






学堂在线上周志华老师讲的机器学习课程网址:https://www.xuetangx.com/course/nju0802bt/14363483?channel=i.area.home_course_ad
什么场景的问题适合机器学习解决?
机器学习通常在解决一个具有高度不确定性、高度复杂性而且无法制定专家规则去做的问题。
比方说,要做故障诊断,假设我们很清楚地知道故障诊断有三个指标,第一个指标是温度高于90度,系统会出问题,这就是一个确定性的规则、知识。但是,在真实场景下,我们没有这么清楚的知识、规则,即高于90度或者低于90度都会出问题。同时,很多因素对这个结果有影响,但是具体有多大的影响,我们不知道,这时候我们才会去用机器学习。
当我们的知识不能针对某个问题给出精确的结果时,希望通过机器学习给出问题的答案,这就不能保证一定会给出正确的答案,因此它不是我们能够清楚了解的问题。用数学公式来说,机器学习就是用很高的概率得到一个很好的模型,公式如下:
P ( ∣ f ( x ) − y ∣ ) < = 1 − ϵ P(|f(x)-y|)<=1-ϵ P(∣f(x)−y∣)<=1−ϵ
ϵ ϵ ϵ越小,模型的泛化能力越强。如果发现问题的结果是无限差,说明这件问题不能用机器学习解决。
什么是过拟合 & 欠拟合?
使用机器学习解决问题时,一般前提是训练数据和未知数据具有相同数据分布,同时,通过机器学习算法在训练数据上学习到了一般规律。
过拟合(学的太多):机器学习算法学习到事物的非重要特性,并将其视为判别事物的一般规律。
欠拟合(学的太少):机器学习算法没有学习到判别事物的一般规律,不足以对该事物进行正确判别。
比如:
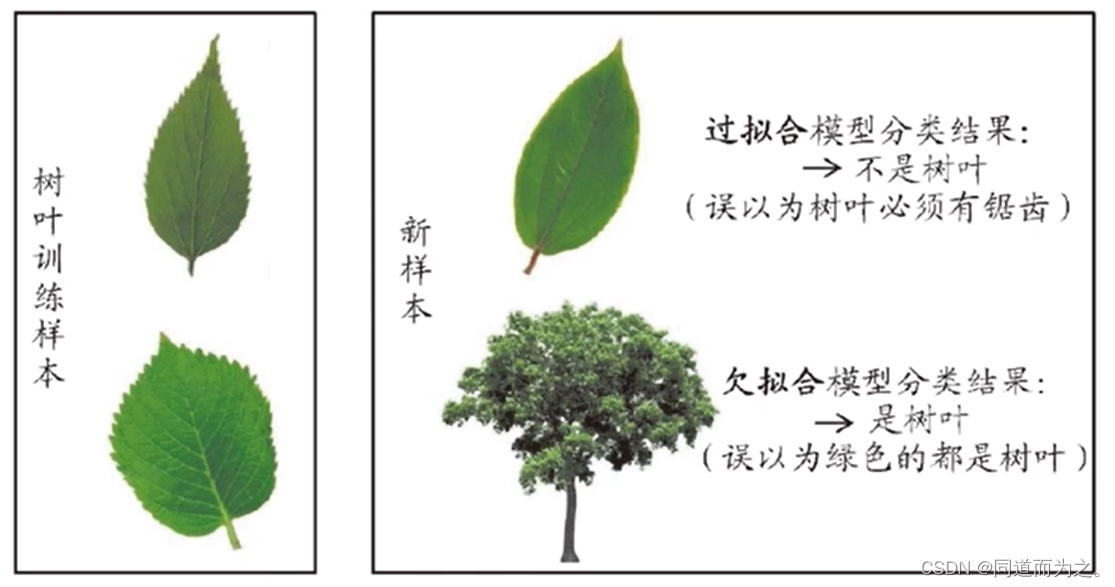
模型过拟合使得模型学习到树叶必须具有锯齿,而这个特性不是树叶的一般规律;模型欠拟合使得模型还没学到树叶的一般规律就给出事物的判别结果,即看到绿色就判定是树叶,而实际是一棵树。
在学习任何一个新算法时,必须要搞清楚这个算法是如何缓解过拟合的,这种缓解的技术在什么时候会失效,这样在遇到问题的时候,就会考虑选择用其它算法。
模型选择方面的三个关键问题
拿到一个模型之后,应该如何评估出它在未来数据上的表现会怎么样?三个关键问题:
- 如何获得测试结果?评估方法
测试集和训练集应该完全"互斥",测试集获取的常用方法:留出法、交叉验证法和自助法。
一、留出法
关键点:1. 数据划分一定要保持训练集和测试集的数据分布一致,否则会引入额外的偏差,比如,分类任务中保持样本的类别比例相似;2. 随机划分100次(经验值)、重复实验后取均值作为留出法的评估结果,从而消除数据切分造成的影响;3. 测试集不能太大,也不能太小。常见做法是按照2: 1 / 3: 1 / 4: 1的比例对数据集进行切分。
缺陷:1. 我们希望评估的是用
D
D
D(数据集)训练出的模型
f
(
D
)
f(D)
f(D),但通过留出法划分的训练集
f
(
D
′
)
f(D')
f(D′)得到的模型,可能不能很好地近似
f
(
D
)
f(D)
f(D),因此
D
′
D'
D′越大越好。同样的,测试集
D
−
D
′
D-D'
D−D′越小,其误差
e
(
D
′
)
e(D')
e(D′)结果越不准,这同样需要
D
−
D
′
D-D'
D−D′也是越大越好。因此,这是一个不能调和的矛盾,只能按照经验比例解决这个矛盾。2. 随机划分数据集,可能有一些数据从未被使用,而它们又对模型评估结果的影响很大,用到实际数据中,模型的表现变得一塌糊涂。
注意事项:假设有两个机器学习算法
l
1
l_1
l1、
l
2
l_2
l2,通过训练集
D
′
D'
D′得到两个模型
M
1
M_1
M1、
M
2
M_2
M2,并且测试集误差
M
1
(
e
(
D
′
)
)
<
M
2
(
e
(
D
′
)
)
M_1(e(D')) < M_2(e(D'))
M1(e(D′))<M2(e(D′)),这时候就选用算法
l
1
l_1
l1,但是,提交给用户的不是
M
1
(
D
′
)
M_1(D')
M1(D′),而是使用算法
l
1
l_1
l1对整个数据集训练后得到的模型
M
(
D
)
M(D)
M(D)。
二、K-fold交叉验证
解决留出法缺陷2导致的问题,从而保证了数据集中每个样本都在测试集中出现过。它按照数据集的顺序依次对数据集进行划分,但是,存在不同的切分导致数据变化的一个问题,这个问题可能导致估计的性能是由这个扰动引起的。解决方法是对数据集进行随机切分10次,共计10 * 10次的交叉验证,也是100次实验。
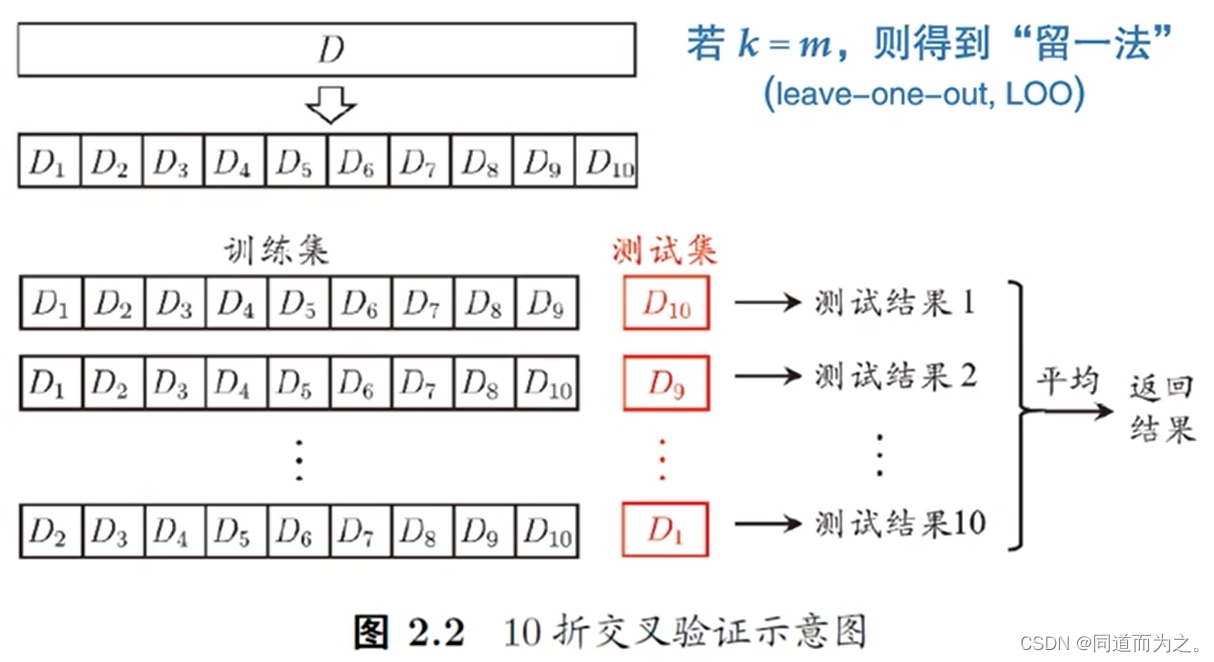
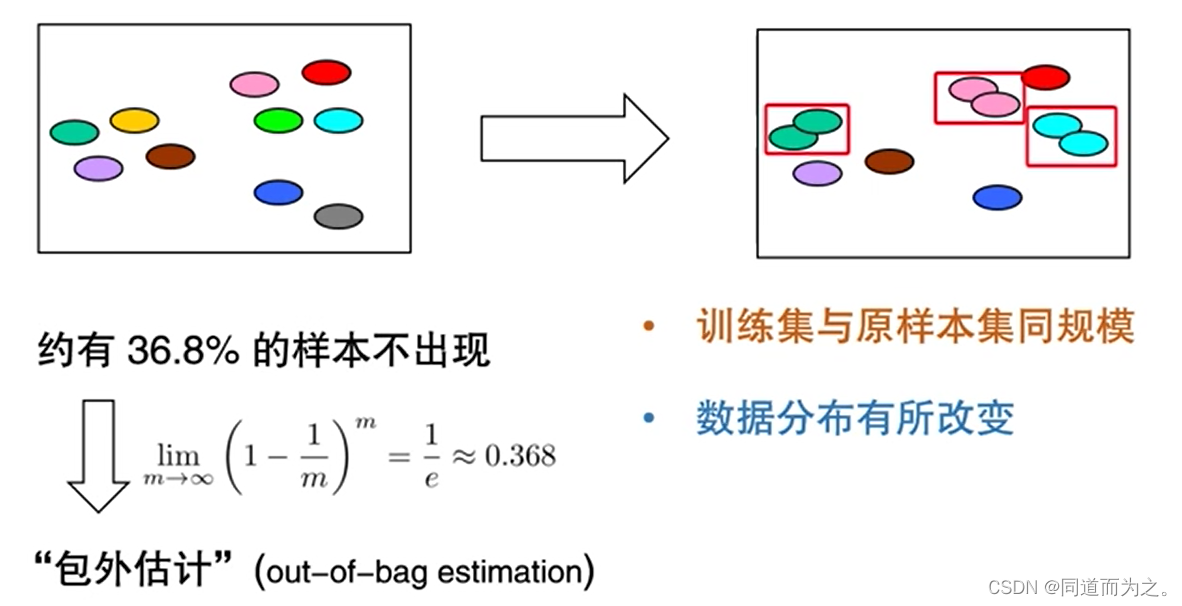
如果每次测试集只留出一个样本,进行100次交叉验证,就是留一法,但是它也是存在预测偏差的。那应该怎么办呢?为了解决训练样本和测试样本数目比例的问题,采用"自助法",即有放回采样。优点:保证训练样本数目与真实样本数目一致;缺点:改变了训练数据的分布,使得模型对部分样本高估。
适用于训练分布稍微不太重要或者数据量不够的情况
三、调参和验证集
从训练集中再拆分出来一小部分数据作为验证集,用它来确定算法的超参数。确定超参数后,要用"拆分后的训练集 + 验证集" 重新训练最终模型,并在测试集上确定模型效果。
切记:测试集一定要是在训练过程中没有用到。调参作为训练过程中的一部分,直接用测试集来确定参数,这是绝对错误的!原因是交叉验证会用到测试集中的数据。
-
如何评估性能优劣?性能度量
什么样的模型是“好”的,不仅取决于算法和数据,还取决于任务需求。
回归问题常用指标:均方误差
分类问题常用指标:错误率&精度、查准率( P = T P T P + F P P=\frac{T P}{T P+F P} P=TP+FPTP, 给用户推荐的内容有多少是用户真正喜欢的)&查全率( R = T P T P + F N R=\frac{T P}{T P+F N} R=TP+FNTP, 用户喜欢的内容有多少被推荐给了用户)、F1度量( 1 F 1 = 1 2 ⋅ ( 1 P + 1 R ) \frac{1}{F 1}=\frac{1}{2} \cdot\left(\frac{1}{P}+\frac{1}{R}\right) F11=21⋅(P1+R1), F 1 = 2 × T P 样例总数 + T P − T N F1=\frac{2 \times T P}{\text { 样例总数 }+T P-T N} F1= 样例总数 +TP−TN2×TP, P和R的调和平均数, 好处是P或R较小的数不会被忽略掉)、加权F1度量( 1 F β = 1 1 + β 2 ⋅ ( 1 P + β 2 R ) \frac{1}{F_\beta}=\frac{1}{1+\beta^2} \cdot\left(\frac{1}{P}+\frac{\beta^2}{R}\right) Fβ1=1+β21⋅(P1+Rβ2), F β = ( 1 + β 2 ) × P × R ( β 2 × P ) + R F_\beta=\frac{\left(1+\beta^2\right) \times P \times R}{\left(\beta^2 \times P\right)+R} Fβ=(β2×P)+R(1+β2)×P×R, 对查准率 / 查全率有不同偏好, β \beta β>1时查全率有更大影响; β \beta β<1时查准率有更大影响)。

-
如何判别实质差别?比较检验
在机器学习中,模型做的是概率近似上的好,那有没有可能一次结果好,绝大多数结果都很糟糕?这样的模型是很糟糕的。因此,需要引入一些比较检验,以表征这个模型在统计意义上是不是好的。需要解决的问题:0.91 > 0.88 是否能确定得出0.91的模型一定比0.88的模型好,答案是不能。原因是测试性能不等于泛化性能;测试性能随着测试集的变化而变化;很多机器学习算法本身有一定的随机性。
统计假设检验(hypothesis test)为学习器性能比较提供了重要依据。

三个关键问题解决后,就会知道"你要的是什么?我怎么能保证我给你的结果就是你想要的"。
线性回归与广义线性回归
基础的线性回归方程需要所有的特征都是数值型,因此需要对离散变量进行数值化。两种情况,若变量值间存在"序"关系,将该变量转化为连续变量,比如身高的取值"高,中,低"连续化为{1.0, 0.5, 0.0};若变量值间不存在"序"关系,需要通过"One-hot"编码处理。
关于线性回归方程参数
w
w
w和
b
b
b求解过程的理解,偏导为0的地方变化率保持不变,说明此时抵达函数的波谷点。
二分类任务的广义线性回归模型,拟合的函数称为"对数几率函数, logistic function, 连续值",而不是逻辑(logit, 0 / 1的离散值)回归函数
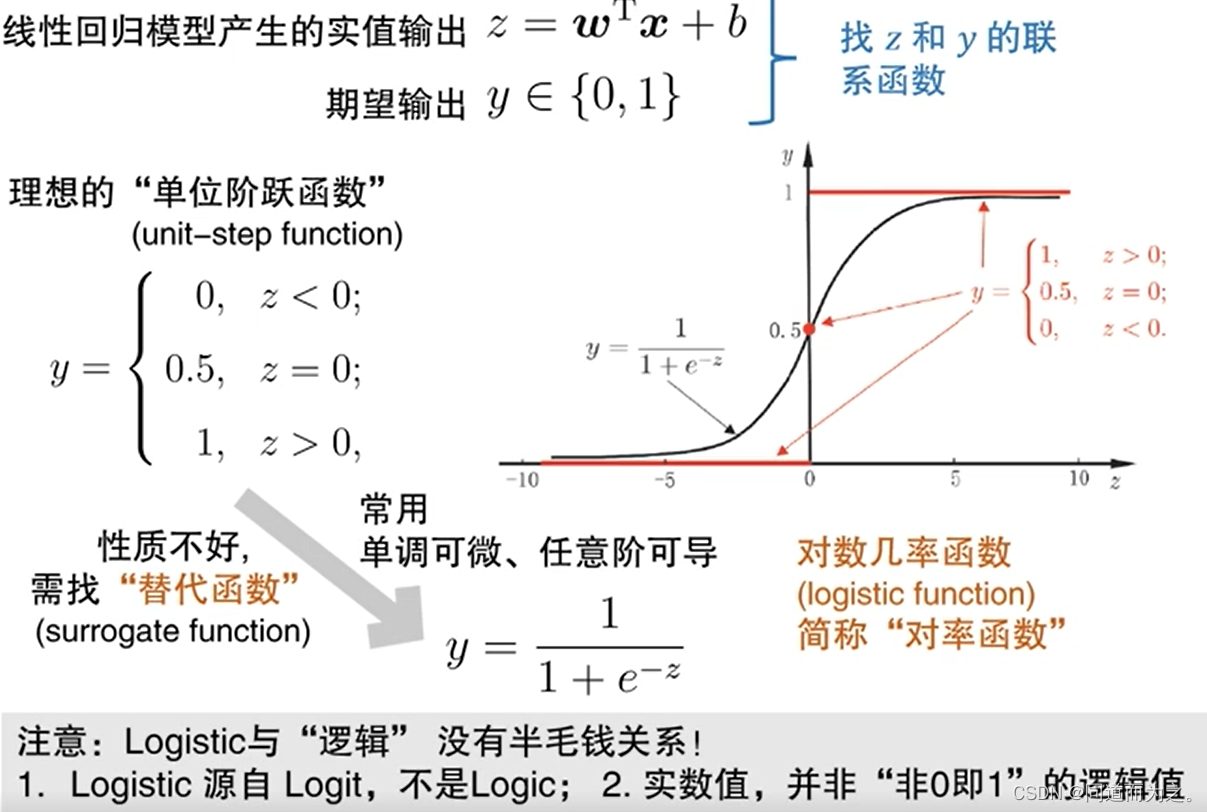
为什么能够使用线性回归方程在解决分类问题?因为几率odds这个统计学概念的存在,它相当于是对连续值y进行处理了,反映了x为正例的相对于x为负例的可能性。

为什么求解逻辑回归不能用均方误差最小化计算?使用梯度为0得到极值的前提条件:目标函数为凸函数,而对率函数非凸函数,因此只能使用极大似然法求解参数。
极大似然法的基本想法:最大化 (真实为正类的概率 × 预测为正类的概率 + 真实为负类的概率 × 预测为负类的概率) 的结果,通俗的理解就是让正例样本最大可能地预测为正,让负例样本最大可能地预测为负,这样能保证损失最小化。至于为什么要引进对数,为了将概率相乘转化为概率相加,防止因概率相乘得到得到的数值过小导致浮点数溢出。过程如下:

集成学习
只有基学习器需要遵守"好而不同"的原则,才能保证集成学习起作用。
成功应用的集成学习方法:
- 序列化方法:AdaBoost、GradientBoost(XGBoost的高效实现)、LPBoost
- 并行化方法:Bagging、Random Forest、Random Subspace
"同质(基学习器类型相同)"集成:针对相同的数据集,比较容易得到预测效果好的基学习器,但是麻烦的是保证基学习器之间的差异性。
"异质(基学习器类型不同)“集成:比如一个模型是神经网络、一个是决策树,在保证单个模型效果说得过去的同时,需要考虑到不同模型产生的输出结果是不能直接用来比较的,解决办法是对它们的结果进行"配准”(比较复杂,后续再讲)。
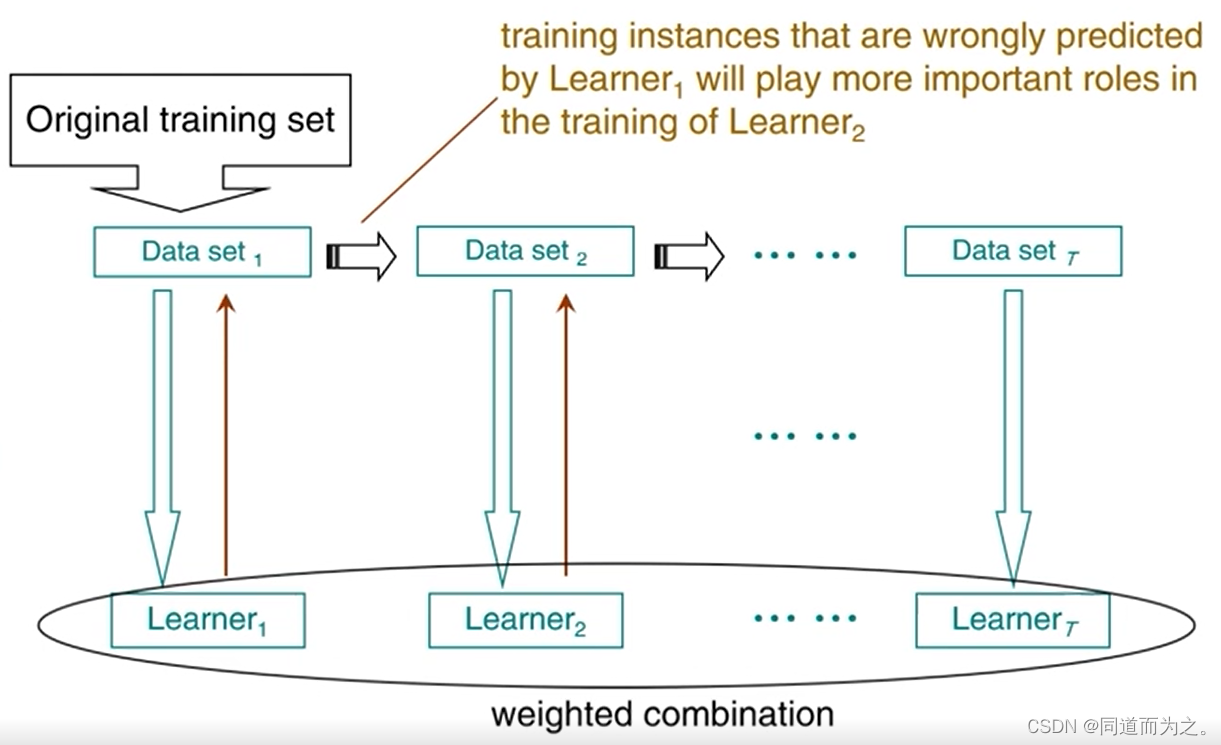
Boosting过程:数据加权(预测正确的数据权重小 & 预测错误的数据权重大) + 学习器加权(不同学习器学习的难度不同,前面的问题简单,后面的问题困难,给予不同权重,得到加权后的结果)。
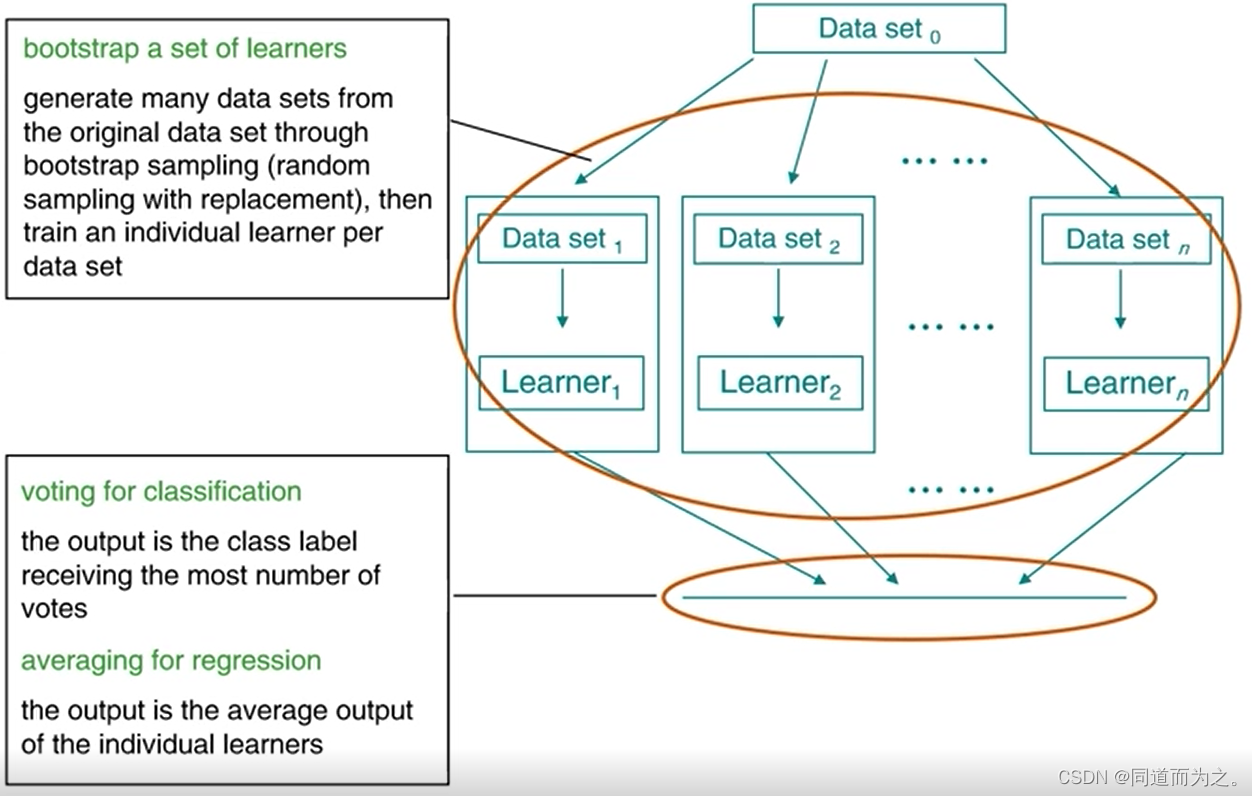
Bagging过程:可重复采样构造若干数据集生成若干相同权重的学习器,分类问题使用少数服从多数,回归问题使用均值。
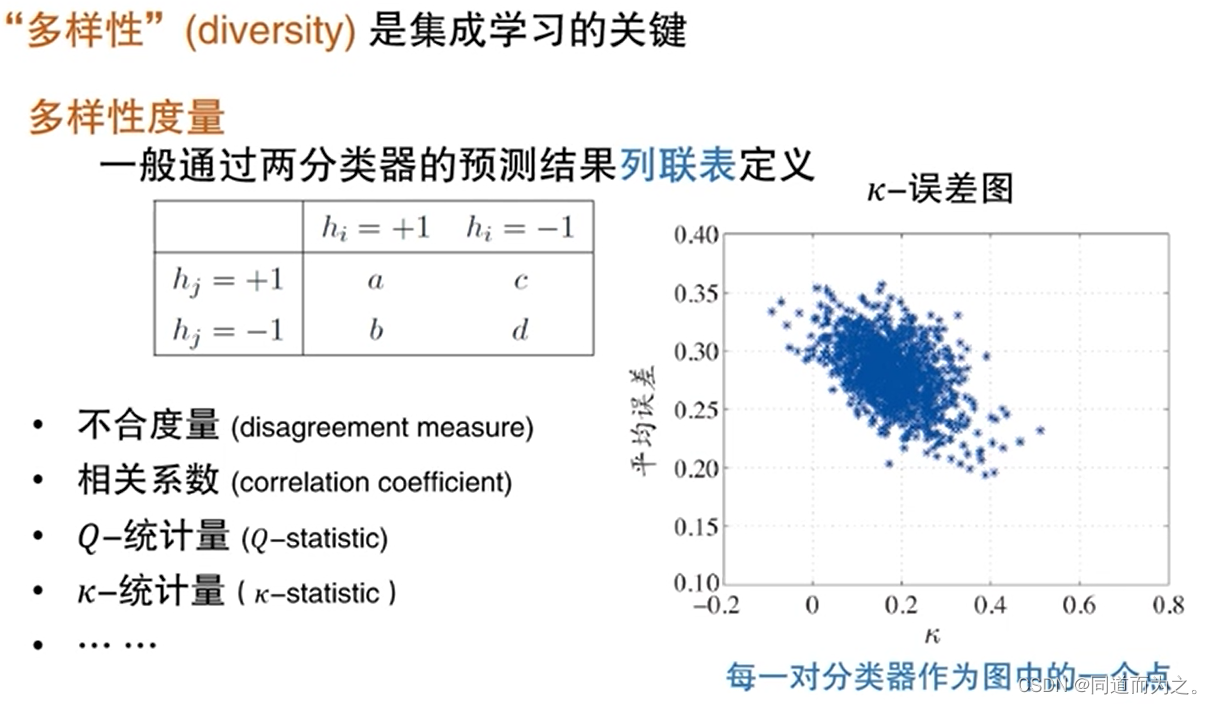
多样性度量: 集成学习的关键!
















 677
677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









