







 本文介绍正则表达式的基础知识,包括特殊字符的作用及其在grep、sed和awk等工具中的应用。通过实例演示了如何使用这些工具进行文本搜索、替换及格式化。
本文介绍正则表达式的基础知识,包括特殊字符的作用及其在grep、sed和awk等工具中的应用。通过实例演示了如何使用这些工具进行文本搜索、替换及格式化。
前言
-
正则表达式 (Regular Expression, RE, 或称为常规表达式)是通过一些特殊字符的排列,用以“搜寻/取代/删除”一列或多列文字字串,简单的说,正则表达式就是用在字串的处理上面的一项 “表示式”。
-
正则表达式并不是一个工具程序,而是一个字串处理的标准依据。 如果想要以正则表达式的方式处理字串,就得要使用支持正则表达式的工具程序才行,这类的工具程序很多,例如 vi, grep,sed, awk 等等。
-
注意:正则表达式与万用字符是完全不一样的东西! 万用字符 (wildcard) 代表的是 bash 操作接口的一个功能,但正则表达式则是一种字串处理的表示方式。不要试图将两者结合起来记忆或者学习,这样只会让你混乱。
一、基础正则表达式
- 正则表达式需要支持工具程序来辅助。所以,我们这里就先介绍一个最简单的字串撷取功能的工具程序,那就是 grep 指令。
1. grep指令介绍
- grep 用来分析一行信息, 若当中有我们所需要的信息,就将该行拿出来。简单的语法如下:
[dmtsai@study ~]$ grep [选项] [--color=auto] '搜寻字串' filename
选项与参数:
-a :将 binary 文件以 text 文件的方式搜寻数据
-c :计算找到 '搜寻字串' 的次数
-i :忽略大小写的不同,所有大小写视为相同
-n :顺便输出行号
-v :反向选择,亦即显示出没有 '搜寻字串' 内容的那一行!
--color=auto :可以将找到的关键字部分加上颜色的显示喔!
范例一:将 last 当中,有出现 root 的那一行就取出来;
[dmtsai@study ~]$ last | grep 'root'
范例二:与范例一相反,只要没有 root 的就取出!
[dmtsai@study ~]$ last | grep -v 'root'
范例三:在 last 的输出讯息中,只要有 root 就取出,并且仅取第一栏
[dmtsai@study ~]$ last | grep 'root' | cut -d ' ' -f1
# 在取出 root 之后,利用上个指令 cut 的处理,就能够仅取得第一栏啰!
范例四:取出 /etc/man_db.conf 内含 MANPATH 的那几行
[dmtsai@study ~]$ grep --color=auto 'MANPATH' /etc/man_db.conf
....(前面省略)....
MANPATH_MAP /usr/games /usr/share/man
MANPATH_MAP /opt/bin /opt/man
MANPATH_MAP /opt/sbin /opt/man
# 神奇的是,如果加上 --color=auto 的选项,找到的关键字部分会用特殊颜色显示喔!
- 特殊符号意义:(可以背一下)

- 上表中的 [:alnum:], [:alpha:], [:upper:], [:lower:], [:digit:] 这几个符号一定要知道代表什么意思,因为他要比 a-z 或 A-Z 的用途要广。
2. grep 的一些进阶选项
- 前面的只是grep 的基础用法,现在我们来看一下进阶版grep 吧!
[dmtsai@study ~]$ grep [-A] [-B] [--color=auto] '搜寻字串' filename
选项与参数:
-A :后面可加数字,为 after 的意思,除了列出该行外,后续的 n 行也列出来;
-B :后面可加数字,为 befer 的意思,除了列出该行外,前面的 n 行也列出来;
--color=auto 可将正确的那个撷取数据列出颜色。
范例一:用 dmesg 列出核心讯息,再以 grep 找出内含 'qxl' 字符的所有行。
[dmtsai@study ~]$ dmesg | grep 'qxl'
[ 0.522749] [drm] qxl: 16M of VRAM memory size
[ 0.522750] [drm] qxl: 63M of IO pages memory ready (VRAM domain)
[ 0.522750] [drm] qxl: 32M of Surface memory size
[ 0.650714] fbcon: qxldrmfb (fb0) is primary device
[ 0.668487] qxl 0000:00:02.0: fb0: qxldrmfb frame buffer device
# dmesg 可列出核心产生的信息!包括硬件侦测的流程也会显示出来。
# 本机使用的显卡是 QXL 这个虚拟卡,通过 grep 来 过滤 qxl 的相关信息,可发现如上信息。
范例二:承上题,要将捉到的关键字显色,且加上行号来表示:
[dmtsai@study ~]$ dmesg | grep -n --color=auto 'qxl'
515:[ 0.522749] [drm] qxl: 16M of VRAM memory size
516:[ 0.522750] [drm] qxl: 63M of IO pages memory ready (VRAM domain)
517:[ 0.522750] [drm] qxl: 32M of Surface memory size
529:[ 0.650714] fbcon: qxldrmfb (fb0) is primary device
539:[ 0.668487] qxl 0000:00:02.0: fb0: qxldrmfb frame buffer device
# 除了 qxl 会有特殊颜色来表示之外,最前面还有行号喔!其实颜色显示已经是默认在 alias 当中了!
范例三:承上题,在关键字所在行的前两行与后三行也一起捉出来显示
[dmtsai@study ~]$ dmesg | grep -n -A3 -B2 --color=auto 'qxl'
# 你会发现关键字之前与之后的数行也被显示出来!这样可以让你将关键字前后数据捉出来进行分析了。
- grep 是一个很常见也很常用的指令,他最重要的功能就是进行字串数据的比对,然后将符合使用者需求的字串行打印出来。
- 需要说明的是 ,“grep 在数据中查寻一个字串时,是以 “整行” 为 单位来进行数据的撷取的。” 也就是说,假如一个文件内有 10 行,其中有两行具有你所要搜寻的字串,则只将那两行显示在屏幕上,其他行不显示。
- 在 CentOS 7 当中,默认已经将 --color=auto 加入在 alias 当中了!使用者就可以直接使用有关键字显色的 grep指令了,无需再加 --color=auto这个参数。
3. 基础正则表达式练习
- 接下来将是实际练习,先说明一下,下面的练习大前提是:grep 已经使用 alias 设置成为“ grep --color=auto ”,也就是说不用在命令行加入 --color=auto 这个参数了。
- 本章的练习文件如下,你可以直接复制然后在你的 Linux中以 vim 储存成 regular_express.txt 这个文件:
"Open Source" is a good mechanism to develop programs!
apple is my favorite food!
Football game is not use feet only!
this dress doesn\'t fit me!
However, this dress is about $ 3183 dollars.^M
GNU is free air not free beer.^M
Her hair is very beauty.^M
I can\'t finish the test.^M
Oh! The soup taste good.^M
motorcycle is cheap than car!
This window is clear!
the symbol '*' is represented as start!
Oh! My god!
The gd software is a library for drafting programs.^M
You are the best is mean you are the no. 1!
The world <Happy> is the same with "glad"!
I like dog!
google is the best tools for search keyword!
goooooogle yes!
go! go! Let's go!
# I am VBird
- 注意:这文件共有 22 行,最后一行为空白行!
3.1 例题一:搜寻特定字串
- 假设我们要从刚刚的文件当中取得 the 这个特定字串,最简单的方式就是这样:
[dmtsai@study ~]$ grep -n 'the' regular_express.txt
8:I can\'t finish the test.
12:the symbol '*' is represented as start.
15:You are the best is mean you are the no. 1.
16:The world <Happy> is the same with "glad".
18:google is the best tools for search keyword.
- 那如果想要“反向选择”呢?也就是说,当该行没有 ‘the’ 这个字串时就显示在屏幕上,那就直接使用:
[dmtsai@study ~]$ grep -vn 'the' regular_express.txt
- 你会发现,屏幕上出现的行列为除了 8,12,15,16,18 五行之外的其他行列!
- 接下来,如果你 想要取得不论大小写的 the 这个字串,则:
[dmtsai@study ~]$ grep -in 'the' regular_express.txt
8:I can\'t finish the test.
9:Oh! The soup taste good.
12:the symbol '*' is represented as start.
14:The gd software is a library for drafting programs.
15:You are the best is mean you are the no. 1.
16:The world <Happy> is the same with "glad".
18:google is the best tools for search keyword.
- 除了多两行 (9, 14行) 之外,第 16 行也多了一个 The 的关键字被撷取到。
3.2 例题二:利用中括号 [] 来搜寻集合字符
- 如果我想要搜寻 test 或 taste 这两个单字时,可以发现到,其实它们有共同的 ‘t?st’ 存在,这个时候,可以这样来搜寻:
[dmtsai@study ~]$ grep -n 't[ae]st' regular_express.txt
8:I can't finish the test.
9:Oh! The soup taste good.
- 其实 [] 里面不论有几个字符,他都仅代表其中的某“一个”字符, 所以,上面的例子说明 了,我需要的字串是 “tast” 或者 “test”这两个字串而已。
- 如果想要搜寻到有 oo 的字符时,则使用:
[dmtsai@study ~]$ grep -n 'oo' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food. 3:Football game is not use feet only.
9:Oh! The soup taste good.
18:google is the best tools for search keyword. 19:goooooogle yes!
- 如果我不想要 oo 前面有 g 的话呢?此时,可以利用在集合字符 [] 的反向选择来达成:
- 集合字符的反向选择 :当 (^) 在 [] 内时,代表的意义是 “反向选择”的意思。 例如,我不要g,则为 [ ^g ]
[dmtsai@study ~]$ grep -n '[^g]oo' regular_express.txt
2:apple is my favorite food.
3:Football game is not use feet only.
18:google is the best tools for search keyword.
19:goooooogle yes!
- 意思就是说,我需要的是 oo ,但是 oo 前面不能是 g 。仔细比较上面两个输出,会发现,第 1,9 行不见了,是因为 oo 前面出现了 g 所致。第 2,3 行没有疑问,因为 foo 与 Foo 均可被接受。但是第 18 行明明有 google 的 goo 却还会出现,是因为该行后面出现了 tool 的 too ,所以该行也被列出来。 也就是说, 18 行里面虽然出现了我们所不要的项目 (goo) 但是由于有需要的项目 (too) , 因此,是符合字串搜寻的。 至于第 19 行,同样的,因为 goooooogle 里面的 oo 前面可能是 o ,例如: go(ooo)oogle ,所以,这一行也符合需求。
- 再来,假设我 oo 前面不想要有小写字符,可以这样写:
grep -n ‘[ ^abcdefghijklmnopqrstuvwxyz]oo’ regular_express.txt
但是这样不怎么方便,由于小写字符的 ASCII 上编码的顺序是连续的 , 因此,我们可以将之简化为下面这样:
[dmtsai@study ~]$ grep -n '[^a-z]oo' regular_express.txt
3:Football game is not use feet only.
- 也就是说,当我们在一组集合字符中,如果该字符组是连续的,例如大写英文/小写英文/数字 等等, 就可以使用[a-z], [A-Z], [0-9]等方式来书写。 那么如果我们的要求字串是数字或英文呢?那就全部写在一起,变成:[a-zA-Z0-9]。
- 例如,我们要取得有数字的那一行, 就这样:
[dmtsai@study ~]$ grep -n '[0-9]' regular_express.txt
5:However, this dress is about $ 3183 dollars.
15:You are the best is mean you are the no. 1.
- 还记得我们上面说的特殊字符吗?我们也可以使用它们来获取同上面一样的结果,如下:
[dmtsai@study ~]$ grep -n '[^[:lower:]]oo' regular_express.txt
# 那个 [:lower:] 代表的就是 a-z 的意思!请参考前两小节的说明表格
[dmtsai@study ~]$ grep -n '[[:digit:]]' regular_express.txt
- 我们知道 [:lower:] 就是 a-z 的意思,那 么 [a-z] 就是 [[:lower:]],注意有双层的 [] 括号!
3.3 例题三:行首与行尾字符 ^ ,$
- 我们在例题一当中,可以查询到一行字串里面有 the 的,那如果我想要让 the 只在行首出现呢? 这个时候就得要使用定位字符(^, $)了。我们可以这样做:
[dmtsai@study ~]$ grep -n '^the' regular_express.txt
12:the symbol '*' is represented as start.
- 此时,就只剩下第 12 行,因为只有第 12 行的行首是 the 开头。
- 如果我想要开头是小写字符的那一行就列出呢?可以这样:
[dmtsai@study ~]$ grep -n '^[a-z]' regular_express.txt
2:apple is my favorite food.
4:this dress doesn\'t fit me.
10:motorcycle is cheap than car.
12:the symbol '*' is represented as start.
18:google is the best tools for search keyword.
19:goooooogle yes!
20:go! go! Let's go
- 你可以发现我们可以捉到第一个字符都不是大写的。上面的指令也可以用如下的方式来取代:
[dmtsai@study ~]$ grep -n '^[[:lower:]]' regular_express.txt
- 那如果我不想要开头是英文字母,则可以是这样:
[dmtsai@study ~]$ grep -n '^[^a-zA-Z]' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
21:# I am VBird
# 此外,指令也可以是,效果是一样的:
grep -n '^[^[:alpha:]]' regular_express.txt
- 注意: ^ 符号,在字符集合符号(括号[])之内与之外是不同的! 在 [] 内代表“反向选择”,在 [] 之外则代表定位在行首的意义。要区分清楚。
- 如果我想要找出来,行尾结束为小数点 (.) 的那一行,该如何处理:
[dmtsai@study ~]$ grep -n '\.$' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food. 3:Football game is not use feet only.
4:this dress doesn\'t fit me. 10:motorcycle is cheap than car.
11:This window is clear.
12:the symbol '*' is represented as start.
15:You are the best is mean you are the no. 1.
16:The world <Happy> is the same with "glad".
17:I like dog.
18:google is the best tools for search keyword.
20:go! go! Let's go.
- 特别注意到,因为小数点具有其他意义(下面会介绍),所以必须要使用转义字符(\)来加以解除其特殊意义。
- 你或许会觉得奇怪,但是第 5~9 行最后面也是以(.)结尾,为什么没有打印出来? 这里就牵涉到 Windows 平台的软件对于断行字符的判断问题了。我们使用 cat -A 指令将第5~10行拿出来看, 你会发现:
[dmtsai@study ~]$ cat -An regular_express.txt | head -n 10 | tail -n 6
5 However, this dress is about $ 3183 dollars.^M$
6 GNU is free air not free beer.^M$
7 Her hair is very beauty.^M$
8 I can't finish the test.^M$
9 Oh! The soup taste good.^M$
10 motorcycle is cheap than car.$
- 我们可以发现在 5 ~ 9 行的结尾, Windows 平台的断行字符是 (^M$ ) ,而正常的 Linux 平台应该仅有第 10 行结尾显示的那样 ($) 。所以,那个 (.)自然就不是紧接在 $ 之前了。所以也就显示不到 5~9 行了。
- 如果我想要找出来,哪一行 是“空白行”, 也就是说,该行并没有输入任何数据,该如何搜寻?如下:
[dmtsai@study ~]$ grep -n '^$' regular_express.txt
22:
- 因为空白行只有行首跟行尾 (^$),所以,这样就可以找出空白行了。
- 假设你已经知道在一个程序脚本 (shell script) 或者是配置文件当中,空白行与开头为 # 的那一行是注解。因此,如果你要将数据列出给别人参考时, 可以将这些数据省略掉,那么你可以怎么做呢?我们以 /etc/rsyslog.conf 这个文件来作范例,你可以自行参考一下输出的结果:
[dmtsai@study ~]$ cat -n /etc/rsyslog.conf
# 在 CentOS 7 中,结果可以发现有 91 行的输出,很多是空白行与 # 开头的注解行
[dmtsai@study ~]$ grep -v '^$' /etc/rsyslog.conf | grep -v '^#'
# 将空白行与 # 开头的注解行省略掉;
# 结果仅有 14 行,其中第一个“ -v '^$' ”代表 “不要空白行”,
# 第二个“ -v '^#' ”代表“不要开头是 # 的那行”。
- 你可能也会问,那为何不是出现 # 的符号的那行就直接舍弃呢?因为某些注解是和数据写在同一行的, 如果你只是抓到 (#)就去除,那就会将某些结果也同时移除了。
3.4 例题四:任意一个字符 (.) 与重复字符 (*)
- . (小数点):代表 “一定有一个任意字符”的意思。
- *(星星号):代表 “重复前一个字符,0 到无穷多次”的意思,为组合形态。
- 注意一定要和万用字符区分!
- 假设我需要找出 ‘g??d’ 的字串,共有四个字符, 起头是 g 而结束是 d ,我可以这样做:
[dmtsai@study ~]$ grep -n 'g..d' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
9:Oh! The soup taste good.
16:The world <Happy> is the same with "glad".
- 因为强调 g 与 d 之间一定要存在两个字符,因此,第 13 行的 god 与第 14 行的 gd 就不会被列出来了。
- 如果我想要列出有 oo, ooo, oooo 等等的数据, 也就是说,至少要有两个以上连续(含 o) 字符,该如何是好?是 o 还是 oo 还是 ooo 呢?如下:*
[dmtsai@study ~]$ grep -n 'ooo*' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
9:Oh! The soup taste good.
18:google is the best tools for search keyword.
19:goooooogle yes!
- 因为( * )代表的是“重复 0 次或多次前面一个字符”的意义,因此,“ o* ”代表的是,“空字符或一个 o 以上的字符 ”。 特别注意,因为允许空字符(就是有没有字符都可以的意思),因此,“ grep -n ’ o* ’ regular_express.txt ” 将会把所有的数据都打印出来屏幕上。
- 那如果是“ oo* ”呢?则第一个 o 肯定必须存在,第二个 o 与( * )组成了( o* ),则代表“空字符或一个 o 以上的字符 ”。 所以,凡是含有 o, oo, ooo, oooo 等等的字符,都可以被列出来。同理,当我们需要 “至少两个 o 以上的字符”时,就需要 ’ ooo* '。
- 如果我想要字串开头与结尾都是 g,但是两个 g 之间仅能存在至少一个 o ,亦即是 gog, goog, gooog… 等等,那该如何?
[dmtsai@study ~]$ grep -n 'goo*g' regular_express.txt
18:google is the best tools for search keyword.
19:goooooogle yes!
- 再来一题,如果我想要找出 g 开头与 g 结尾的字串,当中的字符可有可无, 那该如何是好?是“g*g”吗?让我们试试:
[dmtsai@study ~]$ grep -n 'g*g' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
3:Football game is not use feet only.
9:Oh! The soup taste good.
13:Oh! My god!
14:The gd software is a library for drafting programs.
16:The world <Happy> is the same with "glad".
17:I like dog.
18:google is the best tools for search keyword.
19:goooooogle yes!
20:go! go! Let's go.
- 很明显,输出结果不是我们想要的,因为‘ g*g ’代表代表 “空字符或一个以上的 g” 再加上最后的 g 。因此,整个表达式的内容就是 g, gg, ggg, gggg , 只要该行当中拥有一个以上的 g 就符合所需。
- 那该如何得到我们的 g…g 的需求呢?就利用任意一个字符 ( . )
- 因为 ’ * ’ 可以是 0 或多次重复前面一个字符,而 ’ . ’ 是任意一个字符,所以: ’ . ’ 就代表零个或多个任意字符了。*
[dmtsai@study ~]$ grep -n 'g.*g' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
14:The gd software is a library for drafting programs.
18:google is the best tools for search keyword.
19:goooooogle yes!
20:go! go! Let's go.
- 因为是代表 g 开头与 g 结尾,中间任意字符均可接受,所以,第 1, 14, 20 行是会打印出来的。 这个(.*)的正则表达式表示任意字符是很常见的,希望大家能够理解并且熟悉。
- 再出一题,如果我想要找出拥有 “任意数字”的行列呢?因为仅有数字,所以就成为:
[dmtsai@study ~]$ grep -n '[0-9][0-9]*' regular_express.txt
5:However, this dress is about $ 3183 dollars.
15:You are the best is mean you are the no. 1.
- 虽然使用 grep -n ‘[0-9]’ regular_express.txt 也可以得到相同的结果,但大家要理解正则表达式的使用才好。
3.5 例题五:限定连续字符范围 {}
- 在例四中,我们可以利用(.*)来设置 0 个到无限多个任意重复字符, 那如果我想要限制一个范围区间内的重复字符数呢?
- 举例来说,我想要找出两个到五个 o 的连续字串,该如何操作?这时候就得要使用到限定范围的字符 {} 了,它只对它前面的一个字符起作用。 因为 ‘{’ 与’ }’ 这两个符号在 shell 是有 特殊意义的,因此, 我们必须要使用转义字符(\)让它失去特殊意义才行。
- 假设我要找到含两个 o 的字串,可以是:
[dmtsai@study ~]$ grep -n 'o\{2\}' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
9:Oh! The soup taste good.
18:google is the best tools for search keyword.
19:goooooogle yes!
- 这样看似乎与使用 ’ ooo* '的表达式没有什么差异啊?因为第 19 行有多个 o 依旧也出现了。
- 那假设我们要找出 g 后面接 2 到 5 个 o ,然后再接一个 g 的字串,他会是这样:
[dmtsai@study ~]$ grep -n 'go\{2,5\}g' regular_express.txt
18:google is the best tools for search keyword.
- 第 19 行终于没有被取用了(因为 19 行有 6 个 o ),{} 符号限定了个数范围。
- 如果我想要的是 2 个 o 以上的 ‘goooo…g’ 呢?除了可以使用’ gooo*g’,也可以是:
[dmtsai@study ~]$ grep -n 'go\{2,\}g' regular_express.txt
18:google is the best tools for search keyword.
19:goooooogle yes!
- 总结:{2} 代表了重复 2 次前面单个字符;{2,} 代表了重复 2 ~ 无穷次前面单个字符;{2,5} 代表了重复 2 ~ 5 次前面单个字符。
4. 基础正则表达式字符汇整 (characters)
- 经过了上面的几个简单的范例,我们可以将基础的正则表达式特殊字符汇整如下:

- 再次强调:“正则表达式的特殊字符”与一般在命令行输入指令的“万用字符”并不相同。
- 举例来说,不支持正则表达式的 ls 这个工具中,若我们使用 “ls -l ” 代表的是任意文件名的文件,而 “ls -l a ”代表的是以 a 为开头的任何文件名的文件, 但在正则表达式中,我们要找到含有以 a 为开头的文件,则必须要这样:(需搭配支持正则表达式的工具)
- ls | grep -n ‘^a.*’
- 例题:以 ls -l 配合 grep 找出 /etc/ 下面文件类型为链接文件属性的文件名。
- 答:由于 ls -l 列出链接文件时标头会是“ lrwxrwxrwx ”,因此使用如下的指令即可找出结果:
[dmtsai@study ~]$ ls -l /etc | grep '^l'
5. sed工具
- sed 本身也是一个管线命令,可以分析 standard input , 而且 sed 还可以将数据进行取代、删除、新增、撷取特定行等等的功能。 我们先来了解一下 sed 的用法,再来聊他的用途。
[dmtsai@study ~]$ sed [-nefr] [动作]
选项与参数:
-n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到屏幕上。 但如果加上 -n 参数后,则只有经过 sed 特殊处理的那一行(或者动作)才会被列出来。
-e :直接在命令行界面上进行 sed 的动作编辑;
-f :直接将 sed 的动作写在一个文件内, -f filename 则可以执行 filename 内的 sed 动作;
-r :sed 的动作支持的是延伸型正则表达式的语法。(默认是基础正则表达式语法)
-i :直接修改读取的文件内容,而不是由屏幕输出。
动作说明: [n1[,n2]] function
n1, n2 :不见得会存在,一般代表“选择进行动作的行数”,举例来说,如果我的动作是需要在 10 到 20 行之间进行的,则指令为 “10,20[动作行为] ”
function 有下面这些参数:
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行);
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行;
d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行;
s :取代,可以直接进行取代的工作.通常这个 s 的动作可以搭配正则表达式, 例如 1,20s/old/new/g。
- 需要注意的是, sed 后面接的动作,请务必以 (‘’) 两个单引号括住!
5.1 以行为单位的新增/删除功能
范例一:将 /etc/passwd 的内容列出并且打印行号,同时,请将第 2~5 行删除!
[dmtsai@study ~]$ cat -n /etc/passwd | sed '2,5d'
1 root:x:0:0:root:/root:/bin/bash
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
.....(后面省略).....
- sed 的动作为 ‘2,5d’ ,那个 d 就是删除的动作。因为 2-5 行被删除了,所以显示的数据就没有 2-5 行。另外,注意一下,原本应该是要下达 sed -e 才对,但是没有 -e 也行。
- 如果只要删除第 2 行,可以使用“ cat -n /etc/passwd | sed ‘2d’ ”来达成。
- 若是要删除第 3 到最后一行,则是“ cat -n /etc/passwd | sed ‘3,$d’ ”,符号( $ )代表最后一行。
范例二:承上题,在第二行后(亦即是加在第三行)加上“drink tea?”字样。
[dmtsai@study ~]$ cat -n /etc/passwd | sed '2a drink tea?'
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
drink tea?
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
.....(后面省略).....
- 在 a 后面加上的字串就会出现在第二行后面了!那如果是要在第二行前呢加入字符呢?使用 “ cat -n /etc/passwd | sed ‘2i drink tea?’ ”就可以了。 就是将“ a ”变成“ i ”即可。
- 增加一行很简单,那如果是要增将两行以上呢?
范例三:在第二行后面加入两行字,例如“Drink tea or .....”与“drink beer?”
[dmtsai@study ~]$ cat -n /etc/passwd | sed '2a Drink tea or ......\
> drink beer ?'
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
Drink tea or ......
drink beer ?
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
.....(后面省略).....
- 所以,我们可以新增好几行。但是每一行之间都必须要以反斜线()来进行结尾新行的增加。注意:一定不要忘记最后结束的 ’ 符号。
5.2 以行为单位的取代与显示功能
- 刚刚是介绍如何新增与删除,那么如果要整行取代呢?看看下面的范例吧。
[dmtsai@study ~]$ cat -n /etc/passwd | sed '2,5c No 2-5 number'
1 root:x:0:0:root:/root:/bin/bash
No 2-5 number
6 sync:x:5:0:sync:/sbin:/bin/sync
.....(后面省略)....
- 通过使用 ‘c’ 这个动作我们就能够将数据整行取代了。
- sed 还有更好的用法。我们以前想要列出第 11~20 行, 得要通过“head -n 20 | tail -n 10”之类的方法来处理,很麻烦。 sed 则可以简单的直接取出你想要的那几行,通过行号来获取。 看看下面的范例先:
范例五:仅列出 /etc/passwd 文件内的第 5-7 行
[dmtsai@study ~]$ nl /etc/passwd | sed -n '5,7p'
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
- 上述的指令中有个重要的选项“ -n ”,按照说明文档,这个 -n 代表的是“安静模式”。 作用是将只有经过 sed 特殊处理的那一行(或者动作)显示出来。
- 那么为什么要使用安静模式呢?你可以自行下达 sed ‘5,7p’ 就知道了 (5-7 行会重复输出)。你可以通过这个 sed 的以行为单位的显示功能,就能够将某一个文件内的某些行号捕获出来查阅。
- 思考:上面的进阶 grep指令 ( grep [-A] [-B] [–color=auto] ‘搜寻字串’ filename ),也可以选择输出行数的范围,但必须是以指定搜寻字串为准的范围;而sed 指令( sed -n ‘5,7p’ ) 则可以直接选择输出行数的范围,无需搜寻字串。关联记忆
5.3 部分数据的搜寻并取代的功能
- 除了整行的处理模式之外, sed 还能使用以行为单位进行部分数据的搜寻并取代的功能。 基本上 sed 的搜寻与取代功能与 vi 的类似。如下:
- sed ‘s/要被取代的字串/新的字串/g’
- 上表中黄色字体的部分为关键字,请记下来。至于三个斜线分成的两栏就是新旧字串的替换了。
- 我们使用下面这个取得 IP 数据的范例,一段一段的来处理,了解一下什么是所谓的搜寻并取代功能。
步骤一:先观察原始讯息,利用 /sbin/ifconfig 查询 IP 为何?
[dmtsai@study ~]$ /sbin/ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::5054:ff:fedf:e174 prefixlen 64 scopeid 0x20<link>
ether 52:54:00:df:e1:74 txqueuelen 1000 (Ethernet)
.....(以下省略).....
# 因为我们还没有讲到 IP ,这里你先有个概念即可啊!我们的重点在第二行,
# 也就是 192.168.1.100 那一行而已!先利用关键字捉出那一行!
步骤二:利用关键字配合 grep 撷取出关键的一行数据
[dmtsai@study ~]$ /sbin/ifconfig eth0 | grep 'inet '
inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
# 当场仅剩下一行!要注意, CentOS 7 与 CentOS 6 以前的 ifconfig 指令输出结果不太相同,
# 这个范例主要是针对 CentOS 7 以后的。接下来,我们要将'192.168.1.100'前面的字符通通删除,
# 下面的删除关键在于“ ^.*inet ”,注意最后一位是空格。正则表达式出现。
步骤三:将 IP 前面的部分删除
[dmtsai@study ~]$ /sbin/ifconfig eth0 | grep 'inet ' | sed 's/^.*inet //g'
192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
# 仔细与上个步骤比较一下,前面的部分不见了。接下来则是删除'192.168.1.100'后面的部分,即删除:'netmask 255.255.255.0 broadcast 192.168.1.255'这一段字符串。
# 此时所需的正则表达式为:“ *netmask.*$ ”。注意第一个字符是空格,最后以($)结尾。
步骤四:将 IP 后面的部分删除
[dmtsai@study ~]$ /sbin/ifconfig eth0 | grep 'inet ' | sed 's/^.*inet //g' | sed 's/ *netmask.*$//g'
192.168.1.100
- 假设我只要 MAN 存在的那几行数据, 但是含有 # 在内的注解我不想要,而且空白行也不要。该怎么处理呢?
步骤一:先使用 grep 将关键字 MAN 所在行取出来
[dmtsai@study ~]$ cat /etc/man_db.conf | grep 'MAN'
# MANDATORY_MANPATH manpath_element
# MANPATH_MAP path_element manpath_element
# MANDB_MAP global_manpath [relative_catpath]
# every automatically generated MANPATH includes these fields
....(后面省略)....
步骤二:删除掉注解之后的数据!实际是用空白取代原有字串。
[dmtsai@study ~]$ cat /etc/man_db.conf | grep 'MAN' | sed 's/#.*$//g'
MANDATORY_MANPATH /usr/man
....(后面省略)....
# 从上面可以看出来,原本注解的数据都变成空白行啦!所以,接下来要删除掉空白行
[dmtsai@study ~]$ cat /etc/man_db.conf | grep 'MAN' | sed 's/^#.*$//g' | sed '/^$/d'
MANDATORY_MANPATH /usr/man MANDATORY_MANPATH /usr/share/man MANDATORY_MANPATH /usr/local/share/man
....(后面省略)
- 注意:在sed 指令中使用正则表达式时,需要用两个(/)号括起来,就像上面的( sed ‘/ ^$ /d’ ),若是不括则会报错。
5.4 直接修改文件内容(危险动作)
- sed 甚至可以直接修改文件的内容,而不必使用管线命令或数据流重导向。不过,由于这个动作会直接修改到原始的文件,所以千万不要随便拿系统配置文件来测试! 我们还是使用前面下载的 regular_express.txt 文件来测试。
范例六:利用 sed 将 regular_express.txt 内每一行结尾若为 '.' 则换成 '!'
[dmtsai@study ~]$ sed -i 's/\.$/\!/g' regular_express.txt
# 上头的 -i 选项可以让你的 sed 直接去修改后面接的文件内容而不是由屏幕输出喔!
# 这个范例只是用在取代。想要查看结果需要使用 cat 指令查阅。
范例七:利用 sed 直接在 regular_express.txt 最后一行加入“# This is a test”
[dmtsai@study ~]$ sed -i '$a # This is a test' regular_express.txt
# '$' 代表的是最后一行,而 'a' 的动作是新增。
- sed 的“ -i ”选项可以直接修改文件内容。 举例来说,如果你有一个 100 万 行的文件,你要在第 100 行加某些文字,此时使用 vim 会很难操作,因为文件太大了。那就利用 sed ,通过 sed 直接修改/取代的功能,就不需要使用 vim 去修订了。
二、延伸正则表达式
- 事实上,一般只要了解基础型的正则表达式就已经相当足够了,不过,某些时刻为了要简化整个指令操作,了解一下使用范围更广的延伸型正则表达式的表示式会更方便。 举个简单的例子好了,在grep 的例题三的最后一个例子中,我们要“去除空白行与行首为 # 的 行列”,使用的指令是:
- grep -v ‘^ $’ regular_express.txt | grep -v ‘^ #’
- 需要使用到管线命令来搜寻两次。那么如果使用延伸型的正则表达式,我们可以简化为:
- egrep -v ‘$|#’ regular_express.txt
- 延伸型正则表达式可以通过群组功能符号’ | '来进行一次搜寻。那个在单引号内的管线意义为 “或 or”。
- 此外,grep 默认仅支持基础正则表达式,如果要使用延伸型正则表达式,可以使用 grep -E 。不过更建议直接使用 egrep ,直接区分指令比较好记忆。
- 我们就直接来说明,延伸型正则表达式有哪几个特殊符号。由于下面的范例还是有使用到 regular_express.txt 文件,刚刚我们可能将该文件修改过了 。所以,请重新下载该文件来练习下面的范例。
1. 符号:+
意义:重复“一次或一次以上”的前一个字符 。 范例:搜寻 (god) (good)(goood)… 等等的字串。 那个 o+ 代表“一个以上的 o ”。所以,下面的执行成果会将第 1, 9, 13 行列出来。
- egrep -n ‘go+d’ regular_express.txt
2. 符号:?
意义:重复“0次或一次”的前一个字符 。 范例:搜寻 (gd) (god) 这两个字串。 那个’ o? '代表 “空的或 1 个 o ”所以,上面的执行成果会将第 13, 14 行列出来。 有没有发现到,这两个案例( ‘go+d’ 与 ‘go?d’ )的结果集合与 ‘go*d’ 相同
- egrep -n ‘go?d’ regular_express.txt
- 注意!区别( * )和(+)还有(?)号,(*)符号是重复0次或一次以上的前一个字符; (+)符号是重复“一次或一次以上”的前一个字符;(?)号是重复“0次或一次”的前一个字符 。
3. 符号:|
意义:用 或( or )的方式找出数个字串 。 范例:搜寻 gd 或 good 这两个字串,注 意,是“或”。所以,第 1,9,14 这三行都可以被打印出来喔!那如果还想要找出 dog 呢?
- egrep -n ‘gd|good’ regular_express.txt
- egrep -n ‘gd|good|dog’ regular_express.txt
4. 符号:()
意义:找出“群组”字串 。 范例:搜寻 (glad) 或 (good) 这两个字串,因为 g 与 d 是重复的,所以, 我就可以将 la 与 oo 列于 ( ) 当中,并以 | 来分隔开来, 就可以啦!
- egrep -n ‘g(la|oo)d’ regular_express.txt
5. 符号:()+
意义:多个重复群组的判别 。 范例:将“AxyzxyzxyzxyzC”用 echo 叫出,然后再使用如下的方法搜寻一下。
- echo ‘AxyzxyzxyzxyzC’ | egrep ‘A (xyz)+ C’
- 上面的例子意思是说,要找开头是 A 结尾是 C ,中间有一个以上的 “xyz” 字串的意思。
- 以上这些就是常用的延伸型的正则表达式的特殊字符。另外,要特别强调的是,那个(!) 和(<)在正则表达式当中并不是特殊字符,可以直接使用不用转义。
三、文件的格式化与相关处理
1. awk:好用的数据处理工具
1.1 awk 的基本使用
- 相较于 sed 常常作用于一整个行数据的处理, awk 则比较倾向于将一行的数据当中分成数个“字段”来处理。因此,awk适合处理小型的数据, awk 通常运行的模式是这样的:
- awk ‘条件类型1{动作1} 条件类型2{动作2} …’ filename
- awk 后面接两个单引号(‘’)并加上大括号 {} 来设置想要对数据进行的处理动作。 awk 可以处理后续接的文件,也可以读取来自前个指令的标准输出。
- 但如前面说的,awk 主要是处理“每一行内的不同字段的数据”,而默认的字段的分隔符号为 “空白键” 或 “[tab]键” ”。
举例来说, 我们用 last 指令可以将登陆者的数据取出来,结果如下所示:
[dmtsai@study ~]$ last -n 5
仅取出前五行
dmtsai pts/0 192.168.1.100 Tue Jul 14 17:32 still logged in
dmtsai pts/0 192.168.1.100 Thu Jul 9 23:36 - 02:58 (03:22)
dmtsai pts/0 192.168.1.100 Thu Jul 9 17:23 - 23:36 (06:12)
dmtsai pts/0 192.168.1.100 Thu Jul 9 08:02 - 08:17 (00:14)
dmtsai tty1 Fri May 29 11:55 - 12:11 (00:15)
若想要取出帐号与登陆者的 IP ,且帐号与 IP 之间以 [tab] 隔开,如下:
[dmtsai@study ~]$ last -n 5 | awk '{print $1 "\t" $3}'
dmtsai 192.168.1.100
dmtsai 192.168.1.100
dmtsai 192.168.1.100
dmtsai 192.168.1.100
dmtsai Fri
- 上面的 print 命令是 awk 最常使用的动作。通过 print 的功能将字段数据列出来,字段的分隔则以默认的空白键或 [tab] 按键来隔开。
- 在本例中因为不论哪一行都要处理,因此,{} 中就不需要有 “条件类型” 的限制。 在本例中,我们想要的是每一行的第1列以及第3列,但是,第五行的内容和前四行不一样。这是因为数据格式的问题,第五行的第三列是空的,所以awk 认为 ‘Fri’ 才是第3列的数据。
- 注意:使用 awk 的时候,请先确认一下你的数据当中,如果是连续性的数据,请不要有空格或 [tab] 在内,否则就会像本例出现错误。
- 在 awk 的括号内,每一行的每个字段都是有变量名称的,那就是 $1, $2… 等等。以本例来说, dmtsai 字段是 $1 ,因为他是第一列。 至于 192.168.1.100 是第三列, 所以他就是 $3 。
- 还有个变量是 $0 ,$0 代表“一整行数据” 。以上例来说,第一行的 $0 代表的就是“dmtsai … ” 这一整行。
1.2 awk 的内置变量
- awk 指令是“以行为一次处理的单位”, 而“以字段为最小的处理单位”。那么 awk 怎么知道数据有几行,有几列呢?这就需要 awk 的内置变量了,如下:
| 变量名称 | 代表意义 |
|---|---|
| NF | 每一行 ($0) 拥有的字段总数 |
| NR | 目前 awk 所处理的是“第几行”数据 |
| FS | 目前的分隔字符类型,默认是空白键 |
我们继续以例子来做说明,如果我想要: 打印出每一行的帐号(就是 $1); 打印出目前处理的是第几行(就是 awk 内的 NR 变量), 并且说明,该行有多少字段(就是 awk 内的 NF 变量),该怎么做:
[dmtsai@study ~]$ last -n 5 | awk '{print $1 "\t lines:" NR "\t columns:" NF}'
dmtsai lines: 1 columns: 10
dmtsai lines: 2 columns: 10
dmtsai lines: 3 columns: 10
dmtsai lines: 4 columns: 10
dmtsai lines: 5 columns: 9
# 注意,在 awk 内的 NR, NF 等变量要用大写,且不需要加钱字号 $ 。
- 要注意的是,awk 默认后续的所有动作是以单引号(')括住的。由于单引号与双引号都必须是成对的,所以, awk 的格式内容如果想要以 print 打印时,记得非变量的文字部分,都需要使用双引号(")来定义出来。 因为单引号已经是 awk 的指令固定用法了。
1.3 awk 的条件类型
- 既然有需要用到 “条件” 的类型,自然就需要一些逻辑运算awk 的逻辑运算字符,如下表:
| 运算符号 | 代表意义 |
|---|---|
| > | 大于 |
| < | 小于 |
| >= | 大于或等于 |
| <= | 小于或等于 |
| == | 等于 |
| != | 不等于 |
举例来说,在 /etc/passwd 文件当中是以冒号(:)来作为字段的分隔符的,如下图所示:

该文件中第一字段为帐号,第三字段则是 UID。那假设我要查阅,第三列小于 10 以下的数据,并且仅列出第一列与第三列, 那么可以这样做:
[dmtsai@study ~]$ cat /etc/passwd | awk '{FS=":"} $3 < 10 {print $1 "\t " $3}'
root:x:0:0:root:/root:/bin/bash
daemon 1
bin 2
sys 3
sync 4
....(以下省略)....
- 怎么第一行没有正确的显示出来呢?这是因为我们读入第一行的时候,那些变量 $1, $2… 默认还是以空格键为分隔的,所以虽然我们定义了 FS=“:” 了, 但是却仅能在第二行后才开始生效。
- 那么怎么办?我们可以预先设置 awk 的变量, 利用 BEGIN 这个关键字。这样做:
[dmtsai@study ~]$ cat /etc/passwd | awk 'BEGIN {FS=":"} $3 < 10 {print $1 "\t " $3}'
root 0
daemon 1
bin 2
sys 3
sync 4
......(以下省略)......
- 这样输出的所有行都符合我们的要求了。
1.4 awk 的运算功能
- 另外,如果要用 awk 来进行“计算功能”呢?以下面的例子来看, 假设我有一个薪资数据表文件名为 pay.txt ,内容是这样的:
Name 1st 2nd 3th
VBird 23000 24000 25000
DMTsai 21000 20000 23000
Bird2 43000 42000 41000
- 如何计算每个人的总额呢?可以这样考虑:
- 第一行数据只是说明,所以第一行不要进行加总 (当 NR==1 时处理);
- 第二行以后就会有加总的情况出现 (当 NR >=2 以后处理)
[dmtsai@study ~]$ cat /home/pay.txt | awk 'NR==1 {print $1 "\t" "total"} NR >=2 {print $1 "\t" $2+$3+$4}'
- 输出:
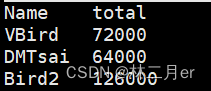
- awk 有几个重要事项应该说明的:
- awk 的指令间隔:所有 awk 的动作,即在 {} 内的动作,如果有需要多个指令辅助时, 可利用分号(;)间隔, 或者直接以 [Enter] 按键换行来隔开每个指令。
- 与 bash shell 的变量不同,在 awk 当中,变量可以直接使用,不需加上 $ 符号。
2. 文件比对工具 diff 和 cmp
- 什么时候会用到文件的比对?通常是“同一个套装软件的不同版本之间,比较配置文件与原始文件的差异”。
- 很多时候所谓的文件比对,通常是用在 ASCII 纯文本文件的比对上。那么 比对文件的指令有哪些?最常见的就是 diff 指令了。
- 另外,除了 diff 比对之外,我们还可以借由 cmp 来比对非纯文本文件。
- 同时,也能够借由 diff 创建的分析文档, 用以处理补丁 (patch) 功能的文件。
2.1 diff 的基本用法
- diff 就是用在比对两个文件之间的差异的,并且是以行为单位来比对的。一般是用在 ASCII 纯文本文件的比对上。 由于是以行为比对的单位,因此 diff 通常是用在同一的文件(或软件) 的新旧版本差异上。
- 举例来说,假如我们要将 /etc/passwd 处理成为一个新的版本,处理方式为: 将第四行删除,第六行则取代成为“no six line”,新的文件放置到 /tmp/test 里面,那么应该怎么做?
[dmtsai@study ~]$ mkdir -p /tmp/testpw #先创建测试用的目录
[dmtsai@study ~]$ cd /tmp/testpw
[dmtsai@study testpw]$ cp /etc/passwd passwd.old
[dmtsai@study testpw]$ cat /etc/passwd | sed -e '4d' -e '6c no six line' > passwd.new
# 注意一下, sed 后面如果要接超过两个以上的动作时,每个动作前面都得加 -e 才行!
# 通过这个动作,在 /tmp/testpw 里面便有新旧两个 passwd 文件存在了!
- diff 的基本用法如下:
[dmtsai@study ~]$ diff [-bBi] from-file to-file
选项与参数:
from-file :一个文件名,作为原始比对文件的文件名;
to-file :一个文件名,作为目的比对文件的文件名;
注意,from-file 或 to-file 可以用 (-) 取代, (-) 代表“Standard input”之意。
-b :忽略一行当中,仅有多个空白的差异(例如 "about me" 与 "about me" 视为相同
-B :忽略空白行的差异。
-i :忽略大小写的不同。
范例一:比对 passwd.old 与 passwd.new 的差异:
[dmtsai@study testpw]$ diff passwd.old passwd.new
4d3 # 左边文件的第四行被删除(d)掉了,基准是右边的第三行
< adm:x:3:4:adm:/var/adm:/sbin/nologin # 这行列出左边(<)文件被删除的那一行内容
6c5 # 左边文件的第六行被取代 (c) 基准是右边文件的第五行
< sync:x:5:0:sync:/sbin:/bin/sync # 左边(<)文件被取代第六行内容
---
> no six line # 右边(>)文件第6行被取代的内容
# 很聪明吧!用 diff 就把我们刚刚的处理给比对完毕了!
- 用 diff 比对文件真的是很简单,不过,不要用 diff 去比对两个完全不相干的文件,因为比不出什么。
- 另外, diff 也可以比对整个目录下的差异。 举例来说,我们想要了解不同的开机执行等级 (run level) 内容有啥不同。假设你已经知道执行等级 0 与 5 的启动脚本分别放置到 /etc/rc0.d 和 /etc/rc5.d 这两个目录下, 则我们可以将两个目录比对一下,如下:
[dmtsai@study ~]$ diff /etc/rc0.d/ /etc/rc5.d/
Only in /etc/rc0.d/: K90network
Only in /etc/rc5.d/: S10network
- 这样就将不同目录下的相同文件名的内容比对出来了,非常方便。
2.2 cmp 的基本用法
- 相对于 diff 的广泛用途, cmp 似乎就用的没有这么多了。
- cmp 主要也用于比对两个文件,主要利用“字节”单位去比对, 因此,当然也可以比对二进制文件。(还是要再提醒喔,diff 主要是以“行”为单位比对, cmp 则是以“字节”为单位去比对,这并不相同!)
- 用法如下:
[dmtsai@study ~]$ cmp [-l] file1 file2
选项与参数:
-l :将所有的不同点的字节处都列出来。因为 cmp 默认仅会输出第一个发现的不同点。
范例一:用 cmp 比较一下 passwd.old 及 passwd.new
[dmtsai@study testpw]$ cmp passwd.old passwd.new
passwd.old passwd.new differ: char 106, line 4
- 比对结果:第一个发现的不同点在第四行,而且字节数是在第 106 个字节处。
四、重点回顾
- 正则表达式就是处理字串的方法,他是以行为单位来进行字串的处理行为。
- 正则表达式通过一些特殊符号的辅助,可以让使用者轻易的达到“搜寻/删除/取代”某特定字串的处理程序。
- 只要工具程序支持正则表达式,那么该工具程序就可以用来作为正则表达式的字串处理之用。
- 正则表达式与万用字符是完全不一样的东西!万用字符 (wildcard) 代表的是 bash 操 作接口的一个功能, 但正则表达式则是一种字串处理的表示方式。
- grep 与 egrep 在正则表达式里面是很常见的两支程序,其中, egrep 支持更严谨的正则表达式的语法。
- 由于严谨度的不同,正则表达式之上还有更严谨的延伸正则表达式。
- 基础正则表达式的特殊字符有: *, ., [], [-], ^, $ 等!
- 常见的支持正则表达式的工具软件有: grep , sed, vim 等等。
- awk 可以使用“字段”为依据,进行数据的重新整理与输出。
- 文件的比对中,可利用 diff 及 cmp 进行比对,其中 diff 主要用在纯文本方面的新旧版本比对。
五、总结
- 本章的内容真的太多太多了!!!需要记的指令很多,用法也很多,最关键的是本章的内容非常非常重要!!所以朋友们只能勤加练习,理解掌握了。
- 小白博主在整理这一章的内容时被很多符号搞的头昏眼花的,也是一次一次的试验,最终才得到了正确的结果。
- 本文整理自《鸟哥的Linux私房菜》一书,作者幽默风趣,强烈建议大家去看看原书。另外,本文在整理过程中忽略了一些内容,比如 printf 和 patch 指令,如果想了解的朋友可以自己去看看原书。
- 最后,如果本文有什么不足之处,请各位大佬在评论区批评指正。如果本文对您有帮助的话,就给小白博主点个赞吧!!欢迎在评论区交流学习!让我们在下一篇博文再见!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











