







Vision-Language Navigation with Random Environmental Mixup
摘要: 视觉语言导航(VLN)任务要求代理在感知视觉观察和理解自然语言指令的同时逐步导航。
由小的数据规模和大的导航空间之间的差异比引起的大范围的数据偏差,使得VLN任务具有挑战性。以前的工作已经提出了各种数据增强方法来减少数据偏差。然而,这些工作并没有明确减少不同房屋场景中的数据偏差。因此,agent将过度适应已看到的场景,并在unseen场景中的导航性能较差。
为了解决这个问题,我们提出了随机环境混合(Random Environmental Mixup REM)方法,该方法通过混合环境生成交叉连接的房屋场景作为增强数据。
具体来说,我们首先根据每个场景的房间连接图选择关键视点。然后,我们交叉连接不同场景的关键视图以构建增强场景。最后,我们在交叉连接的场景中生成增强指令路径对。在基准数据集上的实验结果表明,我们通过REM的增强数据有助于代理减少其在seen和unseen环境之间的性能差距,并提高整体性能,使我们的模型成为标准VLN基准(主要指r2r)的最佳现有方法。

一,介绍
1.1 之前的工作有哪些问题
-
尽管最广泛使用的Room to Room数据集[4]仅包含22K条指令路径对,但实际可能的导航路径空间随着路径长度呈指数增长。因此,学习的导航策略可以很容易地过渡到所看到的场景,并且很难推广到未看到的场景。
-
之前的数据增广的方法都是属于场景内的数据增强,未能明确减少不同房屋场景的数据偏差。这肯定不利于模型在unseen上的表现。
1.2 本文怎么做的
- 本文建议 通过场景化数据增强来减少不同房屋场景之间的领域差距。如果代理在导航过程中看到不同的房屋场景,则不太可能过度渲染场景纹理或房间结构的一部分。
- 受这种动机的启发,本文提出了称为随机环境混合(REM)的方法,以提高导航代理的泛化能力。REM分解两个场景和相应的路径,然后重新组合它们以获得两个场景之间的交叉连接场景。REM方法提供了更多的泛化数据,这有助于减少泛化误差,从而可以提高代理在可见和不可见场景中的导航能力。
- REM方法包括三个步骤。
首先,REM根据betweenness centrality选择房间连接图中的关键顶点。
其次,REM通过关键顶点分割场景,并将它们交叉连接以生成新的增强场景。我们提出了一种方向对齐方法来解决特征不匹配问题。
最后,REM根据上下文将轨迹和指令拆分为子轨迹和子指令,然后交叉连接它们以生成增强的训练数据。 - 实验结果表明REM可以显著减少可见和不可见环境之间的性能差距,从而显著提高整体导航性能
二,Preliminaries
这一块,每篇论文内容都差不多,但是符号有差别,所以每次都重写一遍。
2.1 Vision-language Navigation
给定一系列三元组(环境E、路径P、指令I),VLN任务要求代理理解指令,以便在相应的环境中找到匹配的路径。环境 E 包含大量seen和unseen场景,路径
P
=
{
p
0
,
…
,
p
n
}
P= \{p_0,…,p_n\}
P={p0,…,pn}由长度为 n 的视点列表组成;此外,指令
I
={
w
0
,
…
,
w
m
}
I={w_0,…,w_m\}
I={w0,…,wm}由 m 个单词组成,路径P 和指令I 之间存在一定的对应关系。在时间步骤 t,agent观察panoramic views
O
t
=
{
o
t
,
I
}
i
=
1
36
O_t=\{o_{t,I}\}^{36}_{i=1}
Ot={ot,I}i=136和navigable
viewpoints (最多k个)。图片
O
t
O_t
Ot被分成水平方向的12个视图和垂直方向的3个视图,总共36个视图
o
t
,
i
o_{t,i}
ot,i。在第 t 步,代理预测动作
a
∼
π
θ
(
I
,
O
t
)
a∼ π_θ(I, O_t)
a∼πθ(I,Ot),其中
π
θ
π_θ
πθ 是由参数 θ 定义的策略函数。动作包括Matterpot环境中定义的“左转”、“右转”和“向前移动”等。在Matterport数据集中,每个场景由视点组成的导航图离散化。我们将每个场景建模为图
G
=
(
V
,
E
)
G=(V, E)
G=(V,E),其中顶点集 V 是一组场景viewpoints,而 E 是视点之间的连接。
2.2 Reduce Generalization Error in VLN
学习问题可以表述为函数
f
∈
F
f∈ F
f∈F的搜索、 使给定损失的预期最小化
ℓ
(
f
(
x
)
,
y
)
ℓ(f(x), y)
ℓ(f(x),y)。然而,样本(x,y)的分布
P
\mathcal{P}
P通常是未知的。我们经常可以得到一个集合
T
∼
P
\mathcal{T}∼\mathcal{P}
T∼P 并将其用作训练集。然后,近似函数
f
^
\hat{f}
f^ 可以通过经验风险最小化(Empirical Risk MinimizationERM)来实现。然而
f
^
\hat{f}
f^和
f
f
f之间仍然存在差距。这个error描述了
f
f
f 的泛化能力。
generalization error 可以表示如下

为了增强
f
^
\hat{f}
f^ 的泛化能力,有必要减少
R
g
e
R_{ge}
Rge。根据邻近风险最小化(Vicinal Risk Mini-
mizationVRM)

其中
(
x
^
,
y
^
)
∈
(
T
∪
T
^
)
(\hat{x},\hat{y})∈ (\mathcal{T}∪ \mathcal{\hat{T}})
(x^,y^)∈(T∪T^),
T
\mathcal{T}
T ∼
P
\mathcal{P}
P、
T
^
⊈
T
\mathcal{\hat{T}} ⊈ \mathcal{T}
T^⊈T, 这意味着需要更多的样本来降低
R
g
e
R_{ge}
Rge。当样本数一定时,从样本
(
x
^
,
y
^
)
(\hat{x}, \hat{y})
(x^,y^)到训练集
T
\mathcal{T}
T 的距离
d
(
(
x
^
,
y
^
)
,
T
)
d((\hat{x}, \hat{y}), \mathcal{T})
d((x^,y^),T) 越远,泛化能力越好。
在VLN任务中,训练集由N个场景组成

我们定义了数据增强函数
a
u
g
(
S
i
,
S
j
)
aug(S_i,S_j)
aug(Si,Sj)。生成的增强数据遵循分布
P
\mathcal{P}
P:
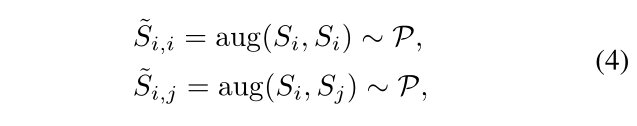
其中
S
^
i
,
i
\hat{S}_{i,i}
S^i,i是场景内增强数据集,而
S
^
i
,
j
\hat{S}_{i,j}
S^i,j是场景间增强数据集。根据等式1和2,我们有以下假设:与
S
^
i
,
i
\hat{S}_{i,i}
S^i,i相比,从
S
^
i
,
j
\hat{S}_{i,j}
S^i,j到
S
i
S_i
Si的距离更远,表示为 $d(\hat{S}{i,i}, S_i) < d(\hat{S}{i,j}, S_i) $。因此,在场景间增强数据上学习的模型具有比在场景内增强数据上所学习的模型更小的泛化误差。
先前的方法在VLN中提出了两种数据增强方法:场景内增强(ISA)方法,如[16]中所述,仅在场景中构建新的路径和指令;如[51]中所述,近场景增强(NSA)方法通过将高斯噪声添加到场景中,在一定程度上突破了场景的限制,但仅将场景扩展到较小的邻域。就我们而言,我们提出了一种场景间数据增强方法:随机环境混合(REM)。REM方法混合两个场景,在两个场景之间构建交叉连接的场景。相较于其他方法,它超越了场景本身的限制,并在更广泛的数据分布下构造增强数据。

图2说明了三种方法之间的差异。场景间方法提供了更广泛的数据;这有助于减少泛化误差,这意味着可以提高代理在可见场景和不可见场景中的导航能力。随后的实验验证了这一假设。
三,方法(Random Environmental Mixup)
我们提出了一种场景间数据增强方法,以在训练集的帮助下构建新的环境、路径和指令。在VLN任务的训练集中,有大量不同的场景。我们从一组训练场景中随机选择两个场景,并将它们混合,以生成交叉连接的场景。采用这种方法使我们能够构建相应的路径和指令。在混合场景时,我们有以下问题:
1)如何选择场景中的关键顶点进行混合? (3.1节)
2) 如何混合两个场景以获得交叉连接的场景? (3.2节)
3) 如何在交叉连接的场景中构建新的路径和指令?(3.2节)
下面给出了这些问题的解决方案,构建了大量交叉连接的场景,这些场景相对于原始训练集是看不到的。

3.1 Select Key Vertexes
关键顶点对于场景之间的混合至关重要。它们的特点可以概括为:
1)连接两个房间的入口或走廊;
2) 顶点有许多穿过它的路径。
为了匹配上述特征,可以参考图的betweenness centrality(中间中心度)来选择关键顶点。

其中
V
C
B
(
v
)
VC_B(\mathcal{v})
VCB(v)是顶点
v
\mathcal{v}
v 的 betweenness centrality,
E
C
B
(
e
)
EC_B(e)
ECB(e)是边缘 e 的 betweenness centrality;
σ
s
t
(
v
)
σ_{st}(\mathcal{v})
σst(v)是从s 到 t通过顶点v的最短路径数;
σ
s
t
(
e
)
σ_{st}(e)
σst(e)是通过边 e从s到t的最短路径数;
σ
s
t
σ_{st}
σst是从s到t的所有最短路径的数量。
中间中心性通过(经过顶点或边的)最短路径数量来描述顶点的重要性。一旦顶点从图形中移除,两边的点将断开连接。
如图3所示,我们选择中间中心度的前10个顶点和边,以获得相应的集合 V V C B V^{VC_B} VVCB和 E E C B E^{EC_B} EECB;随后,通过排除 E E C B E^{EC_B} EECB 中顶点不在 V V C B V^{VC_B} VVCB 中的边,我们获得了最终的关键子图 G C B G^{C_B} GCB。为了确保后续生成更多的路径,我们选择包含 G C B G^{C_B} GCB 中受监督最多的路径的边缘 e k e y e^{key} ekey 及其相应的顶点 v s k e y 、 v t k e y v^{key}_s、v^{key}_t vskey、vtkey。我们从图3发现房间或走廊的入口和出口之间的间距通常最高。在算法1中总结了选择关键顶点的过程。


3.2 Construct Augmented Triplets
3.2.1 Construct Cross-Connected Scenes
我们在训练集中随机选择两个场景(场景1
G
1
G_1
G1 和场景2
G
2
G_2
G2)。我们分三个阶段构建
G
1
G_1
G1 和
G
2
G_2
G2 的交叉连接场景
G
C
G_C
GC(如图4)。
在阶段1选择关键节点:根据算法1,我们获得 G1 的关键顶点
(
v
s
k
e
y
1
,
v
t
k
e
y
1
)
(v^{key1}_s,v^{key1}_t)
(vskey1,vtkey1)和G2的关键顶点
(
v
s
k
e
y
2
,
v
t
k
e
y
2
)
(v^{key2}_s,v^{key2}_t)
(vskey2,vtkey2).
在第2阶段交叉连接两个场景中的节点:我们将
G
1
G_1
G1和
G
2
G_2
G2混合到图
G
C
G_C
GC中,断开两个关键边
e
k
e
y
1
,
e
k
e
y
2
e^{key1},e^{key2}
ekey1,ekey2并连接
(
v
s
k
e
y
1
,
v
t
k
e
y
2
)
(v^{key1}_s,v^{key2}_t)
(vskey1,vtkey2),
(
v
s
k
e
y
2
,
v
t
k
e
y
1
)
(v^{key2}_s,v^{key1}_t)
(vskey2,vtkey1)。通过这种方式,我们获得了交叉连接的场景
G
C
G_C
GC。
在第3阶段方向对齐:我们调整
G
C
G_C
GC的方向;通过调整
G
C
G_C
GC中的顶点位置,确保交叉路径与指令的匹配。
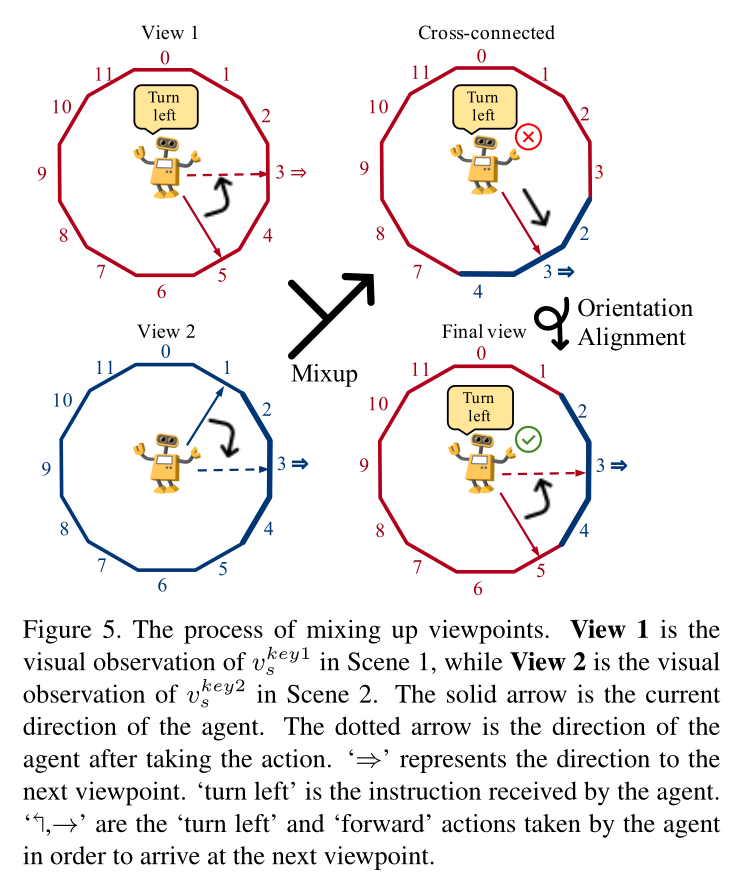
3.2.2 Construct Cross Viewpoints
G
C
G_C
GC是一个包含连接关系信息的图,不需要视觉观察。因此,我们在
G
C
G_C
GC的基础上构建了一个交叉视点,以获得一个新的交叉连接环境。构建新的交叉连接环境的过程如图5所示。以场景1+2中的
v
s
k
e
y
1
v^{key1}_s
vskey1 为例,如第3.1节所述,每个视点全景视图在水平方向上分为12个视图(由数字0–11表示)。通过混合视图1和视图2的视图,我们可以获得视图1+2的全景视图。
更具体地说,视图基于下一个视点的方向。我们将视图2的原始角度周围的三个视图替换为视图1,以获得交叉连接视图(视图1中的
红色
0
–
3
,
7
–
11
\red{红色0–3, 7–11}
红色0–3,7–11,视图2中的
蓝色
2
–
4
\blue{蓝色2–4}
蓝色2–4)。
实验部分将讨论用于替换3个视图的超参数设置。(感觉参考图5还不如参考图4)
3.2.3 Construct Cross Paths and Instructions
交叉连接指令和路径要求指令和路径是细粒度的。为了获得细粒度数据,我们使用细粒度 R2R 分割指令和路径,以及对齐子指令和子路径。如图4(阶段3)所示,我们通过 组合 关键顶点前后的子路径以及相应的子指令,获得交叉连接场景中的路径和指令.
3.2.4 Orientation Alignment
(参考图4可以理解怎么做的,参考图5可以理解怎么做的)
按照图4(阶段1和2),我们构建了交叉连接的场景和相应的交叉视点。简单地连接
v
s
k
e
y
1
v^{key1}_s
vskey1 和
v
t
k
e
y
2
v^{key2}_t
vtkey2会导致顶点的相关方向不匹配在交叉连接的场景中,因此有必要对准顶点的取向。更具体地说,在场景和视图混合之后⇒’ 更改(图5从90◦ 至150◦). 相应地,为了使其能够进入下一个视点,代理的动作也发生了变化(从“↰’ 至’→’). 然而,指令仍然是“左转”。
为了解决动作和指令不匹配的问题,我们需要在交叉连接的场景上固定位置。
为了实现这一点,如图4(阶段3)所示,我们移动顶点
v
t
k
e
y
1
v^{key1}_t
vtkey1,
v
t
k
e
y
2
v^{key2}_t
vtkey2及其相关顶点,交换两个顶点的位置,这意味着关键顶点的相对位置保持不变。
通过固定顶点的位置⇒’ 对齐(见图5最终视图),代理人的行动和指示相应地再次匹配。
3.3 Augmentation in Vision Language Navigation
在这一点上,我们构建了用于训练的增强三元组:(环境、路径、指令)。我们的方法能够将任意两个场景混合成一个新的交叉连接场景。我们可以相应地生成大量新场景及其相应的路径和指令。
对于VLN任务,我们需要导出交叉连接的场景进行训练,包括视点、连接关系和顶点位置。增强的三元组将直接与原始训练集合并,即 T a u g = T ^ ∪ T \mathcal{T}_{aug} = \hat{\mathcal{T}}∪ \mathcal{T} Taug=T^∪T, 我们在训练中用 T a u g \mathcal{T}_{aug} Taug 代替 T \mathcal{T} T。交叉视点的不同方向上的观测特征来自不同的场景。
四,实验
4.1 实验设置
数据集和模拟器 我们基于Matterport3D模拟器[9]在房间到房间(R2R)[4]和R4R[27]上评估我们的代理。这是一个功能强大的导航模拟器。R4R建立在R2R的基础上,旨在为嵌入式导航代理提供更具挑战性的设置。
在场景中,代理将在环境连接图上的预定义视点之间跳跃。
评估指标 已经有许多公认的指标用于评估VLN中的模型:轨迹长度(TL),以米为单位的轨迹长度;导航误差(NE),距离目标点的误差(米);成功率(SR),代理成功到达目标3米以内的次数比例;以及由路径长度(SPL)加权的成功率[2]。在R4R中,CLS[27]、nDTW和SDTW[25]考虑了代理的步骤,并对导航路径中的中间错误敏感。
实施细节 我们使用EnvDrop[51]和VLN⟳Bert[23]作为评估我们方法的基线。
为了公平起见,我们使用了与原始方法相同的实验设置。在不改变超参数设置的基础上,增加了增强的三元组用于训练。
我们随机配对并混合训练集中的61个场景,最终获得116个交叉连接的场景、5916条路径和7022条指令
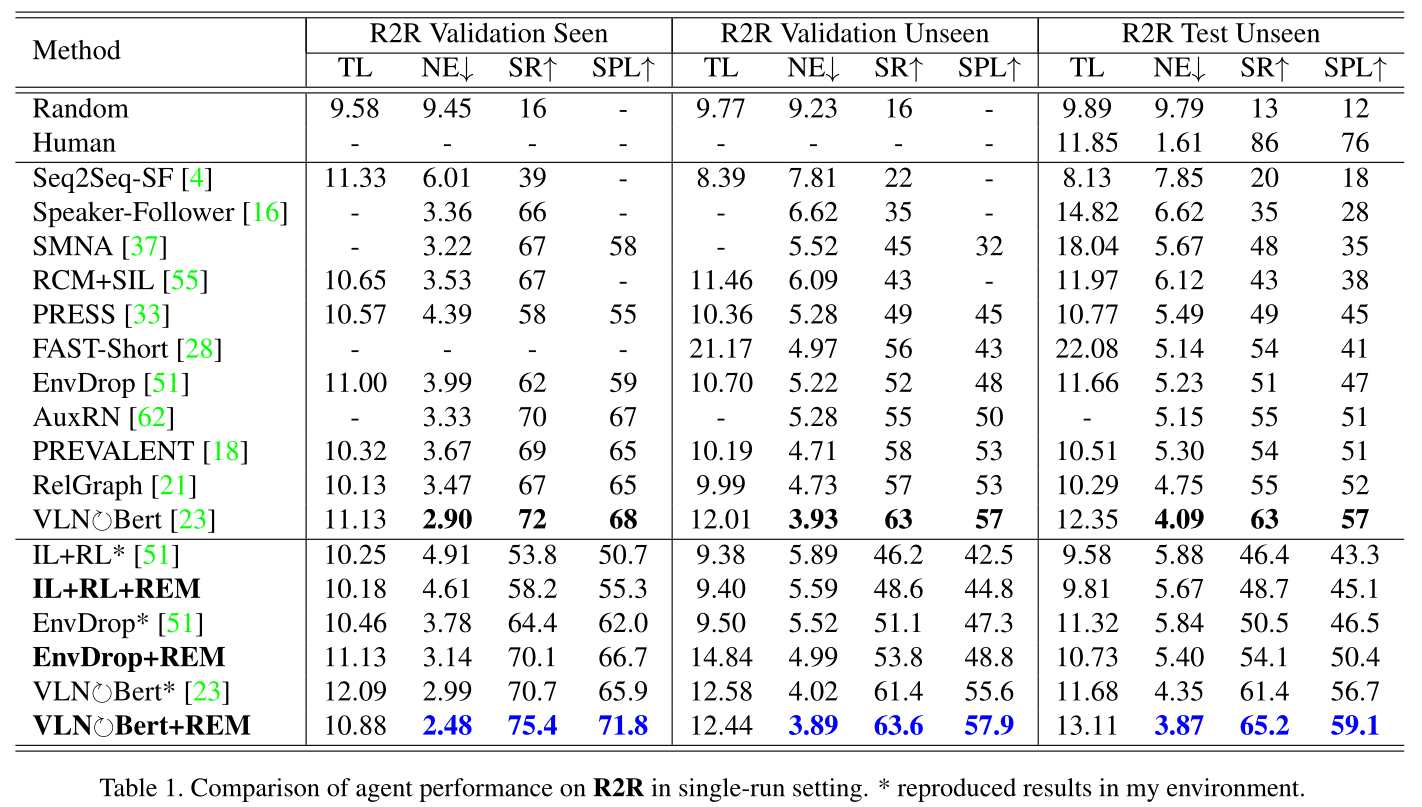
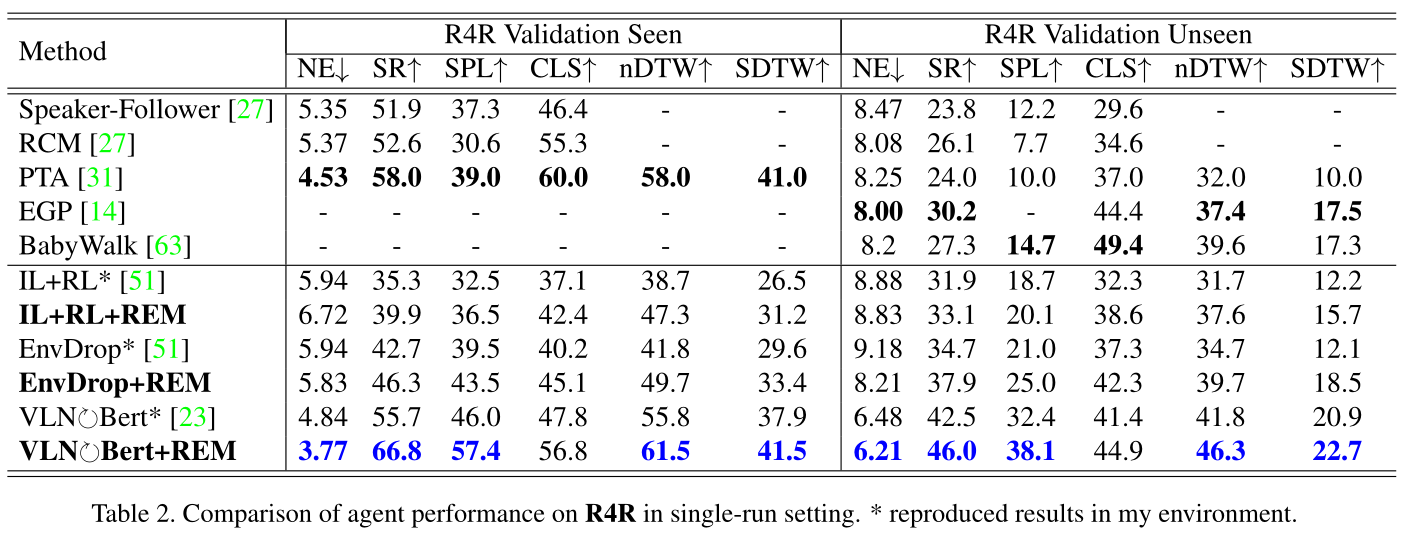
4.2 Results on VLN Standard Benchmark
4.3 方法分析

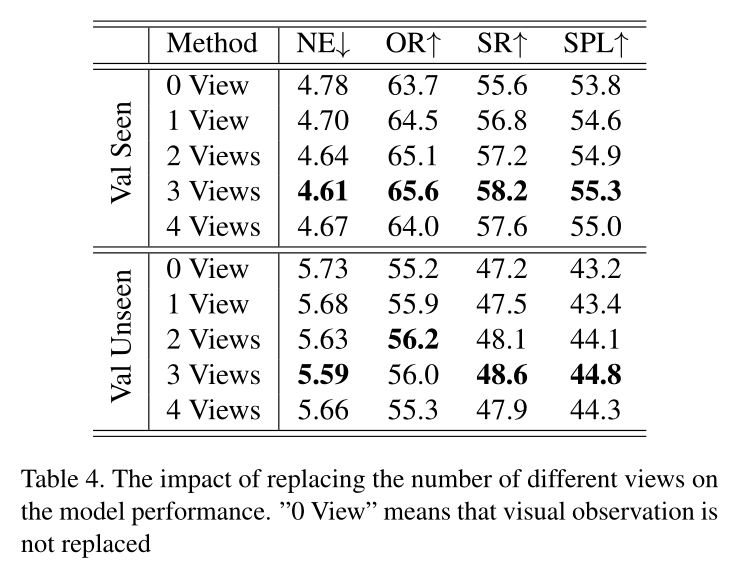
4.4 消融实验

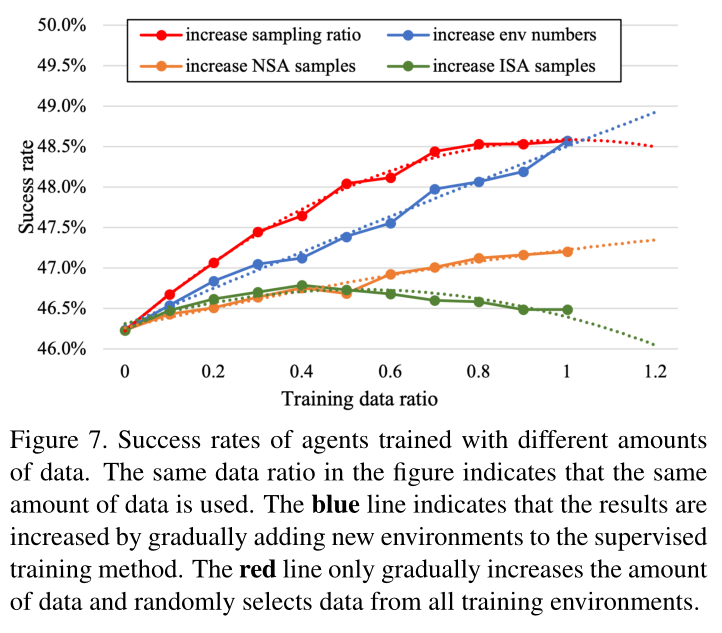
五,总结
在本文中,我们分析了影响泛化能力的因素,并提出了场景间数据增强可以更有效地减少泛化误差的假设。因此,我们提出了随机环境混合(REM)方法,该方法通过混合环境生成交叉连接的房屋场景作为增强数据。在基准数据集上的实验结果表明,REM可以显著减少可见和不可见环境之间的性能差距。
此外,REM显著提高了整体导航性能。最后,消融分析验证了我们关于减少泛化误差的假设
个人思考与看法
- 之前的VLN任务试图训练好的agent能够在即使没见过的环境中找到目标位置或物体。除非环境非常相似甚至一样。不然即使人类也无法找到,只有不断试错。
- 本文方法比较局限于R2R这样的导航任务,不适合其他更细致的任务。
- 本文实际上增广了数据集,没有提其他方法















 764
764











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









