










 文章介绍了2021年TKDE上发表的CAE-M模型,一种针对多源时序数据的深度异常检测方法,通过捕捉时空关联性和复杂性,显著提高了异常检测的精度。模型结合深度卷积自动编码器和预测网络,有效处理不平衡数据和噪声,表现出色于现有技术。
文章介绍了2021年TKDE上发表的CAE-M模型,一种针对多源时序数据的深度异常检测方法,通过捕捉时空关联性和复杂性,显著提高了异常检测的精度。模型结合深度卷积自动编码器和预测网络,有效处理不平衡数据和噪声,表现出色于现有技术。
2021发表于TKDE定会的异常检测模型(CAE-M: 一个基于多变量时序数据的深度异常检测模型)
本文介绍一篇被数据挖掘国际顶级期刊TKDE 2021接收的regular paper,第一作者为中科院计算所张宇欣博士,其他作者来自中科院计算所、微软亚洲研究院等单位。文章针对多源时序数据的时空关联性,提出一种深度时空网络异常检测方法(Deep Convolutional Autoencoding Memory network,CAE-M),解决特征分布的多样性和复杂性,捕捉正常数据的通用表征模式,相比于state-of-the-art的异常检测方法提高了至少 6% 的精度(F1-score)。

背景介绍
异常检测一直是机器学习的核心研究领域之一,其广泛的应用包括网络入侵检测[1]、智慧医疗[2]、传感器网络[3]、以及视频异常检测[4] 等。异常检测似乎是一种简单的二类分类,区分正常和异常数据,然而训练数据往往出现高度不平衡的现象,原因是与正常实例相比,数据集中的异常通常非常罕见。标准分类器试图使分类的准确性最大化,因此会出现模型将少数数据的类别作为噪声而忽略。且用户人工标记每个训练数据往往是很困难的,尤其是异常数据。与有监督学习方法相比,使用半监督和无监督学习方法进行异常检测更有研究价值,因为它们可以更好地处理不平衡和未标记的数据。
目前,多传感器技术已广泛应用于医疗健康(HC)、行为识别(HAR)和工业控制系统(ICS)等领域,这些传感器可以产生大量的多源时序数据。基于多传感器时序数据的异常检测面临的关键挑战是如何通过多传感器数据的时空关联性来发现通用表征模式。此外,噪声数据通常与训练数据混合在一起,这可能会误导模型,使其难以区分正常、异常和噪声数据。在以往的研究中很少能够同时解决这两个挑战。为解决此问题,本文提出CAE-M方法,该方法由两个主要子网络组成:表征网络和预测网络。具体来说,我们将深度卷积自动编码器( Deep Convolutional Autoencoder,DCAE)作特征提取模块,将基于注意力的双向长短期记忆模型(Attention-based Bidirectional LSTM)[5]和自回归模型(Autoregressive,AR)用作预测模块。通过同时最小化重构误差和预测误差,可以共同优化 CAE-M模型。同时,使用了最大均值差异(Maximum Mean Discrepancy,MMD)[6]进行特征空间分布匹配,其目的是减小原有的复杂性分布特征与目标分布的均值之间的距离,使得特征的分布与目标分布(如高斯分布、线性分布)有一定的相似度,降低模型训练的难度,以此来捕捉正常数据的通用表征模式。在训练阶段,使用正常数据对 CAE-M模型进行端到端的训练,在测试(推断)阶段, CAE-M 模型为每个测试数据计算目标函数的误差值,通过误差值的大小作为判断正常和异常数据类别的依据。
我们的方法:CAE-M
我们方法的主要贡献体现在三个方面:
1、我们提出的深度时空网络旨在通过同时执行重构和预测分析来表征复杂的时空模式。在表征网络中,我们构建了深度卷积自动编码器,从多源时序信号中提取低维空间特征。在预测网络中,我们构建了基于注意力的双向长短期记忆模型,以捕获复杂的时间依赖性。此外,我们还引入了自回归线性模型,用于提高模型鲁棒性以适应不同的时序信号以及应用场景。
2、为了减少噪声的影响,我们在深度卷积自动编码器上增加了MMD惩罚项,从分布的角度对特征空间进行分布适配优化。MMD的添加是为了促进低维特征空间的分布近似于目标分布如高斯分布。实验表明,该方法对提高模型精度是有效的。
3、我们在三个多源时序数据集上进行了实验分析,结果表明 CAE-M模型具有优于最新技术的性能。为了进一步验证我们提出的模型的效果,我们还完成了细粒度分析、留一法验证、消融实验、噪声鲁棒性分析、参数敏感性分析等实验。
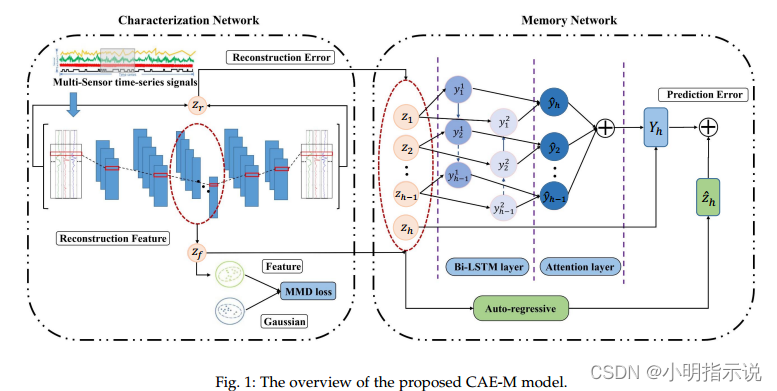
表征网络
构建带有MMD惩罚项的卷积自动编码器,该模块由编码器和解码器组成,旨在计算低维表达:

这里,Encoder表示编码器,由卷积层和池化层组成,Decoder表示解码器,由卷积层和反池化层组成, x‘’表示与x有着相同结构的重构值。 原始输入数据x与重构 x’之间的残差称为重构误差
。自动编码器中通常使用的误差是均方误差(Mean-Square Error,MSE),用于测量x与重构x’之间的接近程度,如下式所述:

为了减少噪声的影响,我们从分布的角度对特征空间进行分布适配,基于卷积自动编码器得到的特征计算最大均值差异值,通过近似低维特征的分布与目标分布,使得正常数据在低维特征空间中具有一致性分布。
预测网络
为了同时捕获多源时序数据的时间依赖性和空间依赖性,我们提出的模型通过同时进行重构分析和预测分析来表征数据复杂的时空模式。考虑到数据中时间分量的重要性,我们提出了非线性预测和线性预测模型,其目的是利用特征空间中的过去信息来预测当前时刻的特征表达。我们将表征网络在h时间步长内生成的低维特征包括重构误差和学习到的低维表示作为预测网络的输入,其表示形式为:
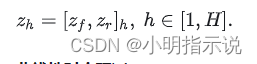
非线性时序预测
我们采用了具有注意力机制的双向长短期记忆网络(Bi-directional Long Short-Term Memory,Bi-LSTM),它可以在计算隐藏状态时考虑全局和局部的时间信息。为了更好地处理时序数据,本研究还加入了注意力机制,将生成的权重向量与每一个时间步的特征做乘法,使得模型能够更加关注重要特征。
线性时序预测
自回归模型(Autoregressive,AR)是一种线性回归方法,在预测短时信息上也能表现出良好的效果。因此,我们将AR模型与非线性预测网络并行处理,共同对时间序列特征进行有效预测。在输出层中,通过计算预测网络的输出与真实值Zh之间的残差来获得预测误差。最终的预测误差包含了非线性预测模型和线性预测模型的输出,表示为:


联合优化
目标函数包括表征网络的重构误差、分布适配的MMD误差、以及预测网络的预测误差,如下式:
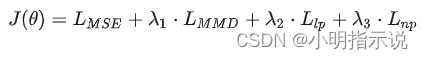

模型训练与推理

实验结果
我们采用了两个大型的公开数据集和一个私有数据集:PAMAP2、CAP和精神疲劳数据集(Mental Fatigue Dataset,MFD)。这些数据集利用多源时序数据分别对用户进行行为识别、睡眠状态检测和精神疲劳检测,它们是评估用户行为异常检测算法的理想测试平台。
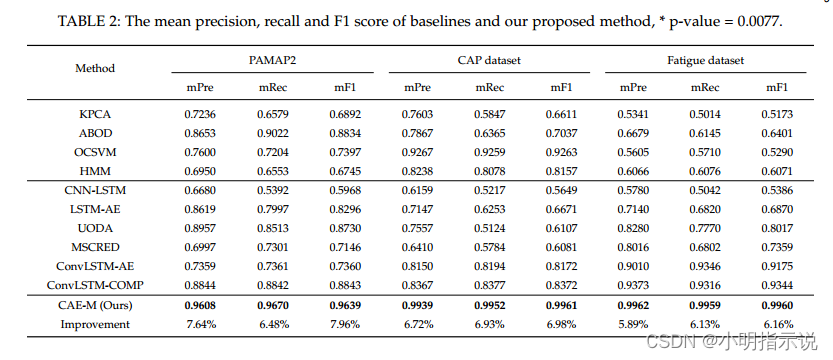
首先,我们看一下模型在不同数据集上的效果,评价指标为召回率、精确率、F1分数,可以看到CAE-M在所有的数据及上都取得了最好的表现。
然后,为了验证模型的有效性,我们将从分布适配对比分析、细粒度分析、留一法验证、消融实验、噪声鲁棒性分析、参数敏感性分析、收敛性分析这几个方面展开研究。
分布适配对比分析(这部分论文中没有,为了更加明确MMD的效果后面补充的):
1)特征空间的分布适配需要用到度量准则来衡量两个分布之间(特征分布和目标分布)的差异,我们对比了皮尔逊相关系数(Pearson Correlation Coefficient,PCC)、互信息(Mutual Information,MI)、KL散度(Kullback–Leibler Divergence,KLD)和最大均值差异(Maximum Mean Discrepancy,MMD)这四种度量手段对模型的结果影响,目标分布使用的是高斯分布,如图2a所示,使用MMD进行分布距离计算得到了最好的实验结果,在F1分数上超过了次优的PCC度量2.34%。
2)特征空间的分布适配也会受到目标分布的影响,即MMD核函数的选择,因此,我们验证了不同核函数的实验结果。我们选择了高斯核函数(Gaussian Kernel)、线性核函数(Linear Kernel)、拉普拉斯核函数(Laplacian Kernel)、幂核(Power Kernel)、以及二次有理核(Rational Quadratic Kernel),如图2b所示,高斯核函数对结果有着最大的提升。
留一法验证分析:我们使用“留一法”(LOSO)来度量模型在不同用户之间的鲁棒性,实际上,当训练和测试数据集包含同一名受试者时,该训练模型可能会出现向该受试者偏移的现象,LOSO验证法能够有效避免该问题。数据集中包含8个受试者,如图所示,实验表明深度学习的方法比传统方法在不同用户之间具有更好的检测精度,CAE-M方法对于不同用户都表现出较稳定的检测精度,平均F1分数为 86.16% 。
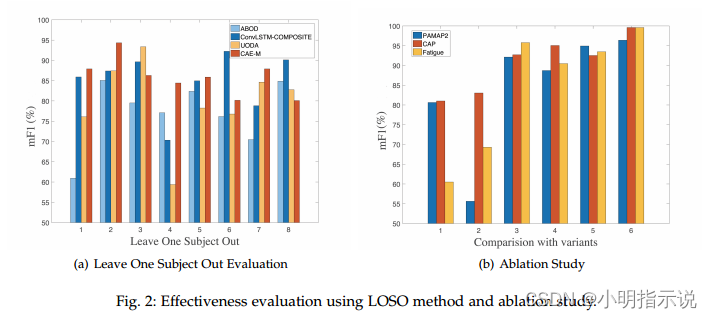
消融分析:我们提出的CAE-DA方法由多个模块组成,包括CAE、MMD、Attention、Bi-LSTM和AR模块。为了证明每个模块的有效性,我们进行了消融实验验证,如图3b所示,实验结果表明,当去除不同模块时,模型在F1分数上都有一定的精度下降,我们可以观察到去除预测或重构误差的CAE-M模型相对而言会达到较低的F1分数,这表明我们的模型针对多源时序数据进行异常检测是有效且必要的。与CAE-M模型相比,去除AR模块会导致大多数数据集的性能显著下降,这表明了AR的关键作用。此外,去除注意力机制和MMD模块也会导致模型性能会呈下降趋势。
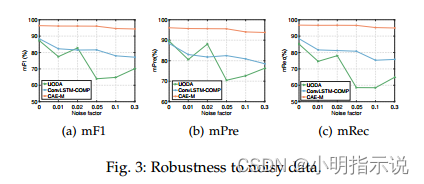
噪声鲁棒性分析:在真实场景中,传感器数据采集易于被噪声污染,因此有效提升模型对噪声的鲁棒性极为重要,我们以1%-30%的比例随机加入高斯噪声,从对比结果可以看出,随着噪声的增加,所有方法的表现都有所下降,对于CAE-M,精度并没有明显下降,证明了我们的方法对于噪声具有一定的鲁棒性。
总结
本文提出了一种针对多源时序数据的深度时空网络异常检测方法(CAE-M),CAE-M利用多源时序数据中的时空依赖性提取特征并进行特征分布适配,对正常数据的通用表征模式进行建模。具体方法是我们首先构建了具有最大均值差异(Maximum Mean Discrepancy, MMD)惩罚项的深度卷积自动编码器,该模块用于表征多源数据的空间依赖性并进行特征分布适配。然后,我们构建了一个由线性(自回归模型)和非线性预测(带有注意力机制的双向长短期记忆模型)组成的预测网络,以捕获时间序列中的时间依赖性。最后, CAE-M共同优化了这两个子网络。我们将所提出的方法与行为识别(Human Activity Recognition, HAR)和健康医疗(Health Care, HC)数据集上的几种最新异常检测方法进行比较,实验结果表明,我们提出的模型优于现有方法。

















 2006
2006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









