







Motivation
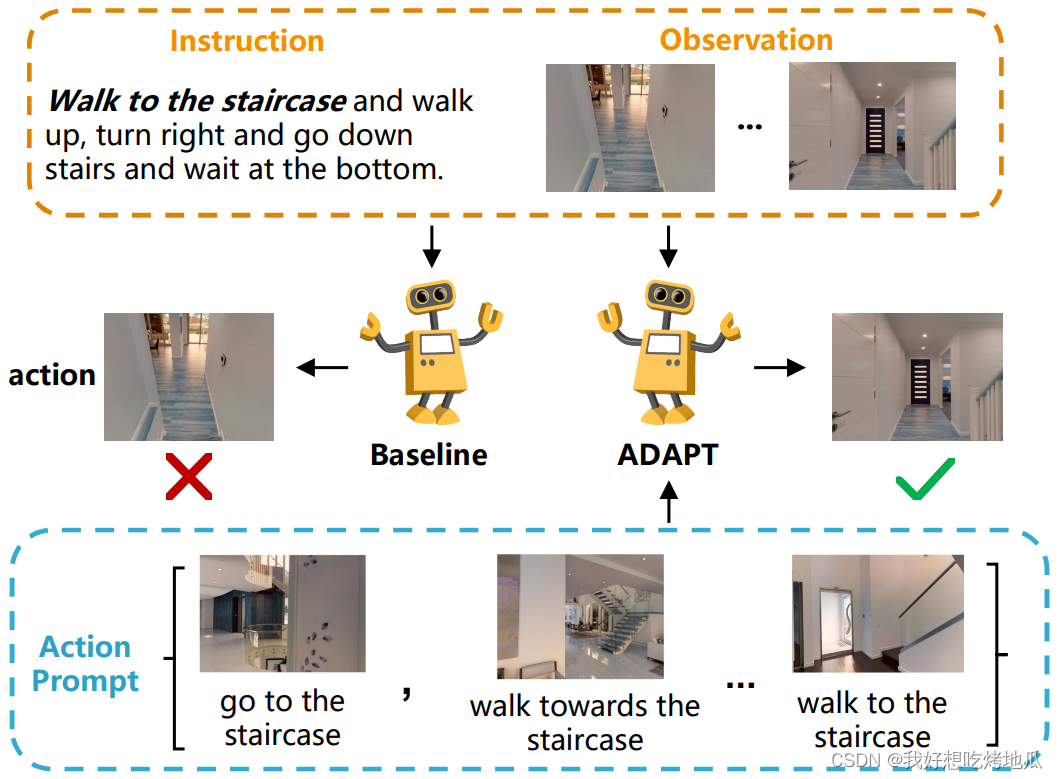
视觉语言导航 (VLN) 是一项具有挑战性的任务,它要求智能体执行动作级模态对齐,即在复杂的视觉环境中按顺序做出指令要求的动作。大多数现有 VLN 智能体直接学习指令路径数据,不能充分探索多模态输入中的行动级对齐知识。本文提出了模态对齐动作提示 (ADAPT),它为 VLN 智能体提供动作提示,使其能够明确学习动作级模态对齐以成功导航。
Prompt Learning 范式已经显示出巨大的潜力,通过简单地提供由人为设计或根据特定任务目标进行优化的提示,赋予预训练模型多种功能。受此启发,提出在 VLN 任务中引入提示,以提高预训练 VLN 智能体的动作级模态对齐能力。提出模式一致的操作提示 (ADAPT),其中为智能体提供明确的操作提示以做出操作决策。操作提示包含一对多模态子提示,其中图像子提示是指示突出视觉对象或位置的单视图观察,成对的文本子提示是与对象相关的操作短语,如 “去楼梯”。
Related Idea: 设计了模态对齐损失和顺序一致性损失,以实现对动作提示的有效学习。预训练 V-L 模型 (CLIP) 来保证动作提示的质量
Method
VLN Agent with Action Prompts
Action Prompts
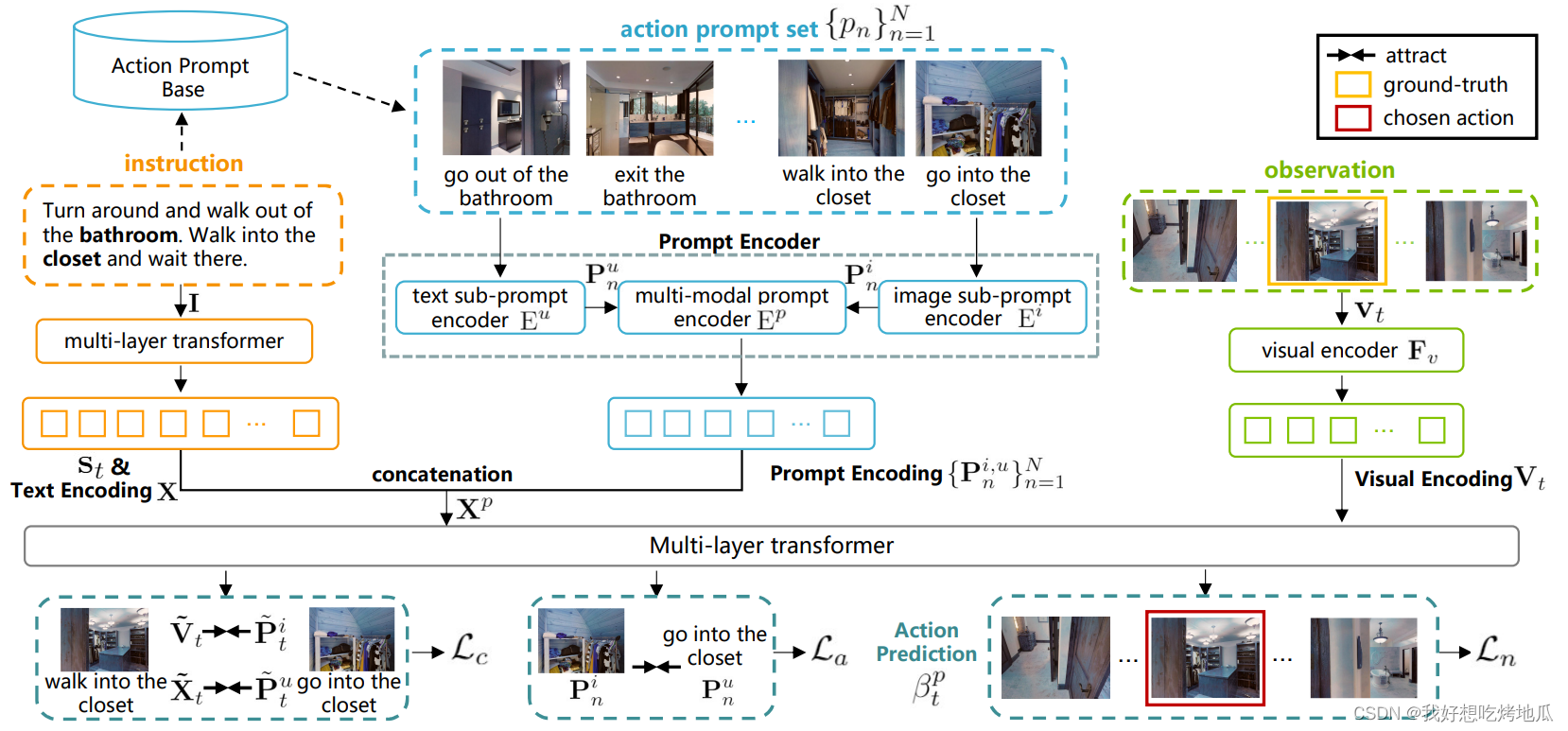
操作提示符是图像子提示符和文本子提示符的模态对齐对,其中前者是单视图观察,后者是操作短语。观察表明一个显著的视觉对象或位置。动作短语包含两个主要元素,即代表动作的单词 / 短语,如 “退出” 或 “走进”,以及对象 / 位置词,如 “椅子” 或 “卧室”。一个动作提示符不仅在两种模态中包含对齐的视觉对象或位置,而且还表明了与模态对齐的动作知识。例如,文本子提示 “走出卧室” 的配对图像子提示包含卧室的外观及其门,智能体可以通过它完成 “走出” 卧室的动作。通过在训练中明确地提供动作提示,智能体能够更好地探索跨模态的动作知识,这对于指导正确的动作决策是很重要的。

Action Decision with Action Prompts
在导航开始时,智能体从操作提示库中检索与指令相关的操作提示。具体地说,给定指令中与对象 / 位置相关的动作短语是根据获取文本子提示的策略派生的。然后计算提示库中每个对象 / 位置相关动作短语与文本子提示之间的句子相似度,检索指令相关动作提示集 { p n } n = 1 N \{p_n\}^N_{n=1} {pn}n=1N,其中 N N N 为该集合的大小。
提示编码器由两个单模态子提示编码器和一个多模态提示编码器组成。分别表示动作提示
p
n
p_n
pn / 图像子提示
p
n
i
p^i_n
pni / 文本子提示
p
n
u
p^u_n
pnu。
p
n
i
p^i_n
pni 和
p
n
u
p^u_n
pnu 首先通过单模态子提示编码器得到子提示特征
P
n
i
\textbf{P}^i_n
Pni 和
P
n
u
\textbf{P}^u_n
Pnu:
P
n
i
=
E
i
(
p
n
i
;
θ
i
)
\textbf{P}^i_n=\text{E}^i(p_n^i; \theta^i)
Pni=Ei(pni;θi)
P
n
i
=
E
u
(
p
n
u
;
θ
u
)
\textbf{P}^i_n=\text{E}^u(p_n^u; \theta^u)
Pni=Eu(pnu;θu)
编码后的特征输入多模态提示编码器来得到编码后的全提示:
P
n
i
,
u
=
E
p
(
Concat
(
P
n
i
,
P
n
u
)
;
θ
p
)
\textbf{P}^{i, u}_n=\text{E}^p(\text{Concat}(\textbf{P}^i_n, \textbf{P}^u_n); \theta^p)
Pni,u=Ep(Concat(Pni,Pnu);θp)
在 ADAPT 的设计中,编码器 E i ( ⋅ ) / E u ( ⋅ ) / E p ( ⋅ ) \text{E}^i(·) / \text{E}^u(·) / \text{E}^p(·) Ei(⋅)/Eu(⋅)/Ep(⋅) 由一个线性层组成,使用 Dropout 操作以减少过拟合。
Construction of the Action Prompt Base
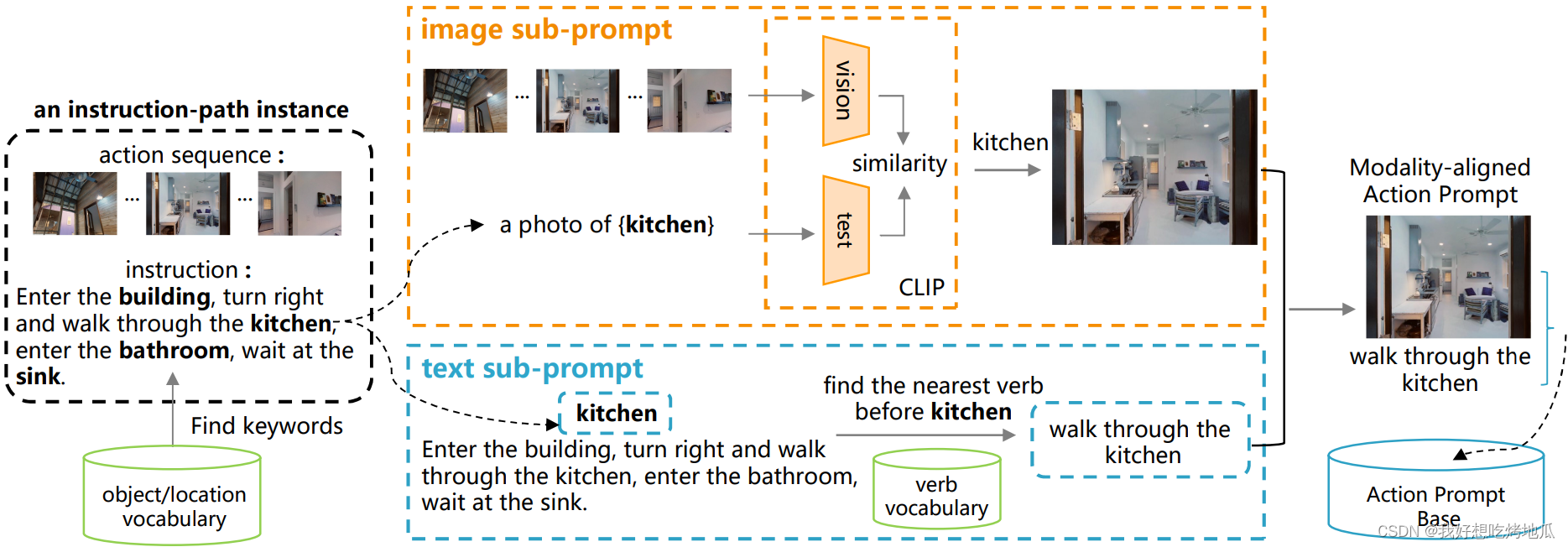
虽然通过对象识别很容易为图像分配对象类别标签,但将图像与动作短语关联起来并不简单。为了更好地将图像和动作短语对齐形成动作提示,设计了一种双分支方案来收集图像和文本子提示。
首先,对于训练数据集中的指令路径实例,使用预先构建的视觉对象 / 位置词汇表来查找指令中引用的视觉对象 / 位置。然后,对于每个视觉对象 / 位置,分别获得相关的图像和文本子提示。
Ground-truth 路径序列包含一组单视图图像,每个图像都表示在特定 Step 需要执行的操作。因此为在动作提示中派生图像子提示,只需要从 Ground-truth 路径序列中检索对象 / 位置相关的图像,该序列本身包含动作信息。没有使用现有的对象分类器或在一组固定的类类别上训练的检测器,而是使用 CLIP。为了适应 CLIP 的推理过程,将短语 “a photo of {CLASS}” 中的 {CLASS} 替换为类别标签为 c c c 的视觉对象 / 位置。
Training and Inference
Modality Alignment Loss
虽然操作提示符具有匹配的图像和文本子提示符,但它们可能不会在特征空间中对齐。为了解决这个问题,遵循 CLIP 中使用的对比学习范式,即强制成对的图像和文本特征相似,非成对的图像和文本特征相距遥远,使用 infoNCE 损失来鼓励每个操作提示中的图像和文本子提示的特征对齐:
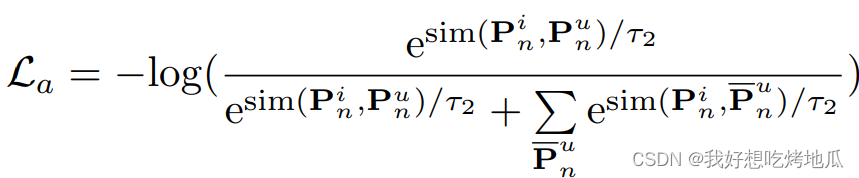
通过模态对齐损失,行动提示可以变得更具辨别性,从而指导行动级模态对齐的学习。















 1815
1815











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









