成k组(即标签有k个类别),其中第j个类别中包含
n
j
n_j
nj条样本,并且
x
i
,
j
x_{i,j}
xi,j表示第j个类别的第i条样本,则样本整体偏差 / 样本与均值的差值平方和计算公式如下:
S
S
T
=
∑
j
=
1
k
∑
i
=
1
n
j
(
x
i
j
−
x
ˉ
)
2
,
x
ˉ
=
∑
j
=
1
k
∑
i
=
1
n
j
x
i
j
n
SST = \sum^k_{j=1}\sum^{n_j}_{i=1}(x_{ij}-\bar x)^2, \bar x = \frac{\sum^k_{j=1}\sum^{n_j}_{i=1}x_{ij}}{n}
SST=j=1∑ki=1∑nj(xij−xˉ)2,xˉ=n∑j=1k∑i=1njxij
更进一步,计算每个组内的样本与均值的差值的平方和,计算结果如下:
S
S
E
j
=
∑
i
=
1
n
j
(
x
i
j
−
x
j
ˉ
)
2
SSE_j = \sum^{n_j}_{i=1}(x_{ij}-\bar {x_j})^2
SSEj=i=1∑nj(xij−xjˉ)2
即第j组的组内偏差平方和,其中
x
j
ˉ
=
∑
i
=
1
n
j
x
i
j
n
j
\bar {x_j} = \frac{\sum_{i=1}^{n_j}x_{ij}}{n_j}
xjˉ=nj∑i=1njxij为第j组数据的组内均值,而k个分组的组内偏差总和(组内偏差平方和)为:
S
S
E
=
∑
j
=
1
k
S
S
E
j
=
∑
j
=
1
k
∑
i
=
1
n
j
(
x
i
j
−
x
j
ˉ
)
2
SSE = \sum_{j=1}^k SSE_j = \sum_{j=1}^k\sum^{n_j}_{i=1}(x_{ij}-\bar {x_j})^2
SSE=j=1∑kSSEj=j=1∑ki=1∑nj(xij−xjˉ)2
此时(在欧式空间情况下)则可以通过数学公式推导得出SST和SSE之间的差值(组间偏差平方和)如下:
S
S
B
=
S
S
T
−
S
S
E
=
∑
j
=
1
k
n
j
(
x
j
ˉ
−
x
ˉ
)
2
SSB=SST-SSE=\sum_{j=1}^k n_j (\bar{x_j}-\bar x)^2
SSB=SST−SSE=j=1∑knj(xjˉ−xˉ)2
即每个组的均值和总体均值的差值的平方加权求和的结果,其中权重就是每个组的样本数量。
在聚类分析中,在总体偏差不变的情况下(给定一组数据,就会有一个固定的SST),我们希望组内偏差越小越好、而组间偏差越大越好,因为这样就能证明组内数据彼此更加相似、而不同分组的数据彼此会更加不同。同样的观点也适用于当前情况,即在给定一个离散变量和连续变量的时候,我们就可以利用离散变量的不同取值对连续变量进行分组(例如根据是否流失,划分为流失用户组和非流失用户组),此时SST是一个确定的值,并且如果SSB很大、SSE很小,则说明不同组的组间差异越大、组内差异较小,而所谓的组间差异,其实也就是由均值的不同导致的,SSB越大说明不同组的均值都和整体均值差异较大,SSE越小说明每个组内的取值和该组的均值比较接近,此时我们会更倾向于判断不同组是取自不同总体;而反之,如果SSB很小而SSE很大,则倾向于判断不同组是取自同一个总体。
此外,我们也需要理解方差分析中方差的含义,在实际计算过程中,SST、SSE和SSB都可以看成是方差计算,其中SST衡量的数据整体方差、SSE衡量的组内方差,而SSB衡量的是每一组的均值分布的方差,即每一组均值和整体均值的离散程度。注:SSB较大,只有一种可能,即分组均值的离散程度较大。
四、量化均值差异程度
构造统计检验量F,来更具体的量化均值差异程度,计算公式如下:
F
=
M
S
B
M
S
E
=
S
S
B
/
d
f
b
S
S
E
/
d
f
e
=
S
S
B
/
(
k
−
1
)
S
S
E
/
(
n
−
k
)
F=\frac{MSB}{MSE}=\frac{SSB/df_b}{SSE/df_e}=\frac{SSB/(k-1)}{SSE/(n-k)}
F=MSEMSB=SSE/dfeSSB/dfb=SSE/(n−k)SSB/(k−1)
此处
d
f
b
df_b
dfb就是统计量SSB的自由度,类似于卡方检验过程中(行数-1*列数-1)用于修正卡方值,
d
f
b
df_b
dfb也是一个用于修正SSB计算量的值——为了防止分组的数量影响了SSB的计算结果;类似的
d
f
E
df_E
dfE就是SSE的自由度,用于修正样本数量对SSE计算结果的影响。这些修正的值会在一开始就确定,例如**k(分成几类)、n(样本总量)**等,并不会受到实际数据取值大小的影响。
F作为统计检验量,满足F(k-1, n-k)的概率分布,F值越大,SSB相比SSE越大,组间差异越大,不同组的数据更倾向于抽样自不同总体、零假设成立的可能性(p值)越低,反之则零假设成立的可能性就越高。
代码实现
接下来通过带入数据,即可算出具体的F值大小,进一步通过查看F值在对应的F(k-1, n-k)中的概率结果,就能够判断是否接受或拒绝原假设。这里用月消费金额和标签进行计算:
# 1. 获取自由度
k = y_train.nunique() # 2
n = len(y_train) # 5282
# 2. 计算F_score值
cat_0_mean = cat_0.mean()
cat_1_mean = cat_1.mean()
SSE0 = np.power(cat_0 - cat_0_mean, 2).sum()
SSE1 = np.power(cat_1 - cat_1_mean, 2).sum()
SSE = SSE0 + SSE1
n0 = len(cat_0) # 3901
n1 = len(cat_1) # 1381
cat_mean = X_train['MonthlyCharges'].mean()
SSB = n0 * np.power(cat_0_mean - cat_mean, 2) + n1 * np.power(cat_1_mean - cat_mean, 2)
MSB = SSB / (k-1)
MSE = SSE / (n-k)
F_score = MSB / MSE # 180
# 3. 计算p值
p = scipy.special.fdtrc(k - 1, n - k, F_score) # 1.7018224028003695e-40
能够看出,F取值180的概率几乎为零,也就是说零假设成立的概率几乎为零,我们可以推翻零假设,即流失人群和非流失人群的月消费金额存在显著差异。
进一步应用到特征筛选环节,得到的结论就是月消费金额和标签存在显著的关联关系,不同类别人群在月消费金额上存在显出差异,可以从月消费金额入手进行分析和预测,月消费金额特征可以带入模型进行训练。
偷懒方法:借助scipy中的stats.f_oneway(单变量方差分析)函数直接进行方差分析计算,仅需带入两类不同的样本即可。过程如下:
# 非流失用户的月消费金额
cat_0 = X_train['MonthlyCharges'][y_train == 0]
# 流失用户的月消费金额
cat_1 = X_train['MonthlyCharges'][y_train == 1]
# 计算f_score和p_value
f_score, p_value = scipy.stats.f_oneway(cat_0, cat_1)
# F_onewayResult(statistic=180.5363892123, pvalue=1.7018224028019414e-40)
相关内容
-
one-way ANOVA
所谓one-way ANOVA是特指单因素方差分析,即只有一个因素导致的数据分组,在当前情况下是指依据是否流失这一个因素对用户进行分组。而除了单因素方差外,还有two-way ANOVA,指的是双因素方差分析,此时既需要考虑不同因素对结果的影响,还要考虑双因素之间是否还有交互作用。对于特征筛选来说,由于我们往往是针对标签进行分组,因此不会涉及双因素方差分析的问题。 -
方差分析与F检验
尽管在方差分析中用到了F检验,但方差分析不同于F检验。F检验泛指一切借助F值进行检验的过程,而方差分析只是其中一种。换而言之,只要假设检验中的检验统计量满足F分布,则该过程就用到了F检验。 -
F检验与卡方检验
从理论上来说,F统计量的分子和分母都是服从卡方分布的, F = S S B / ( k − 1 ) S S E / ( n − k ) F=\frac{SSB/(k-1)}{SSE/(n-k)} F=SSE/(n−k)SSB/(k−1)中,分子是服从自由度为n-k的卡方分布,而分母是服从自由度为n-k的卡方分布,且能够证明二者相互独立。也就是说,统计检验量F是借助卡方分布构建的,更进一步来说,只要是相互独立的、服从卡方分母的随机变量,相除构成的随机变量都是服从F分布的。而F统计量的标准表达公式如下: F = X 1 / d 1 X 2 / d 2 F=\frac{X_1/d_1}{X_2/d_2} F=X2/d2X1/d1其中 X 1 X_1 X1和 X 2 X_2 X2相互独立且服从自由度为 d 1 d_1 d1、 d 2 d_2 d2的卡方分布,此时随机变量F服从自由度为( d 1 , d 2 d_1,d_2 d1,d2)的F分布。 -
方差分析与t检验
除了方差分析以外,还有一种检验也能判断两个样本的均值是否一致,也就是t检验。不同的是,方差分析能够同时检验多个样本,也就是如果是三分类标签、则对应三个不同的样本,卡方检验能够同时判断三个样本是否取自同一总体,进而判断该特征是否可用(从特征筛选的角度来看)。而t检验只能两两比较,很明显应如果是用于特征筛选环节,t检验并不够高效。而t检验、卡方检验和方差分析,被称作统计学三大检验。
特征筛选(关键)
借助sklearn中f_classif评估函数来实现方差分析的过程:
from sklearn.feature_selection import f_classif
'''
f_classif(X, y)
innput:X 连续变量集合 (n_samples, n_features), y: 标签向量 (n_samples,)
return: f_statistic (n_features,) 和 p_values (n_features,)
'''
f_classif(X_train['MonthlyCharges'].values.reshape(-1, 1), y_train.ravel())
# 结果: (array([180.53638921]), array([1.7018224e-40]))
通过查看源码能够发现,sklearn中的f_classif也就是调用f_oneway函数进行的计算,因此最终输出结果和此前实验结果完全一致。同时f_classif本身也是评分函数,输出的F值就是评分。结论:F值越大、p值越小、我们就越有理由相信两列存在关联关系,反之F值越小则说明两列没有关系,可以考虑剔除。
借助SelectKBest来进行基于方差分析评分的特征筛选。这里需要注意的是,基于方差分析的基本流程,即对分组后的变量进行均值方差计算等过程,我们不难发现方差分析其实并不适用于两个离散变量之间的检验。在sklearn中,尽管没有要求只能针对分类问题对连续特征进行检验,但实际上带入离散特征进行检验是毫无意义的。对于分类问题,离散特征的检验可以交给卡方检验。此处仅针对两个连续变量进行方差分析检验特征筛选:
numeric_cols = ['tenure', 'MonthlyCharges', 'TotalCharges'] # tenure为离散特征,另外两个是连续特征
KB_CF = SelectKBest(score_func = f_classif, k = 2) # 根据k个最高F统计量分数
KB_CF.fit(X_train[numeric_cols], y_train) # SelectKBest(k=2)
KB_CF.scores_ # array([772.52712199, 180.53638921, 244.16941072])
KB_CF.pvalues_ # array([8.46456399e-159, 1.70182240e-040, 7.67071015e-054])
KB_CF.get_feature_names_out()
能够看出,对于方差分析来说,tenure字段(如果看成是连续变量的话)和总消费金额字段会比月消费金额字段更有效果。因此,如果是针对分类问题,f_classif与chi2两个评分函数搭配使用,就能够完成一次完整的特征筛选,其中chi2用于筛选离散特征、f_classif用于筛选连续特征。
回归问题中筛选与连续标签呈线性关系的连续变量——F检验(f_regression)
计算过程
f_classif和chi2检验能够很好的解决分类问题的特征筛选。而回归问题,sklearn提供了一种基于F检验的线性相关性检验方法f_regression,该检验方法并不常见,但却和方差分析过程非常类似,f_regression构建了一个如下形式的F统计量:
F
=
r
x
y
2
1
−
r
x
y
2
∗
(
n
−
2
)
F = \frac{r^2_{xy}}{1-r^2_{xy}} * (n-2)
F=1−rxy2rxy2∗(n−2)
其中
r
x
y
r_{xy}
rxy为两个连续变量的相关系数,并且满足自由度为(1,n-2)的F分布。该计算过程并不复杂,并且统计量F和
r
x
y
2
r_{xy}^2
rxy2变化方向一致,即与相关系数绝对值的变化保持一致,本质上和相关系数一样,也是衡量了两个变量之间的相关性,并且是一种线性相关关系,并且数值越大、线性相关关系越强,反之则越弱。
一旦找到了检验统计变量,我们就可以推断当前事件发生的概率,进而有理有据的接受或者拒绝零假设。这里的基于相关系数的检验,零假设是二者不存在线性相关关系。由于最终的检验统计变量仍然是服从F分布的,因此我们称其为线性相关性的F检验。假设检验中零假设与备择假设如下:
H
0
:
两
个
连
续
变
量
间
不
存
在
线
性
相
关
关
系
H_0:两个连续变量间不存在线性相关关系
H0:两个连续变量间不存在线性相关关系
H
0
:
两
个
连
续
变
量
间
存
在
线
性
相
关
关
系
H_0:两个连续变量间存在线性相关关系
H0:两个连续变量间存在线性相关关系
特征筛选(关键)
该方法只能用于回归问题中,并且只能筛选出与标签呈现线性相关关系的连续变量,例子如下:
from sklearn.feature_selection import f_regression
KB = SelectKBest(f_regression, k = 10)
X_new = KB.fit_transform(X_train, y_train) # (5282, 10)
KB.get_feature_names_out() # (10, ) -> 筛选出的10个特征
互信息法(mutual information)
f_regression 只能挖掘线性相关关系,其他类型的关系无法被f_regression识别;由于离散变量的数值大小是没有意义的,因此判断离散变量和其他变量的“线性关系”意义不大,因此 f_regression 只能作用于两个连续变量之间。综上所述,f_regression唯一适用的场景就是用于线性回归的连续变量特征筛选。而针对于回归类问题,仅仅依靠 f_regression 进行连续型变量的特征筛选肯定是远远不够的。挖掘除了线性相关关系外的特征筛选方法:互信息法。互信息法的作用范围非常广,可用于不同类型变量间的关联性挖掘。互信息法借助评估指标互信息来进行特征筛选。
离散变量的互信息计算
对于信息增益来说,即某个变量所包含另一个变量的信息,从本质上来说,信息增益其实就是互信息,而互信息中的“互”,其实也就是两个变量相互包含对方信息的意思。借助维基百科上关于互信息法的解释图进行理解:
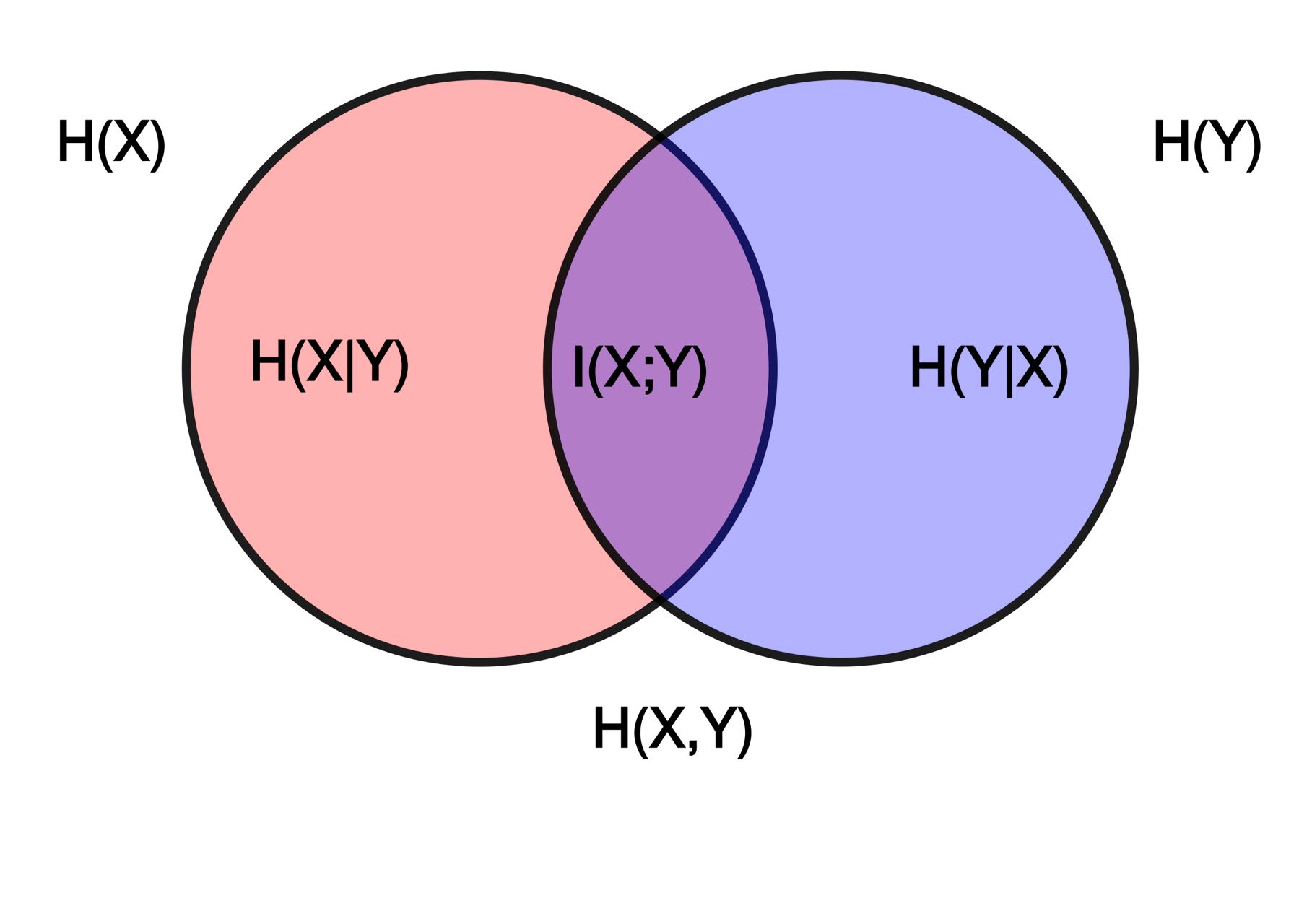
其中,
H
(
X
)
、
H
(
Y
)
H(X)、H(Y)
H(X)、H(Y)表示X和Y的信息熵,
H
(
X
∣
Y
)
H(X|Y)
H(X∣Y)则表示在Y确定时X不确定的部分,
H
(
Y
∣
X
)
H(Y|X)
H(Y∣X)表示在X确定时Y不确定的部分,这些也被称为条件熵。而
I
(
X
;
Y
)
I(X;Y)
I(X;Y)表示两个变量能相互解释的部分,即互信息。
在互信息法的特征筛选过程中,将互信息视作每个特征的评分,然后挑选那些评分较高的特征带入模型进行训练。
反观ID 3的建树流程,多个特征进行决策树的构建,模型会首选信息增益最大的列进行数据集划分(即树的生长),这个过程其实就是借助互信息来进行特征筛选的过程,即ID3每次生长都会选取那些(在剩余特征中)互信息最大的特征。理解到这层,能够很顺利的解决两个问题:其一是为什么树模型以及以树模型为弱分类器的集成算法可以不进行特征筛选,原因是树模型的生长过程其实是会自动进行特征筛选的(CART树类似,信息熵为基尼系数);其二是互信息这一指标确实能够挑选出能有效帮助模型建模的特征。
互信息法的本质,可以将其理解为一个剥离决策树模型训练、单纯只对每个特征进行互信息计算、然后根据互信息进行挑选特征的过程。树模型feature_importance,本质上也是多次生长后累计的互信息值。
需要强调一点,尽管树模型的自动特征挑选和互信息法看起来有些重复,但如果是经过特征衍生的特征矩阵,对其进行特征筛选是非常必要的。在特征衍生过程中动则就会创建数以万计的特征,而如果不进行特征筛选,仅靠树模型以此进行互信息的计算然后再挑选最优特征再进行一层层生长,将会非常耗时。反之,对于目前机器学习算法来说,如果只有数量较少的原始特征而不进行特征衍生,则完全可以不用进行互信息法特征筛选,直接带入模型进行训练即可。
# 两个离散变量的互信息(信息增益)计算
from sklearn.metrics import mutual_info_score
A = np.array([0, 0, 0, 1, 1, 1])
D = np.array([0, 1, 1, 0, 0, 0])
mutual_info_score(A, D) # mutual_info_score(D, A) 0.318
# ps: sklearn中在进行信息熵计算时默认以e为底, 而不是2
除了互信息外,卡方检验也能很好的进行离散变量的关联性挖掘。接下来对比两种方法的异同,并给出各自适用的使用场景。
from sklearn.feature_selection import chi2 # https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.chi2.html#sklearn.feature_selection.chi2
A = np.array([0, 0, 0, 1, 1, 1])
D = np.array([0, 1, 1, 0, 0, 0])
chi2(A.reshape(-1, 1), D)
# (array([1.5]), array([0.22067136]))
# (n_features,) Chi2 statistics for each feature.
# (n_features,) p_values for each feature.
mutual_info_score(A, D) # 0.3182570841474064
首先,卡方检验能够给出明确的p值用于评估是否是小概率事件,而互信息法只能给出信息增益的计算结果,很多时候由于信息增益的计算结果是在0到最小信息熵之间取值,因此信息增益的数值在判断特征是否有效时并不如p值那么直观。
其次,卡方检验的p值源于假设检验统计量服从卡方分布,这种有假设分布的方法也被称为参数方法,而互信息法并不涉及任何假定的参数分布,因此是一种非参数方法。不难发现,参数方法是借助样本估计总体,然后根据总体进行推断的过程,而非参数方法则无需总体信息即可计算。尽管从方法理解层面来看非参数方法会更加简单,但这种“简单”所带来的代价,就是非参数方法无法对小样本进行合理的预估。例如在当前数据情况下,互信息法计算得出的结果应该是一个还不错的结果,从肉眼观察来看A和D也应该存在一定的关联性。
但在卡方检验看来,并不能一定判断二者就不是相互独立的,在二者相互独立的零假设下,接受假设的概率高达22%。这又是什么原因呢?卡方检验是会收到样本数量影响的,而此时卡方检验不敢下结论的原因或许并不是因为现在的A和D表现出来的关联性不够强,而是目前样本数量太少了(只有六条样本)。因此这里如果不改变A和D的数据分布,而仅仅将样本数量扩增至10倍,则卡方检验结果如下:
A1 = np.array(A.tolist() * 10)
D1 = np.array(D.tolist() * 10)
chi2(A1.reshape(-1, 1), D1) # (array([15.]), array([0.00010751]))
mutual_info_score(A1, D1) # 0.31825708414740617
能够发现,此时卡方检验认为当前数据情况下A1和D1相互独立就是一个非常小概率的事件了,即判断A1和D1存在显著的关联关系,而此时互信息的计算结果仍然不变。由此更加直观的感受到参数方法和非参数方法二者的差异,即参数方法会考虑到样本数量这一影响因素,如果样本数量较少,则参数方法会更加趋于保守、更加趋于保留原假设,例如卡方检验,尽管A和D表现出了“肉眼可见”的关联性,但由于样本数量太少,不足以做出有力的推断A和D背后的总体就一定不独立,因此****趋于保留原假设,即二者独立。当样本数量增加后,卡方检验的检验结论也会随之发生变化,越来越多的数据表示二者存在关联性,那么二者独立的概率也将越来越小,这也是A1和D1最终的检验结论。但非参数方法是“所见即所得”,结论并不受样本数量影响。
如何选用这两种方法来选择离散变量?一般来说,对于小样本而言,卡方检验的结果可信度会高于互信息法,因此优先考虑卡方检验,而对于大样本而言,卡方检验和互信息法二者的结果其实并不会有特别大的差异,卡方检验的p值越小、互信息的值就会越大、二者关联度就越高。对于大样本数据,若最终采用模型融合策略进行建模,则最好采用不同的特征筛选方法训练不同模型,以期能达到更好的融合效果。
最后,需要强调的是,如果分类变量样本偏态非常严重,也会影响互信息的结果,但不会影响卡方检验结果:
A = np.array([0, 0, 0, 1, 1, 1])
A2 = A.tolist()
A2.extend([1]*10) # [0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
D = np.array([0, 1, 1, 0, 0, 0])
D2 = D.tolist()
D2.extend([0]*10) # [0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
mutual_info_score(A2, D2) # 0.25742375470115947
chi2(np.array(A2).reshape(-1, 1), np.array(D2)) # (array([1.85714286]), array([0.17295492]))
连续变量的互信息计算
对于互信息法来说,一大优势就是不仅可以分析挖掘离散变量之间的关联性,还可以挖掘离散变量与连续变量、以及连续变量之间的关联性。
连续变量与离散变量的互信息计算
首先是离散变量与连续变量的互信息计算过程,可用于回归问题筛选离散特征、也可以用于分类问题筛选连续特征。不过需要注意的是,由于参与计算的一方变成了连续变量,无论是信息增益还是KL散度的计算公式都将发生变化,即需要将原公式中的累加改为积分运算:
D
K
L
(
p
(
x
,
y
)
∣
∣
p
(
x
)
p
(
y
)
)
=
∑
y
∈
Y
∑
x
∈
X
p
(
x
,
y
)
log
(
p
(
x
,
y
)
p
(
x
)
p
(
y
)
)
=
H
(
Y
)
−
H
(
Y
∣
X
)
=
H
(
X
)
−
H
(
X
∣
Y
)
D_{KL}(p(x,y) || p(x)p(y)) = \sum\limits_{y \in \mathcal{Y}}\sum\limits_{x \in \mathcal{X}} p(x,y) \,\text{log}\left(\frac{p(x,y)}{p(x)p(y)}\right)=H(Y)-H(Y|X)=H(X)-H(X|Y)
DKL(p(x,y)∣∣p(x)p(y))=y∈Y∑x∈X∑p(x,y)log(p(x)p(y)p(x,y))=H(Y)−H(Y∣X)=H(X)−H(X∣Y)
I
(
X
;
Y
)
=
∫
Y
∫
X
p
(
x
,
y
)
log
(
p
(
x
,
y
)
p
(
x
)
p
(
y
)
)
d
x
d
y
I(X;Y) = \int_{\mathcal{Y}}\int_{\mathcal{X}} p(x,y) \,\text{log}\left(\frac{p(x,y)}{p(x)p(y)}\right) dxdy
I(X;Y)=∫Y∫Xp(x,y)log(p(x)p(y)p(x,y))dxdy
考虑到积分运算在机器学习领域并不好实现,因此sklearn中将这个过程等价于一个K近邻过程,即通过K近邻过程来计算连续变量的互信息。
最近邻计算函数
连续变量的互信息计算过程需要借助最近邻函数进行计算,最近邻是一种非常通用的搜索算法。互信息中用到的是无监督的最近邻算法,即单纯的进行最近邻元素的搜索与半径的计算。
a = np.array([0, 1, 2, 4, 7, 9, 3])
对于a中第一个元素0来说,数值上距离最近的元素就是第二个元素1,其次是第三个元素2,即1和2是0的两个最近邻。无监督的最近邻方法能够借助sklearn中的NearestNeighbors评估器完成计算:
from sklearn.neighbors import NearestNeighbors
nn = NearestNeighbors(n_neighbors=2) # 对a中每个元素进行n_neighbors=2的最近邻搜索
nn.fit(a.reshape(-1, 1))
nn.kneighbors()
'''
(array([[1., 2.],
[1., 1.],
[1., 1.],
[1., 2.],
[2., 3.],
[2., 5.],
[1., 1.]]), # 距离两个最近邻之间的距离
array([[1, 2],
[2, 0],
[6, 1],
[6, 2],
[5, 3],
[4, 3],
[2, 3]], dtype=int64)) # 两个最近邻的索引
'''
当然,我们也可以将其推广至多维空间内任意n近邻的计算过程中去。需要注意的是,有的时候我们是通过设置最近邻的个数来查找最近邻,而有的时候我们可能希望通过设置个距离范围半径,来查找半径范围内的所有可能的近邻,此时则需要用到KDTree(或者BallTree)来查找,基本流程如下:
from sklearn.neighbors import KDTree
kd = KDTree(a.reshape(-1, 1))
kd.query_radius(a.reshape(-1, 1), 1)
'''
array([array([0, 1], dtype=int64), array([0, 1, 2], dtype=int64),
array([1, 2, 6], dtype=int64), array([3, 6], dtype=int64),
array([4], dtype=int64), array([5], dtype=int64),
array([2, 3, 6], dtype=int64)], dtype=object)
返回的结果就是每个元素在给定半径1时,搜索到的距离小于等于1的元素的索引
'''
计算过程(关键)
在连续变量和离散变量的互信息计算过程中,基本思路仍然是根据离散变量的不同取值对连续变量进行分组,然后通过衡量组内差异和组间差异来判断如此分组是否有效。该思路和方差分析的思路完全一致,只不过方差分析通过构建了一个F统计量来量化的衡量组间差异的程度,并且是一种参数方法,而互信息则是借助K近邻来衡量组内差异和组间差异。
sklearn用于计算离散变量和连续变量之间互信息的函数为_compute_mi_cd
from sklearn.feature_selection import
对于函数参数来说,c代表连续变量、d代表离散变量,n_neighbors代表最近邻元素个数。















 485
485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









