






背景
在实际模型训练过程中,对连续型字段进行离散化处理,也就是将连续性字段转化为离散型字段。连续字段的离散过程如下所示:
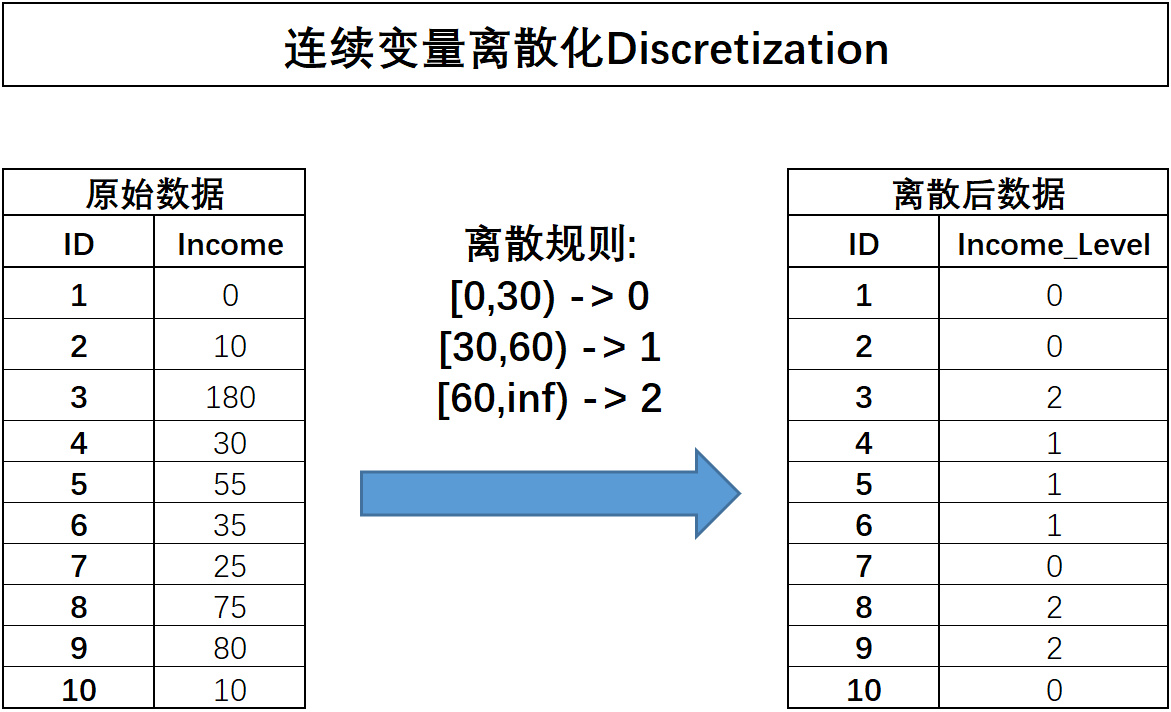
离散之后字段的含义将发生变化,原始字段Income代表用户真实收入状况,而离散之后的含义就变成了用户收入的等级划分,0表示低收入人群、1表示中等收入人群、2代表高收入人群。连续字段的离散化能够更加简洁清晰的呈现特征信息,并且能够极大程度减少异常值的影响(例如Income取值为180的用户),同时也能够消除不同特征量纲差异的影响,同时,对于很多线性模型来说,连续变量的分箱相当于在线性方程中引入了非线性的因素,从而提升模型表现。当然,连续变量的分箱过程会让连续变量损失一些信息,而对于其他很多模型来说(例如树模型),分箱损失的信息大概率会影响最终模型效果。
等宽分箱
所谓等宽分箱,需要先确定划分成几分,然后根据连续变量的取值范围划分对应数量的宽度相同的区间,并据此对连续变量进行分箱。例如上述Income字段取值在[0,180]之间,现对其进行等宽分箱分成三份,则每一份的取值范围分别是[0,60),[60,120),[120,180],连续字段将据此进行划分,分箱过程如下所示:
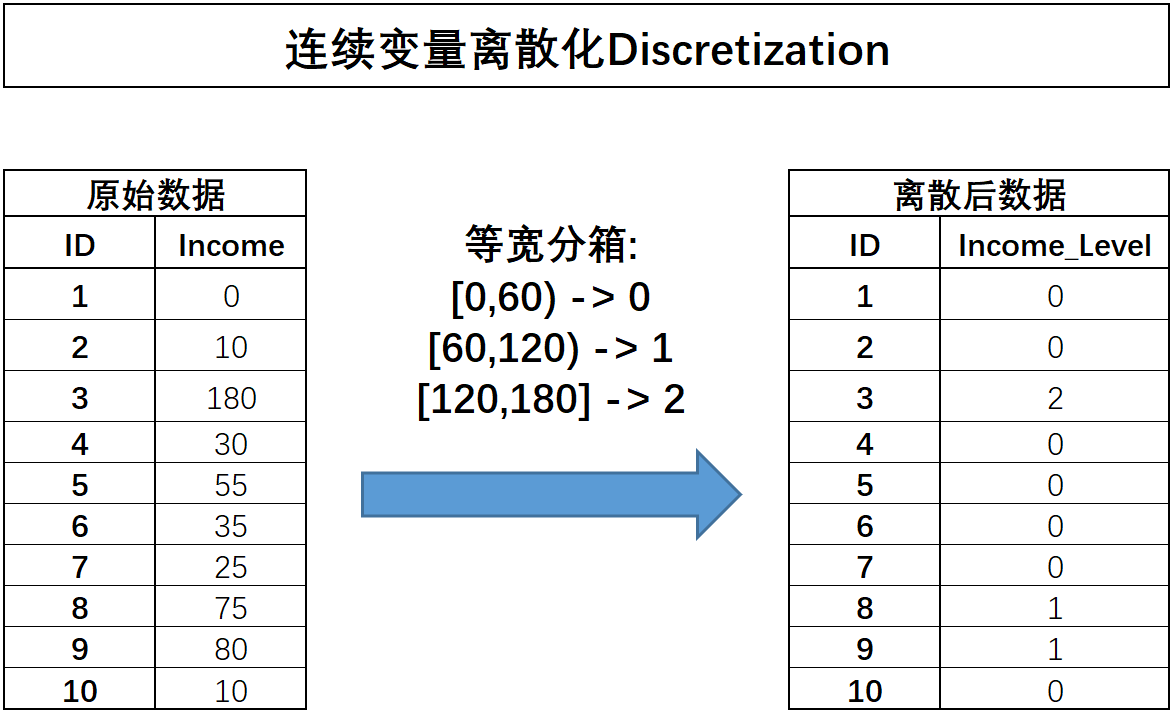
代码实现:
# 注意,一列特征必须以列向量呈现,才能够被KBinsDiscretizer正确识别
income = np.array([0, 10, 180, 30, 55, 35, 25, 75, 80, 10]).reshape(-1, 1)
dis = preprocessing.KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform')
# 三分等宽分箱,strategy选择'uniform'
# strategy参数位上输入等宽分箱、等频分箱还是聚类分箱,encode参数位上输入分箱后的离散字段是否需要进一步进行独热编码处理或者自然数编码
dis.fit_transform(income)
dis.bin_edges_
在分箱结束后,可以通过.bin_edges_查看分箱依据(每个箱体的边界)。这些分箱的边界也就是模型测试阶段对测试集进行分箱的依据,这也符合“在训练集上训练(找到分箱边界),在测试集上测试(利用分箱边界对测试集进行分箱)”这一基本要求。
等频分箱
在等频分箱的过程中,需要先确定划分成几分,然后选择能够让每一份包含样本数量相同的划分方式。如果样本数量无法整除等频分箱的箱数,则最后一个“箱子”将包含余数样本。例如对10条样本进行三分等频分箱,则会分为3/3/4的结果。代码实现如下:
# 两分等频分箱,strategy选择'quantile'
dis = preprocessing.KBinsDiscretizer(n_bins=2, encode='ordinal', strategy='quantile')
dis.fit_transform(income)
dis.bin_edges_
聚类分箱(关键)
聚类分箱,指的是先对某连续变量进行聚类(往往是KMeans聚类),然后用样本所属类别作为标记代替原始数值,从而完成分箱的过程。
通过income数据来模拟该过程,使用KMeans对其进行三类别聚类。等宽分箱会一定程度受到异常值的影响,而等频分箱又容易完全忽略异常值信息,从而一定程度上导致特征信息损失,而若要更好的兼顾变量原始数值分布,使用聚类分箱能够更加完整的保留原始数值分布信息。因此,在实际建模过程中,如无其他特殊要求,建议优先考虑聚类分箱方法。
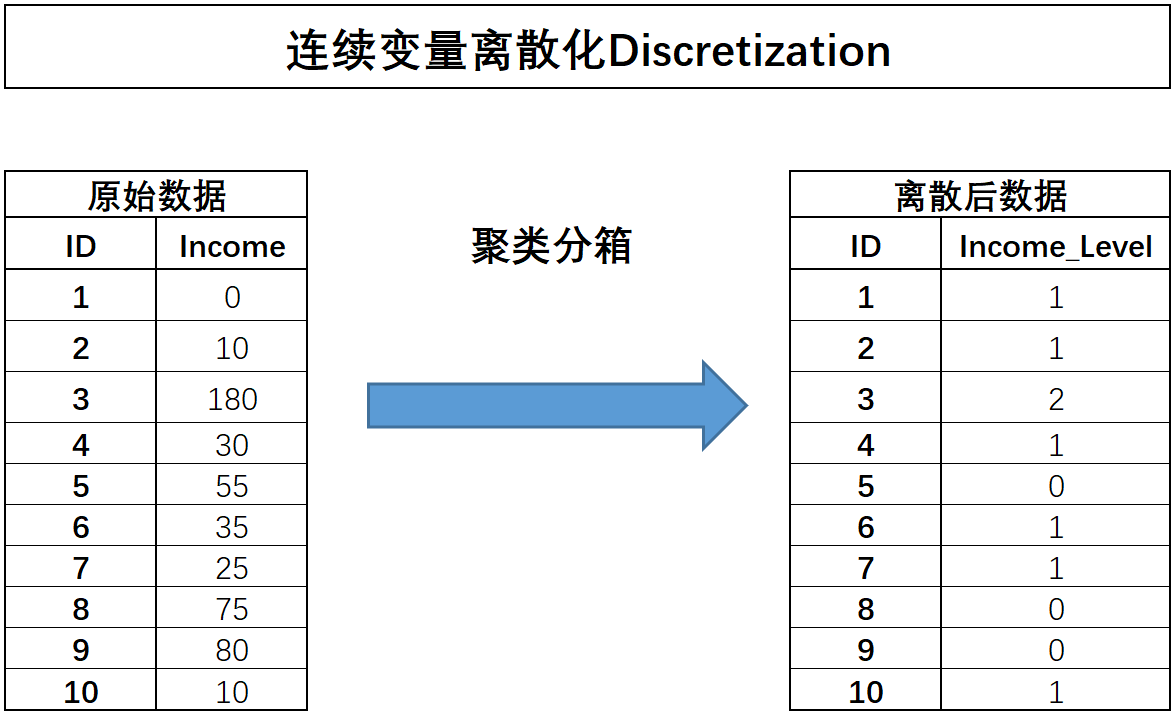
代码如下:
from sklearn import cluster, preprocessing
income = np.array([0, 10, 180, 30, 55, 35, 25, 75, 80, 10]).reshape(-1, 1)
# 方法一: 调用cluster中的聚类算法
kmeans = cluster.KMeans(n_clusters = 3)
kmeans.fit(income)
kmeans.labels_ # 离散化后每条样本的取值
# 方法二: 设置KBinsDiscretizer转化器的strategy参数为'kmeans'
dis = preprocessing.KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='kmeans')
dis.fit_transform(income)
dis.bin_edges_ # 查看各个箱的边界
有监督分箱
无论是等宽/等频分箱,还是聚类分箱,本质上都是进行无监督的分箱,即在不考虑标签的情况下进行的分箱。而有监督分箱根据标签取值对连续变量进行分箱。最常用的分箱就是树模型分箱。
树模型的分箱有两种,其一是利用决策树模型进行分箱,简单根据决策树的树桩(每一次划分数据集的切分点)来作为连续变量的切分依据,由于决策树的分叉过程总是会选择让整体不纯度降低最快的切分点,因此这些切分点就相当于是最大程度保留了有利于样本分类的信息,通过如下示例进行说明,假设以income为特征,y为标签训练决策树:
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
%matplotlib inline
income = np.array([0, 10, 180, 30, 55, 35, 25, 75, 80, 10]).reshape(-1, 1)
y = np.array([1, 1, 0, 1, 0, 0, 0, 1, 0, 0])
clf = DecisionTreeClassifier().fit(income, y)
# 观察训练结果
plt.figure(figsize = (8, 3), dpi = 300)
tree.plot_tree(clf)
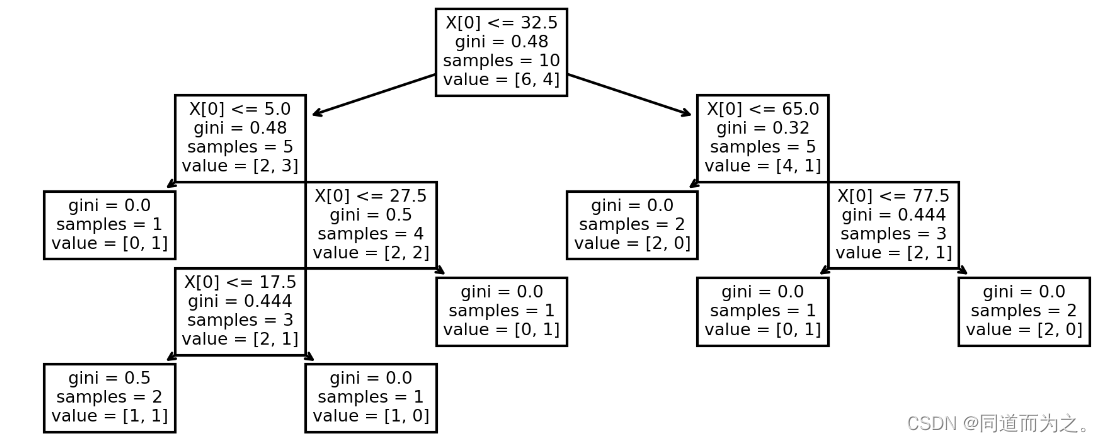
根据上述结果,如果需要对income进行三类分箱的话,则可以选择32.5和65作为切分点,对数据集进行切分:
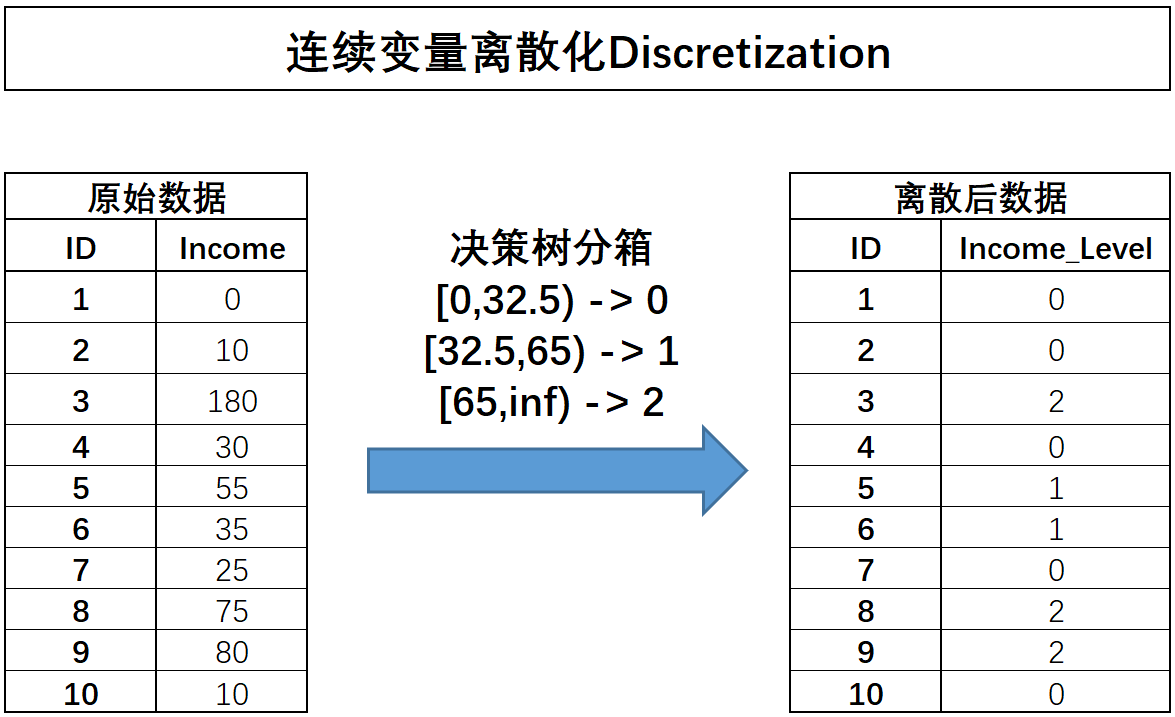
不难发现,这种有监督分箱的结果其实会极大程度利于有监督模型的构建(例如如果按照上述规则进行分箱,则不会影响决策树前两层的生长)。但是,有监督的分箱过程会面临泄露数据集标签信息从而造成过拟合、决策树生长过程不稳定、树模型容易过拟合等问题影响。因此,一般来说有监督的分箱可能会在一些特殊场景下采用一些变种的方式来进行,例如在推荐系统中常用的GBDT+LR模型组合中,就会采用一种非常特殊的方式对连续变量进行分箱:假设我们采用训练集中所有连续变量及标签训练两颗决策树,第一棵树有3个叶节点,第二棵树有2个叶节点,假设某条样本在第一棵树的第二个叶节点中、出现在第二棵树的第二个叶结点中,则将该样本标记为010 01,其中总共5位数表示总共5个叶节点,而0表示该样本未出现在该位置上、1表示出现在该位置上,并最终将010 01代替该样本的所有连续变量的取值,在每条样本都采用了该方式重编码后,就能完整使用新生成的这5列替换原数据集中所有连续变量。














 4019
4019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









