






这是第一篇提出 视觉对话导航 的任务的论文
链接:https://cvdn.dev/
Vision-and-Dialog Navigation
一,引言
本文定义了个 Navigation from Dialog History 任务。CVDN可用于训练导航代理,如语言远程操作的家庭和办公室机器人,在不确定的情况下询问下一步该去哪里的目标问题。
此外,CVDN还可以用于培训能够回答此类问题的agent,只要他们具备环境方面的专家知识,就可以为不熟悉的地方的人提供自动语言指导(例如,在办公楼问路)。
CVDN中使用的照片级真实感环境可以使经过模拟训练的代理能够进行和理解人类的对话,从而将这些技能传递到现实世界。
CVDN中的对话框包含的单词几乎是R2R指令的三倍,覆盖的平均路径长度比R2R中的路径长三倍多。
本文基于R2R任务[7],使用相同的模拟器和API训练导航代理。MatterPort包含90个3D房屋扫描,每个扫描
S
S
S分为可视全景图
p
∈
S
p ∈ S
p∈S(导航代理可以占用的节点),并伴随邻接矩阵
A
S
A_S
AS。
我们区分
s
t
e
p
s
steps
steps和(p和q之间的)
d
i
s
t
a
n
c
e
distance
distance ,
s
t
e
p
s
steps
steps 表示中间节点的数量
d
h
d_h
dh,而距离以米为单位定义为
d
m
d_m
dm。
步长距离
d
h
(
p
,
q
)
d_h(p,q)
dh(p,q)是通过
A
S
A_S
AS 从节点p到节点q的跳数。如果
A
S
[
p
,
q
]
=
1
A_S[p,q]=1
AS[p,q]=1,则以米为单位的距离
d
m
(
p
,
q
)
d_m(p,q)
dm(p,q)定义为物理距离,否则定义为p和q之间的最短路径。平均而言,1步对应2.25米。
在每个时间步,代理都会发出在模拟环境中执行的导航操作。动作是 l e f t , r i g h t , u p , d o w n , f o r w a r d left ,right, up , down, forward left,right,up,down,forward, or s t o p stop stop。在采取除停止以外的任何操作后,代理将从环境接收新的视觉观察。只有当代理面对相邻节点时, f o r w a r d forward forward操作才可用
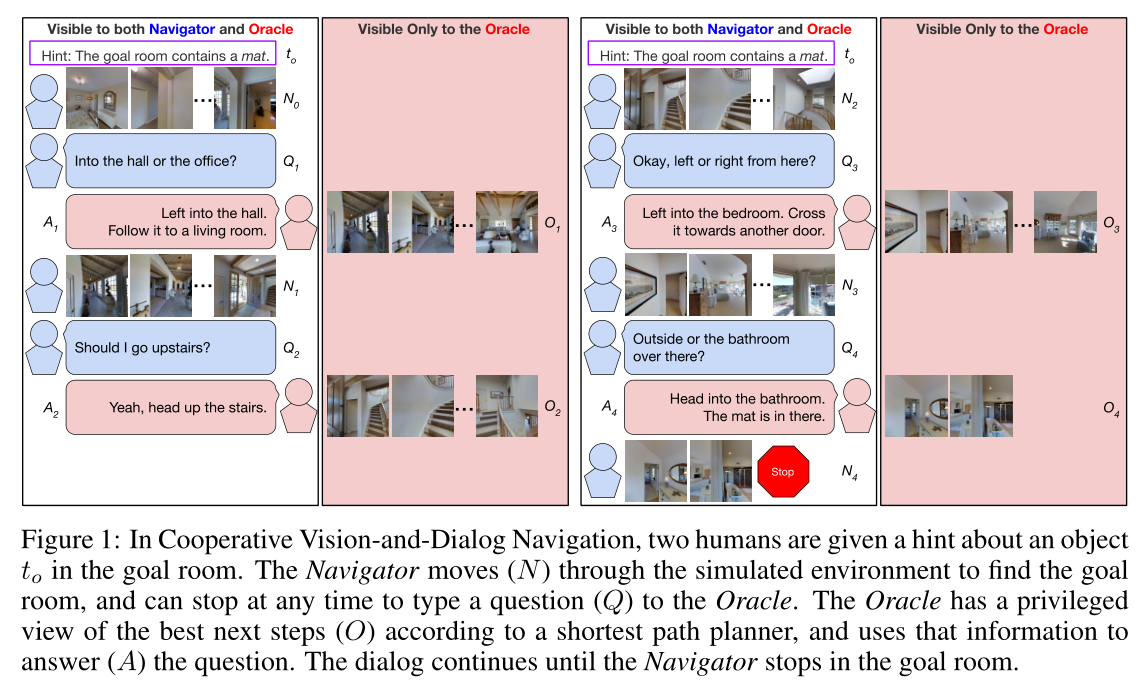
二,协作视觉和对话导航数据集(CVDN)
我们收集了2050个人类导航对话,包括83个MatterPort[6]房屋中的超过7k个导航轨迹,其中有问答交流。我们用含糊不清和未明确说明的初始说明进行提示。不明确的导航指令需要澄清,因为它可能涉及多个可能的目标位置。
未指定的导航指令是指没有描述到达目标的路线的指令。
2.1 对话提示
对话提示dialog prompt是房屋扫描
S
S
S、要查找的目标对象
t
o
t_o
to、起始位置
p
0
p_0
p0和目标区域
G
j
G_j
Gj的元组。我们使用MatterPort对象分割来获取区域位置为household objects。我们定义了一组81个唯一的对象类型,它们至少出现在5个唯一的房子中,每个房子出现2到4次。2每个对话框都以一个提示开始,例如“目标房间包含一棵植物”,根据构造,这个提示既不明确(有两到四个房间有一棵植物),也underspecified(提示中没有描述通往房间的路径
给定房屋扫描
S
S
S 和目标对象
t
o
t_o
to,将为房屋中包含
t
o
t_o
to实例的每个目标区域
G
j
G_j
Gj创建对话框提示。目标区域是房屋扫描中占据同一房间的节点集。选择起始节点
p
0
p_0
p0 以最大化
p
0
p_0
p0 与包含
t
o
t_o
to 的目标区域
G
0
:
∣
G
∣
G_{0:|G|}
G0:∣G∣ 之间的距离。

2.2 Crowdsourced数据收集
我们通过Amazon Mechanical Turk收集人类对话。3在每个人工智能任务(HIT)中,工人阅读有关导航器和Oracle的角色,并可以练习使用导航界面。一对工人通过聊天界面相互连接。
每个对话框都是通过随机选择的提示 S , t o , p 0 , G j S,t_o,p_0,G_j S,to,p0,Gj实例化的,导航器从全景图 p 0 p_0 p0开始,两名工作人员都通过文本指示:“提示:球门室包含一个to。”对话框以导航器开始。轮到导航员时,他们可以导航,键入一个自然语言问题询问甲骨文,或者猜测他们找到了目标房间。
不正确的猜测导致无法继续导航,并迫使导航器向Oracle提问。在整个导航过程中,甲骨文被视为导航器界面的镜子,因此两名工作人员都始终意识到当前的视觉框架。轮到甲骨文的时候,他们可以根据最短路径规划器查看一个动画,描述接下来5次通过导航图到达目标房间的过程,并通过自然语言与导航器进行沟通(图1)。选择了五跳,因为这比R2R数据集中的6跳平均路径略短,人类注释员能够提供合理的语言描述。每个HIT支付每个工人1.25美元,整个数据集收集成本超过7000美元。
在成功找到目标房间后,工人们对合作伙伴的合作性进行了评分(从1分到5分)。未能保持4分或更高平均同行评分的工人被禁止参加更多的HIT。平均而言,对话参与者在CVDN中的平均同伴评分为4.52/5。
2.3 分析
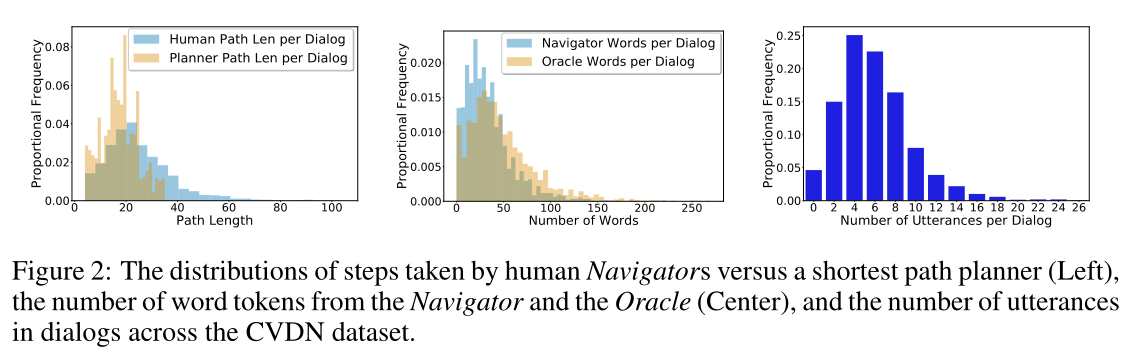
CVDN数据集比R2R任务具有更长的路径和语言上下文。对话框显示复杂的现象,需要对话框和导航历史来解决。
图2显示了CVDN数据集中对话框中的路径长度、字数和话语数的分布。人类(25.0±12.9)和规划者(17.4±7.0)的路径长度平均比R2R(6.0±0.85)的路径长三倍多,并且具有更高的方差。导航仪(33.5)和神谕(48.1)的平均字数总计为每个对话平均81.6个单词,再次超过了每个指令29个单词的房间间平均值将近三倍
对话平均每次约有6次发言(3次问答交流),其中一小部分的发言时间要长得多,多达26次。有些对话没有交流(约5%):导航员仅凭直觉就能找到目标位置。因为不止一个房间总是包含,所以这些都是“幸运”的猜测
我们随机抽取了100个对话,其中至少有一个问答交换,并注释了每个话语(每个说话者342个)是否表现出某些现象(表2)。Navigator和Oracle角色的一半以上的话语,以及所有对话的90%以上,都包含以自我为中心的引用,需要代理的位置和方向来解释。一些Oracle答案需要Navigator问题来解决(例如,当答案只是确认时)。一些话语需要以前交流的对话历史或过去的视觉导航信息。当说话者试图纠正错误时,超过10%的对话表现出会话修复。演讲者有时会通过离题的评论和笑话建立融洽关系。两位演讲者,特别是那些担任导航员的演讲者有时会发送空洞的通信,但这仅限于较小比例的对话。
试图执行导航、提问或回答关于具体环境的问题的模型必须与这些类型的现象作斗争。例如,代理可能不仅需要参与最后一次QA交换,还需要参与整个对话和导航历史记录,以便正确地遵循说明。
三,从对话框历史记录导航任务
CVDN为训练代理提供导航、提问和问答服务。
在本文中,我们主要讨论导航。在给定的对话历史中成功导航的能力是视觉和对话导航范例中任何未来工作的关键。每个对话框都是一系列Navigator问题和Oracle答案交换,每个交换之后都有Navigator步骤。我们使用这种结构将对话框从对话框历史(NDH)实例划分为导航。
特别是,CVDN实例每个都由导航动作的重复序列 < N 0 , Q 1 , A 1 , N 1 , … , Q k , A k , N k > <N_0,Q_1,A_1,N_1,…,Q_k,A_k,N_k> <N0,Q1,A1,N1,…,Qk,Ak,Nk>的N,Navigator询问的问题的Q,以及Oracle的答案A组成。对于每个带有提示 ( S , t o , p 0 , G j ) (S,to,p0,Gj) (S,to,p0,Gj) 的对话框,将为每个创建一个NDH实例 0 ≤ i ≤ k 0 \le i \le k 0≤i≤k、 输入是到和一个(可能是空的)问答历史 ( Q 1 : i , A 1 : i ) (Q_{1:i}, A_{1:i}) (Q1:i,A1:i)。任务是从Ni的终端节点开始,预测使代理更接近目标位置 G j G_j Gj的导航动作 N i − 1 N_{i-1} Ni−1(或 p 0 p_0 p0,对于 N 0 N_0 N0)。我们从CVDN中的2050导航对话框中提取了7415个NDH(Navigation from Dialog History)实例
我们将这些实例分为训练、验证和测试折叠,通过房屋扫描保留R2R折叠。这种划分由对话框进一步完成,因此对于CVDN中的每个对话框,从中创建的NDH实例都属于同一个文件夹。与R2R一样,我们根据扫描是否存在于训练集中,将验证步骤分为可见和不可见的房屋扫描。这导致了4742个训练、382个seen验证、907个unseen验证和1384个unseen测试实例。
我们为NDH任务提供了两种形式的监督:
N
i
N_i
Ni,即Navigator在问答交换 i 后所采取的导航步骤,
O
i
O_i
Oi,即向
O
r
a
c
l
e
Oracle
Oracle显示并用作上下文以提供答案Ai的最短路径步骤。
在任务的每个实例中,i在从中绘制实例的对话框中对QA交换进行索引(
i
=
0
i=0
i=0 表示空的QA,然后是初始导航步骤)。在NDH实例中,
N
i
N_i
Ni步长从1到40(平均6.63),
O
i
O_i
Oi步长从0到5(平均4.35)。导航器通常比oracle描述的更进一步,使用他们对房屋布局的直觉来寻找目标对象。
我们通过测量代理人在 G j G_j Gj方面取得的进展来评估该任务的绩效。设 e ( P ) e(P) e(P) 是路径P的结束节点, b ( P ) b(P) b(P)为起点, P ^ \hat{P} P^是导航代理推断的路径。然后,朝向目标的进展被定义为在 b ( P ^ ) b(\hat{P}) b(P^)与在 e ( P ^ ) e(\hat{P}) e(P^) 时从距离目标区域Gj的距离的减少(以米为单位)。因为Gj是一组节点,所以我们取最小距离 m i n p ∈ G j ( d m ( p , q ) ) min_{p∈Gj}(dm(p,q)) minp∈Gj(dm(p,q)) 作为 q q q 和区域 G j G_j Gj 之间的距离。请注意,这是一个拓扑距离(例如,我们测量墙周围的距离,而不是直接穿过墙。)
四,实验
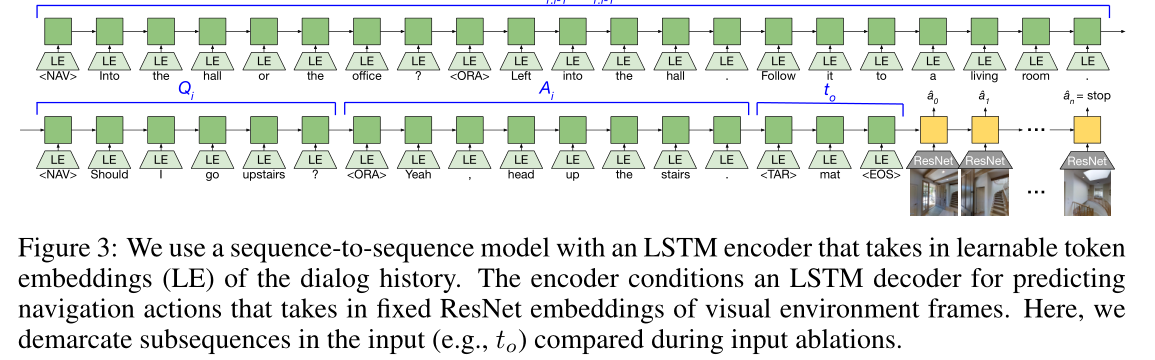
Anderson等人[7]引入了序列到序列模型,作为R2R任务的学习基线。我们制定了一个类似的模型来编码整个对话历史,而不是单个导航指令,作为NDH任务的初始学习基线。对话历史使用LSTM编码,并用于初始化LSTM解码器的隐藏状态,该解码器的观察是来自环境的视觉帧,其输出是环境中的动作(图3)。
我们将出现少于5次的单词替换为UNK标记。最终的词汇表大小在训练中为1042个语言标记,在组合训练和验证中为1181个标记。我们还使用特殊的NAV和ORA标记来为说话者的标记做序言,使用TAR来为目标对象标记做序语,使用EOS来指示输入序列的结束。(We also use special NAV and ORA tokens to preface a speaker’s tokens, TAR to preface the target object token, and EOS to indicate the end of the input sequence.)在训练期间,学习每个令牌的嵌入,并将其作为输入提供给编码器LSTM。对于视觉特征,我们将视觉框架嵌入为Imagenet预训练的ResNet-152模型的倒数第二层[31]。
当针对验证进行评估时,我们只针对训练进行训练。当根据测试折叠进行评估时,我们对训练折叠和验证折叠的联合进行训练。我们消除了对话历史编码的距离,并在训练时引入了一种混合规划和人工监督策略。我们假设,编码较长的对话历史和使用混合监督步骤将增加代理人朝目标前进的数量。

训练
给定来自端节点e(P∗), 代理推断导航动作以形成路径
P
^
\hat{P}
P^。我们对所有代理进行批量大小为100的20000次迭代的学生强制训练,并每100次迭代评估验证性能。所有时期的最佳性能报告用于验证折叠。
在每个时间步,代理执行其推断的动作
a
^
\hat{a}
a^,并使用交叉熵损失对动作
a
∗
a^*
a∗进行训练,那是最短的到最终节点的路径
e
(
P
∗
)
e(P^*)
e(P∗).使用整个导航路径,
P
∗
P^∗
P∗, 因为在其他工作中考虑了监督而不是仅考虑端节点。在测试时,代理被训练到在看不见的验证倍数上获得最佳性能的时期,然后进行评估(例如,每个代理只运行一次测试倍数评估
回想一下,对于每个NDH实例,给出了QA交换期间显示给Oracle的路径i,Oi,以及交换后导航器所采用的路径Ni。当e(Oi)∈ Ni or Oi。这种新的监督形式与以往关于从不完美或敌对的人类演示中学习的工作类似。一种常见的解决方案是使用不完美的人类演示来学习初始策略,然后使用强化学习(RL)进行细化[33]。通过首先为演示分配一个置信度度量,并且只包括那些通过某个阈值的演示,可以提高学习性能[34]。虽然我们将对更复杂的RL方法的评估留给未来的工作,但上述混合监督可以被认为是使用简单的二元置信启发式来阈值人类演示
基线和消融
我们将序列到序列代理与完整状态信息最短路径代理、非学习基线和单峰基线进行比较。最短路径代理在推理时采用到监督目标的最短路径,并表示学习代理在给定形式的监督下所能做的最好。非学习型随机代理选择一个随机方向并向前走5步。在VLN任务中,仅考虑视觉输入、仅考虑语言输入或两者都不考虑的单峰模型消融代理可以优于随机基线[35]。因此,我们还将我们的代理与单峰基线进行了比较,在单峰基线中,代理在每个解码器时间步(无视觉基线)和/或编码器的空语言输入(无语言基线)将视觉特征归零,以代替 V V V ResNet特征。为了检查对话历史的影响,我们考虑有权访问目标对象 t o t_o to 的代理;最后一个Oracle回答 A i A_i Ai;领航员提问 Q i Q_i Qi;以及完整的对话历史记录.
结果
表3显示了不同监督形式下的代理人表现。我们在每个监督范式和跨范式的所有模型消融之间进行配对t检验,并应用Benjamini–Y ekutieli程序控制假发现率(详见附录)。
在看不见的环境中,使用所有对话历史显著优于单模态消融。Navigator监控Ni的最短路径代理性能接近NDH上的人类性能,因为e(Ni)是数据收集期间QA交换i后人类Navigator到达的节点。序列到序列模型建立了NDH的初始多模式基线,与人类表现相比,尤其是在看不见的环境中,仍有余量。需要使用所有对话历史,而不仅仅是最后一个问题或问答交换,以获得比在看不见的测试环境中单独使用目标对象更好的统计性能。这支持了我们的假设,即对话历史有助于理解最新导航指令 A i A_i Ai的上下文。使用混合监督训练的模型在统计上总是显著优于使用Oracle或导航员监督训练的那些模型。这支持了我们的假设,即只有在看起来可信的情况下使用人类演示才能提高agent朝着目标的进展,
五,总结与未来工作
总结:
我们介绍了合作视觉和对话导航:2050人,在照片般逼真的模拟环境中定位导航对话。对话包含复杂的现象,需要以自我为中心的视觉基础,并参考对话历史和过去的导航历史来获取上下文。CVDN是研究现场导航交互的一种宝贵资源,对于训练既能在人类环境中导航又能在不确定的情况下提出问题的代理人,以及为在陌生地方导航的人提供口头帮助的代理人,CVDN都是一种宝贵的资源。
然后,我们定义“从对话框历史记录导航”任务。我们的评估表明,对话历史与导航代理学习基于对话的指令和正确导航操作之间的映射相关。此外,我们发现,使用人类和规划者监督的混合形式结合了两者的优点:根据人类直觉对环境进行长期探索以找到目标,以及与语言输入保持一致的短期准确性。
局限性:
CVDN数据集基于MatterPort模拟器中的房间到房间任务[7]。我们希望使用CVDN来训练真实世界的对话和导航代理。仅仅对真实世界数据进行微调可能是不够的。真实世界的机器人导航依赖于激光扫描深度,而不仅仅是RGB信息,并且会引发低质量的自我中心视觉、传感器噪声和定位问题。虽然模拟提供了照片般真实的环境,但它受到了离散的、基于图形的导航的影响,需要映射真实世界的可导航环境并将其划分为拓扑航路点。在高保真、连续运动模拟器(例如[36])中收集的人机对话或使用虚拟现实技术可能有助于更容易地转移到物理机器人平台。然而,与现有的R2R任务共享仿真环境意味着对话历史任务(如NDH)的模型可以从R2R的预训练中受益。
未来工作:
我们实验中使用的序列到序列模型用作NDH任务的初始学习基线。向前看,通过将NDH制定为一个顺序决策过程,我们可以使用RL来塑造代理的策略,如最近的VLN工作[37]。对话分析还表明,历史导航动作中存在初始模型未考虑的相关信息。联合调节对话和导航历史可能有助于解决过去的参考指令,如“回到楼梯间,走一段楼梯”,并可能涉及跨模态注意力对齐。
CVDN数据集还为以导航为中心的提问和问答任务提供了一个框架。在我们未来的工作中,我们将探索训练两名特工:一名在迷路时导航和提问,另一名回答这些问题。这将有助于对CVDN进行端到端评估,并将不同于所有现有的VLN任务,因为涉及两个经过训练的代理参与面向任务的对话。

















 1546
1546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









