







 介绍了REVERIE任务及数据集,旨在评估代理在真实3D室内环境中根据自然语言指令导航并识别远程目标的能力。任务极具挑战性,要求代理在未见过的环境中识别对象。文章还提出了一种交互式导航器指针模型,并通过实验验证了模型的有效性。
介绍了REVERIE任务及数据集,旨在评估代理在真实3D室内环境中根据自然语言指令导航并识别远程目标的能力。任务极具挑战性,要求代理在未见过的环境中识别对象。文章还提出了一种交互式导航器指针模型,并通过实验验证了模型的有效性。
REVERIE任务更加具体地给出了更具有挑战性的任务:根据指令在没见过的环境中识别对象。
REVERIE: Remote Embodied Visual Referring Expression in Real Indoor Environments
一, 引言

孩子们还能够理解自然语言指令,并将其与视觉世界联系起来。
图1显示了一个REVERIE任务的例子。机器人在起始位置接受自然语言指令,该指令指向同一建筑物内另一位置的远程目标对象。为了执行任务,代理需要导航到更靠近对象的位置,并返回包含指令指定的目标对象的边界框。它要求机器人利用环境知识推断物体的可能位置,并根据语言指令明确识别物体。REVERIE更具挑战性,因为目标对象在初始视图中不可见,需要通过在环境中主动导航来发现。
这些高级指令从根本上不同于VLN中的细粒度视觉运动指令,并将支持高级推理和现实应用。
我们在Matterport3D模拟器上构建了REVERIE数据集,该模拟器提供了建筑物中所有可导航位置的全景图和连通图。
扩展模拟器可以将边界框投影到不同视点和角度的图像上,从而能够适应对每个可能位置的评估。
REVERIE数据集包括90栋建筑内的10567幅全景图,包含4140个目标对象,以及平均长度为18个单词的21702条众包指令。表1展示了来自数据集的示例指令,说明了各种语言现象,包括空间关系、多个长修饰语和悬空修饰语以及参考语等。
本文贡献:
- 一个新的具体视觉和语言问题,真实3D室内环境中的远程具体视觉指代表达(REVERIE),在给定表示要执行的实际任务的自然语言指令的情况下,代理必须在真实室内环境中导航和识别远程对象。
- REVERIE任务的第一个基准数据集,包含大规模的人工注释指令,并使用额外的对象注释扩展Matterport3D模拟器。
- 一种新颖的交互式导航器指针模型,在多种评估指标下为REVERIE数据集提供了强大的基线。
二, REVERIE数据集
本节描述REVERIE任务和数据集,包括任务定义、评估指标、模拟器、数据收集策略和收集指令的分析。
2.1 REVERIE任务
我们的REVERIE任务要求智能代理正确定位由简明的高级自然语言指令(见表1中的示例)指定的远程目标对象(在起始位置无法观察到)。值得注意的是,我们的指令比VLN中的详细指令更接近日常生活中的实际场景,因为后者非常复杂和冗长,人类无法控制机器人。由于目标对象与起始对象位于不同的房间中,代理首先需要导航到目标位置。
公式化描述:
正式地说,每一集的开头,给agent一个高级自然语言指令
X
=
w
1
,
w
2
,
,
,
w
L
\mathcal{X}={w_1,w_2,,,w_L}
X=w1,w2,,,wL,L是指令长度,agent可以访问周围的全景图
V
0
=
v
0
,
k
,
k
∈
1
,
…
,
36
\mathcal{V}_0 ={v_{0,k}, k \in 1,\dots,36}
V0=v0,k,k∈1,…,36 (36=12个航角×3个仰角) 和当前的导航视点,其中
v
0
,
k
v_{0,k}
v0,k由代理的状态确定,该状态包括3D位置、航向和仰角的元组
s
0
,
k
=
p
0
,
ϕ
0
,
k
,
θ
0
,
k
s_{0,k}={p_0,\phi_{0,k} , \theta_{0,k} }
s0,k=p0,ϕ0,k,θ0,k(使用3个仰角和12个方位角)。
然后,代理需要执行一系列动作 a 0 , , ˙ a T {a_0, \dot, a_T} a0,,˙aTi以到达目标位置,每个动作都选择一个可导航视点或选择当前视点,这意味着停止。该动作也可以是“检测”动作,输出指令引用的目标对象边界框。值得注意的是,代理可以在任何步骤尝试定位目标,这完全取决于算法设计。但我们只允许代理在每一集中输出一次,这意味着代理在一次运行中只能猜测一次答案。如果代理“认为”它已经定位了目标对象并决定输出它,则需要输出一个边界框或从模拟器提供的几个候选对象中进行选择。边界框表示为 b x , b y , b w , b h {b_x,b_y,b_w,b_h} bx,by,bw,bh,其中bx和by是左上点的坐标,bw和bh分别表示边界框的宽度和高度。在代理输出目标边界框后,剧集结束。
2.2 评估指标
模型的性能主要通过REVERIE成功率来衡量,即成功任务的数量占任务总数的比例。如果任务从一组候选对象中选择了目标对象的正确边界框(或当未给出候选对象边界框时,预测边界框和地面真实边界框之间的IoU≥ 为0.5,则认为任务成功。因为目标对象可以在不同的视点或摄像机视图下观察,所以只要代理可以在3米内识别目标,无论从不同的视场或视图,我们都将其视为成功。我们还用四种指标测量导航性能,包括成功率、oracle成功率、由路径长度(SPL)加权的成功率和路径长度(以米为单位)。请注意,在我们的任务中,只有当代理停在距离目标对象3米以内的位置时,导航才被视为成功。
2.3 REVERIE模拟器
我们的模拟器基于Matterport3D模拟器[1],这是一个基于Matterport3D数据集构建的大规模交互环境[4]。在模拟器中,通过迭代地从全景视点图中选择相邻节点并调整每个视点处的相机姿态,一个具体化的代理能够在每个建筑物中虚拟地“移动”。在每个视点,它返回一个渲染的彩色图像,该图像捕获当前视图,如图1所示。
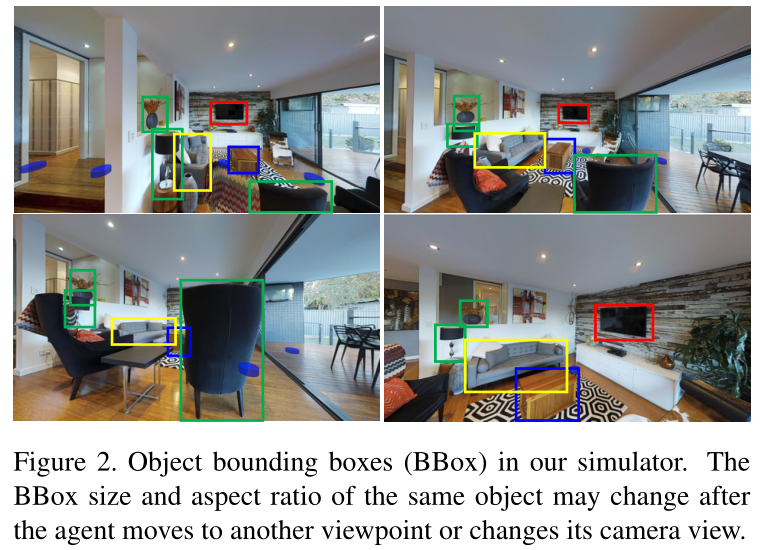
添加对象级注释。 在我们提出的任务中需要对象边界框,它们要么作为对象假设提供,要么用于评估代理定位自然表达式所指对象的能力。将对象边界框添加到模拟器中的主要挑战是,当相机移动或旋转时,我们需要处理2D边界框的可见性和坐标的变化。
为了解决这些问题,我们计算每个视图中边界框和对象深度之间的重叠。如果边界框被另一个边界框完全覆盖,并且它具有更大的深度,我们将其视为被遮挡的情况。具体而言,对于每个建筑,Matterport3D数据集为其中出现的所有对象提供了中心点位置
c
=
c
x
,
c
y
,
c
z
\mathbf{c}={c_x,c_y,c_z}
c=cx,cy,cz、三个轴方向
d
i
=
d
i
x
,
d
i
y
,
d
i
z
,
i
∈
{
1
,
2
,
3
}
d_i=d^{x}_i,d^{y}_i,d^{z}_i, i \in \{1,2,3\}
di=dix,diy,diz,i∈{1,2,3} 和三个半径ri,每个轴方向一个。为了在web模拟器中正确渲染对象,我们首先使用c、di和ri计算八个顶点。然后,通过Matterport3D数据集提供的相机姿势将这些顶点投影到相机空间中。C++和web模拟器都将随代码一起发布。
请注意,目标物体可能在一个房间的多个视点处被观察到,但我们希望机器人可以在短距离内到达目标。
因此,我们只保留距离视点三米以内的物体。
对于每个对象,都会关联一个类标签和一个边界框。但值得注意的是,随着视点和相机角度的变化,我们会相应地调整大小和纵横比。总共,我们获得了20k个对象注释.
2.4 数据收集
我们的目标是收集未来可能分配给家庭机器人的高级人类日常命令,例如“打开厨房的左窗”或“到我的卧室给我拿个枕头”。我们开发了一个交互式3D WebGL模拟器,以收集亚马逊Mechanical Turk(AMT)上的此类指令。网络模拟器首先显示路径动画,然后在目标位置随机突出显示一个对象,以便工人提供查找或操作的指令。命令没有样式限制,只要它可以引导机器人到达目标对象。如果有类似的房间或物体,则向工人提供辅助房间和物体信息,以便于他们提供明确的指示。工人们可以环顾目标位置,了解周围的环境。对于每个目标对象,我们收集三个引用表达式。完整的采集界面(见补充资料)是几轮实验的结果。超过1000名工人参与了数据收集,总共贡献了大约2648小时的注释时间。收集的数据示例见表1,更多的补充数据。
2.5 数据集分析
REVERIE数据集共包含21702条指令和1600多个单词的词汇表。收集的指令的平均长度为18个单词,涉及导航和引用表达式信息。考虑到R2R中提供的详细导航指令的平均长度为29个单词,而之前最大的数据集RefCOCOg[30]平均包含8个单词,我们的指令命令更加简洁自然,因此更具挑战性。

图3(左)显示了所收集的指令的长度分布,这表明大多数指令有10条∼ 22个单词,而最短的注释只3个单词。

图4(左)以单词云的形式显示了指令中使用的单词的相对数量。这表明,人们更喜欢“去”导航,大多数指令都涉及“浴室”。我们还计算了指令中提到的对象的数量,其分布如图3(右)所示。它显示56%的指令提到3个或更多对象,28%的指令提及2个对象,其余15%的指令提及1个对象。平均而言,每个目标视点处有7个对象和50个边界框。数据集中有4140个目标对象,分为489个类别,是目前最流行的引用表达式数据集ReferCOCO[30]中80个类别的6倍。图4(右)显示了不同类别中目标对象的相对数量。
数据集分割
我们遵循与R2R[1]数据集相同的train/val/test分割策略。
训练集由2353个对象上的59个场景和10466条指令组成。
seen和unseen的验证集总共包含63个场景、953个对象和4944条指令,其中10个场景和3573条指令(超过525个对象)保留用于val unseen。
对于测试集,我们收集了6292条指令,涉及随机散布在16个场景中的834个对象。
在培训和验证过程中,所有测试数据都是unseen。测试集的基本事实将不会公布,我们将托管一个评估服务器,在那里可以上传代理轨迹和检测到的边界框进行评分。
三, 交互式导航器指针模型
由于我们的REVERIE任务要求代理导航到目标位置并指出目标对象,一个简单的解决方案是使用最先进的导航(作为导航器)和引用表达式理解(作为指针)方法。然而,导航器和指针如何协同工作非常重要。理想情况下,我们希望导航器和指针相互受益。在这里,我们提出了一种简单而有效的交互方式,作为一个强大的基线,可以实现最佳性能。具体地说,我们的模块包括三个部分:
一个导航器模块,它决定下一步要采取的操作;
一个指针模块,它试图根据语言指南定位目标对象,
一个交互模块,用于将从指针获得的引用表达式理解信息发送到导航器以指导其做出更准确的动作预测的响应。
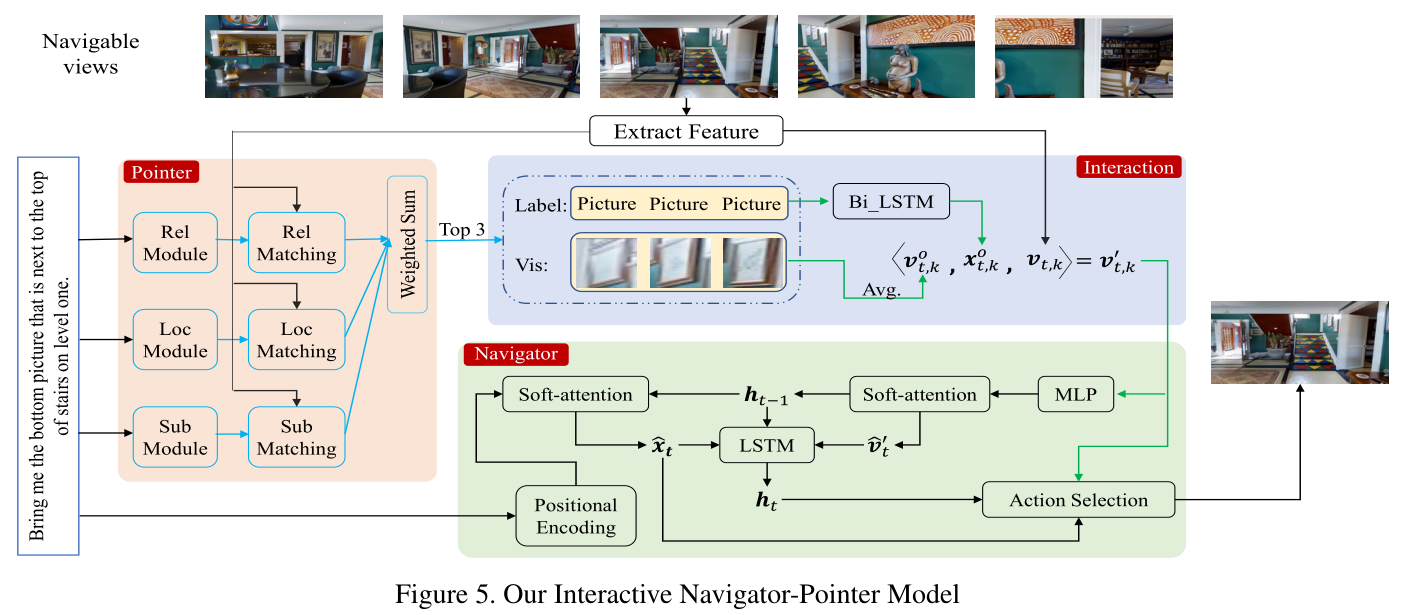
3.1 导航模块
参考:Tactical rewind: Self-correction via backtracking in vision-and-language navigation
我们的导航器模块的主干是FAST的 “short” 版本,它使用具有注意机制和回溯机制的序列对序列LSTM架构来提高动作准确性。
具体来说,让
X
∈
R
L
×
512
X \in \mathbf{R}^{L×512}
X∈RL×512表示通过LSTM从
X
\mathcal{X}
X获得的指令特征,
V
′
\mathbf{V}^{'}
V′
=
{
v
t
,
1
′
;
…
;
v
t
,
K
′
}
= \{ v^{'}_{t,1}; \dots ; v^{'}_{t,K} \}
={vt,1′;…;vt,K′}
∈
R
K
,
4736
\in \mathbf{R}^{K,4736}
∈RK,4736表示我们的交互式模块在步骤 t 为全景图像
V
t
\mathcal{V}_t
Vt 获得的更新视觉特征。首先,grounded文本
x
^
t
=
α
t
⊤
X
\hat{x}_t = \alpha^{\top}_t X
x^t=αt⊤X 和grounded视觉
v
^
t
′
=
β
t
⊤
V
′
\hat{v}^{'}_t = \beta^{\top}_t V^{'}
v^t′=βt⊤V′通过学习:

其中
α
t
∈
R
L
×
1
\alpha_t \in \mathbf{R}^{L×1}
αt∈RL×1是文本注意力权重,
β
t
∈
R
K
×
1
\beta_t \in \mathbf{R}^{K×1}
βt∈RK×1是视觉注意力权重,
W
x
W_x
Wx和
W
v
W_v
Wv是可学习的参数,
P
E
(
⋅
)
P E(·)
PE(⋅)是位置编码,用于捕获指令中每个单词之间的相对位置,
g
(
⋅
)
g(·)
g(⋅)为单层多层感知器(MLP),
h
t
−
1
∈
R
512
×
1
\mathbf{h}_{t-1} \in \mathbf{R}^{512×1}
ht−1∈R512×1 是先前编码器上下文。新的上下文由LSTM更新,以新的文本和视觉特征以及先前选择的动作作为输入:

然后,可以通过每个候选的编码上下文和指令之间的内积来计算logit l t l_t lt

其中
W
a
W_a
Wa 是可学习参数矩阵。
基于logit l t l_t lt,FAST short维护一个候选队列和一个结束队列。当前位置的所有可导航视点(包括当前视点)都被推送到候选队列中,但只有具有最大累积logit ∑ T = 0 t l T \sum^t_{\mathcal{T}=0} l_{\mathcal{T}} ∑T=0tlT 的视点被弹出作为所选下一步。每个通过的视点都被推入结束队列。如果选择了当前视点或候选队列为空或达到最大步长,则一集结束。最后,选择具有最大累积logit的视点作为实际停止位置。
3.2 pointer模块
我们使用MAttNet[29]作为pointer,因为它具有良好的泛化能力。它将表达式分解为三个模块化组件,这些组件与主题外观、位置以及与其他对象的关系有关,通过注意力机制 q m = ∑ j = 1 L a m , j e j q^m = \sum^L_{j=1}a_{m,j}e_j qm=∑j=1Lam,jej 其中 m ∈ { s u b , l o c , r e l } m∈ {sub,loc,rel} m∈{sub,loc,rel}, e j e_j ej是表达式/指令 X \mathcal{X} X中每个单词的嵌入。 a m , j a_{m,j} am,j是每个模块对每个单词的关注。
然后针对每个模块短语嵌入
q
m
q^m
qm条件下的每个对象
o
i
o_i
oi计算三种匹配分数
S
(
o
i
∣
q
m
)
S(o_i|q^m)
S(oi∣qm)。具体而言,
S
(
o
i
∣
q
s
u
b
j
)
=
F
(
v
^
i
s
u
b
j
,
q
s
u
b
j
)
S(o_i|q^{subj}) = F(\hat{v}^{subj}_i, q^{subj})
S(oi∣qsubj)=F(v^isubj,qsubj),
S
(
o
i
∣
q
l
o
c
)
=
F
(
v
^
i
l
o
c
,
q
l
o
c
)
S(o_i|q^{loc}) = F(\hat{v}^{loc}_i, q^{loc})
S(oi∣qloc)=F(v^iloc,qloc) 和
S
(
o
i
∣
q
r
e
l
)
=
m
a
x
j
≠
i
F
(
v
^
i
r
e
l
,
q
r
e
l
)
S(o_i|q^{rel}) = max_{j ≠ i}F(\hat{v}^{rel}_i, q^{rel})
S(oi∣qrel)=maxj=iF(v^irel,qrel),其中
F
(
⋅
)
F(·)
F(⋅)是一个两层的MLP,
v
^
i
s
u
b
j
\hat{v}^{subj}_i
v^isubj是使用14×14网格的每个对象的“in-box”关注特征,
l
^
i
l
o
c
\hat{l}^{loc}_i
l^iloc是对象oi的位置表示,该位置表示由一个完全连接的层获得,并将其与同一类别的最多五个周围对象的相对位置偏移和面积比作为输入。
v
^
i
j
r
e
l
\hat{v}^{rel}_{ij}
v^ijrel是周围对象oj的视觉表示,不考虑类别。
对象
o
i
o_i
oi和指令
X
\mathcal{X}
X的最终匹配分数是加权和:
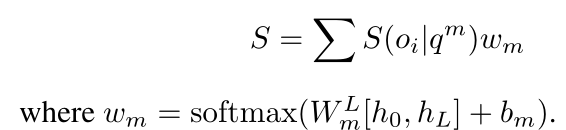
3.3 交互模块
直观地说,我们希望Navigator和Pointer相互交互,从而提高导航和引用表达式的准确性。例如,导航器可以使用视觉接地信息来决定何时何地停止,如果导航器能够到达正确的目标位置,则可以提高指针精度。为此,我们提出了一个交互模块,可以将指针的输出插入导航器。具体来说,我们首先使用上面的指针模块执行引用表达式理解,以选择每个候选视图中的前3个匹配对象。然后,我们使用可训练的双向 LSTM 来编码这些选定对象的类别标签
X
O
=
L
a
b
e
l
i
∈
t
o
p
3
\mathcal{X}_O = {Label_{i \in top3}}
XO=Labeli∈top3

作为第k个候选视点的文本表示。此外,这些对象区域的ResNet FC7层的平均输出被用作视觉表示
v
t
,
k
o
v^o_{t,k}
vt,ko。最后,我们通过连接更新候选视点特征

其被发送到导航器(参见等式2和4)。这种交互中的指针是每个候选视点的重点,它突出了导航器要考虑的最与目标相关的对象.公式2和公式4:
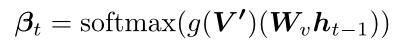
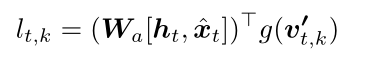
3.4 损失函数
我们的最终损失包括两部分,导航损失
L
n
a
v
L_{nav}
Lnav和引用表达式损失
L
e
x
p
L_{exp}
Lexp。
L
n
a
v
L_{nav}
Lnav是行动选择的交叉熵损失和进度监控的均方误差损失:

其中
y
t
α
y^{\alpha}_t
ytα 是步骤 t 中的ground truth action,
λ
1
λ_1
λ1=0.5 是平衡两个损失的权重,
y
t
p
m
∈
[
0
,
1
]
y^{pm}_t ∈ [0,1]
ytpm∈[0,1]是从当前视点到目标的以长度为单位的归一化距离,
y
t
p
m
y^{pm}_t
ytpm是预测进度。
引用表达式loss
L
e
x
p
L_{exp}
Lexp是排名损失

其中
λ
2
=
1.0
,
λ
3
=
1.0
,
(
o
i
∣
r
i
)
λ_2=1.0,λ_3=1.0,(o_i|r_i)
λ2=1.0,λ3=1.0,(oi∣ri)是正对(对象,表达式) positive pairs (object,expression) ,
(
o
i
,
r
j
)
和
(
o
k
,
r
i
)
(o_i, r_j) 和 (o_k, r_i)
(oi,rj)和(ok,ri) 是 negative pairs(object,expression), δ是正负对之间的距离余量。所有损失汇总如下:

训练我们的交互式导航指针模型。默认情况下,我们将
λ
4
λ_4
λ4设置为1.0.
四, 实验
4.1 实验细节
模拟器图像分辨率设置为640×480像素,垂直视场为60度。对于列车分割中的每一条指令,目标视点处的图像和对象边界框(对于目标对象可见的视图)按照MAttNet中的指针训练格式进行组织。使用经过训练的指针,如第4.3节所述,为导航器提供辅助对象信息,以训练导航器。代码和数据集将被发布。
4.2 REVERIE实验结果
我们首先评估了几种基线模型和最新(SoTA)导航模型,并结合MattNet,即指针模块。导航模型决定停止后,指针模块用于预测目标对象。此外,我们还使用交互式web界面测试人类性能(详见补充资料)
下面是对评估的基线和最先进模型的简要介绍。有四种基线模型,它们是
-
Random 利用数据集的特征,随机选择具有随机步长(最多10步)的路径,然后随机选择一个对象作为预测目标。
-
Shortest 总是沿着通往目标的最短路径。
-
R2R-TF和R2R-S是第一批导航基线,通过注意机制训练基本LSTM。R2R-TF和R2R-SF之间的区别在于,R2R-TF在每一步都使用地面实况动作进行训练(Teacher Forcing,TF),而R2R-SF采用从其动作空间的预测概率中采样的动作(StudentForcing(SF))
评估的四种SoTA导航模型为
-
SelfMonitor 使用视觉文本共同接地模块突出显示下一步行动的指示,并使用进度监视器反映进度。
-
RCM 采用强化学习来鼓励指令和轨迹之间的全局匹配,并执行跨模型基础。
-
**FAST Short ** 将回溯引入SelfMonitor。
-
FAST Lan Only 采用上述FAST Short模型,但我们只输入语言指令,没有任何视觉输入。此模型用于检查我们的任务/数据集是否对语言输入有偏见

结果
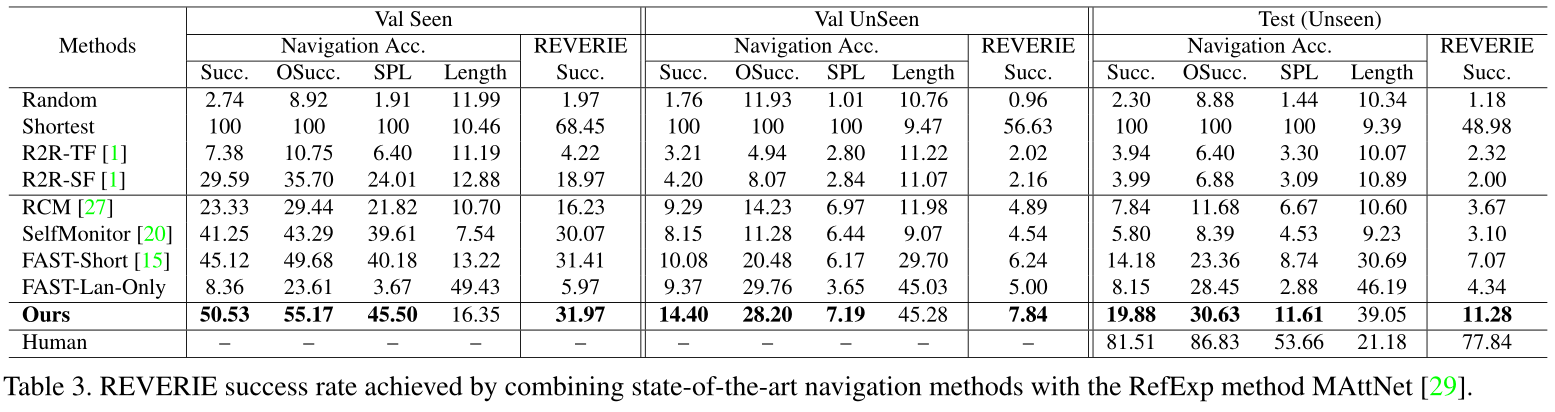
详细的实验结果如表3所示,其中前四行是基线的结果,后四行是SoTA方法的结果,最后两行是我们的模型和人类性能的结果。
根据表3中的基线部分,随机模型的REVERIE成功率仅为1%左右,这表明REVERIE任务有很大的解决空间。序列对序列基线R2R-TF和R2R-SF[1]在Val-Seen分裂上取得了良好的结果,但在unseen上显著减少。学生强迫一般比教师强迫好。最短模型实现了完美的性能,因为直接给出了到达目标的地面真实路径。
在第二部分中,通过SoTA导航(FAST)和引用表达式(MAttNet)模型的组合实现了最佳REVERIE成功率。然而,REVERIE在测试中的成功率仅为7.07%,远远低于人类的77.84%。这些SoTA导航模型的导航精度表明了我们导航任务的挑战。与之前的R2R相比,观察到在unseen上有近30%的下降。例如,Val UnSeen拆分的FAST Short[15]的导航SPL得分从R2R数据集的43%下降到REVERIE的6.17%。
为了测试我们的数据集是否有强烈的语言偏见,即,一个仅使用语言的模型是否能够获得良好的性能,我们实现了一个只使用指令作为输入的FAST仅使用局域网的模型。我们观察到,seen和unseen都大幅下降,这表明,共同考虑语言和视觉信息对我们的任务是必要的。
总的来说,这些SoTA模型结果表明,SoTA导航和引用表达式方法的简单组合不一定会带来最佳性能,因为来自导航器或指针的失败将降低总体成功率。在本文中,我们首次尝试使导航器和指针能够交互工作,如第4.3节所述。表3中的结果表明,我们的交互模型始终比非交互模型取得更好的结果。FAST Short可以被视为我们的烧蚀模型,没有我们提出的交互模块。我们的最终模型在测试分割中获得4.2%的增益
仅引用表达式
我们还报告了仅引用表达式的性能。在此设置中,将代理放置在地面真实目标位置,然后测试引用表达式理解模型。
我们测试了SoTA模型,如MattNet[29]和CMErase[17],以及具有三重排序损失的简单CNN-RNN基线模型。表4显示了人员绩效的结果。它表明,SoTA模型在test上达到了约50%的准确率,这比综合考虑表3中所示的导航和引用表达式时的结果要好得多。尽管如此,与人的表现仍有40%的差距,这表明我们提出的REVERIE任务具有挑战性
4.3
五,总结
实现人类机器人协作是一个长期目标。在本文中,我们通过提出一个在真实室内环境中远程实施的视觉参考表达(REVERIE)任务和数据集,进一步实现了这一目标。
REVERIE是第一个评估代理遵循高级自然语言指令去导航和识别目标对象在之前没见过的真实图像渲染的建筑的能力的代理。我们研究了几个基线和一个交互式导航器指针代理模型,其性能始终表明了在该领域进一步研究的重要必要性。
我们得出三个主要结论:
第一,REVERIE很有趣,因为现有的视觉和语言方法可以很容易地插入。
其次,理解和执行高级指令的挑战是巨大的。
最后,由于与人的表现有很大差距,将教学导航和参考表达理解结合起来是一项具有挑战性的任务。
————————————————————————————————————————————
补充材料
评估指标
-
导航成功Navigation Success:只有在停止视点可以观察到目标对象时,导航才视为成功。请注意,为了鼓励代理靠近目标对象,我们将对象设置为可见,如果它们距离当前位置不到3米。
-
导航Oracle成功Navigation Oracle Success:如果目标对象可以在其传递的视点中观察到,则导航被视为Oracle成功。
-
导航SPL-Navigation SPL:它是由导航路径长度加权的导航成功率,

其中N是任务数, S i ∈ { 0 , 1 } Si∈ {0,1} Si∈{0,1}是任务i 成功的二进制指标, l i \mathcal{l}_i li是任务i的起始视点和目标视点之间的最短长度, p i p_i pi是任务i的代理的路径长度。
-
导航长度Navigation Length:轨迹长度(米)。
-
REVERIE Success:如果输出边界框具有IoU(相交于并集),则任务视为REVERIE成功≥ 0.5与地面真相
其他的就是一些可视化的例子

















 602
602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









