






写在前面:
由于要做学期总结,故写此篇文章,在总结的同时,将知识进行复习巩固。篇幅较长,预计分为六个章节。此章节为深度学习篇,详细如下:
1、二分类问题:
二分类就是输出 y只有 {0,1} 两个离散值(也有 {-1,1} 的情况)。我们以一个「图像识别」问题为例,判断图片是否是猫。识别是否是「猫」,这是一个典型的二分类问题——0代表「非猫(not cat)」,1代表「猫(cat)」。
其中逻辑回归是最常见的二分类算法

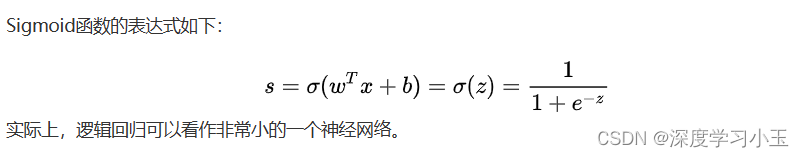
2、逻辑回归的损失函数

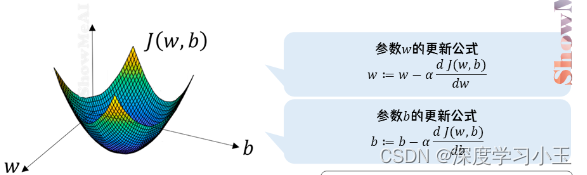
3、梯度下降算法
4、前向传播和反向传播
其中前向传播较为简单,反向传播其实就是求偏导的过程。详细略
5、完整的logistic回归流程
向量化:
6、广播的概念(很重要)
广播(Broadcasting)是一种机制,它允许不同形状的张量在进行算术运算时自动进行一些维度的扩展,使其形状相容。
import numpy as np
A = np.array([[1], [2], [3]])
B = np.array([[4, 5, 6, 7]])
# 广播
result = A + B
print(result)
# 输出:
# [[5 6 7 8]
# [6 7 8 9]
# [7 8 9 10]]
在深度学习中,广播机制经常用于张量的加法、减法、乘法等元素级别的操作,使得处理不同形状的数据更加方便。广播的概念是在 NumPy、PyTorch、TensorFlow等深度学习框架中都得到了支持。
7、激活函数
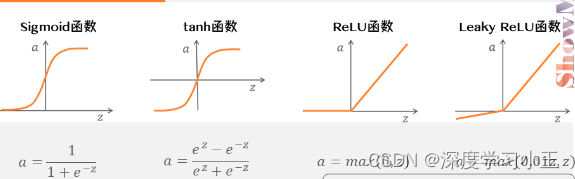
根据具体的情况选择激活函数,如果不清楚选择何种激活函数,推荐ReLu激活函数
8、为什么需要深度网络
例如人脸识别,训练得到的神经网络,每一层的作用有差别:
- 第一层所做的事就是从原始图片中提取出人脸的轮廓与边缘,即边缘检测。这样每个神经元得到的是一些边缘信息。
- 第二层所做的事情就是将前一层的边缘进行组合,组合成人脸一些局部特征,比如眼睛、鼻子、嘴巴等。
- 后续层次逐层把这些局部特征组合起来,融合成人脸的模样。
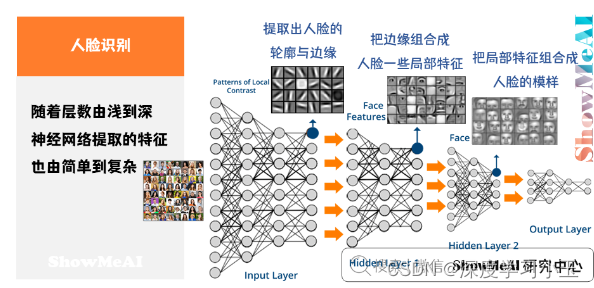
随着层数由浅到深,神经网络提取的特征也是从边缘到局部特征到整体,由简单到复杂。隐藏层越多,能够提取的特征就越丰富、越复杂,模型的准确率也可能会随之越高。
9、参数和超参数

其中超参数是需要自己去设置最优超参数,这是比较困难的,通常的做法是选择超参数一定范围内的值,分别代入神经网络进行训练,测试cost function随着迭代次数增加的变化,根据结果选择cost function最小时对应的超参数值。
10、正则化
高偏差对应着欠拟合,而方差对应着过拟合。解决方法为:
- 模型存在高偏差:扩大网络规模,如添加隐藏层或隐藏单元数目;寻找合适的网络架构,使用更大的NN结构;花费更长时间训练。
- 模型存在高方差:获取更多的数据;正则化 (Regularization) ;寻找更合适的网络结构。
- 不断尝试,直到找到低偏差、低方差的框架。

很有效的正则化方式叫做Dropout (随机失活) ,它是指在神经网络的隐藏层为每个神经元结点设置一个随机关闭的概率,保留下来的神经元形成一个结点较少、规模较小的网络用于训练。
反向随机失活:Inverted Dropout

11、梯度爆炸和梯度消失
-
梯度消失(Gradient Vanishing):
- 定义: 在反向传播过程中,梯度逐渐变小,最终趋近于零。
- 原因: 主要发生在深度网络中,当梯度通过多个层传递时,每一层都用激活函数进行非线性变换,导致梯度缩放。
- 影响: 导致底层的权重更新很小,使得底层网络参数几乎不会得到更新,导致网络无法学习到底层的特征。
-
梯度爆炸(Gradient Exploding):
- 定义: 在反向传播过程中,梯度逐渐变大,最终趋近于无穷大。
- 原因: 同样发生在深度网络中,梯度通过多个层传递时,每一层都用激活函数进行非线性变换,导致梯度放大。
- 影响: 导致底层的权重更新非常大,使得网络权重发生剧烈变化,可能导致数值溢出(超出计算机表示范围)或参数更新过于剧烈,影响网络稳定性。
解决方法:
- 权重初始化: 使用适当的权重初始化方法,如He初始化,有助于缓解梯度消失或梯度爆炸问题。
- 激活函数选择: 使用饱和度较小的激活函数,如ReLU,有助于减缓梯度消失问题。
- 批量归一化(Batch Normalization): 规范化输入,有助于防止梯度消失或梯度爆炸。
- 梯度裁剪(Gradient Clipping): 在反向传播过程中,对梯度进行裁剪,防止梯度爆炸。
- 使用更复杂的结构: 如残差连接(Residual Connections)等,有助于减缓梯度消失问题。
- 使用不同的优化器: 不同的优化器对于不同的问题可能有更好的表现,例如使用带有动量的优化器(如Adam)。
12、优化算法
在深度学习中,优化算法用于调整模型的参数以最小化(或最大化)损失函数。以下是一些常见的优化算法:
-
梯度下降法(Gradient Descent):
- 批量梯度下降法(Batch Gradient Descent): 使用整个训练集的梯度来更新参数。
- 随机梯度下降法(Stochastic Gradient Descent,SGD): 每次仅使用一个样本的梯度来更新参数,减少计算开销。
- 小批量梯度下降法(Mini-Batch Gradient Descent): 综合了批量梯度下降和随机梯度下降,每次更新使用一小批样本的梯度。
-
学习率调度:
- 动态学习率: 根据训练的进展动态调整学习率,例如学习率衰减或使用自适应学习率算法(如Adam)。
- 学习率衰减: 随着训练的进行,逐渐减小学习率,有助于更稳定的收敛。
-
动量优化算法:
- 动量梯度下降(Momentum): 引入动量项,模拟物体在梯度场中的运动,有助于加速收敛并减小震荡。
- Nesterov Accelerated Gradient(NAG): Momentum的一种改进,更准确地计算梯度。
-
自适应学习率算法:
- Adagrad: 根据每个参数的历史梯度调整学习率,适用于稀疏数据。
- RMSprop: Adagrad的改进版本,引入指数加权移动平均来减缓学习率的下降速度。
- Adam(Adaptive Moment Estimation): 结合了动量和RMSprop的优点,适用于各种问题。
-
二阶优化算法:
- 牛顿法(Newton's Method): 利用二阶导数信息调整学习率,但计算开销较大。
- 拟牛顿法(Quasi-Newton Methods): 通过近似牛顿法来减小计算开销,如BFGS、L-BFGS等。
-
正则化:
- L1正则化和L2正则化: 通过在损失函数中添加正则项,惩罚参数的大小,防止过拟合。
- 弹性网络(Elastic Net): 结合了L1和L2正则化,同时考虑了稀疏性和参数的大小。
-
批标准化(Batch Normalization):(重点,不懂可以搜寻资料了解)
- 通过规范化输入: 有助于加速收敛,提高模型的稳定性,降低对初始权重的敏感性。















 567
567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









